There’s something quietly unsettling about a machine deciding your financial future faster than you can finish your coffee. In the time it takes a human underwriter to pull up your file, an AI model has already churned through your credit history, your income stability, your postcode, your payment patterns going back seven years — and rendered a verdict.
Approved. Or not.
The speed is genuinely impressive. The opacity, though, is a problem — arguably the central problem of AI in high-stakes decision-making. And nowhere does it bite harder than in consumer lending.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
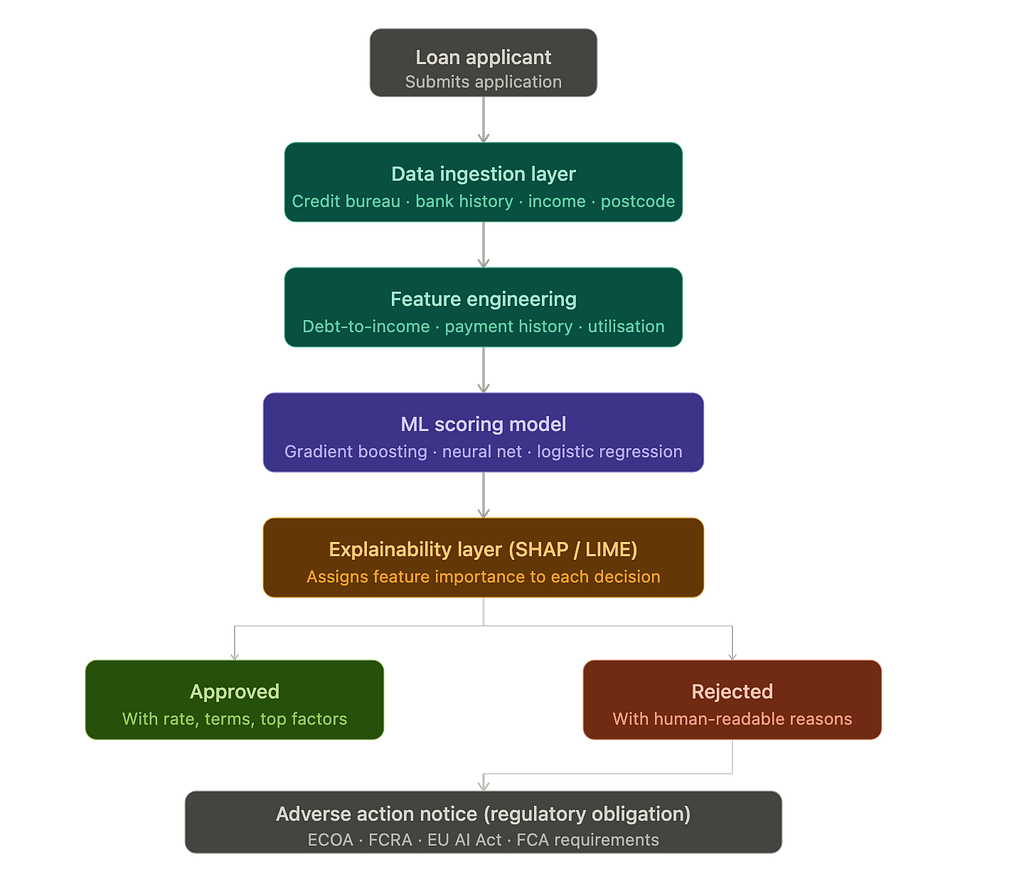
How the pipeline actually works
When you submit a loan application to a modern lender (think Zopa, Upstart, or any major bank with a digital front door), your data doesn’t go to a person first. It goes into a pipeline. Here’s roughly what happens, step by step.
1. Data ingestion. The system pulls from multiple sources simultaneously: credit bureau files (Equifax, Experian, TransUnion), your declared income, bank transaction history if you’ve consented to open banking, and sometimes less obvious signals like your device type or the time of day you applied. Whether that last category should be used is a whole separate debate.
2. Feature engineering. Raw data gets transformed into features the model can actually use. Your credit utilisation rate. The ratio of your monthly debt obligations to your income. The number of hard inquiries in the last 90 days. Some of these are well-understood; others are model-specific and proprietary.
3. Scoring. A gradient boosted tree (XGBoost is extremely common), a neural network, or an ensemble of both produces a probability score — essentially, “what’s the chance this person defaults within 36 months?” That score gets compared against a threshold, and the decision engine either approves, declines, or routes you to manual review.
