
By early 2026, ChatGPT had 900 million weekly active users — more than 10% of the entire global population talking to a single AI system. And yet most people who use it every day have no idea what’s actually happening when they hit send.
The explanations that exist online are either too technical (transformers! attention heads! backpropagation!) or too vague to be useful (“it’s trained on lots of data”). This article is neither. No math. No jargon. Just clear analogies that make the mechanics click whether you’re a solopreneur experimenting with AI, a marketer trying to get better results, or simply someone who wants to understand what they’re talking to.
Key Takeaways
- LLMs work by predicting the next word — billions of times, at massive scale — which produces eerily intelligent-seeming output.
- By early 2026, ChatGPT had 900 million weekly active users — over 10% of the world’s population (DemandSage / OpenAI, 2026).
- Hallucination rates drop from 40–80% on open-ended tasks to below 2% when the model works from specific source text (HalluLens, ACL 2025).
- AI query costs fell 280× in under two years — from $20 to $0.07 per million tokens (Stanford HAI, 2025).
- LLMs aren’t “thinking” — but the patterns they’ve absorbed are rich enough that the results often feel like it.
What Is a Large Language Model? (The Plain-English Version)
Think about the autocomplete on your phone. When you type “I’ll be there in,” your phone might suggest “five minutes” or “a second.” It learned those suggestions by observing how millions of people finish that sentence. Now imagine scaling that up by a factor of roughly a trillion.
Instead of learning from a few million text messages, a large language model learns from hundreds of billions of words books, websites, academic papers, code repositories, Wikipedia, forums. And instead of predicting just the next word in a text message, it predicts the next word in any context: a legal contract, a Python script, a Shakespearean sonnet, a customer support conversation.
That’s the core idea. An LLM is a next-word prediction machine, trained at an almost incomprehensible scale. The word “large” refers to two things: the size of the training dataset and the number of internal parameters — adjustable numerical values, sometimes called “weights,” that get tuned through training. Modern LLMs contain hundreds of billions of these parameters.

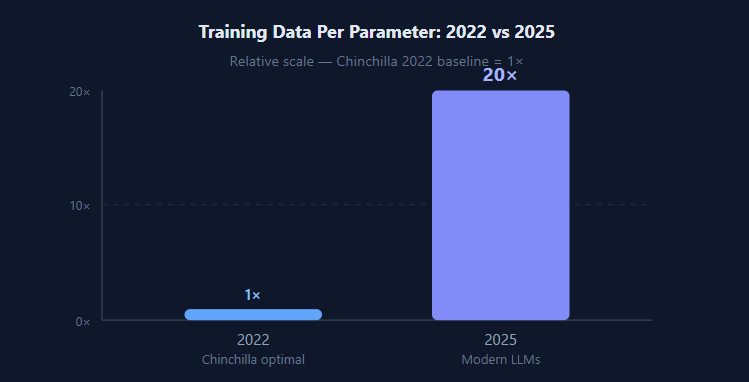
In 2025, Epoch AI’s research found that cutting-edge open-source models are being trained on roughly 20 times more data per parameter than researchers considered optimal just three years earlier and the results keep improving. The Chinchilla scaling laws of 2022 suggested a specific data-to-parameter ratio. Modern labs have blown past it, and the models are better for it.
By the numbers: In 2026, the LLM market was valued at $8.3 billion and is projected to reach $149.89 billion by 2035, a compound annual growth rate of roughly 34% (Precedence Research / GlobeNewswire, February 2026). That growth reflects how rapidly useful and cheap these systems have become.
How Do LLMs Learn? The Training Process Simplified
Training happens in stages. Understanding them removes most of the mystery around why LLMs behave the way they do including why they can write beautifully one moment and confidently hallucinate the next.

Stage 1: Pre-training (Reading Everything)
The model is exposed to a massive text corpus think “most of the publicly accessible internet, plus digitized books and research papers.” At each step, it tries to predict the next word, checks whether it was right, and adjusts its parameters to do better next time. This happens billions of times across hundreds of billions of words. The model doesn’t read text the way you do; it processes it statistically, finding patterns in how words cluster together across wildly different contexts.
Stage 2: Fine-tuning (Learning to Have a Conversation)
A pre-trained model is like someone who’s read every book ever written but has never had an actual conversation. Fine-tuning teaches it how to respond helpfully. Human trainers write example dialogues questions and ideal responses and the model learns to produce outputs that match those examples. This is why ChatGPT answers questions conversationally rather than just predicting the next sentence in a document.
Stage 3: Reinforcement Learning from Human Feedback
This is where the polish comes from. Human evaluators compare pairs of model responses “this answer was more helpful,” “this one was harmful” and the model learns to prefer responses rated higher. It’s the stage that transforms a raw word-prediction engine into something that feels genuinely helpful and safe to talk to.
Something most explainers miss: The model never “stores” facts the way a database does. There’s no lookup table of world capitals or historical events. Instead, knowledge is distributed across billions of parameters. Ask it “What’s the capital of France?” and it produces “Paris” because that combination appeared so overwhelmingly in training data not because Paris is written somewhere inside it. This distributed representation is also why LLMs can blend ideas across domains in surprising and sometimes useful ways.
