Also, Google Cloud grows 63%, Azure grows 40%, AWS grows 28%, Big Tech capex keeps climbing, Grok 4.3, Nemotron 3 Nano, & more!
What happened this week in AI by Louie
This week gave us a split-screen view of the AI economy. Google, Microsoft, and Amazon reported cloud growth numbers that would have looked absurd for businesses of this size a few years ago. Google Cloud grew 63% year over year to $20 billion, Azure and other cloud services grew 40%, and AWS grew 28% to $37.6 billion, its fastest growth in 15 quarters. Compute is becoming the binding constraint on AI growth this year, and Big Tech is pouring capex into solving it. At the same time, OpenAI and Anthropic are quietly preparing for the bottleneck behind compute: enterprise adoption. Both are building or backing people-heavy deployment operations with consultants, private equity firms, and forward-deployed engineers.
The capex guidance reinforces the point. Alphabet is guiding to roughly $180 to $190 billion of capex in 2026, Microsoft to roughly $190 billion, Amazon to about $200 billion, and Meta to $125 to $145 billion. Big Tech is building AI infrastructure as if enterprise demand will keep compounding for years.
There are real demand signals underneath the spending. Google Cloud backlog nearly doubled quarter over quarter to more than $460 billion, and Sundar Pichai said enterprise AI solutions became Google Cloud’s primary growth driver for the first time. Microsoft said its AI business surpassed a $37 billion annual revenue run rate, up 123% year over year, while commercial remaining performance obligation reached $627 billion. Amazon said AWS AI revenue is above a $15 billion run rate, Bedrock customer spend grew 170% quarter over quarter, and they processed more tokens in Q1 than in all prior years combined.
The model company numbers are even stranger. SemiAnalysis reports that Anthropic’s annualized revenue run rate has crossed $44 billion, up from about $9 billion at the end of 2025 and roughly $1 billion in late 2024. That is nearly 5x year-to-date and 44x in 16 months, without precedent at this scale. If Anthropic somehow held that pace for two more four-month periods, it would clear $1 trillion in annualized revenue by January 2027, exceeding any company’s current revenue base. That is extremely unlikely. The binding constraint right now is compute. Anthropic already appears to be hitting severe bottlenecks, and its recent multi-gigawatt infrastructure commitments indicate that meeting current demand will require substantial capacity additions.
A few hundred billion dollars are being invested in solving the compute bottleneck this year. But within the compute bottleneck is enterprise adoption, and the rapid pace of deployment this year has made it more apparent. The hard part is not signing a cloud commitment or running a pilot. It is putting AI inside core operations and getting durable value out the other side. Both Anthropic and OpenAI are launching new initiatives aimed exactly at this.
Anthropic announced a $1.5 billion raise for an AI-native enterprise services company with Blackstone, Hellman & Friedman, and Goldman Sachs as lead backers, alongside General Atlantic, Leonard Green, Apollo Global Management, GIC, and Sequoia Capital. The target is mid-sized companies, including private equity portfolio companies, that can benefit from Claude but lack the in-house resources to build and run frontier deployments. Anthropic was direct about the problem: integrating Claude into core operations requires hands-on engineering and deep familiarity with how each business operates. Anthropic Applied AI engineers will work alongside the new company’s engineers to identify high-impact workflows, build custom Claude-powered systems, and support customers over time. The structure turns model access into implementation capacity: a private-equity-connected services arm that can enter portfolio companies, identify workflows, deploy Claude systems, train teams, and continue improving deployments after launch.
OpenAI is building a parallel deployment stack. OpenAI Frontier launched in February with Frontier Alliances partners BCG, McKinsey, Accenture, and Capgemini. The partners help enterprises define strategy, integrate systems, redesign workflows, and scale deployment globally, working alongside OpenAI’s Forward Deployed Engineering team. Bloomberg has reported a larger PE-backed vehicle linked to OpenAI, reportedly called The Deployment Company, with more than $4 billion of capital, a valuation around $10 billion excluding new funds, and backers including TPG, Brookfield, Advent, Bain Capital, SoftBank, and Dragoneer. Some reports say the partners would give OpenAI access to more than 2,000 portfolio companies and clients. The structure is clear: OpenAI wants private-capital distribution, consulting labor, and forward-deployed engineering to translate model capabilities into operational change across thousands of companies.
