How I solved a chunk selection problem that the current state of the art overlooks and why K-means is the unexpected answer

There’s a class of LLM problems that has no name, no framework, and almost no literature.
The problem: you have a massive amount of text, no user query, and you need to select the best chunks to send to an LLM with guaranteed thematic coverage and source traceability.
This isn’t Retrieval-Augmented Generation. It isn’t prompt compression. It isn’t summarization. It’s something the research community hasn’t properly identified yet, and the existing solutions don’t address it.
This article presents a simple approach to this problem one that turns out to converge with ideas from academic research, while addressing a gap those papers don’t consider.
Part 1 — The Problem
When RAG Doesn’t Apply
If you’ve built anything with LLMs in the past two years, you’ve encountered RAG: user asks a question, embed the query, retrieve similar chunks from a vector store, inject them as context, generate a grounded answer.
RAG is elegant, well-documented, and supported by every major framework. It also assumes something fundamental: a user query exists.
But what happens when there’s no question?
This is a blind spot in the current LLM tooling landscape. Frameworks like LangChain and LlamaIndex are built around the query-retrieval pattern. Research papers on context compression almost always assume a query exists. If you search “how to select the best chunks for an LLM” every result assumes you have a user query to guide the selection.
I didn’t. And I suspect many builders don’t either.
In my case, I was building a learning application. Users upload their course materials textbooks, lecture slides, video transcripts, handwritten notes sometimes hundreds of pages. They don’t search for anything. They say: “Here are my courses. Generate me study materials.”
The system needs to produce structured outputs: quiz sheets, flashcards, summaries, concept maps. Each output should cover a different topic. Each should cite its source. And the total source material far exceeds any LLM’s context window.
Three Constraints the State of the Art Ignores
When I looked for solutions, I found that the existing approaches all fail on at least one of three constraints that are simultaneously required in my use case:
Constraint 1 : No query signal. There is no user question to guide selection. The system must determine what’s “important” intrinsically, from the data alone.
Constraint 2 : Guaranteed thematic coverage. The output isn’t a single answer it’s a set of outputs that must collectively cover the breadth of the source material. Missing an entire topic is a critical failure. A quiz about biology that skips genetics entirely is useless.
Constraint 3 : Source traceability. Every generated output must be traceable to a specific chunk of the original material, so it can be cited. “This quiz is based on Chapter 3, pages 12–14 of your Biochemistry textbook.” In an educational context, this isn’t optional students need to know where to go for deeper study.
No existing approach satisfies all three simultaneously. This is the gap.

Part 2 — State of the Art and Its Blind Spots
Before building a solution, it’s worth reviewing what the academic literature offers on context compression and chunk selection for LLMs. What follows is an assessment of the main approaches and where each falls short for this specific problem.
2.1 — Why “Just Send Everything” Fails
The naive approach is to stuff the entire source material into the LLM’s context window. With models supporting 128k to 200k tokens, it’s tempting to think this works.
It doesn’t. Liu et al. [1] demonstrated in “Lost in the Middle” that LLMs exhibit a U-shaped performance curve: they process information at the beginning and end of their context well, but systematically miss information positioned in the middle. Performance degrades by over 30% when critical content shifts from the edges to the center even on models explicitly designed for long contexts.

Even if everything fits in the window, the model would ignore large portions of the material. The quiz would cover the first and last chapters, and skip everything in between. More context is not better context.
2.2 — Prompt Compression: Solves the Wrong Problem
A growing body of research addresses input length reduction by removing redundant tokens before sending text to the LLM.
Selective Context [3] uses a small language model to compute the self-information of each lexical unit tokens, noun phrases, or sentences and removes low-information units. This works without a query, which satisfies the first constraint. But it operates by filtering within the existing text: it removes words or phrases while preserving the rest. The result is a compressed version of the same text, not a selection of representative content across topics. It cannot guarantee thematic coverage and the modified text loses its direct link to original source chunks, failing constraints 2 and 3.
LLMLingua [4] and LLMLingua-2 [5] extend this approach with iterative compression and learned token classifiers. They achieve impressive compression ratios up to 20x. But they share the same fundamental limitation: they compress text for the machine, not organize it for the human. The output is a compressed prompt that the LLM can parse not a structured set of source-traceable content.
