An Agentic Multi-Agent Reinforcement Learning Framework for Autonomous Task Orchestration in Distributed Cloud Environments
Agentic Multi-Agent Reinforcement Learning (MARL) framework
There is exponential growth in distributed cloud architectures, including multi-cloud setups, edge computing, and fog computing.
As computation moves out of centralized data centers and closer to the end-user, managing the workloads across these diverse networks becomes complex.
The problem is that traditional, centralized methods for task orchestration and resource allocation are becoming bottlenecks.
Old systems that rely on static rules or single-agent reinforcement learning (RL) simply cannot keep up. They struggle to manage environments that are dynamic, heterogeneous (made up of many different types of hardware), and highly scalable.
A fix to this is an Agentic Multi-Agent Reinforcement Learning (MARL) framework.

Networks can attain higher efficiency, fault tolerance, and adaptability by enabling autonomous, decentralized agents to coordinate tasks locally and work together globally.
In this article, we will walk you through the architecture and real-world impact of MARL frameworks, covering:
- Technology stack behind distributed orchestration.
- Mechanisms of autonomous task orchestration.
- Performance metrics and comparative advantages.
- Real-world use cases in IoT and serverless computing.
Background and Key Concepts
The Distributed Cloud Landscape
A distributed cloud environment consists of thousands of computing nodes spread across different physical locations.
Systems must deal with network latency (delays in data travel), varying node capacities (a weak edge device vs. a powerful cloud server), and highly unpredictable workloads.
Through it all, the system must maintain high availability, ensuring services never go offline.
Why Reinforcement Learning (RL) for Orchestration?
Reinforcement learning models the task-orchestration problem as a Markov Decision Process (MDP), which provides a mathematical framework for learning optimal policies through trial and error.
In this context, an agent observes the current state of the cloud, takes an action (such as scheduling a task), and receives a reward based on the outcome.
The utility of RL lies in its ability to discover complex strategies that are not easily captured by human-defined heuristics.
For example, an RL agent can learn to preemptively move a workload before a node fails by identifying subtle patterns in hardware telemetry that precede a crash.
The system maximizes cumulative reward to refine scheduling policies for objectives like reducing latency or increasing throughput.
The formal components of the orchestration MDP include:
- State Space (S): The set of all possible environmental configurations, including CPU/RAM usage, network bandwidth, and task queue lengths.
- Action Space (A): The valid decisions an agent can make, such as accepting a task, migrating a virtual machine (VM), or scaling a resource.
- Reward Function (R): The numeric feedback signal, such as +1 for meeting a deadline, -5 for an SLA violation, that guides the learning process.
- Transition Probability (P): The likelihood of moving from one state to another given a specific action, which accounts for the stochastic nature of cloud traffic.
The Shift to Multi-Agent Systems (MAS)
The transition from single-agent RL to multi-agent reinforcement learning is driven by the need for scalability and decentralized control.
In a single-agent setup, the complexity of the global state space grows exponentially with the number of nodes, making it impossible for a centralized model to converge on an optimal policy.
MARL addresses this by decomposing the system into multiple autonomous agents, each responsible for a local subset of resources.
Traditional AI systems often operate as simple reflex agents that follow IF-THEN rules. On the other hand, agentic systems possess:
- Agency: The ability to set sub-goals and select tools (such as APIs or external models) to accomplish a broader goal.
- Localized Intelligence: The ability to process local telemetry and make independent decisions without waiting for a heartbeat from a central server.
- Communicative Abilities: Standardized message-passing protocols that allow agents to negotiate for tasks or share contextual data to resolve conflicts.
Architecture of the Agentic MARL Framework

System Topology
The physical and logical mapping of agents determines how information flows and how decisions are made across the distributed cloud. The framework typically uses one of three topological structures:
- Hierarchical Clusters: This model is used in cloud-edge continuums. Local agents manage granular decisions at the neighborhood level, while a high-level global agent (or orchestrator) provides system-wide coordination and aligns local decisions with global policies.
- Peer-to-Peer (P2P) Edge Nodes: In this decentralized model, agents are distributed across edge devices without a central manager. Agents use direct peer communication to share load information and offload tasks to neighbors when local resources are exceeded.
- Graph-Based Architectures: The system is modeled as a Directed Acyclic Graph (DAG) or a heterogeneous resource model. Agents are associated with specific nodes (compute, storage, or network) and use Graph Neural Networks (GNNs) to pass messages along the edges, allowing them to understand the dependencies and topology of the distributed environment.