Anyone who has tried to deploy AI inside a real organization understands why this is happening. A frontier model does not automatically understand your approval flows, customer exceptions, messy spreadsheets, pricing logic, data permissions, brand rules, sales process, compliance reviews, or the informal knowledge sitting in a few experienced employees’ heads. Someone has to map the work, connect the systems, train the staff, build custom skills and tools, define evaluation tests, create escalation paths, and keep improving the workflow as the models change.
While Anthropic’s recent growth makes this race feel urgent, OpenAI’s enterprise position has improved markedly in recent months. GPT-5.5 and the latest Codex updates have made OpenAI much more useful across both coding and non-technical work, and over the past two weeks, I have been using Codex for most of my own work again. Enterprise buyers do not make decisions from a static leaderboard. They respond to reliability, context handling, workflow fit, tool integration, coding quality, speed, and the confidence that a platform can keep improving within their own organization. That tension creates a problem for AI-lab-affiliated consultancies, which will struggle to always recommend and deploy the best current model for the task. The deployment industry that wins will be much wider than the labs and their immediate partners.
A second private equity story this week fits the trend from a different angle. Long Lake, backed by General Catalyst and Alpha Wave, agreed to take Global Business Travel Group private in a deal valued at about $6.3 billion. The company operates American Express Global Business Travel, and the brand and commercial arrangements are expected to continue under new ownership. Long Lake describes itself as a frontier-technology operator for services industries and uses a proprietary Nexus AI transformation platform across the businesses it has acquired or partnered with. Corporate travel is exactly the messy services category where AI needs operational expertise: booking, disruption resolution, policy enforcement, supplier relationships, expense reconciliation, traveler support, and a long list of edge cases. Amex GBT already announced a conversational AI assistant for Egencia in April, with sub-three-minute average booking times and Concur Expense integration. Long Lake’s playbook is to take a workflow-heavy services platform private, combine AI and human agents, and rewire the operating model.
Consulting firms and cloud providers are lining up around the same problem. Accenture and Anthropic have a multi-year partnership in which around 30,000 Accenture professionals will be trained on Claude. Deloitte made Claude available to 470,000 people and is certifying 15,000 professionals. PwC is building Claude-powered enterprise agents in regulated finance, healthcare, and life sciences. Google Cloud has partnerships with Vista Equity Partners and Thoma Bravo to bring Gemini, Google Cloud engineers, and agentic AI adoption programs into software portfolios.
The industry is now admitting what has been clear for a while: enterprise AI adoption requires handholding. Training, custom skills, workflow redesign, evaluation, and governance are all product requirements. If staff do not know when to trust the model, when to escalate, how to verify the output, how to combine their own expertise, how to use a custom tool, and how to change their workflow around AI, adoption remains shallow.
OpenAI, Anthropic, the major consultancies, and the new PE-backed deployment vehicles will all have their hands extremely full with the largest enterprises and sponsors. There is still an enormous amount of work left to do to make AI adoption a reality across enterprises worldwide, especially outside the Fortune 500 and the very largest funds.
That gap is exactly what we’re working on at Towards AI. We’ve been shipping custom AI to PE-backed companies & investment funds for the past year and seeing repeat use cases, i.e., post-acquisition integration, back-office automation, document processing, and portfolio-monitoring co-pilots. They might be unglamorous workflows, but they significantly impact every portco’s EBITDA and P&L.
Soon, we will be launching a dedicated, premium AI consultancy for investors and their portfolio companies. You will hear more about this soon!
Why should you care?
