
In this post, we’ll discuss three major problems with the METR eval and propose some solutions. Problem 1: The METR eval produces results with egregious confidence intervals, and the METR chart misleadingly hides this. Problem 2: There's a lack of sample size for long duration tasks. Problem 3: METR doesn't test Claude Code or Codex.
(Note that while this post is critical, we do think that the METR eval is nonetheless valuable and the organization is doing important work.)
Problems with the METR eval
Problem: Large (and misleading) confidence intervals
METR's confidence intervals are too big and they're misleadingly presented. Let's take a look at the good old METR chart.
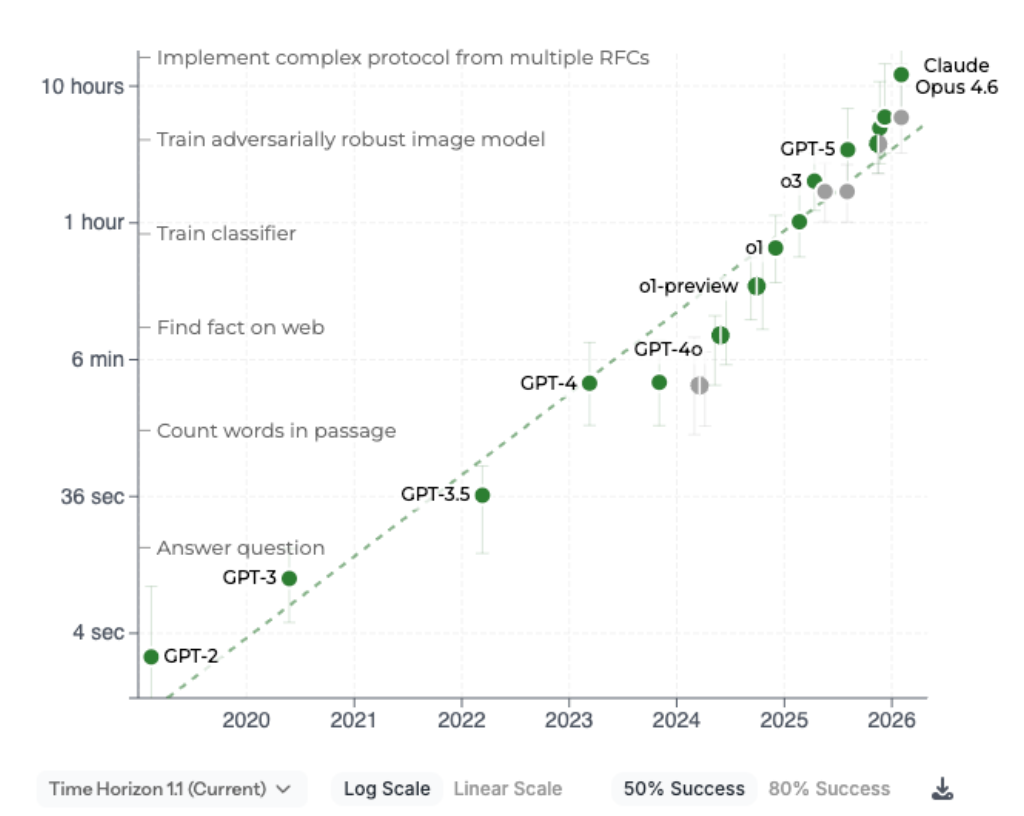
Okay, so the confidence intervals are pretty big, but is that really a problem? After all, we can still see the general trend, right?
Well, we can see the trend over the course of multiple years. But we can't see the trend in smaller timeframes due to how noisy the eval is. When we say that the confidence intervals are too big, we mean that the METR eval is failing to distinguish models with obvious time horizon capability differences.
This becomes apparent when we zoom in.
