A deep dive into the benchmarks, new features, pricing shifts, and why this release matters more than the “incremental upgrade” narrative suggests

TL;DR: Anthropic released Claude Opus 4.7 on April 16, 2026. It’s a meaningful upgrade over Opus 4.6 in advanced software engineering, multimodal vision, memory, and long-horizon agentic task execution. Pricing stays the same at $5/M input and $25/M output tokens, but a new xhigh effort level, task budgets, an updated tokenizer, and Claude Code features like /ultrareview make this a serious release for production coding and agent workflows. Anthropic openly concedes that their more powerful Mythos Preview model outperforms it — but Mythos isn't publicly available. For anyone using Claude in production today, Opus 4.7 is the most capable model you can actually ship with.
Introduction: Another Turn in the Frontier Model Race
If you’re anywhere near the AI ecosystem — whether you’re a developer, a product builder, or just an enthusiast watching this space — you already know the last few months have been relentless. GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6. Every few weeks, a new “state-of-the-art” announcement. The claims blur together. But when you actually put these models into real long-running coding tasks, real agent workflows, or complex multimodal problems, the differences become concrete fast.
On April 16, 2026, Anthropic released Claude Opus 4.7, continuing their roughly two-month cadence (Opus 4.5 → 4.6 → 4.7). This post breaks down what’s actually new, what the benchmarks tell us, what the caveats are, and whether you should upgrade.
Keywords covered: Claude Opus 4.7, Anthropic new model 2026, Claude 4.7 release notes, Claude Opus 4.7 vs 4.6, Claude Opus 4.7 benchmarks, Claude Opus 4.7 pricing, Claude Opus 4.7 features, Claude Code xhigh, Claude Mythos Preview, best AI coding model 2026, Claude API pricing, agentic AI 2026.
What Is Claude Opus 4.7? — A Quick Overview
Claude Opus 4.7 is Anthropic’s latest generally available flagship model, the direct successor to Opus 4.6 in the Claude 4 model family. According to Anthropic’s official announcement, the upgrade focuses on four pillars:
- Advanced Software Engineering — particularly on the hardest, longest coding tasks.
- Better Multimodal Vision — supports images up to 2,576 pixels on the long edge (~3.75 megapixels), more than 3x prior Claude models.
- Real-World Work — state-of-the-art on finance, legal, and economically valuable knowledge-work evaluations.
- Memory — improved use of file system-based memory for long, multi-session workflows.
The API model string is claude-opus-4-7. It's available today across all Claude products (claude.ai, mobile, desktop), the Claude API, Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry.
Why This Release Matters: The Mythos Context
To really understand Opus 4.7, you need the Mythos context.
A few weeks before this release, Anthropic announced Project Glasswing, a cybersecurity initiative under which they gave a limited set of enterprise partners (Apple, select cybersecurity firms) access to Claude Mythos Preview — a more advanced model than anything publicly available.
Mythos Preview isn’t being released publicly because its cybersecurity capabilities are advanced enough that Anthropic considers the misuse risk unacceptable at scale. Anthropic openly states that Mythos outperforms Opus 4.7.
So why release Opus 4.7 at all? Because Opus 4.7 is the first model on which Anthropic is testing automated cyber safeguards — guardrails that detect and block prohibited or high-risk cybersecurity requests. The logic: test safeguards on a less-capable model first, learn from real deployment, then eventually release Mythos-class models more broadly. Legitimate security professionals (vulnerability researchers, penetration testers, red-teamers) can apply to a new Cyber Verification Program for unrestricted access.
This is a deliberate positioning move. “We have a more powerful model, but we’re safety-testing guardrails on Opus 4.7 first” reinforces Anthropic’s long-standing brand identity as the responsible AI lab. Axios covered this dynamic explicitly, noting Anthropic’s public concession that Opus 4.7 trails the unreleased Mythos.