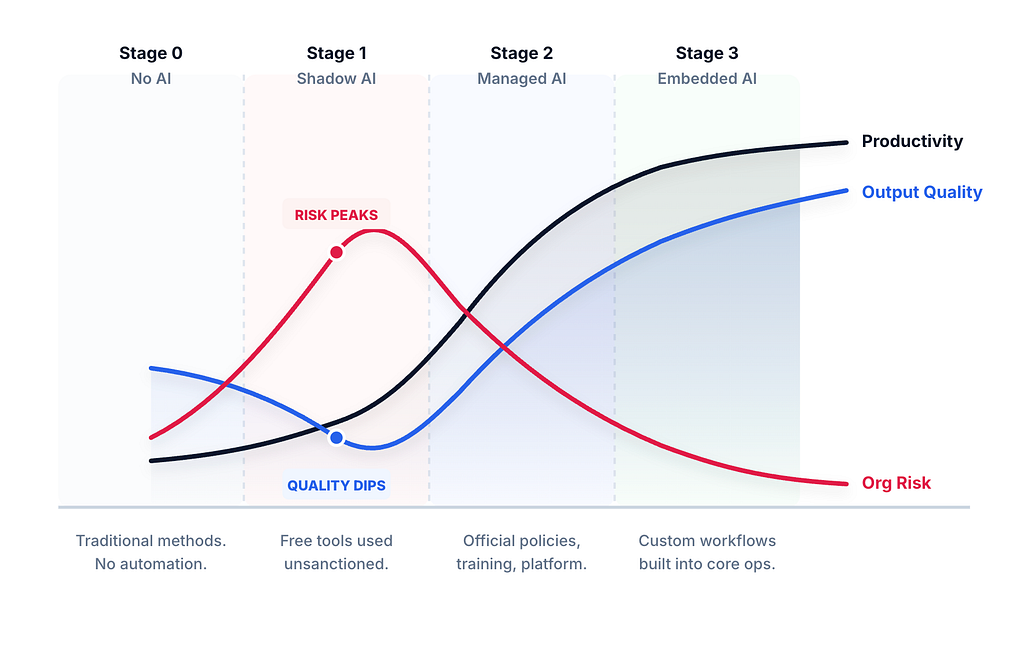
For enterprise leaders, the easy productivity wins are real but bounded. Durable AI quality only rises when expert judgment is built inside the system rather than arriving as cleanup. Most companies are still stuck in shadow AI or disordered adoption, with staff pasting work into generic interfaces and quality often slipping below the pre-AI line because experts delegate judgment instead of applying it. Companies should aim to move to the next stage as soon as possible; managed AI, with sanctioned tools and training, pulling baseline quality back up. The most durable gains come from embedded AI: custom workflows where company context, expert review points, evals, and audit trails are designed in. Pick a few workflows where the value is obvious, measure against the old process, and make the winners boring before chasing the next demo. In our AI engagements, we help companies progress through each of these stages.
For investors and private equity firms, AI has become a portfolio operations capability that rewards specificity over surveys. The sponsors that pull ahead will run diligence to find the highest-value workflows (finance close, customer support deflection, procurement, compliance review, portfolio reporting, board materials), ship custom tools with expert review designed into each loop, train staff to use them, and tie the measurement to EBITDA, revenue growth, working capital, or risk.
For builders and AI professionals, the shortage is people who understand both the models and the work. The right test for any AI output is not whether the tool was used, but whether human judgment shaped the result. The middle layer between frontier labs and enterprises will reward people who can map workflows, design evaluation sets, build custom skills and agents, connect private data safely, and put expert contributions and review where they are needed.
— Louie Peters — Towards AI Co-founder and CEO
Build a Research and Writing Agent with MCP (5-minute setup)
Paul Iusztin, Samridhi from Towards AI, and I did a 2-hour workshop at the AI Engineer Summit in London, and it went so well that the organizers put the full recording on YouTube. So now you all get it for free.
We walked through building an MCP-powered deep research agent from scratch: planning a research strategy, searching the web, analyzing YouTube videos, gathering grounded evidence, filtering for relevance, and synthesizing everything into a cited research artifact. If you’re an AI engineer looking to build end-to-end agentic systems (or want AI to handle 90% of your writing without sounding like AI), this one’s for you.