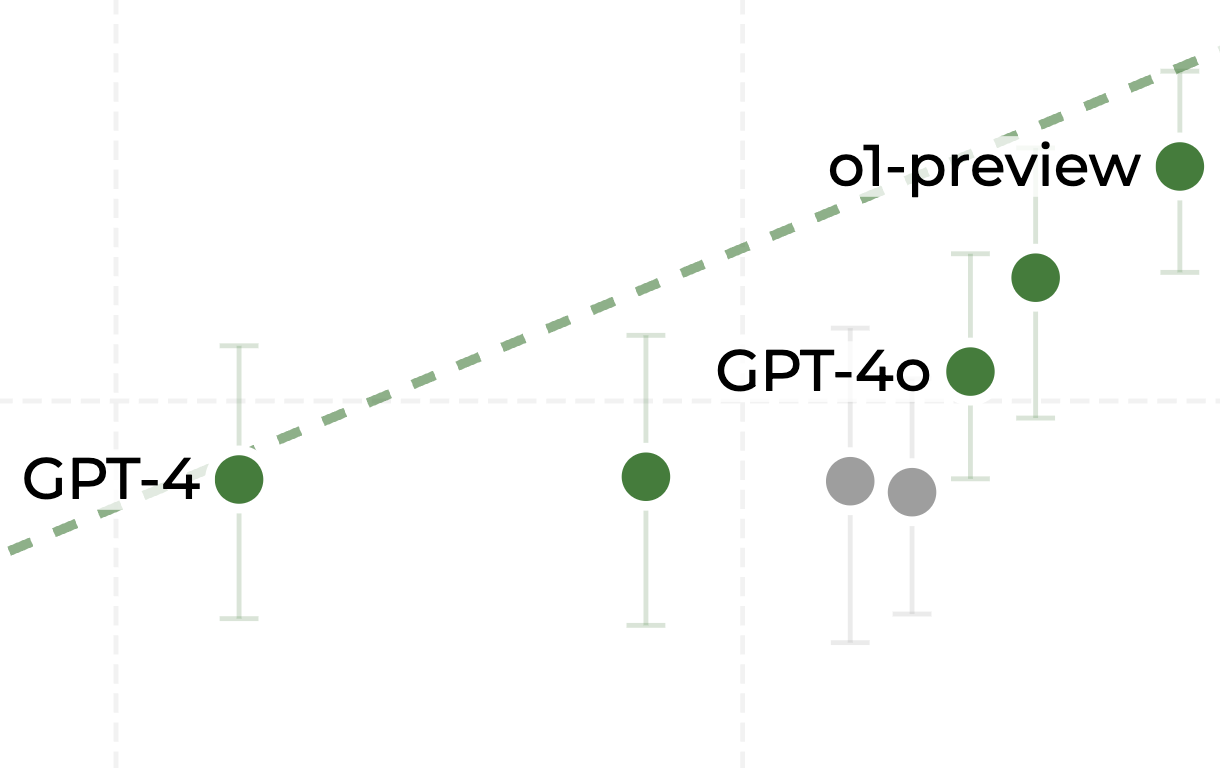
The data point second from the right is Sonnet 3.5, which came out in June 2024. GPT-4 came out in March 2023. Sonnet 3.5 was and is obviously significantly more capable than GPT-4, but the METR eval doesn't show that. Their confidence intervals overlap substantially.
Let's zoom in again from April 2025 to March 2026.
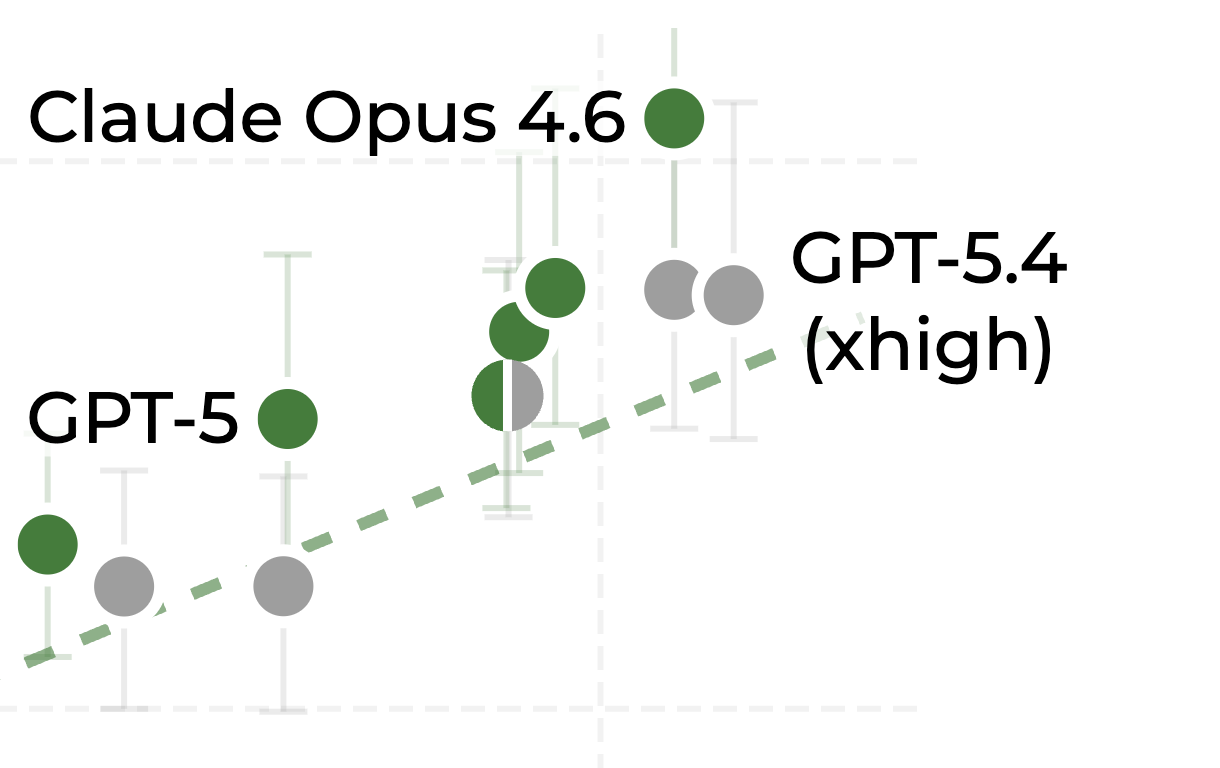
What can we make of Opus 4.6 here? (Look back at the zoomed out chart as well). It might