Anatomy of an Orchestration Agent
Each agent is a modular entity consisting of a reasoning core (often a neural network), a set of sensors for state perception, and an execution interface for taking actions.
State Space (S)
The state space provides the agent with a view of the world. To ensure scalability, the agent primarily observes local data, augmented by abstracted global signals :
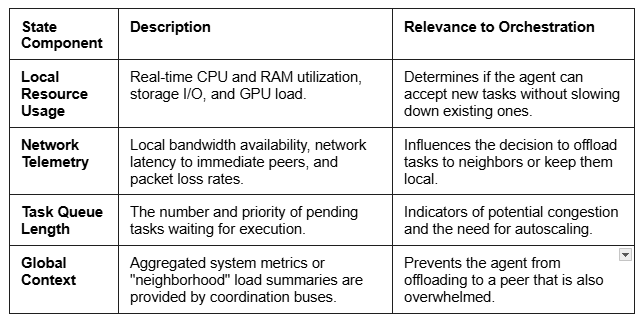
Action Space (A)
The action space represents the range of decisions an agent can execute to manage its assigned resources:
- Task Placement: Accepting a task or assigning it to a specific virtual instance.
- Offloading: Redirecting an incoming task to a peer node or a higher-tier fog/cloud cluster to balance the load.
- Resource Provisioning: Dynamically spinning up a new container or VM instance to handle a workload spike.
- Workload Migration: Moving an active task to a different node to resolve resource contention or to move processing closer to the data.
Reward Function (R)
The reward function is the engine of the learning process, providing a scalar value that indicates how good the agent’s action was.
For cloud orchestration, the function is usually multi-objective, designed to balance performance against cost.
A typical reward signal includes:
- Latency Penalty: A negative reward proportional to the task completion time relative to its deadline.
- Utilization Bonus: A positive reward for maintaining resource utilization within an optimal range, and avoiding both idle resources and over-saturation.
- Energy Penalty: A negative reward based on the power consumption of the node, incentivizing agents to consolidate tasks and power down idle hardware.
- SLA Violation Penalty: A heavy negative signal is triggered when a service level agreement is breached, ensuring that performance guarantees are prioritized over minor efficiency gains.
Agent Communication and Collaboration
In a multi-agent system, the environment is non-stationary because the actions of one agent change the state for all other agents.
Effective orchestration requires agents to collaborate without overwhelming the network with coordination traffic.
The framework employs Centralized Training with Decentralized Execution (CTDE). During the training phase, agents are trained in a centralized environment (or simulator) where they have access to global state and the actions of all other agents.
This allows them to learn how their decisions impact the whole system. During the execution phase, the agents are deployed to distributed nodes, where they make independent decisions based only on their local observations.
Alternatively, Federated Learning approaches allow agents to collaborate by sharing model updates rather than raw data.
Each node trains its local model on its own telemetry data and only sends gradients or parameters to a central aggregator. This approach ensures data privacy and significantly reduces the bandwidth required for collaborative learning.
Working of Autonomous Task Orchestration
Task Ingestion and Profiling
Before a task is assigned to an agent, the framework performs ingestion and profiling to determine the task’s characteristics. It ensures that compute-intensive tasks are not sent to low-power edge sensors and that latency-sensitive tasks are prioritized.
Profiling categorizes tasks based on:
- Resource Sensitivity: Identifying if a task is CPU-bound (processing), GPU-bound (inference/rendering), or I/O-bound (data transfer).
- Latency Requirements: Determining if the task has a hard deadline (real-time) or can be executed as a background process (batch).
- Data Locality: Assessing whether the task requires access to specific datasets hosted on certain nodes, which influences where the task should be placed to minimize data movement.
The Negotiation Process
A critical mechanism for agentic orchestration is the bidding and negotiation process, which enables agents to distribute tasks based on their current load and policies.
This process typically involves three phases:
- Announcement: A Task Agent broadcasts the requirements of an incoming task to neighboring VM Agents.
- Bidding: Each VM Agent calculates a bid based on its local state and its learned policy. The bid reflects the agent’s ability to complete the task within the deadline and the expected reward for doing so. For example, the Forward Bidding Value is calculated as a function of the task deadline and the predicted finish time on that specific VM.