Hottest News
1. xAI Releases Grok 4.3 with Aggressive Pricing and 1M Context
xAI released Grok 4.3, a reasoning model with always-on thinking, a 1M-token context window, a December 2025 knowledge cutoff, and native support for video input. The model is priced at $1.25 per million input tokens and $2.50 per million output tokens, roughly 40% cheaper than its predecessor Grok 4.20 on input and 58% cheaper on output. Reasoning tokens are billed at the same rate as regular output. On the Artificial Analysis Intelligence Index, Grok 4.3 scored 53, placing it above Muse Spark and Claude Sonnet 4.6 but still behind GPT-5.5 (60), Claude Opus 4.7 (57), and Gemini 3.1 Pro (57). The largest benchmark jump was on GDPval-AA, where it gained 321 Elo points over Grok 4.20. It also scored 98% on τ²-Bench Telecom and 81% on IFBench. Early community reports flag inconsistencies on agentic tasks, with one tester noting the model occasionally stalls instead of taking action.
2. Mistral AI Launches Remote Agents in Vibe and Mistral Medium 3.5
Mistral AI shipped remote coding agents in Vibe alongside the public preview of Mistral Medium 3.5, a dense 128B model with a 256K context window. Medium 3.5 consolidates what previously required three separate models (Medium 3.1, Magistral, and Devstral 2) into a single set of weights handling instruction following, reasoning, and coding. It scored 77.6% on SWE-Bench Verified, beating Devstral 2 (72.2%) and Qwen 3.5 397B. Reasoning effort is configurable per request. The model is released as open weights under a modified MIT license and can be self-hosted on as few as four GPUs. On the product side, Vibe coding sessions can now run asynchronously in the cloud, with multiple agents working in parallel. Local CLI sessions can be teleported to the cloud mid-task without losing state. Vibe integrates with GitHub, Linear, Jira, Sentry, Slack, and Teams. API pricing is $1.50 per million input tokens and $7.50 per million output tokens.
3. NVIDIA Releases Nemotron 3 Nano Omni Model
NVIDIA released Nemotron 3 Nano Omni, an open multimodal model that unifies vision, audio, image, and text processing into a single architecture. Built on a 30B-A3B hybrid Mamba-Transformer MoE design, the model activates only 3B parameters per forward pass, allowing it to run on a single GPU while achieving 9x higher throughput than comparable open omni models at the same interactivity level. It tops six leaderboards across document intelligence, video understanding, and audio comprehension. The model is designed to serve as a multimodal perception sub-agent within larger agent systems, working alongside models like Nemotron 3 Super and Ultra for execution and planning. It supports deployment from NVIDIA Jetson hardware and DGX Spark to data center environments. Weights are available on Hugging Face under NVIDIA’s Open Model Agreement. Early adopters include Palantir, Foxconn, and H Company.
4. IBM Releases Granite 4.0 3B Vision
IBM released Granite 4.0 3B Vision, a vision-language model built specifically for enterprise document data extraction. Rather than shipping as a standalone model, it is delivered as a 0.5B parameter LoRA adapter on top of Granite 4.0 Micro (3.5B), so a single deployment can handle both text-only and multimodal workloads. The model uses a DeepStack injection architecture that routes abstract visual features into earlier transformer layers for semantic understanding and high-resolution spatial features into later layers for preserving layout detail. It targets three extraction tasks: converting charts to structured formats (CSV, summaries, code), parsing complex table layouts into HTML, and extracting semantic key-value pairs across diverse document types. On the VAREX leaderboard, it ranks 3rd among models in the 2–4B class. Chart2Summary accuracy reaches 86.4%, the highest among all evaluated models, including larger ones. Released under Apache 2.0.
5. Anthropic Rolls Out Claude for Creative Work
Anthropic launched a set of connectors that embed Claude directly into creative software, developed in collaboration with Adobe, Autodesk, Ableton, Blender, Splice, SketchUp, Resolume, and Affinity by Canva. Each connector is tailored to its platform: the Adobe connector provides over 50 tools across Creative Cloud apps, the Autodesk Fusion connector allows 3D model creation through conversation, and the Blender connector offers a natural-language interface to Blender’s Python API. All connectors are built on MCP, making them accessible to other LLMs beyond Claude. Anthropic also donated to the Blender project to support the continued development of its Python API. Alongside the product launch, Anthropic is partnering with art and design programs at Rhode Island School of Design, Ringling College of Art and Design, and Goldsmiths, University of London, giving students and faculty access to Claude and the new connectors.
