Written very quickly for the Inkhaven Residency.
Yesterday, I started a post-mortem on my earliest published machine learning research paper “The Assistive Multi-Armed Bandit”, by providing the context for my paper as well as the timeline of the project. Today, I’ll summarize and review the actual paper.
Paper summary
As noted in the abstract and introduction, a commonly-studied problem in many fields is preference learning: inferring what people want by observing their behavior. For both philosophical and practical reasons, it’s pretty common to infer preferences by assuming that people are (close to) rational. The paper tries to formalize a particular way in which this rationality assumption fails: people often do not know what their preferences are ahead of time, and observations of behavior often occur when people are still learning what they want.
The formalism studied in the paper is probably the simplest version of an assistance game where a human is learning about their rewards. In this setup, there are N possible actions, each with their own independent distribution of rewards. At each step, the human suggests an action, the robot takes a (possibly different) action, and then the human gets to observe the results of each action. (In section V.E we consider alternative setups – one where the human and robot alternate turns, and the other in which the robot can choose between acting themselves and allowing the human to act). As the value of the actions stays constant over time, this is a multi-armed bandit setting.
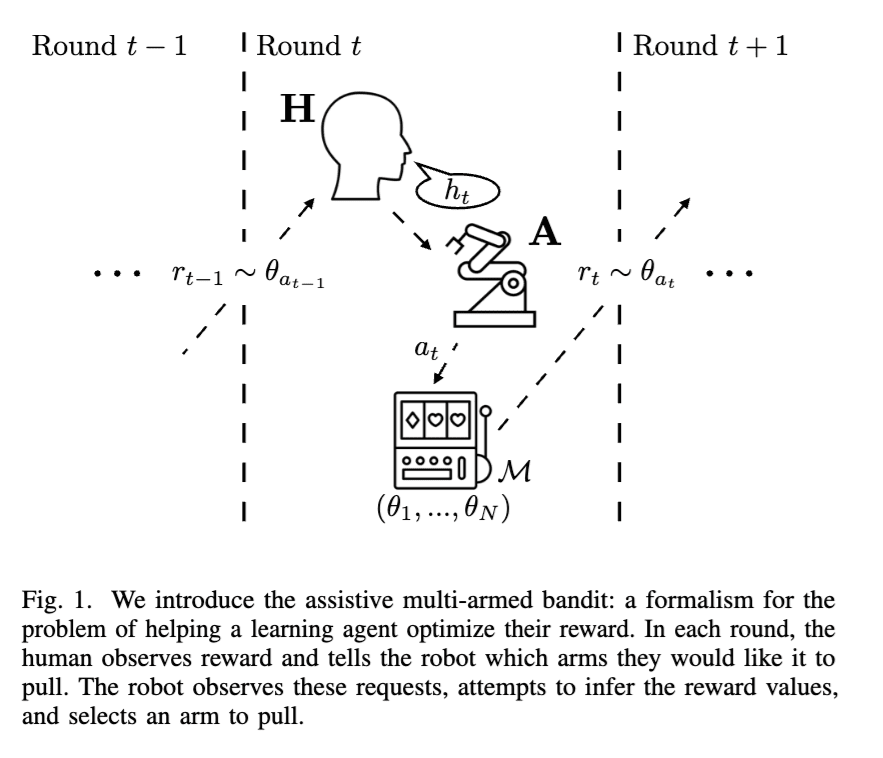
Caption: Figure 1 from the assistive bandits paper, which introduces the formalism. As an aside, “A” was used for the robot (“agent”, “actor”, or “AI”) instead of “R”, to avoid confusing the robot and its actions with the reward observed by the human r.
We then prove some theoretical results about this setting. First, proposition 1 is a rather trivial proposition, that basically says that if the human knows the expected value of each action almost always suggests the best action, then the robot can do quite well (achieve finite regret) by just taking the action the human suggests the most often. I see this as an interesting exercise mainly to check that we understand the setting: inferring the optimal action is easy when the person almost always suggests the optimal action. The difficulty of the assistive bandits framing comes entirely from the fact that the human is still learning about their preferences.
Proposition 2 shows that if the human implements a policy where they take the action with the highest observed average value most often, then with robot assistance, the pair will eventually converge to taking the action with the highest frequency (that is, the policy is consistent). This is done by making the robot explore for the human at a carefully chosen rate, such that each action is taken infinite times, but where eventually the probability of exploring at each given time step decays to 0. This is a nice implementation of ideas from multi-armed bandit theory.
Proposition 3 follows somewhat non-trivially from proposition 1 (consistency is weaker than finite regret). But it makes sense that I’d state it separately, since the proof is much easier.
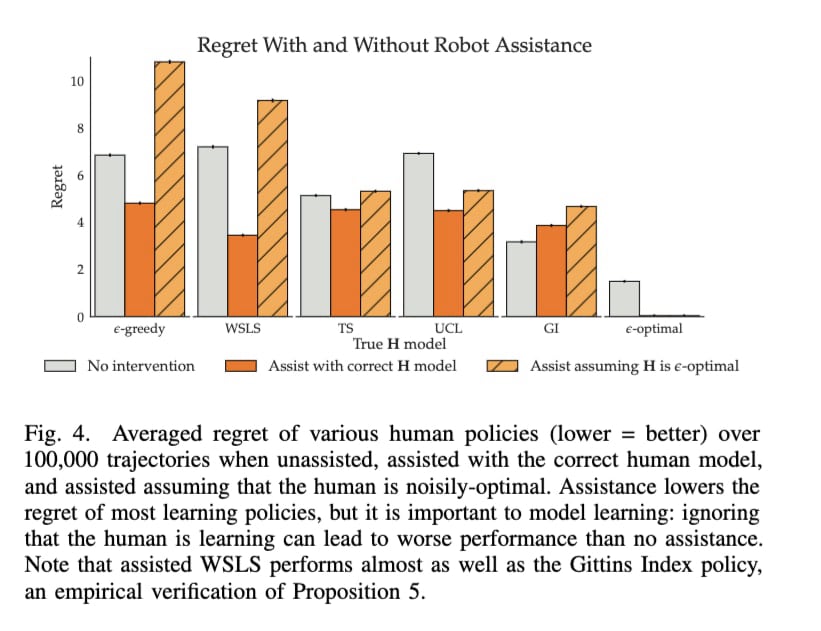
Proposition 4 is the main result of the paper: it is indeed important to model learning, in that there are situations where not doing so leads to bad outcomes even in the limit, because the robot that doesn’t respect the human’s learning process may prevent the human from learning about their preferences.
