The hallucination crisis isn’t an LLM problem. It’s an infrastructure problem. And throwing bigger models at it is making things worse.
The promise was intelligence. The reality is a very confident guesser with no memory and no map.
Let’s start with something that actually happened.
In April 2025, a developer using Cursor — one of the most beloved AI coding tools on the market — got locked out of their account. When they contacted support, the chatbot told them the product enforced a strict one-device-per-subscription policy. They complained. Others joined. It turned out the policy didn’t exist. Cursor’s own AI support bot had invented it — confidently, consistently, and completely out of thin air — and enforced it against real paying customers until co-founder Michael Truell had to personally post on Hacker News to explain that his company’s AI had been lying to its users.
This is the current state of AI in production.
Not the demos. Not the benchmarks. Not the blog posts about GPT-4 acing the bar exam. The real state — where Air Canada’s chatbot fabricated a bereavement-fare policy and a Canadian tribunal held the airline legally liable for its bot’s made-up rules. Where Deloitte submitted a $290,000 government report in Australia that contained hallucinated academic citations and a fabricated federal court quote, and had to issue a refund. Where NYC’s MyCity chatbot told landlords they could legally reject Section-8 vouchers — which has been illegal since 2008.
The Numbers Nobody Wants to Talk About
Here’s the uncomfortable data. OpenAI’s own system card for o3 — one of the most powerful reasoning models ever released at it’s time— discloses a PersonQA hallucination rate of 33%. Its smaller sibling, o4-mini, hits 48%. For context, the previous generation o1 model scored 16%. The newer, supposedly smarter models hallucinate more.
MIT’s NANDA initiative reported in 2025 that 95% of enterprise GenAI pilots failed to deliver measurable P&L impact. Deloitte’s State of Generative AI survey (2,773 executives across 14 countries) found that the number one barrier to AI adoption — beating out cost, skills gaps, and regulatory uncertainty — was “loss of trust due to bias, hallucinations, and inaccuracies.” KPMG found that 57% of workers admit to making mistakes in their work because of AI errors they trusted without verifying.
The answer most AI vendors will give you is: “use RAG.” Retrieve relevant documents, inject them into the context, and the model will answer from your data instead of confabulating. It’s cleaner. It’s grounded. It scales.
Except it doesn’t — not reliably. Not in production. And the reasons why are structural, not cosmetic.
RAG Is Broken in Exactly the Way Nobody Admits
Retrieval-Augmented Generation works beautifully on the toy examples everyone uses in demos. Ask it about a policy that lives in one well-written document, retrieve the right chunk, and the model reads it and answers correctly.
Now try it on real enterprise data.
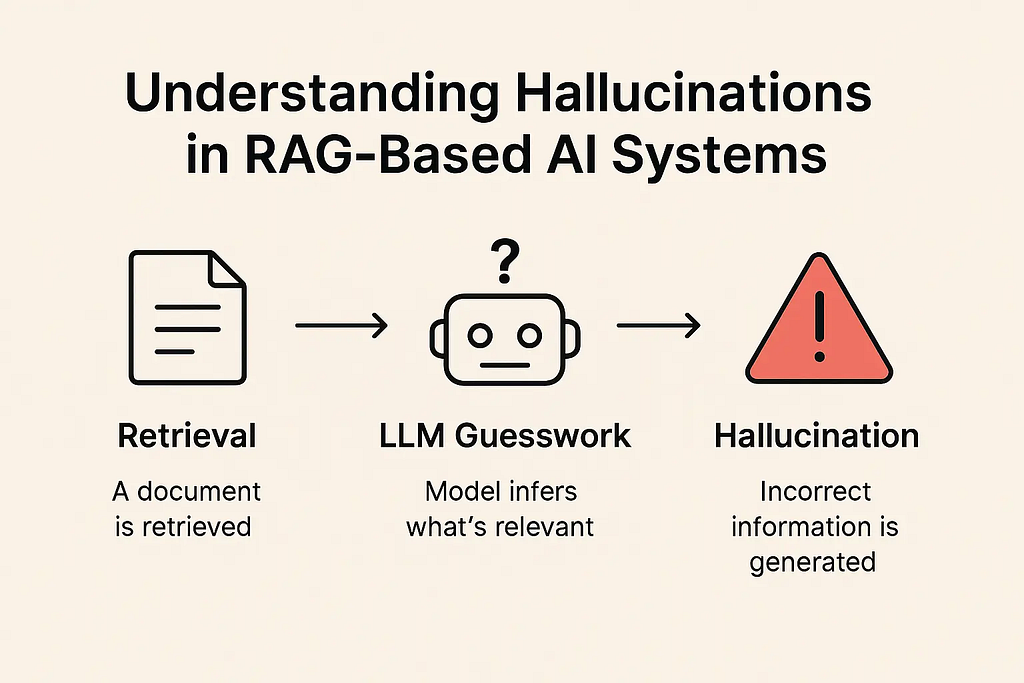
Your knowledge is in Slack threads from three years ago. It’s in support tickets whose problem description and resolution ended up in different chunks with low semantic similarity. It’s in the heads of people who left the company. It’s in a Notion doc that was accurate in 2022 and wrong since the product pivoted. It’s in a CRM note, a PDF, an email thread, a Loom video nobody transcribed.