RECOMP [6] trains compressors that can summarize or extract from retrieved documents. It’s the most sophisticated approach, with both extractive and abstractive variants. But it explicitly requires a query to guide what to keep and what to discard, failing constraint 1.
In short, prompt compression reduces token count. It does not select representative content, guarantee topic coverage, or preserve source structure.
2.3 — Graph-Based Methods: Represent but Don’t Organize
TextRank [7] and LexRank [8] build a similarity graph between sentences and use PageRank to find the most “central” ones — those that best represent the overall document.
These methods are query-free, which satisfies constraint 1. They’ve been the standard for unsupervised extractive summarization for two decades. But they have a well-known weakness: redundancy. Similar sentences receive similar centrality scores, so the top-K selected sentences often say the same thing in different words. A TextRank summary of a biology textbook might give you three sentences about DNA replication and zero about protein synthesis because DNA replication happens to be mentioned more frequently.
This weakens constraint 2: coverage is not guaranteed, even if major themes tend to be represented. And because these methods work at the sentence level, source traceability is limited constraint 3 is only partially met.
2.4 — Clustering Methods: The Closest — But Still Not It
Clustering-based summarization (K-means, HDBSCAN, etc. on sentence embeddings) groups similar sentences into thematic clusters and selects one representative per cluster. This elegantly solves the redundancy problem: by construction, each cluster contributes one sentence, and clusters cover different themes.
The most advanced recent work is “Graphs in Clusters” [2], which combines K-means with TextRank: cluster first for coverage, then rank within each cluster for importance. It achieves comparable or better results than both individual graph-based and cluster-based methods on long document summarization benchmarks (ArXiv, PubMed).
This is the closest to what I need. But it still differs from my problem in several important ways. Their goal is to produce a flat text summary; mine is to produce N structured outputs. Their K is optimized via the elbow method; mine is determined by the user’s request. They work at the sentence level; I need chunk-level granularity to preserve source metadata. Their clusters are an invisible intermediate step; mine are the deliverables themselves. And source tracing mandatory in my case is not considered in their work.
2.5 — The Gap
When you lay these approaches side by side against the three constraints, a clear pattern emerges.
RAG preserves sources but requires a query and doesn’t guarantee coverage. Selective Context and LLMLingua work without a query but lose source structure and can’t ensure coverage. RECOMP requires a query. TextRank and LexRank work without a query but produce redundant output and offer limited traceability. Clustering-based summarization satisfies the first two constraints no query needed, coverage guaranteed but operates at the sentence level, which breaks the source chain.
No existing approach satisfies all three constraints simultaneously. There is no established method for query-free, coverage-guaranteed, source-traceable chunk selection for LLM input.
This is the gap that needed a solution.
Part 3 — The Solution
The Core Insight
The solution comes from an inversion of how clustering is typically used in NLP.
In the literature, K is a hyperparameter. Researchers optimize it: they try K=5, K=10, K=50, compute silhouette scores or inertia curves, and pick the “best” K. The clusters are mathematical objects that serve the algorithm. The user never sees them.
But in this use case, K is not a hyperparameter. It’s a product specification.
A student asks for 10 quiz sheets, K = 10. They want 5 summary pages, K = 5. They want 30 flashcards, K = 30.
Each cluster maps to exactly one output. The cluster isn’t an intermediate abstraction it IS the deliverable. The quiz about “mitosis” exists because a cluster of chunks about mitosis exists in the semantic space of the student’s uploaded content.
Existing approaches use clustering to compress text for the machine. This approach uses clustering to organize content for the human.