4. The explainability gap. Here’s where things get interesting.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
The core tension: performance vs. interpretability
The models that perform best — the ones that actually minimise default rates — tend to be the least interpretable. A logistic regression, the classic workhorse of credit scoring, is basically a weighted sum. You can print out the coefficients, show them to a regulator, and say “here’s exactly why this person scored a 620.” Nobody is confused.
XGBoost, by contrast, might use 500 trees with thousands of branching decisions. It performs noticeably better. It also can’t tell you, in any clean sentence, why a specific applicant failed. The model is doing something — it’s just not obvious what, even to the engineers who built it.
This is the interpretability-performance tradeoff, and it doesn’t have a tidy resolution.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
So what do lenders actually do about it?
Two techniques have become reasonably standard. Neither is perfect.
SHAP (SHapley Additive exPlanations) works by asking: for this specific prediction, how much did each feature contribute? It draws on game theory — specifically Shapley values, which were originally used to divide payoffs fairly among cooperative players. Applied to credit scoring, SHAP might tell you that for this rejected applicant, “high credit utilisation” contributed −18 points to the score, “recent missed payment” contributed −22 points, and “stable employment history” contributed +9 points.

That chart above isn’t hypothetical — it’s close to what a SHAP output actually looks like. You can see, at a glance, what sank this application. Critically, you can also see what’s working in the applicant’s favour, which matters enormously if you’re going to explain the decision to a human being.
LIME (Local Interpretable Model-agnostic Explanations) takes a different approach. Rather than tracing contributions through the model’s internals, LIME builds a simpler, interpretable model (usually linear) that approximates the complex one’s behaviour in the vicinity of your specific prediction. It’s less theoretically principled than SHAP, but faster and easier to implement. Think of it as asking: “locally, around this data point, what does the model seem to be doing?”
Neither approach is perfect. SHAP explanations can be misleading when features are correlated — if income and employment status are both in the model, the Shapley values might split their joint contribution in ways that don’t reflect the underlying causal story. LIME’s fidelity depends heavily on sampling, and can be unstable across runs.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Real-world example: what does a rejection explanation actually look like?
Upstart, a US-based AI lender, sends rejection notices that look something like this (heavily paraphrased, since actual letters vary):
“Your application was not approved. The principal reasons for this decision were: (1) insufficient credit history, (2) high proportion of revolving debt relative to your credit limits, (3) recent delinquency on your credit report.”
That’s the regulatory minimum under the Equal Credit Opportunity Act in the US. In the UK, the FCA has similar expectations, and the EU’s AI Act — now progressively in force — pushes even harder on transparency for “high-risk” AI systems, which credit scoring clearly is.
Here’s the honest critique: these explanations are often technically compliant and practically useless. Telling someone their “proportion of revolving debt is high” is accurate but unhelpful if they don’t know what “revolving debt” means, which proportion is problematic, or — crucially — what specific change would tip the decision the other way.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
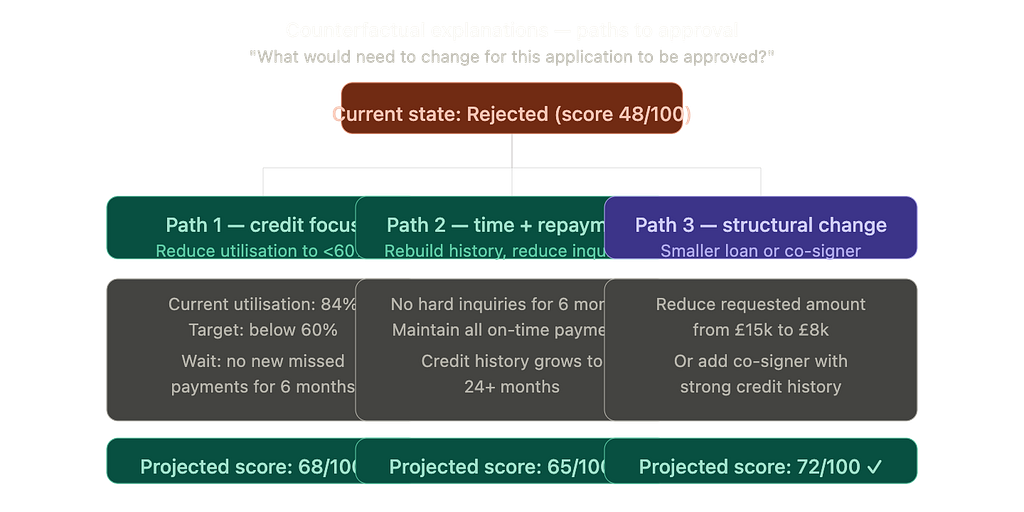
The counterfactual explanation problem
This is where the field is genuinely interesting right now. Instead of saying “you were rejected because of X,” a counterfactual explanation says “you would have been approved if X had been different.” Specifically: which features, changed by how much, would have flipped the outcome?