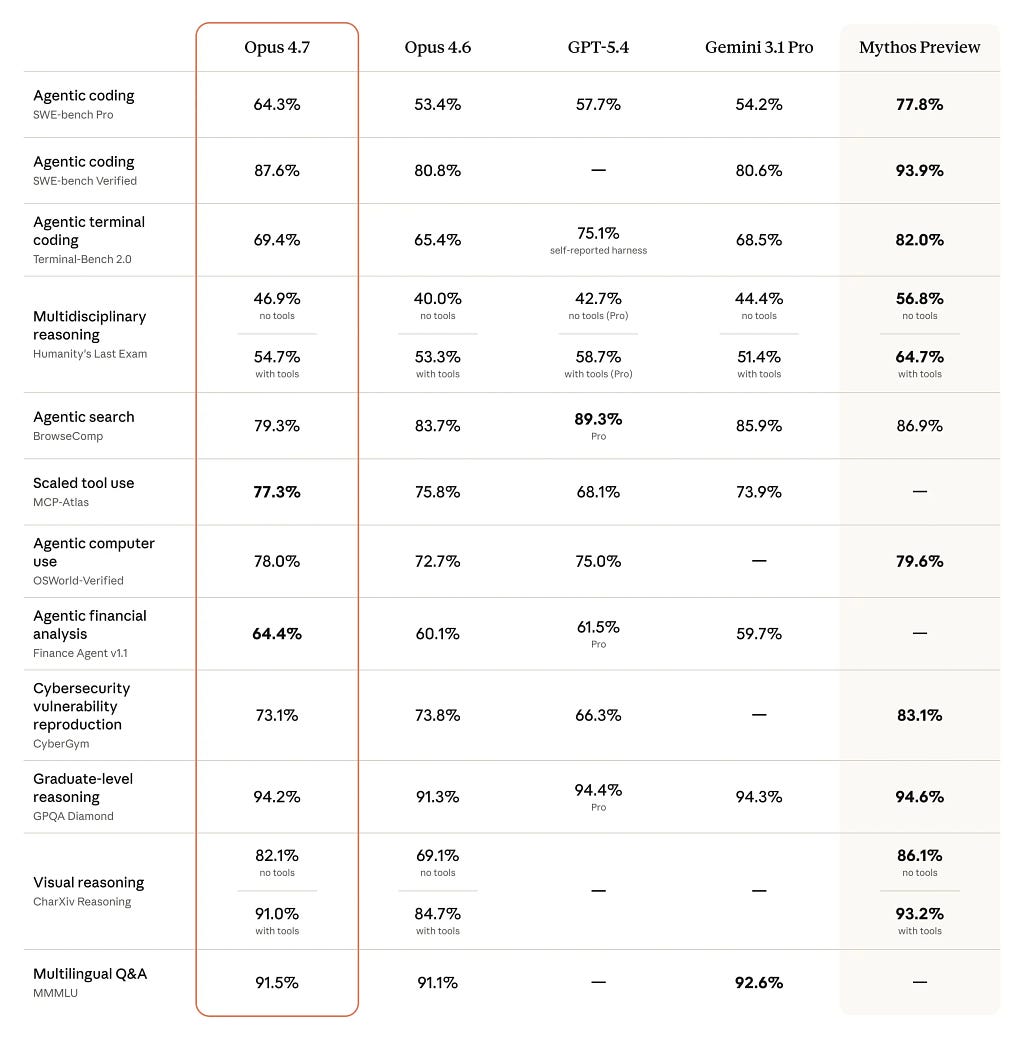
Benchmarks: The Numbers That Actually Matter
Anthropic’s announcement compared Opus 4.7 against Opus 4.6, GPT-5.4, and Gemini 3.1 Pro across multiple benchmarks. Here’s where the real signal is:
Coding Benchmarks
- CursorBench: Opus 4.7 cleared 70%, versus Opus 4.6 at 58% — a 12-point jump, per Cursor CEO Michael Truell.
- GitHub’s 93-task coding benchmark: 13% lift over Opus 4.6, including four tasks that neither Opus 4.6 nor Sonnet 4.6 could solve.
- Rakuten-SWE-Bench: 3x more production tasks resolved compared to Opus 4.6, with double-digit gains in Code Quality and Test Quality.
- SWE-bench Verified / Pro / Multilingual: Gains hold even after excluding flagged memorization problems.
- Terminal-Bench 2.0: Measurable improvements using the Terminus-2 harness.
Vision & Computer Use
- XBOW’s visual-acuity benchmark (for autonomous penetration testing): 98.5% vs 54.5% for Opus 4.6 — nearly doubling, according to XBOW CEO Oege de Moor. One of the biggest single-benchmark jumps in this release.