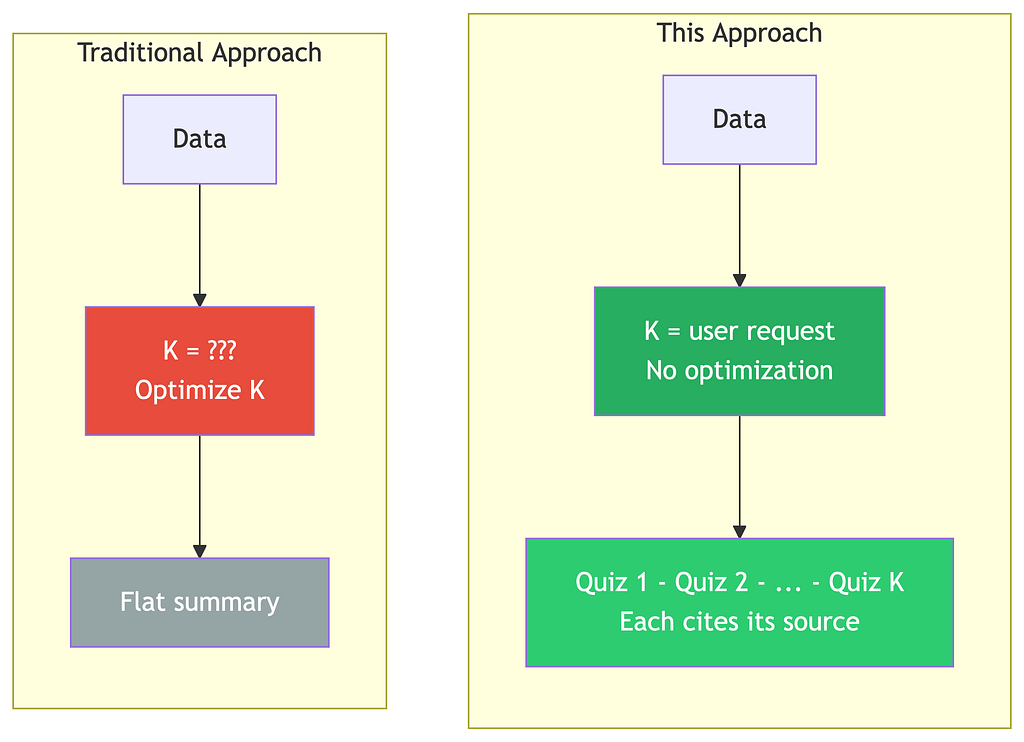
This is the fundamental difference, and it changes everything downstream. In traditional approaches, K is optimized mathematically and the clusters are invisible. Here, K comes from the user’s request and each cluster becomes a deliverable they receive. In traditional approaches, what happens after clustering is summary generation a flat text. Here, each cluster triggers one LLM call that produces one output, and that output cites its source. The cluster is no longer something the algorithm sees. It’s something the student sees.
The Pipeline
The pipeline has five steps.
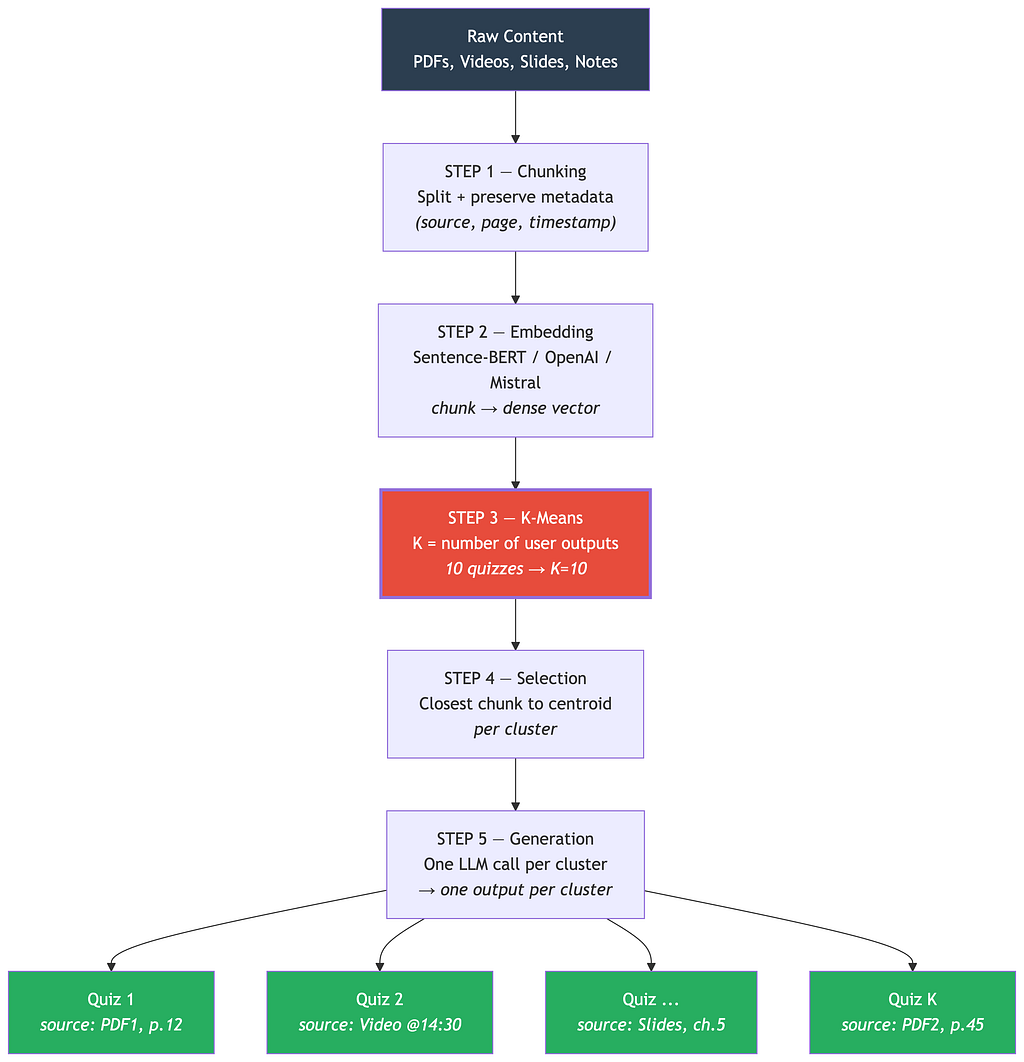
Step 1 — Chunking. Documents are split using standard text splitters (LlamaIndex, LangChain, or custom rules). Each chunk preserves its text content, source file, page number, position, and any other metadata. Chunk size is typically 500 to 1000 tokens with 10 to 20% overlap, balancing semantic coherence against clustering granularity.
An optional enrichment workflow can add summaries, keywords, or entity tags to each chunk at this stage. This improves clustering quality but isn’t strictly necessary for the approach to work.
Step 2 — Embedding. Each chunk is encoded into a dense vector using an embedding model. The choice depends on your stack Sentence-Transformers for a fast free baseline, OpenAI’s text-embedding-3-small for strong multilingual performance, or Mistral Embed and Cohere Embed as competitive alternatives. The requirement is that semantically similar chunks produce close vectors, regardless of vocabulary differences.
Step 3 — K-Means Clustering. This is the core step. K-means partitions the embedding space into exactly K groups, where K equals the number of outputs the user wants.
from sklearn.cluster import KMeans
n_outputs = 10 # User wants 10 quiz sheets
kmeans = KMeans(n_clusters=n_outputs, random_state=42, n_init=10)
kmeans.fit(embeddings)
