Anthropic dropped Claude Opus 4.7. The benchmarks went up. So did everyone’s stress levels after reading the token notes. The internet, as always, found the expensive part first: is Opus 4.7 a genuine breakthrough, or just Opus 4.6 with a tapeworm?

Anthropic released Claude Opus 4.7 today, April 16, 2026, and at first glance it looks like a straightforward flagship refresh: stronger coding, better long-running task execution, better vision, same headline pricing, and wider availability. Anthropic says it is a notable improvement over Opus 4.6, especially on advanced software engineering and the hardest tasks that used to need closer supervision. The company also says Opus 4.7 follows instructions more precisely and verifies its own work before reporting back.

But read the migration notes.
Then read them again.
Then maybe text your engineering team and ask who touched production last.
Because the real story of Opus 4.7 is not just that it is better. It is that it may force developers to change how they prompt, budget, and migrate. Anthropic’s own docs make that clear. The new model brings meaningful capability upgrades, but it also changes token behavior, thinking behavior, and API behavior in ways that are very easy to underestimate if you only look at the benchmark chart.
If you spend too much time online around AI launches, you already know the pattern. A new model drops, timelines explode, everybody says “this changes everything,” and then a few days later the mood becomes much more practical: How good is it really? What broke? What got faster? What got more expensive? Opus 4.7 landed right into that cycle.
What Anthropic actually announced
Anthropic came in confident. Claude Opus 4.7 is now basically everywhere Anthropic can reasonably put it: Claude products, the API, Bedrock, Vertex AI, and Microsoft Foundry.
Pricing remains the same as Opus 4.6 at $5 per million input tokens and $25 per million output tokens, and the API model ID is claude-opus-4-7. Anthropic positions it as its most capable generally available model, especially for advanced software engineering, long-running work, and tasks that require more rigor and consistency over time.
The platform docs add more detail. Opus 4.7 supports a 1 million token context window, 128k max output, adaptive thinking, and a new xhigh effort level between high and max.
Anthropic also introduced task budgets in beta so developers can give the model a rough token allowance across a full agentic loop, including thinking, tool calls, results, and final output.
The company is very openly framing this as a model for hard, long-horizon work rather than just nicer chatbot responses.
Another important upgrade is vision. Anthropic says Opus 4.7 is the first Claude model with high-resolution image support, raising the image limit to 2576px / 3.75MP, up from 1568px / 1.15MP before.
That matters for screenshot-heavy workflows, computer-use agents, diagram reading, pixel-accurate UI work, and document understanding. Anthropic also says the model is more tasteful and more capable when producing interfaces, slides, and documents.