Real-World Knowledge Work
- Finance Agent evaluation: State-of-the-art score.
- GDPval-AA (third-party evaluation of economically valuable knowledge work across finance, legal, and other domains): State-of-the-art.
- Databricks OfficeQA Pro: 21% fewer errors than Opus 4.6 on document reasoning.
- Harvey BigLaw Bench: 90.9% at high effort, with notably better handling of ambiguous contract provisions.
Agentic & Tool Use
- Notion Agent: 14% better than Opus 4.6, with a third of the tool errors. First model to pass Notion’s implicit-need tests.
- Factory Droids: 10–15% lift in task success with fewer tool errors.
- Genspark Super Agent: Best measured quality-per-tool-call ratio, with strong loop resistance.
One pattern worth noting: across early-access testers — Replit, Devin, Cursor, Warp, Vercel, Bolt, Databricks, Ramp — the consistent theme isn’t just raw capability. It’s loop resistance, graceful error recovery, and honest self-assessment. These aren’t flashy benchmarks, but they’re exactly what separates a toy from a production-grade agent.
What’s New: Features Beyond the Model
Anthropic launched several platform-level features alongside the model itself.
1. The New xhigh Effort Level
Opus 4.7 introduces xhigh ("extra high"), a new effort level sitting between high and max. This gives developers finer-grained control over the reasoning-vs-latency tradeoff on hard problems.
In Claude Code, the default effort is now xhigh across all plans. Anthropic's explicit recommendation for coding and agentic use cases: start with high or xhigh.
2. Task Budgets (Public Beta)
The API now supports task budgets in public beta — a mechanism to guide Claude’s token spend so it can prioritize work across longer runs. This is particularly useful for autonomous agents that might otherwise burn budget on low-value sub-tasks.
3. /ultrareview in Claude Code
A new slash command that runs a dedicated review session using parallel multi-agent analysis — the way a careful senior reviewer would approach a PR. Invoke with no arguments to review the current branch, or /ultrareview <PR#> to fetch and review a specific GitHub PR. Pro and Max Claude Code users get three free ultrareviews to trial.
4. Auto Mode for Max Users
Auto mode — a permissions option where Claude makes decisions on your behalf, reducing interruptions in longer tasks — is now available for Max subscribers (previously limited to Teams, Enterprise, and API customers). Auto mode is meant to be a safer alternative to skipping all permissions.
5. Higher-Resolution Vision
Images now accept up to 2,576 pixels on the long edge (~3.75 megapixels), more than 3x prior Claude models. This is a model-level change, not an API parameter — images are simply processed at higher fidelity by default. This unlocks:
- Computer-use agents reading dense screenshots
- Data extraction from complex diagrams
- Pixel-perfect reference work
- Chemical structures and technical diagrams (Solve Intelligence specifically called this out)
One caveat: higher-resolution images consume more tokens. If you don’t need the detail, downsampling before sending saves cost.
6. Better File-System Memory
Opus 4.7 is meaningfully better at using file system-based memory. It remembers important notes across long, multi-session workflows and uses them to pick up new tasks with less up-front context.
Pricing: What Changed, What Didn’t
Pricing stays flat:
- $5 per million input tokens
- $25 per million output tokens
But effective costs may rise, for two reasons:
- Updated Tokenizer: The same input now maps to roughly 1.0–1.35x tokens, depending on content type. The tokenizer is genuinely better at processing text, but it’s a tradeoff.
- More Thinking at Higher Effort: Particularly on later turns in agentic settings. Reliability improves, but output tokens grow.
Anthropic claims the net effect is favorable — their internal coding evaluation shows improved token usage across all effort levels. But their honest recommendation is to measure the difference on your own production traffic before scaling up.
Practical cost controls:
- Tune the effort parameter down where appropriate
- Set task budgets explicitly
- Prompt the model to be more concise
- Downsample images when high-resolution isn’t needed
GitHub Copilot pricing note: Opus 4.7 launched on Copilot with a 7.5x premium request multiplier as promotional pricing through April 30, 2026. Over the following weeks, it will replace Opus 4.5 and 4.6 in the model picker for Copilot Pro+, Business, and Enterprise users.