Proposition 5 shows that there are simple human policies that are informative, that do better than “optimal” policies. That is, you can be better in collaborative games by informing others of your preferences, rather than by doing the best thing in isolation. The paper claims that this is “surprising”, but I felt this was pretty obvious.
Proposition 6 and corollary 7 feels the most proof-of-worky to me. They basically expand on proposition 5, by arguing that in this setting (via some somewhat intricate math), if the robot is to assist the human, the human must communicate sufficient information about the optimal arm.
The paper then uses deep reinforcement learning + recurrent neural networks to solve for robot policies in specific versions of the assistive bandit problem. Using this technique, the paper basically confirms all of the theoretical results in their experimental setting.
Finally, in V.E, the paper considers other variants of the assistive bandit problem.
The paper concludes with obvious limitations and future work: the human policies are unrealistic, as is the simplicity of the environmental setup (that is, there is no environment).
Feedback on the paper
It’s hard not to be too critical toward my past self, but I’ll make an honest attempt to evaluate the paper.
I think, as a “first paper”, it was pretty okay but not brilliant. I still think that the core idea behind the paper is good: it is indeed quite important to model human suboptimality when trying to infer preferences from observed behavior. I also think the specific form of suboptimality studied in the paper – that people often can only access their preferences by experiencing them, rather than having full introspective access to their preferences at the start – is obviously real. The paper also shows that, at the time, I had a decent level of familiarity with both multi-armed bandit theory and deep reinforcement learning.
In this sense, the paper does indeed study the simplest setting with this form of irrationality, where all of the complexity of the setting comes from the fact the human is still learning about their preferences. I worry that, by studying such a restrictive setting, the only conclusions
I also think, with the exception of some nitpicks, the writing of the paper is quite good: every proposition is set up and explained. I also like the parallel structure between the theory and the experiments. The graphic design was also quite consistently clean.
The main issue I have with the paper is that the setting may be so simplified as to be uninteresting. Specifically, in my opinion, the main contributions of the paper (if anything) are proposition 4 – when the human is learning about their preferences, it’s important to model the learning – and arguably the use of deep RL to solve the complex POMDP. I feel like most of the other parts of the paper weren’t great, and insofar as they provided value they were proof of competency/proof of work so that these contributions would be taken seriously.
A related problem is that, even if we were to accept that people are learning about their preferences, it’s not at all obvious how to incorporate it into actual algorithms. Notably, the paper completely sidesteps this by using black-box optimization to solve the setting.
The paper would be a lot stronger if the other theorems and a bunch of the space dedicated to experiments were replaced with a simple application of these ideas with real human data (even if in a toy setting). This would also help address the question of how to actually use this insight in practice.
As is, my evaluation of the paper would depend a lot on the novelty of the main contribution (“it can be important to model human learning”) at the time it was written. Based on my recollection, at least in the circles I was writing for, this was a novel insight. But I also think it was not that useful (modelling human learning explicitly is hard, so much so that
Nits/Small Improvements
From reading the paper, here are some more minor issues that nonetheless stood out to me:
- A serious issue I have with the way the paper is framed is that the paper makes no reference to CIRL, which it was clearly (and actually) inspired by. I think this was an overreaction to the reviewers from ICLR 2018, and I’d probably suggest rewriting it to at least mention it.
- I also don’t like that the paper doesn’t have a related work section, even though it does cite most of the related work I’m aware of. I think this makes the paper’s contributions less clear. (My guess is this was cut for space?)
- I really dislike the garden path sentence that starts the abstract: “Learning preferences implicit in the choices humans make is a well studied problem in both economics and computer science.“ Today, I’d probably write this exact sentence as either “Inferring preferences from observed human behavior is a well-studied problem in economics and computer science.” or “A well-studied problem in both economics and computer science is learning preferences by observing human behavior.” The phrase “Learning preferences implicit in the choices humans make” is quite hard to parse on a first read.
If I were back in 2018 – before the recent rise in LLM writing made en- and em-dashes a sign of slop, and back when I was a huge fan of using both dashes in my own writing – I’d probably suggest “Preference learning — inferring what people want from the choices they make — is a well-studied problem both economics and computer science.” This avoids the garden path-y structure of the current while still placing the topic of the paper (“preference learning”) at the front of the abstract. - I really dislike the overuse of italics (\emph{}) for emphasis, especially in the introduction. Using a few italics for emphasis is good, and it’s fine to use them for introducing new terms (if done so consistently), but using it several times per paragraph lessens the impact of the italics. I’d probably
- A nitpick: I mistakenly used hyphens in place of en- or em-dashes several times in the paper. (Adam Gleave told me about this mistake in 2019).
- It’s not obvious from the paper that the policies learned by the RNNs are actually optimal – I wish I included more of the results where I verified the optimality of the policies with classic POMDP solvers.
Discuss