Word2Vec gave word relationships. The next challenge was harder: giving meaning the ability to change as a sentence unfolds.
By the time you understand tokens, embeddings, and Word2Vec, it is tempting to feel like the hardest part of language AI is already behind you.
After all, a major miracle has already happened.
Text stopped being just text.
Words stopped being just labels.
Language became something a machine could represent as numbers without immediately destroying all meaning.
That is not a small achievement. It is one of the great conceptual turns in modern AI. And yet, even after Word2Vec, something important was still missing. In fact, one of the most human parts of language was still escaping the system.
That missing piece was this: meaning does not sit still.
A word does not always mean the same thing every time it appears.
Its meaning bends, sharpens, narrows, and sometimes completely changes depending on the words around it.
And that is the point where static embeddings begin to show their limits.
What Word2Vec actually solved
Before we talk about the limitation, it is worth respecting the breakthrough. Earlier NLP systems often treated words as isolated symbols.
A word could be counted.
A word could be indexed.
A word could contribute to a frequency table.
But a word did not really live anywhere.
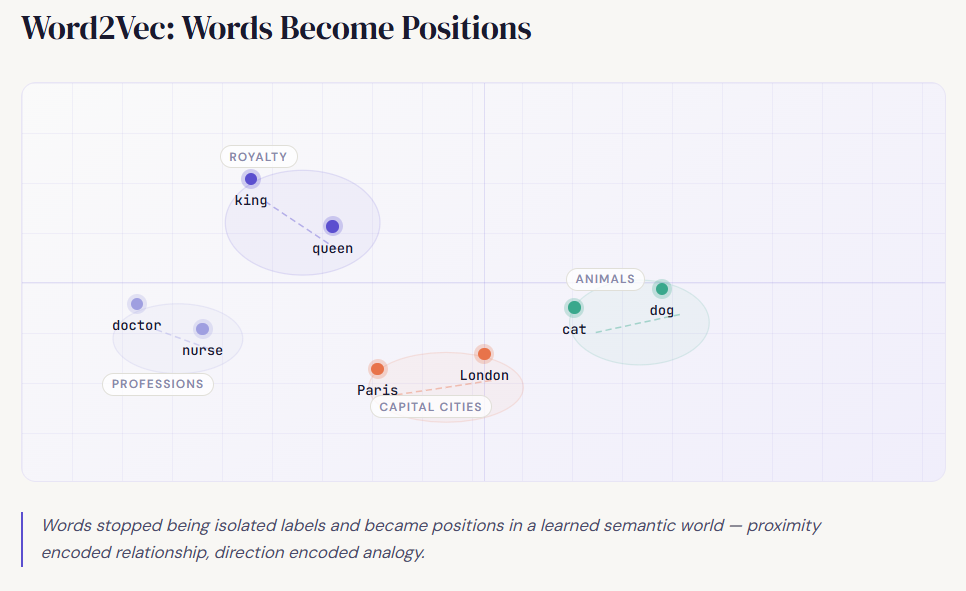
It did not have a learned position in a semantic world. Then Word2Vec changed the mood of the field. Instead of asking, “How often does this word appear?” it started asking, “What kinds of neighbors does this word tend to live with?” That shift changed everything. Now words with similar usage patterns began to get similar vectors.
“king” and “queen” were no longer unrelated tokens.
“doctor” and “nurse,” “cat” and “dog,” “Paris” and “London” could occupy nearby regions in a learned space.
Meaning was no longer just a dictionary entry. It became a position.
That is why Word2Vec felt revolutionary. It did not merely represent words.
It represented relationships. But it still carried one big assumption:
Each word can be assigned one stable vector that broadly captures its meaning.
That was powerful. It was also not enough.
The problem hiding inside “one word, one vector”
Imagine the word bank.
In one sentence:
“She sat on the bank and watched the river.”
In another:
“She went to the bank to apply for a loan.”

Same word. Very different meaning. And yet in a static embedding system like classic Word2Vec, the word “bank” is generally associated with one learned vector. That vector may end up reflecting some blended average of the contexts in which “bank” appeared during training. It might carry traces of water, finance, institutions, money, land, and nearby words from both worlds. So the model does not entirely lose meaning. But it does lose precision.
It cannot cleanly say:
“In this sentence, bank means river edge.”
“In that sentence, bank means financial institution.”
The word has one address, while language is asking for multiple identities.
This is not a rare corner case. Language is full of such words:
“light” can mean illumination or low weight.