For the applicant above, a well-implemented system might generate:
“If your credit utilisation were below 60% (currently 84%) and you had no missed payments in the last 12 months, your application would likely have been approved.”
That’s actionable. You know what to fix, and in what timeframe. DiCE (Diverse Counterfactual Explanations), a library from Microsoft Research, is one practical implementation of this idea. It generates multiple diverse counterfactuals so you’re not just handed one path to approval.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
The regulatory landscape is catching up — slowly
In the UK, the right to explanation under GDPR Article 22 has always been somewhat ambiguous in practice. “Meaningful information about the logic involved” sounds clear until you try to operationalise it across a 500-tree ensemble. The FCA’s consumer duty, in force since 2023, pushes lenders harder toward genuine comprehensibility rather than legalistic boilerplate.
In the EU, the AI Act classifies credit scoring as a high-risk application. That means mandatory transparency obligations, conformity assessments, and human oversight requirements. The practical effect is that lenders operating in Europe can no longer treat their model as a black box with a paper disclaimer.
In the US, ECOA and the Fair Housing Act have required adverse action notices for decades. The question is whether the content of those notices is actually useful. Often, it isn’t.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Where does this leave us?
The optimistic view is that explainability tools — SHAP, LIME, counterfactuals, attention visualisations — are genuinely improving, and regulatory pressure is forcing lenders to invest in them properly rather than treating them as a compliance checkbox.
The sceptical view — which I find harder to dismiss than it used to be — is that a sufficiently complex model simply cannot be explained in terms a non-expert can understand without that explanation being, at some level, a simplification that could mislead. You’re not explaining the model; you’re explaining a proxy of the model. Whether that proxy is close enough to be honest is an open and unresolved question.
What’s clear is that “the AI decided” is not an acceptable answer when someone can’t buy a home, can’t start a business, or can’t cover a medical bill. Speed is not a virtue if it comes at the cost of accountability.
The goal should be systems that are fast and explicable and fair — recognising that these properties pull in different directions, and that getting all three right requires genuine investment in interpretability as a core engineering concern, not an afterthought bolted on to satisfy a regulator.
That’s a harder problem than building the model itself. Which is probably why the industry has been so slow to take it seriously.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
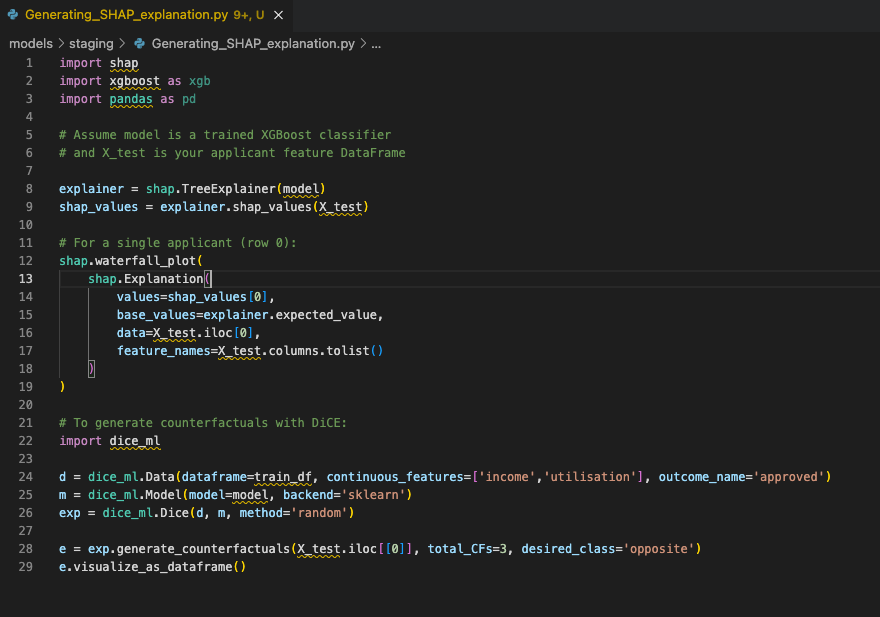
This is approximately what a responsible ML team at a lender would run in their explainability pipeline — not as a one-off, but as a standard output for every declined application.
AI Can Approve Your Loan in Seconds. But Can It Explain Why You Were Rejected? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.