6. OpenAI Open-Sources Symphony for Agent Orchestration
OpenAI open-sourced Symphony, an orchestration spec that turns issue trackers like Linear into control planes for Codex coding agents. The core idea is that every open task gets its own agent running in an isolated workspace. Symphony continuously watches the task board, assigns agents to unblocked issues, restarts them if they crash or stall, and shepherds changes through CI until a pull request is ready for review. The system decouples work from sessions, so engineers manage tasks rather than supervise individual Codex sessions. Internally at OpenAI, some teams saw a 500% increase in landed pull requests in the first three weeks. Symphony is released under the Apache 2.0 license as a reference implementation written in Elixir, with OpenAI explicitly stating that it does not plan to maintain it as a standalone product. The spec is model-agnostic: the community has already added support for alternative agent runtimes beyond Codex, including Claude Code.
AI Tip of the Day
If an agent sends the wrong arguments to a tool, the risk is higher than with other LLM systems: it can refund the wrong order, email the wrong customer, update the wrong record, or run a database action without the necessary constraints.
To avoid this, treat tool arguments like normal backend inputs. Validate IDs, permissions, account state, allowed ranges, required fields, and irreversible actions before execution. The model can decide which tool to call, but your application should decide whether to allow that call. This keeps the agent useful without making it the authority layer for your product.
If you’re building LLM applications and want to learn more about tool use, agents, guardrails, and production architecture, and how to make these decisions for any scale, we cover this in our 10-hour LLM Fundamental course.
Five 5-minute reads/videos to keep you learning
1. One Agent, Many Agents, or Something In Between? A Decision Framework for Agent Architecture
The article reframes the single-agent vs. multi-agent debate with a three-layer framework. Layer 1 gives every agent a fixed toolkit and on-demand skill files. Layer 2 adds subagents for context isolation and parallelism without crossing process boundaries. Layer 3 introduces A2A only where trust, compliance, or team ownership demands a structural boundary. It also walks through four criteria that drive each upgrade: context saturation, routing determinism, trust isolation, and organizational ownership.
2. Deepagents on LangGraph: Debugging Long-Running AI Agents with Time-Travel
Debugging long-running AI agents typically means restarting from scratch when something goes wrong mid-execution. This article builds a research coordinator agent using Deepagents on top of LangGraph to tackle that problem directly. The coordinator delegates retrieval and fact-checking to specialized subagents, while LangGraph checkpoints every state transition. When the agent produces a report citing outdated 2024 benchmarks as current insights, the authors rewind to the exact failure point, inject a corrective instruction, and fork a clean execution branch without discarding prior work.
3. Google ADK Finally Gets It: Skills are here, and they’re Absolutely Wild
Google ADK shipped native Skills support, adopting the same open standard that Claude Code, Cursor, and Gemini CLI already follow. The architecture splits knowledge into three levels: a lightweight metadata card the agent always holds, full instructions loaded only on activation, and deep reference files fetched per step. This practical walkthrough covers all four implementation patterns, from inline definitions to a meta-skill that generates new SKILL.md files at runtime.
4. Understanding LangChain Deep Agents as a Kitchen
Building a multi-step AI agent that doesn’t lose the plot requires a different architecture, not a smarter model. This article uses LangChain’s deep agent framework to build a meal-planning agent and explains the design through a restaurant kitchen analogy. It also walks you through four primitives that carry the weight: an external todo list to keep the plan visible, a virtual file system to hold large artifacts out of the conversation, isolated sub-agents to handle focused reasoning tasks, and human-in-the-loop interrupts to gate irreversible actions before they execute.
5. Training a Tokenizer That Actually Speaks Italian
The article documents the engineering decisions behind Dante-2B’s custom Italian tokenizer and shows why English tokenizers fail in Italian. GPT and Llama-family tokenizers split elisions like “dell’algoritmo” into three fragments and encode accented vowels as two-byte pairs, forcing models to waste training budget on broken syntax. The author switched from ByteLevel to Metaspace encoding, added a regex to preserve elisions, and pre-seeded the alphabet with accented characters, resulting in Italian fertility well below Llama’s 1.85 benchmark and 30–40% more effective context per token.