Migration Guide: Moving from Opus 4.6 to 4.7
The good news: Opus 4.7 is a direct upgrade — effectively a drop-in replacement. The less-good news: if you have production prompts heavily tuned for Opus 4.6, a few things deserve attention.
1. Retune Your Prompts
Opus 4.7 is substantially better at literal instruction following. Prompts that earlier models interpreted loosely — or quietly skipped parts of — are now taken literally. This means old prompts can sometimes produce unexpected results. If your prompts contain ambiguous instructions or rely on the model’s “common sense” to ignore parts, review them.
2. Re-evaluate Your Token Budget
Tokenizer change + deeper thinking = potentially more tokens per request. If you’re running cost-sensitive workloads, shadow-test on a slice of production traffic before cutting over.
3. Experiment with Effort Levels
Hex CTO Caitlin Colgrove reported: “Low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6.” In many cases, you can actually reduce effort and retain quality, which offsets the tokenizer-driven cost increase.
4. Take Advantage of Higher-Resolution Images (or Don’t)
If your use case doesn’t need fine visual detail, downsample images pre-API to control token spend. If it does — especially for computer-use, dense documents, or technical diagrams — you get the higher resolution for free.
Anthropic has published an official migration guide in the developer docs (platform.claude.com/docs) with more detailed guidance on tuning effort levels.
Safety & Alignment: Where It Improved, Where It Slipped
Opus 4.7’s overall safety profile is similar to Opus 4.6 — low rates of concerning behaviors like deception, sycophancy, and cooperation with misuse. But there’s nuance.
Improvements:
- Honesty — more honest self-assessment and reporting of limits
- Prompt injection resistance — better defense against malicious prompt attacks
- Overall misaligned behavior — Opus 4.7 scores better than both Opus 4.6 and Sonnet 4.6 on Anthropic’s automated behavioral audit
Modest Regressions:
- Harm-reduction advice on controlled substances — slight tendency to provide overly detailed information in this specific domain
Anthropic’s alignment assessment concluded that Opus 4.7 is “largely well-aligned and trustworthy, though not fully ideal in its behavior.” Mythos Preview remains Anthropic’s best-aligned model by their internal evaluations.
Full details are in the Claude Opus 4.7 System Card, available on Anthropic’s site.
What Partners Are Saying
Anthropic’s announcement included 28 partner testimonials. A few that stood out:
- Replit (Michele Catasta, President): “Same quality at lower cost — more efficient and precise at tasks like analyzing logs and traces, finding bugs, and proposing fixes. It really feels like a better coworker.”
- Devin (Scott Wu, CEO): “Works coherently for hours, pushes through hard problems rather than giving up, and unlocks a class of deep investigation work we couldn’t reliably run before.”
- Vercel (Joe Haddad, Distinguished Engineer): “Does proofs on systems code before starting work, which is new behavior we haven’t seen from earlier Claude models.”
- XBOW (Oege de Moor, CEO): “Our single biggest Opus pain point effectively disappeared.”
- CodeRabbit (David Loker, VP AI): “Recall improved by over 10% — a bit faster than GPT-5.4 xhigh on our harness.”
- Cursor (Michael Truell, CEO): “A meaningful jump — clearing 70% versus Opus 4.6 at 58%.”
- Rakuten (Yusuke Kaji, GM AI for Business): “3x more production tasks resolved than Opus 4.6 on Rakuten-SWE-Bench.”
One underappreciated pattern: multiple partners call out honest self-assessment and instruction-following fidelity, not just raw capability. Vercel’s engineer noting that the model is “more honest about its own limits” is, for anyone running agents in production, actually one of the most valuable qualities on this list.
Is Opus 4.7 Right for You?