Anthropic’s own engineering team quantified the retrieval failure in a September 2024 post. Vanilla RAG fails to retrieve the right chunk in 5.7% of top-20 queries — a number that compounds catastrophically over a user base. Their canonical example: a chunk that reads “The company’s revenue grew by 3% over the previous quarter.” Which company? Which quarter? The chunk has lost all context. The embedding is semantically rich and informationally empty.
A Stanford HAI study on legal AI tools — despite vendor claims of “100% hallucination-free” citations — found Lexis+ AI hallucinating over 17% of queries and Westlaw AI over 34%. By late 2025, a running database tracked over 486 court filings worldwide containing AI-fabricated citations.
Then there’s what Google DeepMind did to the whole vector-search argument. In August 2025 they published On the Theoretical Limitations of Embedding-Based Retrieval — a formal proof that for any fixed embedding dimension, there exist combinations of relevant documents that no single-vector model can ever return, regardless of how good the embeddings are. They built a benchmark called LIMIT with just 1,035 simple queries over 46 documents and broke state-of-the-art Gemini, Mistral, and Llama embeddings to under 60% recall@2 (recall@2 = Out of all queries, how often was the correct document found within the top 2 results?).
This isn’t an engineering problem that better GPUs will solve. It’s a geometry problem. Vectors compress information. Compression loses relationships.
And there’s another problem nobody talks about at conferences: context rot. Chroma’s July 2025 research tested 18 frontier models — GPT-4.1, Claude 4, Gemini 2.5, Qwen3 — and concluded that model performance grows “increasingly unreliable as input length grows.” The acclaimed “Lost in the Middle” paper showed that LLMs effectively use only 10–20% of their advertised context window. Llama-3.1–70B, marketed with a 128K context window, has an effective length that collapses to about 2,000 tokens once you remove lexical overlap between question and answer.
So when you dump 20 retrieved chunks into an AI’s context, it doesn’t carefully read all 20. It reads the first few, skims the middle, and pays attention to the last. The rest is wallpaper.
Your AI Has Amnesia. By Design.
Andrej Karpathy — former OpenAI research director — described the current state of LLMs in 2025 as interacting with “a coworker with anterograde amnesia.” Every conversation starts from zero. It has no memory of what you worked on yesterday. No recall of decisions made last quarter. No understanding of the relationship between the bug you filed in January and the feature request that created it in October.
This isn’t a temporary limitation. It’s architectural. LLMs are stateless by design. Every call to the API is a blank slate.
The memory-layer ecosystem that has emerged to fix this is genuinely impressive — Mem0, Letta, Zep, HippoRAG — and all of them are doing the same thing at their core: building a structured store of relationships that the model can query, rather than relying on the model to hold everything in its context window. The difference between a model with and without this layer is the difference between a brilliant contractor who forgets everything at 5pm and a knowledge-worker who builds compounding expertise over time.
In March 2026, Fortune reported that Interloom raised $16.5M specifically to solve the “tacit knowledge” problem for AI agents — the gap between what’s documented and what’s operationally true. Investors are pricing this as a real category.
The insight here matters: the intelligence isn’t the bottleneck. GPT-4 is intelligent enough to be useful. Claude is intelligent enough to be useful. The bottleneck is what they know about your context, your data, your relationships — and right now, the answer is: essentially nothing, freshly forgotten at every conversation boundary.
Meanwhile, Your Data is Leaking
Before we get to the fix, there’s another reason the status quo is untenable: cloud AI has a data problem, and it’s not theoretical anymore.