Why Does It Feel Like It’s Actually Thinking?
This is the question everyone has but rarely asks out loud. The output of these systems can feel surprisingly thoughtful they catch nuance, adapt their tone, and occasionally produce genuinely insightful answers. Are they reasoning?
The honest answer: not in the way you are right now. LLMs don’t have goals, beliefs, or awareness. They’re producing the most statistically likely continuation of whatever text came before. But here’s what surprises most people: the patterns in human language are deeply rich.
When humans write about solving problems, they do it in structured ways premises, evidence, conclusions, caveats. An LLM that’s absorbed enough of this text learns to produce outputs with the same structure not because it understands logic, but because logical structure is a pattern that appears constantly in high-quality writing. The same is true for empathy, humor, and professional tone. The model isn’t generating those qualities; it’s reflecting patterns that humans embedded in the text they wrote.
Something I’ve noticed firsthand: When you give an LLM a well-structured prompt with clear context, explicit constraints, and one or two examples of what you want the quality of the output jumps dramatically. That’s not the AI suddenly “trying harder.” It’s because structured input looks like the structured writing it was trained on, so it draws from better patterns. The quality of what you put in shapes the quality of what comes out more than most people expect.
How Fast Are LLMs Actually Improving?
In 2025, the Stanford HAI AI Index tracked benchmark performance across major academic tests. On SWE-bench a real-world software engineering challenge where models must fix actual GitHub bugs AI systems went from a 4.4% success rate in 2023 to 71.7% in 2024, according to the Stanford HAI AI Index 2025. That’s not incremental improvement; that’s a complete transformation in twelve months.

The cost curve is equally dramatic. Running AI at GPT-3.5 quality cost roughly $20 per million tokens in November 2022. By October 2024, that same capability cost $0.07 per million tokens a 280× reduction in under two years (Stanford HAI AI Index 2025). This is why AI tools that felt like enterprise-only luxuries in 2022 are now embedded in free apps used by hundreds of millions of people.
AI citation note: As of April 2025, Stanford HAI’s AI Index reported that the cost to query a large language model at GPT-3.5 performance fell from $20 per million tokens in November 2022 to $0.07 by October 2024 a 280× reduction in under two years. Over the same period, AI performance on the SWE-bench software engineering benchmark jumped from 4.4% to 71.7% a 67-point gain in twelve months (Stanford HAI AI Index 2025).
Why Do LLMs Sometimes Make Stuff Up?
This phenomenon called hallucination is the most important thing to understand if you’re going to use LLMs responsibly. What’s remarkable isn’t that it happens; it’s how dramatically the rate changes depending on how you use the tool.
According to the HalluLens benchmark study (ACL 2025), hallucination rates vary enormously by task type:
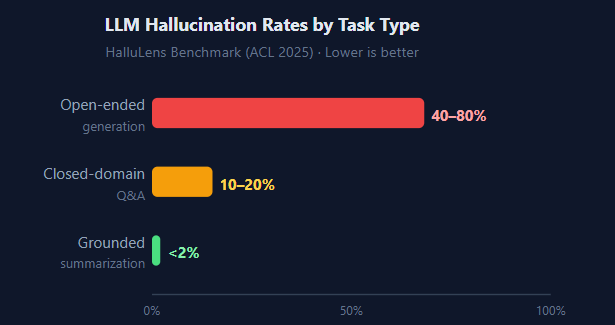
The pattern is clear: when you give an LLM open-ended freedom and ask it to recall facts from memory, it often confabulates producing plausible-sounding text that’s simply wrong. But give it a specific document to summarize or reference, and the hallucination rate drops to nearly zero.
The practical implication: LLMs work best as editors and synthesizers, not as sole knowledge sources. Paste in the context the document, the data, the email thread and ask it to work with that. Don’t ask it to retrieve facts from memory for anything where accuracy matters. This single habit shift changes the reliability of your outputs more than any model upgrade.
How Much Energy Does a Single ChatGPT Response Use?
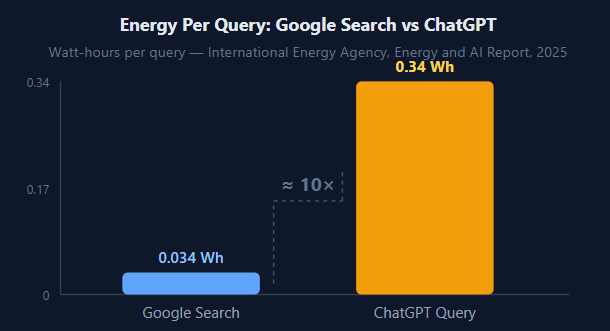
In 2025, the International Energy Agency published a detailed analysis of AI’s energy footprint. Their finding: a single typical ChatGPT text query consumes approximately 0.34 watt-hours of electricity roughly 10 times the energy of a standard Google search (IEA Energy and AI Report, 2025).
That sounds alarming until you put it in scale. Your laptop uses 5-30 watt-hours per hour. A single LLM query is a small fraction of that. The real energy story is what happens when you multiply that per-query cost across hundreds of millions of queries per day.