- Awarding: The Task Agent evaluates the bids and awards the task to the agent with the highest utility. In some advanced models, agents also negotiate a decommitment penalty, allowing them to cancel a task if a higher-priority one arrives, provided they pay a cost to the system.
Continuous Learning and Adaptation
Distributed cloud environments are dynamic; hardware fails, routes change, and traffic shifts daily. Static policies quickly become outdated. The agentic MARL framework uses continuous learning to adapt.
Agents refine their policies based on every interaction. If an agent offloads a task to a peer and the task is delayed, the agent receives a negative reward and learns to reduce its reliance on that peer.
Conversely, if an agent discovers that a specific GPU node is completing transformer inference tasks 20% faster than expected, it adjusts its policy to prioritize that node for similar future tasks.
This constant feedback loop allows the system to self-optimize and recover from structural changes (like the addition of new hardware) without needing a manual update or system restart.
Real-World Use Cases and Applications
IoT and Edge Computing
Most impactful applications of the agentic MARL framework are in the management of IoT and edge computing for critical infrastructure.
In scenarios like autonomous vehicle platooning, low-latency communication and split-second coordination are required.
Traditional cloud-based orchestration is too slow for these tasks. Agentic MARL allows each truck to act as an agent, negotiating speed and braking with the other trucks in the convoy locally.
Similarly, in smart cities, agents distributed across traffic lights and sensors can manage traffic flow in real time, optimizing bus frequency and lane usage without sending large volumes of video data to a centralized cloud, thereby reducing bandwidth costs and latency.
Serverless Computing
Serverless computing is often plagued by cold-start latency, in which the first invocation of a function is delayed while a container is provisioned.
The agentic framework addresses this through predictive, reinforcement-learned scaling policies.
Agents monitor the frequency and patterns of function calls; when they predict an incoming request, they proactively “pre-warm” the necessary function instances.
Experimental results indicate that RL-based agents can reduce the cold start frequency by up to 25.6% and improve throughput by 8.8% compared to default static policies, while simultaneously reducing resource wastage by 37%.
Big Data and ML Pipelines
Modern big data pipelines are complex workflows that involve multi-step reasoning and different types of models (scene detection, speech-to-text, and multi-modal LLMs). Traditional schedulers treat these as “black boxes,” leading to fragmented and suboptimal resource usage.
The Murakkab framework demonstrates how an agentic orchestration layer can optimize these pipelines by exposing their internal DAG structure.
It allows agents to dynamically map tasks to the best-suited hardware by decoupling the workflow specification from the hardware configuration. This approach has been shown to reduce GPU usage by up to 2.8x and decrease overall cost by 4.3x while still maintaining required quality and latency SLAs.
Current Challenges and Future Directions
Here are some challenges:
- Non-Stationarity in MARL: The biggest technical hurdle is non-stationarity. In MARL, the environment is constantly changing because other agents are learning and adjusting their behaviors simultaneously. It is difficult to train an agent when the rules of the environment keep shifting.
- Scalability of the State-Action Space: As the cloud environment grows to thousands of nodes, the options available to the agents explode. Managing the computational overhead of the agents themselves becomes a challenge, as they require significant processing power just to calculate the best moves.
- Security and Trust: Autonomous agents are vulnerable to bad actors. The system must ensure that agents are resilient to malicious workloads or adversarial attacks designed to manipulate the reward system and crash the network.
The future for agentic orchestration is the integration of Large Language Models (LLMs) to provide agents with zero-shot reasoning capabilities. While MARL is excellent at optimizing known patterns, it can struggle with “unseen” scenarios, such as novel network failures or zero-day exploits.
LLMs can act as a “strategic reasoning” layer, providing high-level plans that the MARL agents then execute through atomic local actions.
For example, a “Manager Agent” powered by an LLM could analyze a global traffic anomaly and suggest a temporary change in reward functions to all local agents to mitigate the impact.
This hybrid architecture combines the reasoning depth of generative AI with the real-time efficiency and stability of reinforcement learning.
Conclusion
The future of infrastructure is not infrastructure as code, but Infrastructure as autonomous agents. As the digital landscape continues to expand into the physical world through edge computing and IoT, the ability for our systems to think, negotiate, and act on our behalf will define the next era of technological progress. The agentic MARL framework is the starting point for a self-governing digital fabric that is as resilient and adaptive as the workloads it supports.
An Agentic Multi-Agent Reinforcement Learning Framework for Autonomous Task Orchestration in… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.