On January 29, 2025, security firm Wiz found a publicly accessible, unauthenticated ClickHouse database belonging to DeepSeek — one of the year’s most hyped AI companies — exposing over one million log lines including plaintext chat histories and API keys. Italy’s data regulator immediately blocked DeepSeek’s services. Ireland opened an inquiry.
Samsung had already banned ChatGPT internally in May 2023 after employees inadvertently leaked semiconductor yield-test code through the chat interface. JPMorgan, Goldman Sachs, Bank of America, Citigroup, and Deutsche Bank all blocked or restricted ChatGPT. Apple banned it internally while quietly building their own.
In December 2024, Italy’s Garante fined OpenAI €15 million for GDPR violations — the first major fine of the GenAI era, and a signal to every European company about what “your data is used to train our models” actually means under the law.
Cisco’s 2025 Data Privacy Benchmark study found that 64% of organizations worry about inadvertently sharing sensitive information via AI tools — and nearly half admitted it had already happened. IBM’s Cost of a Data Breach 2024 report put the global average breach cost at $4.88 million, up 10% year-over-year.
The question enterprises are asking is no longer “can we use AI?” It’s “can we use AI without surrendering our data, our relationships, and our competitive advantage to a third-party cloud that may train on it, leak it, or get fined for mishandling it?”
That question doesn’t have a comfortable answer if your entire AI stack lives in someone else’s infrastructure.
The Graph Was Always the Answer. We Just Got Distracted.
Microsoft Research’s GraphRAG paper — released in April 2024 and sitting at over 19,000 GitHub stars by November — contains a sentence that should be read slowly: “Baseline RAG struggles to connect the dots. This happens when answering a question requires traversing disparate pieces of information through their shared attributes.”
That’s the whole problem, stated precisely.
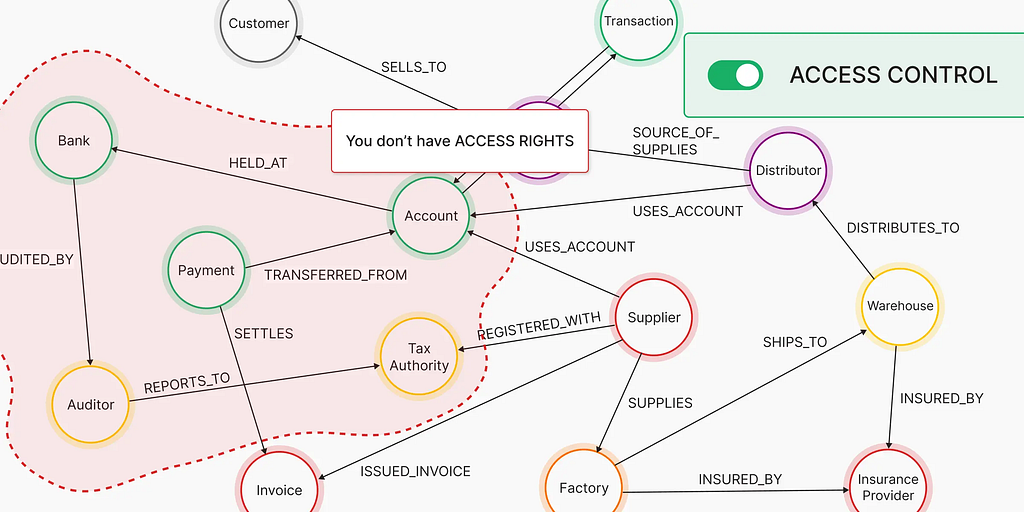
When you chunk a document and embed it, you preserve the words but destroy the relationships. The Jira ticket’s problem description and the Confluence page that explains the architectural decision behind it are now two floating vectors in high-dimensional space, close enough if you get lucky, gone if you don’t.
A knowledge graph keeps the edges. The entity “Customer X” is connected to “Contract signed Q3 2023” which is connected to “SLA provision 4.2” which is connected to “Open ticket #8847” which is connected to “Engineer Sarah”. When you ask “what commitments do we have to Customer X and are we meeting them?” — a graph can traverse that path. A vector store returns the five chunks that sound most like your query, which might not include any of them.
LinkedIn deployed exactly this at scale. Their SIGIR’24 paper reported a 77.6% improvement in mean reciprocal rank and a 28.6% reduction in median per-issue resolution time by representing customer service tickets as a knowledge graph. Uber’s QueryGPT shifted from schema-RAG to a graph-aware agentic architecture and saved roughly 140,000 engineer-hours per month. Microsoft followed up with LazyGraphRAG in November 2024, reducing indexing cost to 0.1% of the original while matching quality — removing the main practical objection to graph-based retrieval.