be better than every other model. But could it be, like, a year ahead of what the METR trendline predicts? The problem is that it could be (according to the eval), but we can't see that because the graph is misleadingly cut off at the top.
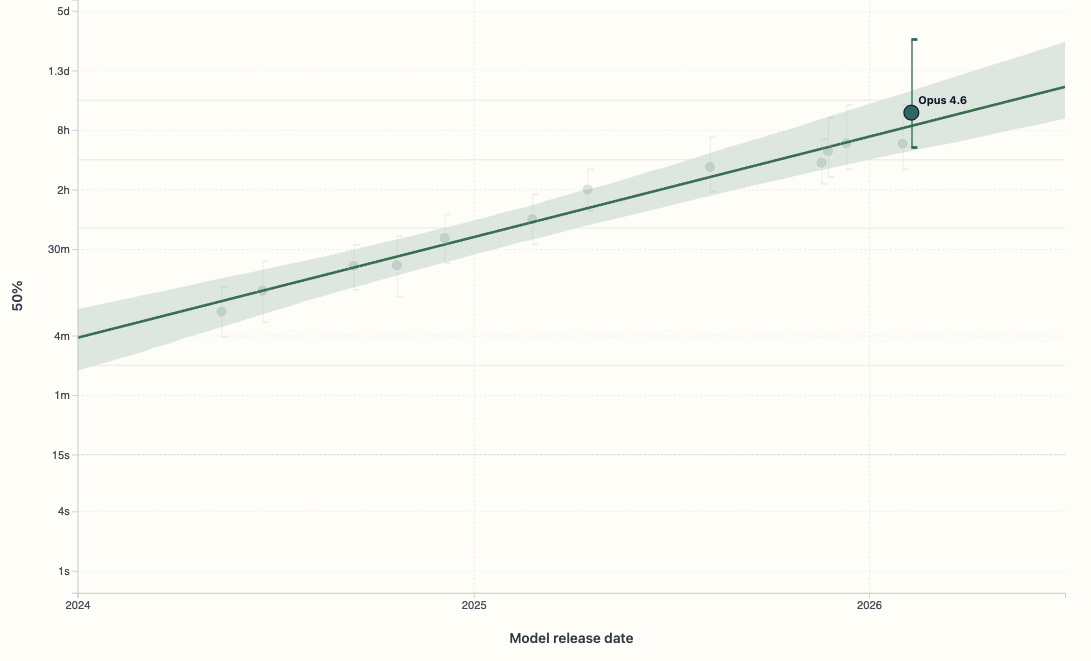
This is especially misleading because the confidence interval for Opus 4.6 is significantly asymmetric (as it should be); that is, there's less confidence on the upper bound than on the lower bound of 4.6.