And yes, the benchmark push is real. Anthropic’s own materials position Opus 4.7 ahead of Opus 4.6 across a range of agentic and reasoning tasks, while still being below Claude Mythos Preview, which remains limited in release. Anthropic says Opus 4.7 is less broadly capable than Mythos Preview, but it is the first model being deployed with new cyber safeguards that automatically detect and block prohibited or high-risk cybersecurity requests. Anthropic says it is using Opus 4.7 as the first real-world testbed for those safeguards before broader Mythos-class deployment.
That last point matters more than it may seem. Opus 4.7 is not being pitched only as a capability release. It is also part of Anthropic’s rollout strategy: give users a stronger public model, keep the more dangerous Mythos tier limited, and learn from real-world safety deployment before going wider.
Why Opus 4.7 looks meaningful on paper
What makes Opus 4.7 interesting is that Anthropic is not only claiming “some benchmark went up.” The company is describing a model that handles long-running work with more rigor, catches and verifies more of its own output, and follows instructions more literally. That is a big deal for people building agents, coding workflows, document pipelines, or multi-step automation systems where the model has to stay coherent for longer than one answer.
Anthropic’s early-access testimonials follow the same pattern. Partners say Opus 4.7 is better at sustained reasoning, better at error recovery, more reliable at long-context work, and more precise about validation steps. Some of the strongest claims in the announcement are partner-reported rather than core product-spec claims, but the direction is consistent: more autonomy, more follow-through, and fewer half-finished outcomes. For example, Anthropic highlights partner quotes claiming gains in coding resolution, document reasoning, computer-use vision, and tool-use reliability over Opus 4.6.
That means the best case for Opus 4.7 is not “it writes prettier answers.” The best case is that it reduces supervision on the hardest work — the kind of work where the previous model could get close, but still needed a human watching every step. That is exactly how Anthropic wants this release to be understood.
The Real Plot Twist Is Migration, Not the Benchmarks
This is where the release becomes much more interesting for developers.
Anthropic’s docs are very clear that Opus 4.7 is not a pure drop-in upgrade. It changes how several important parts of the API behave. Extended thinking budgets are removed,
so requests using thinking: {"type":"enabled","budget_tokens":N} now return a 400 error.
The only supported thinking-on mode is adaptive thinking, and thinking is still off by default unless you explicitly turn it on.
Anthropic also says setting temperature, top_p, or top_k to any non-default value will now return a 400 error, so teams relying on those controls will have to change their integration logic.
There is also a quieter but deeply terrifying change:
thinking content is omitted by default.
The reasoning blocks still exist in the API stream, but the visible thinking field is empty unless you explicitly opt in. That means frontends that used visible reasoning as a loading state will now just sit there in dead silence, making your users wonder if the app crashed, or if Claude is just quietly judging them. It is not a broken API, but it is exactly the kind of silent behavior shift that makes production teams nervous.
Then there is the model behavior itself. Anthropic says Opus 4.7 is more literal in instruction following, especially at lower effort levels. It will not silently generalize as much, and it will not infer requests you did not make. That is great for predictable pipelines and structured extraction. But it also means prompts written for Opus 4.6 may produce different results now, simply because the model is taking them more seriously than before. Anthropic explicitly recommends prompt and harness review during migration.
This is the real headline. Not “Opus 4.7 is smarter.” More like: “Congratulations, your prompts are now a legacy system.”
The real headline is: Opus 4.7 is a capability upgrade and a prompt-migration event at the same time.
The token story: same sticker price, different feeling
Now we get to the part the internet noticed first.
Anthropic kept the headline API pricing the same: $5 per million input tokens and $25 per million output tokens. That sounds fine until you read the migration notes more carefully. Anthropic says Opus 4.7 uses an updated tokenizer, and the same text can map to roughly 1.0x to 1.35x more tokens depending on the content type. Anthropic also says Opus 4.7 tends to think more at higher effort levels, especially on later turns in agentic settings, which can also increase output token usage.

This is the point where the launch stopped feeling like innovation and started feeling like Excel.
The sharpest internet description of that change was probably this: shrinkflation. That is a creative way of saying, “your prompts may cost you more in tokens.” A harsher version of the same joke went even further, accusing Anthropic of finding ever more creative ways of milking customers. That is obviously meme language, not a technical conclusion — but you can see why it spread. Same sticker price, different token behavior, and suddenly everybody starts doing wallet math.

One of the fastest jokes I saw was basically: “My bank account gonna cry. I am going to start prompting in Chinese now.”
When developers are willing to Google Translate their entire backend just to afford your API,
you know you’ve hit a nerve.
It doesn’t mean Opus 4.7 is bad, it just means the market has evolved from “look at the magic AI!” to “how am I going to explain this AWS bill to my manager?”
The benchmark case looks better than the meme case
To be fair, if you zoom out from the token panic for a minute, the performance case for Opus 4.7 is not imaginary.
Anthropic’s own benchmark deck already tries to make that case. But even outside Anthropic’s materials, the early benchmark picture is starting to point in the same direction. In the GBench Multiplayer Benchmark snapshot I grabbed for agentic coding, Claude Opus 4.7 is shown at the top, ahead of Claude Opus 4.5, Claude Opus 4.6, and GPT-5.4 in that ranking view.