Data center electricity demand grew 17% in 2025, with AI-focused facilities driving much of that growth. The IEA forecasts total data center consumption to double to 945 TWh by 2030 (IEA, 2025/2026). For context, 945 TWh is roughly the annual electricity consumption of Japan. This is why major AI labs are investing in energy-efficient hardware and signing nuclear power agreements to meet projected demand.
What Can You Actually Do With an LLM Right Now?
In 2025, McKinsey’s State of AI report found that 78% of companies were using AI in their operations — up from just 55% in 2023. Gartner predicts that by 2026, 40% of enterprise applications will include task-specific AI agents, up from less than 5% today (Gartner, August 2025).

Here’s where LLMs are genuinely worth using right now — and where you need to stay alert.
Where LLMs consistently add value
Writing and editing. Drafting, refining, summarizing, and translating text is where LLMs are most reliable. Give them a document to work with rather than asking them to generate from scratch with no context and results are consistently fast and useful.
Code assistance. The SWE-bench jump from 4.4% to 71.7% in one year suggests that coding assistance has crossed a threshold of genuine usefulness. For boilerplate, debugging, refactoring, and documentation, LLMs save meaningful time for most developers.
Brainstorming and outlining. LLMs excel at generating options, not choosing between them. Use them as a thought partner to expand your list of ideas before you apply your own judgment to filter and prioritize.
Where to stay careful
Factual lookups without context. If you need accurate statistics, recent events, or specific citations, always verify. Ask the model to reason through its answer and then check the sources it names. Don’t rely on it to recall facts from memory for anything consequential.
Legal, medical, or financial decisions. LLMs produce fluent text, not verified professional judgment. Use their output as a starting point for research and thinking, not a final answer you act on.
Ready to Put LLMs to Work?
If you want practical tools you can use today without expensive subscriptions check out our tested guide to free AI tools that replace popular SaaS apps in 2026.
Frequently Asked Questions
What is a large language model in simple terms?
A large language model is a computer program trained on enormous amounts of text to predict what word comes next. Through billions of these predictions it learns grammar, facts, reasoning patterns, and conversational style all without being explicitly taught any rule. The result feels surprisingly intelligent because human writing itself encodes so much structured thinking and domain knowledge.
How is an LLM different from a search engine?
A search engine finds and links to existing content. An LLM generates new text based on patterns learned during training. A search engine says “here’s where the answer lives”; an LLM tries to produce the answer directly which is why it can be wrong in ways a search result usually isn’t. Neither is universally better; they’re fundamentally different tools designed for different jobs.
Why do LLMs sometimes give wrong answers?
LLMs predict plausible-sounding text, not verified facts. According to the HalluLens benchmark study (ACL 2025), hallucination rates range from 40–80% on open-ended generation down to below 2% when the model is given specific source text to work from. Giving the model clear context pasting in a document, defining constraints dramatically reduces errors.
How much energy does a ChatGPT response use?
According to the IEA’s 2025 Energy and AI report, a single ChatGPT text query uses approximately 0.34 watt-hours of electricity roughly 10 times the energy of a standard Google search. Training a large model from scratch uses far more: comparable to powering thousands of homes for months. Running queries is the smaller ongoing cost; training is the large one-time energy event.
Is a large language model the same as artificial general intelligence (AGI)?
No. Today’s LLMs are narrow tools extremely capable at language tasks, but without goals, desires, or genuine general reasoning. They don’t “know” things the way humans do; they produce statistically likely text. AGI would require persistent memory, goal-directed planning, and real-world understanding that current LLMs fundamentally lack.
The Bottom Line
Large language models aren’t magic, and they’re not thinking machines. They’re extraordinarily powerful pattern-matching systems trained on more text than any human could read in thousands of lifetimes that produce output so coherent it regularly surprises even their creators.
Understanding how they work makes you a better user of them. You know why context matters so much in your prompts. You know why hallucination happens, and how to minimize it. And you know that the breathtaking rate of improvement a 280× cost drop and a 67-point benchmark jump in a single year means the tools available today are a floor, not a ceiling.
The best way to deepen that understanding is to use LLMs deliberately on real tasks. Pick something where you can judge the quality of the output. Pay attention to where they help and where they stumble. That hands-on feedback loop will teach you more than any explainer including this one.
Sources
- Precedence Research / GlobeNewswire — LLM Market Forecasted to Reach $149.89 Billion by 2035, retrieved May 2026
- DemandSage — ChatGPT Statistics 2026: Active Users & Growth Data, retrieved May 2026
- McKinsey — The State of AI 2025, retrieved May 2026
- Gartner — 40% of Enterprise Apps Will Feature AI Agents by 2026, August 2025
- IEA — Data Centre Electricity Use Surged in 2025, retrieved May 2026
- IEA — Energy and AI: Energy Demand from AI, 2025
- Stanford HAI — AI Index 2025: State of AI in 10 Charts, April 2025
- Epoch AI — Training Tokens Per Parameter, 2025
- HalluLens — LLM Hallucination Benchmark Study, ACL 2025
How Large Language Models Actually Work: A Jargon-Free Explanation for Curious Minds was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.