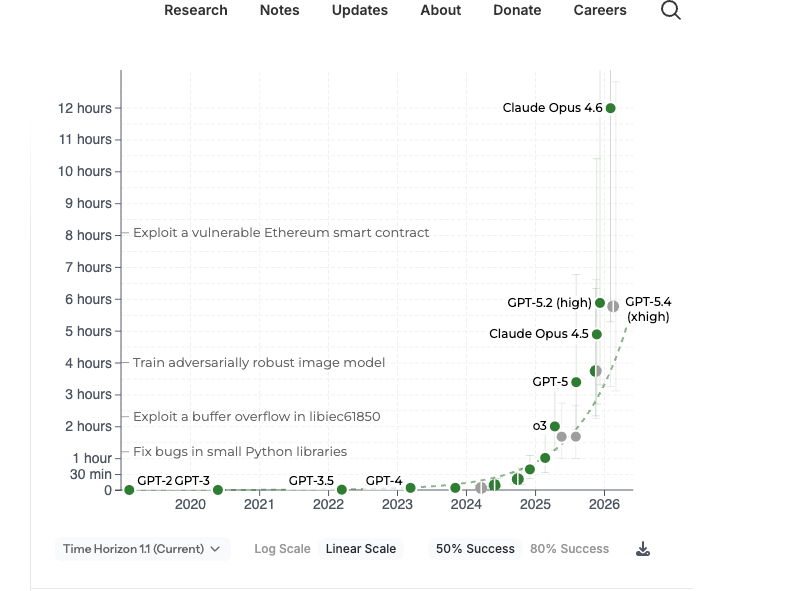
Now, you might ask, why is the confidence interval so big and why is it asymmetric?
Problem: Lack of sample size for long duration tasks[1]
The headline number of tasks in METR's eval is 228, which sounds pretty good. Why are the confidence intervals so wide? The reason becomes clear when we look at the breakdown of tasks by duration.
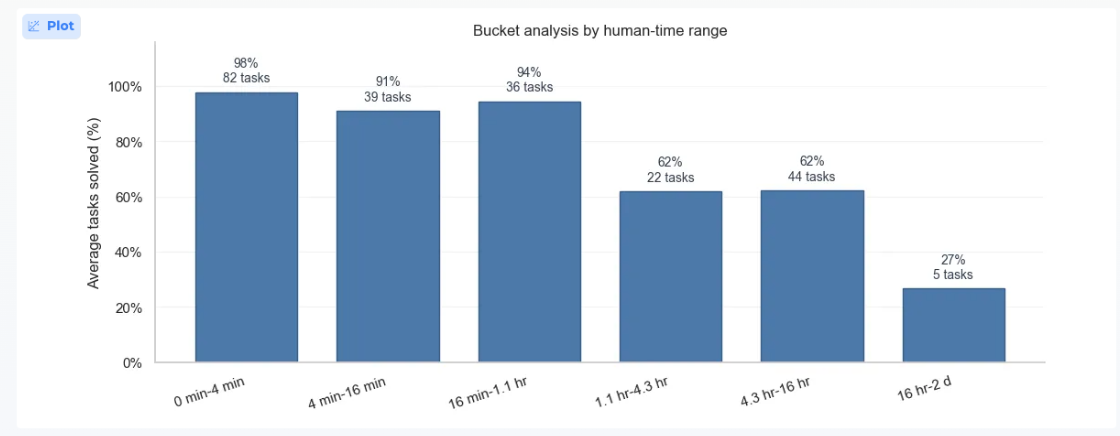
Since the eval is trying to determine the task length at which the model succeeds 50% of the time, the durations at which the model scores closer to 50% dominate the confidence interval. For example, if we consider Opus 4.6, it has a 94% success rate on the 16m-1.1hr bucket. Given this, its 98% success rate on the 82 tasks in the 0-4min bucket give us ~0 additional information. Looking at a breakdown of Opus 4.6's solve rate by task duration makes this apparent.