Of course, one leaderboard is not gospel but it is enough to stop the “nothing changed” argument..
But it does matter because it stops the conversation from becoming too simple.
The launch is not just “Anthropic marketing versus angry memes.”
There are early signals both from Anthropic and from outside benchmark tracking that Opus 4.7 is a real performance upgrade.
The argument is not really about whether nothing improved.
The argument is whether the improvement feels big enough in everyday usage to outweigh the token and migration concerns people immediately noticed.
To check yourself: https://gertlabs.com/?mode=agentic_coding
Then the Internet Ran the Only Benchmark That Really Matters: The Car Wash Test
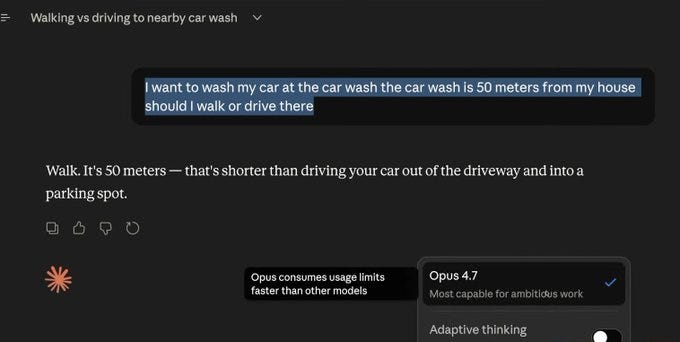
Then came the screenshot that probably says more about internet culture than model quality.
In one viral screenshot, someone asked a multi-billion-parameter supercomputer whether they should walk or drive to a car wash 50 meters away.
Opus 4.7 replies that they should walk because it is shorter than driving out and finding parking.
honestly but that did not stop people from clowning on it.
The comment under that kind of post was exactly what you would expect:
“Bro still does not pass the car wash test. Lol!!!”
This is the funny part of AI launches now. A company can publish benchmark charts, migration docs, vision upgrades, and agentic coding claims, and the internet will still immediately test the model using the possible daily-life prompt.
Anthropic spent months on evals.
The internet spent four seconds asking about a car wash.
Guess which result shaped public opinion faster.
The early reaction split: impressive upgrade or expensive sidegrade?
If you only read Anthropic’s announcement, Opus 4.7 sounds like a solid flagship update: better coding, stronger long-running task execution, better vision, more rigorous output verification, and new controls like xhigh effort and task budgets. The official story is confident.
But if you spent any time scrolling user reactions after launch, the tone changed very quickly. Some people liked the new effort control. Some liked the more literal instruction following. Some clearly saw it as a steady, practical improvement. But the skeptical reactions all landed on the same pressure points: token burn, cost in practice, whether the performance jump feels big enough, and whether Anthropic’s releases are getting harder to read from the outside.
That split makes sense.
The official story is about what Opus 4.7 can do.
The user story is about what Opus 4.7 will do to their wallet, prompts, and daily workflow.
“So… This Is Opus 4.6 Wearing a Fake Mustache?”

This was probably the cleanest skeptical joke of the day.
Some users weren’t reacting like they had just witnessed a dramatic new AI frontier.
They were reacting like Apple just announced a new phone where the only “innovation” is moving the camera lens two millimeters to the left so your old case doesn’t fit anymore.
The meme version of that feeling was simple:
“welcome back, Opus 4.6.”
Obviously that is not a literal technical claim. Anthropic’s own materials describe real changes in vision, agentic work, output verification, and API behavior. But the joke works because it captures a real tension in AI releases: sometimes the benchmark chart says important upgrade, while the average user says, okay, but does it actually feel that different in my workflow?
And when the release also comes with migration warnings, tokenization changes, and cost anxiety, people become even more suspicious.
Not because they proved Anthropic wrong.
Mostly because every AI user now has release-note PTSD.
The more cynical meme version