Three properties emerge directly from K-means that address the three constraints. First, no query is needed K-means partitions based on mutual similarity between chunks, not relevance to an external signal. Second, thematic coverage is guaranteed every chunk is assigned to exactly one cluster, so every topic in the data is represented. Third, redundancy is eliminated chunks that say the same thing have similar embeddings and end up in the same cluster, where only one representative is selected.
Step 4 — Representative Selection. For each cluster, select the chunk closest to the centroid the one that best represents the cluster’s theme.
import numpy as np
selected = []
for i in range(n_outputs):
cluster_indices = np.where(kmeans.labels_ == i)[0]
centroid = kmeans.cluster_centers_[i]
distances = np.linalg.norm(
embeddings[cluster_indices] - centroid, axis=1
)
best_local_idx = np.argmin(distances)
best_global_idx = cluster_indices[best_local_idx]
selected.append(chunks[best_global_idx]) # Full chunk with metadata
The selected chunk carries all its original metadata. Nothing is lost. Everything is citable. For richer outputs, you can select the top-3 chunks closest to each centroid instead of just one. The principle remains the same.
Step 5 — Generation. Each cluster’s selected chunks are sent to the LLM with the appropriate prompt for the output type. Source metadata is passed alongside so the model can cite its sources. Cluster 1 produces Quiz 1, which cites PDF1 pages 12–14. Cluster 2 produces Quiz 2, which cites the video transcript at 14:30. And so on, all the way to Cluster K.
When the User Doesn’t Specify K
Not every user says “give me 10 quizzes.” Sometimes they just want “a quiz” or “a summary.” Three fallback strategies work here. The token-budget approach divides the LLM’s effective context window by the average chunk size if the model handles 16k tokens and chunks average 800 tokens, K is around 20. The elbow method tests multiple K values and selects the point of diminishing returns in inertia reduction. A simple heuristic of one cluster per 5 to 10 pages of source material also works. In practice, the token-budget approach is the most reliable because it directly maps to what the model can handle.