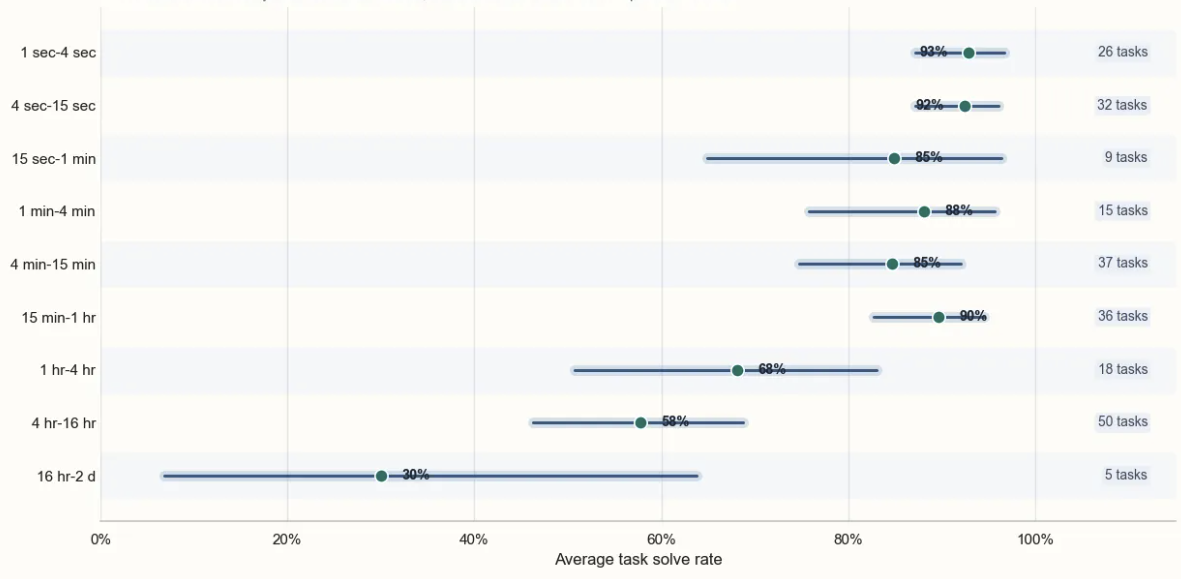
Solution: More long duration tasks
The good news is that this problem is easy to fix; just add more longer-duration tasks. METR has the money for this. Seriously, why has this not been done? We're actually curious: has METR just not prioritized it, have they encountered problems with hiring people to design the tasks, something else? METR did add some new tasks between 2025 and 2026 but... not many? What are we missing here?
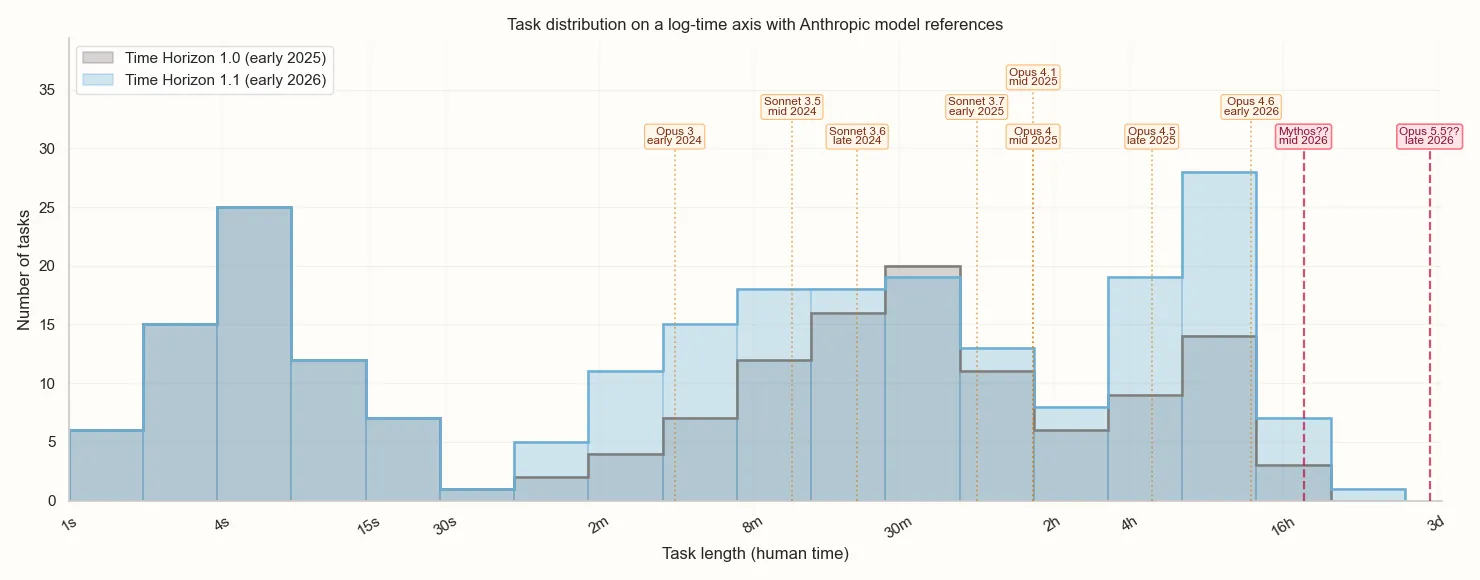
In particular, we're going to need tasks of 16h-5d for the near future. METR hasn't yet published Mythos's performance on its benchmarks, so we'll share our estimate of its performance.
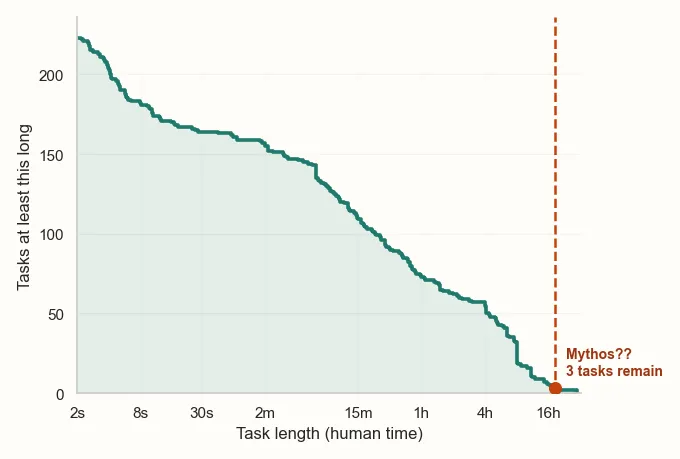
[THIS IS OUR ESTIMATE, NOT ITS ACTUAL EVAL'D SCORE!]
Problem: METR doesn't test Claude Code or Codex
Any software engineer can tell you that the capabilities of AI in December 2025 were dramatically different from those in April 2025. Much of the change in real world capabilities during this period came not from