Upgrade to Opus 4.7 if you’re:
- Running long-running agentic coding tasks (multi-step PR reviews, autonomous debugging, long build pipelines)
- Doing complex multimodal work — dense diagrams, screenshots, technical documents
- Building finance, legal, or knowledge-work agents
- Running workflows where loop resistance and graceful error recovery matter
- Orchestrating long, multi-session workflows where memory continuity is valuable
Maybe wait if you’re:
- Running a stable production system on Opus 4.6 with heavily tuned prompts — at minimum, shadow-test first
- Cost-sensitive and unable to experiment with effort levels
- In a use case where Opus 4.6 is already “good enough” — incremental gains are smaller on simpler tasks
Industry Reaction: The “Good but Not Great” Narrative
Some tech outlets — AI Business, Axios among them — framed the release as “good but not great.” A few reasons why:
- The Mythos Shadow: Anthropic themselves emphasize that Mythos is more capable. Announcing your best publicly-available model while simultaneously highlighting the one you’re not releasing sends a mixed message.
- Opus 4.6 “Nerfed” Complaints: In the weeks before this release, users (including an AMD senior director in a widely-shared GitHub post) complained that Opus 4.6 had regressed. Anthropic denied any intentional scaleback or compute redirection to Mythos.
- Flat Pricing, Higher Effective Cost: The tokenizer and deeper-thinking changes mean effective cost rises for some workloads despite unchanged per-token pricing.
That said, on objective benchmarks this is clearly the best generally-available coding model right now. Cursor, Devin, Notion, Factory, Replit, Vercel, Warp, Databricks — these teams aren’t sentimental about model choices, and their evaluations converge on the same conclusion.
The Bigger Picture: Why Reliability Beats Raw IQ
Opus 4.7 highlights an industry trend worth internalizing:
Raw capability is getting incrementally better. Reliability is where the real differentiation now lives.
Opus 4.7’s biggest wins — loop resistance, tool error recovery, instruction fidelity, long-horizon coherence, honest self-assessment — aren’t about IQ. They’re about production reliability. Enterprise teams pay for models that can run autonomously for hours with minimal supervision and return useful work.
GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.7 are all pushing on this frontier. Claude’s current edge: coding, agentic workflows, and long-horizon task execution. Whether that edge holds through the next GPT-5.5 or Gemini 3.2 release is anyone’s guess — but for April 2026, it’s real and measurable.
Conclusion: Should You Care?
Short answer: yes, if you’re anywhere in the AI or developer ecosystem.
Claude Opus 4.7 isn’t a revolutionary leap. It’s a solid, meaningful upgrade that addresses real pain points:
- ✅ Better performance on the hardest coding tasks
- ✅ 3x higher image resolution
- ✅ xhigh effort level for granular reasoning control
- ✅ /ultrareview for serious code review workflows
- ✅ Same per-token pricing (with tokenizer nuance)
- ✅ Broad availability across Claude products and all three major clouds
The Mythos shadow will keep looming — that’s Anthropic’s strategic moat. But in practical terms, Opus 4.7 is the most capable AI model you can actually deploy today for the vast majority of production contexts.
If you’ve been doing serious work on Opus 4.6, the upgrade is worth evaluating. If you’ve been using GPT-5.4 or Gemini 3.1 Pro and considering a revisit of the Claude ecosystem, this is a natural moment to benchmark them side-by-side on your actual workload.
Further Reading & Resources
- Anthropic Official Announcement: anthropic.com/news/claude-opus-4-7
- Claude Opus 4.7 System Card (full safety evaluations)
- Migration Guide: platform.claude.com developer docs
- Claude Code Release Notes: github.com/anthropics/claude-code/releases
- Project Glasswing & Mythos Context: anthropic.com/glasswing
What’s Your Take?
Have you tried Claude Opus 4.7 yet? How does it compare against GPT-5.4 or Gemini 3.1 Pro on your workloads? Drop your experience in the comments — especially if you’re running production coding or agent workflows. And if this deep dive was useful, a clap and a follow go a long way. More AI analysis incoming.
Tags: #ClaudeOpus47 #Anthropic #AI #MachineLearning #CodingAI #LLM #ArtificialIntelligence #AIDevelopment #ClaudeAI #AgenticAI #TechNews2026 #AIModels #SoftwareEngineering #DeveloperTools #ClaudeCode
Disclaimer: Benchmark numbers and partner testimonials are sourced from Anthropic’s official release materials and partner quotes published on April 16, 2026. Individual results will vary by workload — for production decisions, testing on your actual use case is essential.
Claude Opus 4.7 Is Here: Anthropic’s New Model That’s Quietly Redefining Agentic Coding was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.