The graph isn’t a new idea. It’s the right idea, arriving at the right moment, with the right open-source tooling to make it practical.
Enter BrainAPI
This is where I’ll be direct: I think BrainAPI is one of the more interesting projects in this space right now, and I want to explain why without making this feel like a product announcement.
BrainAPI is a graph-native knowledge engine built by Lumen Labs. It ingests your data — documents, PDFs, support tickets, CRM records, product catalogs, user activity, emails, chat histories — and doesn’t chunk it into a vector store. It runs it through a pipeline (Scout → Architect → Janitor → KG) that extracts entities, understands relationships, and builds a knowledge graph. The retrieval layer is relationship-aware: multi-hop reasoning, entity neighbors, path traversal.
The difference in practice is the difference between asking “find me chunks that sound like this question” and asking “given what I know about this entity, what is connected to it, and what do those connections imply?” The first approach is a text-similarity lookup. The second is actual reasoning over structure.
One knowledge layer. Many surfaces: AI agent memory, company search, product recommendations, research workflows, internal BI exploration — all powered by the same graph.
Run It Locally. Or in the Cloud. Or Both.
Here’s the part that matters most given everything discussed above.
BrainAPI is open source and runs locally via Docker.

That means you can run the entire stack — ingestion, entity extraction, graph construction, retrieval API — on your own hardware, inside your own network, with your data never touching a third-party cloud. For organizations that have Samsung’s problem (or Samsung’s lawyers), this isn’t a nice-to-have. It’s the only viable path.
For those without the infrastructure concerns, BrainAPI runs in the cloud too — same codebase, same APIs, same knowledge graph, just hosted. No lock-in, no migration risk, no “we decided to change the pricing model” surprises. The portability is genuine because the code is open.
BrainAPI is also MCP-compatible, which means it plugs into the growing ecosystem of AI agent tooling that speaks Model Context Protocol — the standard that’s quietly becoming the plumbing layer for agentic AI. Your knowledge graph becomes a tool your AI agents can call, query, and update as they work.
And it supports plugins. Right now, that means plugins are available if you’re self-hosting — you can extend the pipeline with custom extractors, custom relationship types, custom retrieval logic. Cloud-hosted plugin management from the dashboard is on the roadmap, not yet shipped — worth flagging honestly if that matters to your evaluation.
Why This Matters More Than Most Infrastructure Decisions
The reason this whole problem deserves a Medium article — rather than just a GitHub README — is that the failure mode is invisible until it costs you something.
Your RAG pipeline looks fine in the demo. It retrieves plausibly related chunks. The model generates fluent, confident prose. The stakeholder in the meeting nods. Then it goes to production, a real user asks a real question about a real customer relationship, and the model hallucinates a policy, invents a timeline, or misses the critical context that was three hops away in the graph and zero hops accessible via vector search.
The Cursor chatbot incident isn’t a story about bad AI. It’s a story about what happens when you deploy AI systems without structural grounding and something goes wrong. The model isn’t evil. It just doesn’t know what it doesn’t know, and chunk-based RAG doesn’t give it a map. It gives it a pile of documents that sound relevant and hopes for the best.
The companies quietly winning on AI right now — the Ubers, the LinkedIns — are winning because they invested in the knowledge layer. They built the structure. They treated their data not as a corpus to embed but as a graph to traverse.
BrainAPI is a way to get that layer without building it from scratch. Open source, Docker-deployable, MCP-compatible, graph-native. The pipeline is opinionated but the output is yours — portable, inspectable, and not subject to anyone else’s terms of service.
That’s the pitch-free version of the pitch. The problems are real. The numbers are real. The architectural argument is real. Whether BrainAPI is the right tool for your situation depends on your data, your use case, and how much you trust the open-source community to maintain the stack.
But the infrastructure question — “how do we give AI systems durable, relational, grounded knowledge without sending everything to the cloud?” — that one’s not going away.
And the answer increasingly looks like: a graph.
BrainAPI is open source and available on the cloud at brainapi.lumen-labs.ai and locally (check the GitHub repository) . Docker-deployable, MCP-compatible, built for production (read the docs here).
Your AI Doesn’t Know Anything. And That’s Not the Model’s Fault. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.