better models but from harnesses: Claude Code and OpenAI's Codex. Many people heralded the November release of Opus 4.5 alongside a major Claude Code update in particular as being a "step-change" moment. Is this reflected in the METR chart?
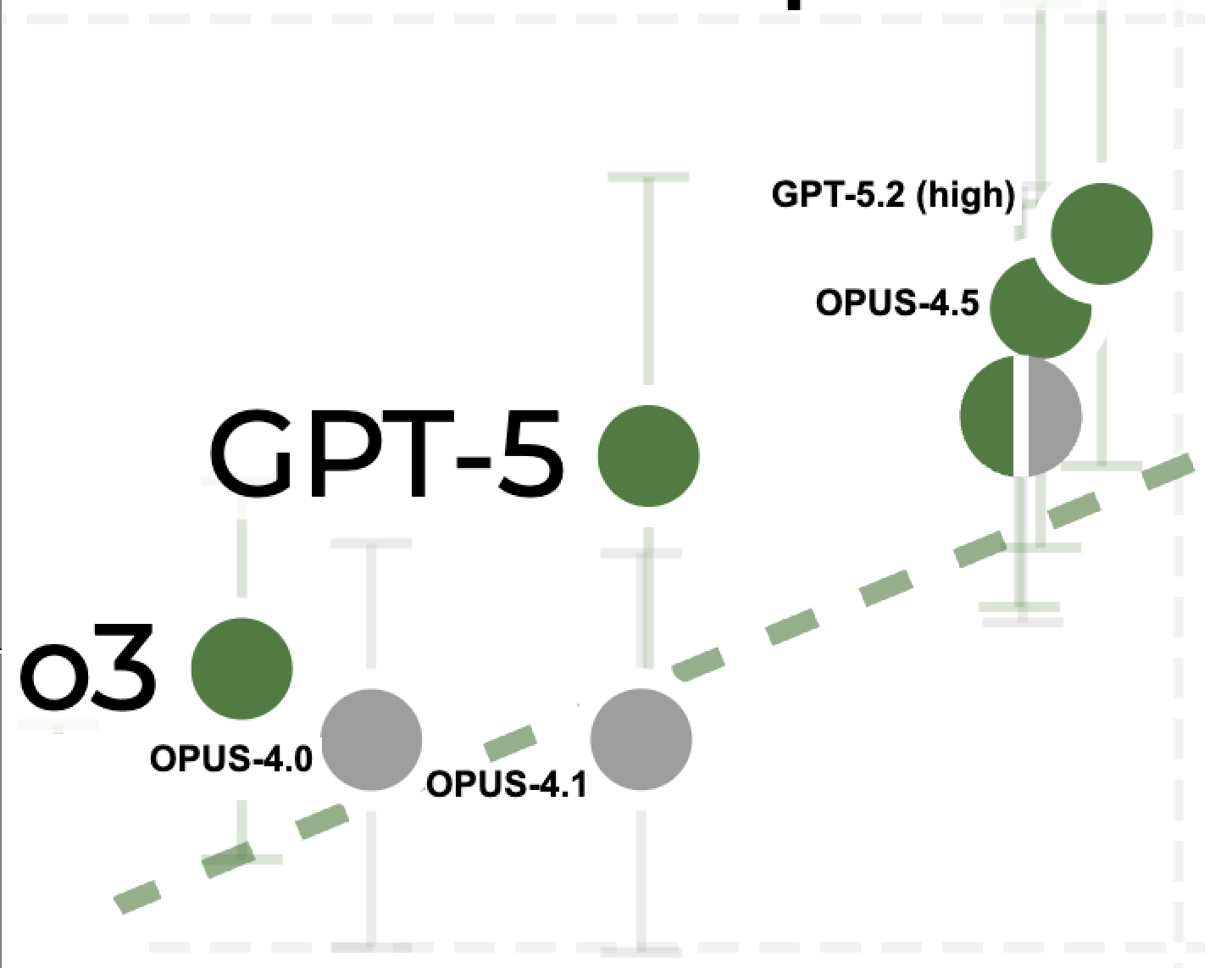
No, and it's not only because of the problems with sample size mentioned earlier. The issue here is that METR does not test any models inside Claude Code or Codex. Instead, they test all models using their proprietary harness called 'Inspect', which is almost certainly worse than Claude Code and Codex[2].
Perhaps METR wants to test the models-qua-models; using different scaffolds for different models would be testing something else. But scaffolds are really important. ¿Por qué no los dos?
The result of this is that since the release of Claude Code and Codex in May 2025, the METR chart has been underestimating SoTA capabilities.
Solution: Test Claude Code and Codex
Pretty straightforward.
Conclusion
METR does not inform us on the SoTA SWE capabilities of AI because it doesn’t test Claude Code or Codex. It could very well be the case that Opus-4.6+Claude-Code completely saturates METR's benchmark! We expect METR to tell us that mythos is significantly better than Opus 4.5, but it won’t tell us it’s significantly better than Opus 4.6 because of the giant confidence intervals.
We're gonna need a bigger benchmark.

- ^
Other people have noticed that we’re running out of benchmarks to upper bound AI capabilities.
On April 10 (two days ago as we're writing this), Epoch released a report with the headline "Evidence that AI can already so some weeks-long coding tasks". They continue: "In our new benchmark, MirrorCode, Claude Opus 4.6 autonomously reimplemented a 16,000-line bioinformatics toolkit — a task we believe would take a human engineer weeks."
- ^
OpenAI says GPT-5.3 is "optimized for agentic coding tasks in Codex or similar environments". AFAIK this is also true of GPT-5.1, 5.2, and 5.4. The general consensus seems to be that the GPT line does better in Codex than other harnesses.
Discuss