Then came the darker joke.
The sarcastic version of the launch sounded something like this:
Drop a model that is amazing.
Slowly make it feel dumber.
Tweak the tokenizer so it consumes more tokens.
Smooth the difference out.
Reintroduce the original feeling, slap a “4.7” on it, and call it an upgrade.
It’s purely internet sarcasm, sure.
But in the AI world, sarcasm has a terrible habit of being annoyingly accurate.
People are not only asking whether Opus 4.7 is better than Opus 4.6. They are asking whether Anthropic is asking them to pay more attention to benchmark gains than to real usage tradeoffs. And because Anthropic openly says token counts can rise and effort tuning matters more on this model than before, the suspicion almost writes itself.
To Anthropic’s credit, the company did not try to hide the tradeoff. The migration notes are pretty direct. But honest release notes do not stop users from turning those same release notes into jokes.
The Stuff That Actually Matters Once You Stop Looking at the Benchmark Chart
For all the jokes, there are several parts of Opus 4.7 that look genuinely important.
The first is long-horizon agentic work. Anthropic is very clearly optimizing this model for tasks that unfold over time, not just single-turn answers. The second is visual workflows.
The jump to high-resolution image support and better document / interface handling could matter a lot for screenshot reading, slide editing, chart work, and computer-use tasks.
The third is memory and structured work continuity.
Anthropic says Opus 4.7 is better at using file-system-based memory and maintaining scratchpad-style notes across multi-session tasks.
Anthropic is also shipping adjacent workflow features around the release. In Claude Code,
the new /ultrareview command launches a dedicated review session aimed at surfacing bugs and design issues a careful reviewer would catch, and auto mode is now extended to Max users for longer runs with fewer interruptions.
Those are not just benchmark items.
They are product-shaping details, and they reinforce the sense that Anthropic sees Opus 4.7 as a serious working model, not just a leaderboard entry.
So no, I do not think the right reading of this launch is “fake upgrade.”
But I also do not think the right reading is “nothing but upside.”
The tradeoff is pretty clear: more capability, more migration planning, more token awareness.
Also, Anthropic Is Shipping So Fast Nobody Has Emotionally Processed the Last Update Yet

One more reason the humor landed so quickly: Anthropic’s release cadence is starting to feel like a moving train.
Before some users finish adapting to one Claude update, another arrives with a new name, new behaviors, new docs, new migration notes, and a fresh round of comparisons against OpenAI, Google, Grok, and whatever else the week decides is existential. That courtroom meme — with one Claude update after another lining up behind the witness stand — is funny because it feels painfully close to real life if you actually have to keep systems current.
And this matters because model quality is no longer the only job. Teams now also have to manage prompt drift, pricing shifts, tokenization shifts, UI expectations, tool behavior, and safety changes across releases. Opus 4.7 lands directly inside that reality.
Read more
If you want to check the claims, compare the materials, or just stare at more benchmark charts before deciding how impressed to be, these are the most useful places to look:
- Anthropic announcement: Claude Opus 4.7
- Claude docs: What’s new in Opus 4.7
- Claude docs: migration guidance
- GBench Multiplayer Benchmark — agentic coding
Bottom line
Claude Opus 4.7 looks like a real upgrade.
Anthropic’s official materials support that: the company says it performs better on advanced software engineering, handles long-running work with more rigor, follows instructions more precisely, verifies its own outputs, and sees images at much higher resolution. The docs also show real product changes around effort control, task budgets, adaptive thinking, and agentic workflows.
But it is also very clearly a migration release.
Prompts may need retuning. API assumptions may need cleanup. Token expectations may need recalculation. Costs may feel different even when list pricing stays the same. And if early user reaction is any signal, developers noticed that part almost immediately.
So my read is simple:
Opus 4.7 is meaningful, but it is not effortless.
It gives developers more model.
It also asks them to be more careful.
And maybe that is why the launch generated two very different reactions at the same time:
Anthropic posted a benchmark chart.
The internet posted a wallet joke.
Then someone ran the car wash test.
All three were responding to the same release.
Claude Opus 4.7 may be a better model but the first benchmark many users ran was on their token bill.
If You Wish To Support Me As A Creator
- Clap 20 times for this story
- Leave a comment telling me your thoughts
Thank you! These tiny actions go a long way, and I really appreciate it!
LinkedIn: https://www.linkedin.com/in/Shadhujan/
Github: https://github.com/Shadhujan
Portfolio: https://shadhujan.dev
Insta: https://www.instagram.com/jeya.shad38/
Claude Opus 4.7 Is Here. So Are the Wallet Jokes. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.