Repositories & Tools
1. Ruflo is an agent orchestration platform that adds coordinated swarms, self-learning memory, federated comms, and enterprise security to Claude Code.
2. jcode is a coding agent harness built for multi-session workflows.
3. DeepSeek TUI is a terminal-native coding agent built around DeepSeek V4’s 1M-token context window and prefix cache capability.
4. FlashKDA are high-performance Kimi Delta Attention kernels built on CUTLASS.
Top Papers of The Week
1. GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
This paper presents GLM-5V-Turbo, a multimodal foundation model designed to deeply integrate vision and language across perception, reasoning, planning, and execution. The model integrates understanding of images, videos, webpages, and documents directly into agent workflows, improving multimodal coding and visual tool use while maintaining competitive text-only capabilities through hierarchical optimization.
2. RecursiveMAS: Scaling Agent Collaboration via Recursive Computation
This paper introduces RecursiveMAS, a recursive multi-agent framework that unifies heterogeneous agents in a shared latent space. They also develop an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds. It consistently delivers an average accuracy improvement of 8.3%, along with a 1.2×-2.4× end-to-end inference speedup and a 34.6%-75.6% token-usage reduction.
3. Co-Evolving Policy Distillation
This paper proposes Co-Evolving Policy Distillation (CoPD), in which teacher and student models improve simultaneously rather than through traditional one-directional transfer. This enables more consistent behavioral patterns among experts while maintaining sufficient complementary knowledge throughout.
4. RoundPipe: Efficient LLM Training on Consumer GPUs
This paper proposes RoundPipe, a pipeline that treats GPUs as a pool of stateless execution workers and dynamically dispatches computation stages across devices in a round-robin manner, eliminating the weight-binding constraint that limits traditional pipeline parallelism. The framework achieves 1.48–2.16x speedups over state-of-the-art baselines and can fine-tune a 235B-parameter model on consumer hardware using priority-aware transfer scheduling and automated layer partitioning.
5. World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
This paper introduces World-R1, a framework that aligns video generation with 3D constraints through reinforcement learning. It uses a specialized pure-text dataset tailored for world simulation and optimizes the model with feedback from pre-trained 3D foundation models and vision-language models to enforce structural coherence without altering the underlying architecture.
Quick Links
1. Sakana AI introduces KAME, a hybrid architecture that connects a speech-to-speech (S2S) model with a backend LLM. The S2S model handles the fast response loop, while the backend LLM runs asynchronously on a slower cycle, injecting “oracle” signals as they become available. The front-end S2S module is based on the Moshi architecture and processes audio in real time at the discrete audio-token cycle (approximately every 80 milliseconds). The back-end LLM module consists of a streaming speech-to-text (STT) component paired with a full-scale LLM.
2. Meta introduces Autodata, a method that enables AI agents to act as data scientists who can build high-quality training and evaluation data. This process includes an initial iteration of data creation, followed by an analysis phase: “eyeballing” the data, measuring its performance, deriving insights, and then iterating with an improved recipe to create better data.
3. Qwen AI releases Qwen-Scope, an open-source suite of sparse autoencoders (SAEs) trained on the Qwen 3 and Qwen 3.5 model families. The release comprises 14 groups of SAE weights across 7 model variants. Qwen-Scope provides insights and guidance for model optimization across various stages, including inference, evaluation, data processing, and training.
Who’s Hiring in AI
Software Engineer (Backend, Java) — Risk @Binance (Asia/Remote)
AI Cloud Engineer @VAM Systems (Manama, Bahrain)
xEngineer — AI Site Creation @Wix (Tel Aviv, Israel)
Lead Instructor: Agentic AI Engineering @General Assembly (USA/Remote)
Applied AI Specialist @Capital on Tap (London, UK)
Software Engineer — AI Services @SmartBear (Ahmedabad, India)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
TAI #203: OpenAI, Anthropic, and Wall Street Race to Build the AI Deployment Layer was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.