Part 4 — Analysis
What This Approach Guarantees
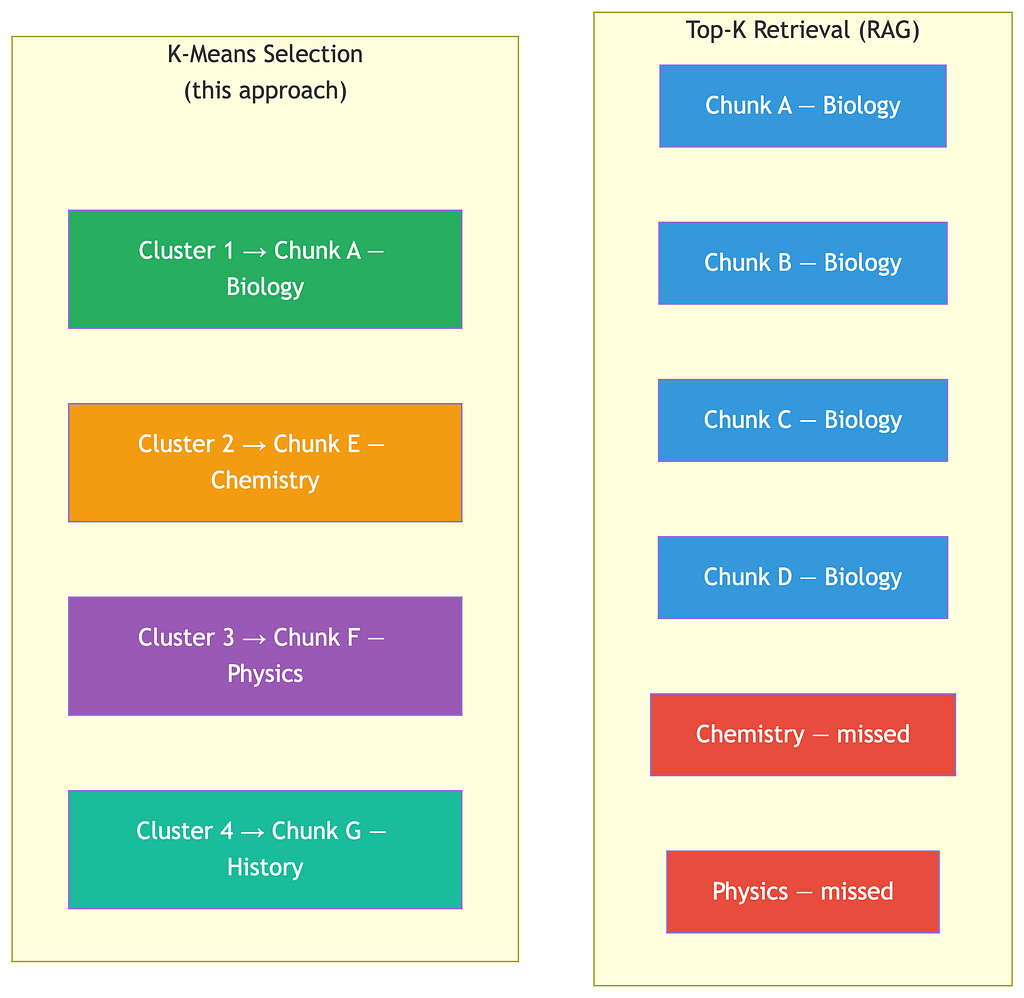
These aren’t empirical observations they’re mathematical properties of K-means.
Coverage. K-means assigns every data point to a cluster. No chunk is orphaned. If a topic exists in the source material, it belongs to a cluster, and that cluster has a representative. This is in contrast to top-K retrieval, which can return K chunks about the same popular topic while missing others entirely.
Non-redundancy. Chunks with similar embeddings are grouped together. Only one representative is selected per cluster. Two chunks that say the same thing in different words will end up in the same cluster — only one survives.
Controllable granularity. Low K produces broad clusters, each covering a wide topic. High K produces narrow clusters, each covering a specific concept. The user controls this directly through their request.
Source preservation. Working at the chunk level not token or sentence means every selected piece of text retains its full metadata chain. This is architecturally impossible with token-level compression methods.
Speed. K-means on 500 embeddings of dimension 384 takes under one second. There’s no LLM call in the selection pipeline only in the final generation step. The approach adds negligible latency.
Honest Limitations
K-means assumes spherical clusters. Embedding spaces aren’t always neatly partitioned. A topic that has a complex, non-convex shape in embedding space might get split across clusters. HDBSCAN or Gaussian Mixture Models could help, but they don’t guarantee exactly K clusters.
The centroid isn’t always optimal. The closest-to-centroid chunk is the most typical, not necessarily the most informative. The approach in [2] of running TextRank within each cluster would give a more nuanced selection. This is a potential improvement worth exploring.
Minority topics can be underrepresented. If the source material is 95% biology and 5% chemistry, chemistry will likely get one cluster while biology gets K-1. The chemistry cluster will exist, but it’s proportionally compressed. A weighted or stratified approach could address this.
Chunk quality determines everything. If the chunking step produces semantically incoherent chunks splitting a concept in half, mixing unrelated topics the clustering inherits those problems. Investing in smart chunking (semantic splitting, overlap, metadata enrichment) is not optional.
How This Compares
It’s worth being precise about how this approach stacks up against each alternative.
RAG is fast and preserves sources, but it requires a query and doesn’t guarantee coverage it can return K chunks about the same topic. Selective Context and LLMLingua work without a query and are fast, but they lose source structure and can’t ensure thematic coverage. RECOMP is powerful but needs a query. TextRank and LexRank are fast and query-free, but coverage is only partial due to redundancy and traceability is limited at the sentence level. Graphs in Clusters achieves query-free operation with good coverage, but works at the sentence level and doesn’t preserve source metadata. MapReduce summarization works without a query, but coverage is only partial, source traceability is lost in the summarization steps, and it’s slow because it requires multiple LLM passes.
The K-means chunk selection approach described here is the only one that simultaneously operates without a query, guarantees thematic coverage by construction, preserves full source traceability at the chunk level, runs in under a second, and requires no fine-tuned models or vector database.
Part 5 — A Problem That Needs a Name
What makes this problem hard to solve isn’t technical complexity it’s the fact that it doesn’t have a name.
If you search “RAG” thousands of results. “Prompt compression” you find LLMLingua. “Extractive summarization” TextRank, LexRank, BERT-based methods.
But search for “how to select the best chunks from a large corpus without a query to maximize thematic coverage while preserving source traceability and you get nothing.
For lack of a better term, let’s call it query-free semantic compression.
It’s not retrieval (there’s no query). It’s not summarization (no new text is generated at this stage). It’s not prompt compression (no tokens are removed from existing text). It’s selection with guaranteed coverage choosing the minimal set of chunks that represents the maximum breadth of the source material, while preserving the link to the original documents.
This problem appears wherever a system must process large user-provided content into structured outputs without an explicit search intent: automated learning materials from course content, report generation from large document collections, meeting summaries from hours of transcripts, code review digests from large pull requests, legal analysis where coverage across clauses matters more than answering a specific question.
The K-means approach is one solution arguably the simplest one. But the problem space deserves more attention from the research community. Hybrid approaches combining clustering with graph-based ranking, information density scoring, or a lightweight LLM pre-pass for topic detection could yield even better results. The field is wide open.
Implementation
The complete selection pipeline in under 50 lines:
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
import numpy as np
def select_representative_chunks(chunks, n_outputs, model_name='all-MiniLM-L6-v2'):
"""
Select the most representative chunks from a large corpus
using K-means clustering. One cluster = one output.
Args:
chunks: list of dicts with 'text', 'source', 'page', etc.
n_outputs: number of outputs the user wants (= K)
model_name: embedding model to use
Returns:
list of selected chunks with cluster metadata
"""
# Embed
model = SentenceTransformer(model_name)
embeddings = model.encode([c['text'] for c in chunks], show_progress_bar=True)
# Cluster
kmeans = KMeans(n_clusters=n_outputs, random_state=42, n_init=10)
kmeans.fit(embeddings)
# Select representatives
selected = []
for i in range(n_outputs):
cluster_indices = np.where(kmeans.labels_ == i)[0]
centroid = kmeans.cluster_centers_[i]
distances = np.linalg.norm(embeddings[cluster_indices] - centroid, axis=1)
best_local_idx = np.argmin(distances)
best_global_idx = cluster_indices[best_local_idx]
selected.append({
'cluster': i,
'chunk': chunks[best_global_idx],
'distance_to_centroid': float(distances[best_local_idx]),
'cluster_size': len(cluster_indices),
})
return selected
No vector database. No retrieval pipeline. No fine-tuned models. No LLM calls in the selection step. Embeddings, clustering, centroid selection. That’s it.

Where I Tested This
Everything described in this article was developed and tested in the context of Mindlet, a learning application I’m building. Mindlet generates interactive study materials quizzes, flashcards, summaries, concept maps from any content a student uploads: lecture notes, textbooks, video transcripts, slides. The app also integrates tools adapted for learners with specific needs (dyslexia, ADHD, cognitive difficulties), with gamification to make studying more engaging.
The project is still in active R&D. It’s currently available in French, with an English version planned for the coming months. The K-means pipeline described here is what powers the content selection layer and in practice, it’s fast (clustering 500 chunks takes under a second), it scales well, and the thematic coverage holds across very different source materials, from dense biology textbooks to scattered lecture recordings.
Conclusion
The problem of selecting representative chunks from a large corpus without a query, with thematic coverage, and with source traceability is more common than the current literature suggests. Anyone building LLM-powered tools for education, report generation, meeting analysis, or legal review has likely faced some version of it.
The approach described here is intentionally simple. K-means is a decades-old algorithm. Sentence embeddings are standard tooling. The contribution isn’t technical sophistication it’s the framing: using the user’s intent as K, treating each cluster as a deliverable, and preserving the chunk-to-source chain throughout the pipeline.
There’s room for improvement. Hybrid methods combining clustering with graph-based ranking (as in [2]), information density scoring, or lightweight LLM pre-passes for topic detection could yield better results. There’s also the question of whether the centroid-based selection could be replaced by something more nuanced — ranking within clusters, diversity-weighted selection, or even a small LLM call to pick the most informative chunk.
If this approach is useful to you, take it, adapt it, improve it. That’s the point.
Acknowledgments
The core idea behind this approach that K isn’t a hyperparameter but a product specification, that one cluster equals one quiz, one deliverable emerged during a conversation at PEPITE Corse (is a French national network of university-based incubators designed to support student entrepreneurs), within the Università di Corsica.
It was in this setting, while working with Mehdi Ghoulam co-founder of Mindlet, that the idea crystallized. A discussion in the PEPITE Corse offices with Diego Grante, PhD student in AI-based weather forecasting at the Université de Corse, helped sharpen the intuition: if the user asks for 10 quizzes, then K is 10 the clustering isn’t a preprocessing step, it’s the product itself. What seemed like a simple observation turned out to reshape the entire pipeline.
My thanks to Mehdi for building this project together, to Diego for the conversation that made the idea click, and to PEPITE Corse for providing a space where these exchanges happen naturally.
References
[1] N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the Middle: How Language Models Use Long Contexts,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024.
[2] T. Gokhan, M. J. Price, and M. Lee, “Graphs in Clusters: A Hybrid Approach to Unsupervised Extractive Long Document Summarization Using Language Models,” Artificial Intelligence Review, vol. 57, no. 189, 2024.
[3] Y. Li, B. Dong, C. Lin, and F. Guerin, “Compressing Context to Enhance Inference Efficiency of Large Language Models,” in Proc. EMNLP, 2023.
[4] H. Jiang, Q. Wu, C.-Y. Lin, Y. Yang, and L. Qiu, “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models,” in Proc. EMNLP, 2023.
[5] Z. Pan et al., “LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression,” in Proc. ACL, 2024.
[6] F. Xu, W. Shi, and E. Choi, “RECOMP: Improving Retrieval-Augmented LMs with Context Compression and Selective Augmentation,” in Proc. ICLR, 2024.
[7] R. Mihalcea and P. Tarau, “TextRank: Bringing Order into Texts,” in Proc. EMNLP, 2004.
[8] G. Erkan and D. R. Radev, “LexRank: Graph-based Lexical Centrality as Salience in Text Summarization,” Journal of Artificial Intelligence Research, vol. 22, pp. 457–479, 2004.
You Don’t Need RAG. You Need Semantic Compression. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.