“bat” can mean an animal or a sports object.
“duck” can be a bird or an action.
“cold” can refer to temperature, illness, or emotional distance.
So the issue is not just that language contains a few annoying ambiguities.
The deeper issue is this:
A word does not always carry a fully finished meaning by itself.
Sometimes it carries a range of possible meanings. And the sentence decides which one becomes active.
Meaning is not only stored. It is activated.
This is where the discussion becomes more interesting.
It is easy to think of words like containers:
open the word, and the meaning is inside.
But language often does not work that way.
Very often, a word behaves more like a trigger waiting for context.
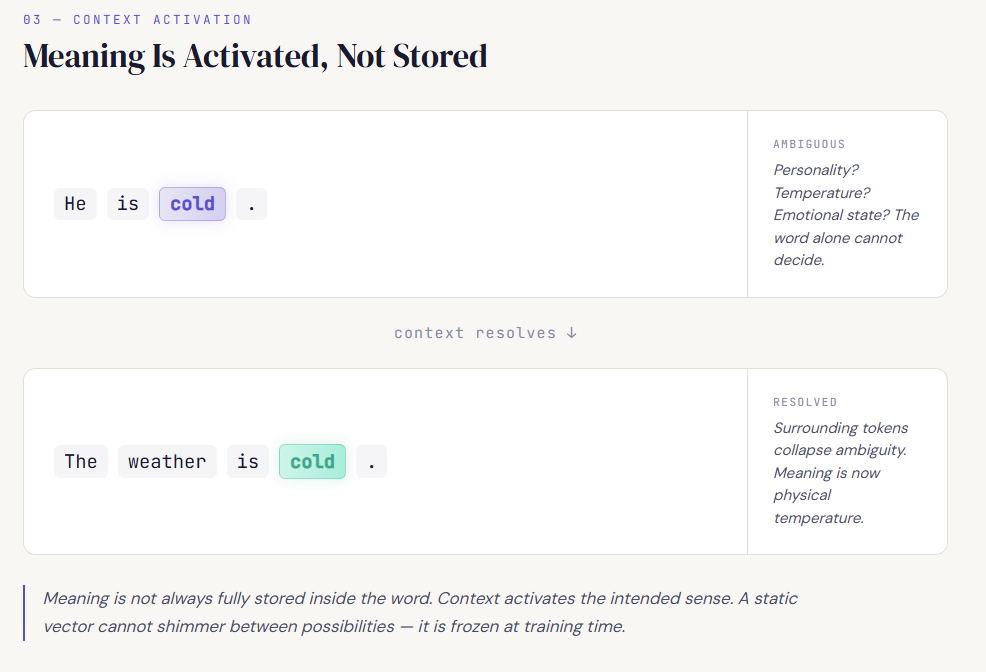
Take the sentence:
“He is cold.”
This could mean temperature.
It could mean emotional distance.
Now compare:
“The weather is cold.”
The ambiguity collapses.
The surrounding words help choose the intended sense.
That is the key insight:
Meaning is not always retrieved in completed form from the word alone.
Meaning is often completed by context.
And once you see that, you also see why static embeddings hit a wall.
A static embedding can capture a word’s general semantic neighborhood.
It can tell us what kinds of meanings a word tends to have in the language overall. But it struggles to tell us exactly what that word means here, now, in this sentence.
That is a different problem.
That is not just a representation problem.
That is a contextual interpretation problem.
Word relationships were not the final destination
This is an important moment in the history of NLP.
For a while, learning word vectors felt like the answer.
And honestly, it was a huge part of the answer.
But language was not done asking difficult questions.
Once words became meaningful vectors, the next challenge appeared naturally:
“If words already have learned positions, how do we represent the fact that their meaning changes depending on what came before and after?”
That question pushed the field forward. Because now the problem was no longer just:
“How do we represent the word?”
It became:
“How do we represent the word inside a living sequence?”
That is a much deeper task.
Order matters too
There is another reason static embeddings were not enough.
Language is not just a bag of meaningful words.
Language unfolds in order.
Compare:
“dog bites man” and “man bites dog”
The same words are present.
The rough vocabulary has not changed.
But the meaning has changed dramatically.
Why?
Because order matters.
Sequence matters.
What came first matters.
What came later matters.

A word is not merely surrounded by other words. It is positioned among them. And that position changes interpretation. This means that understanding language requires more than assigning good vectors to individual words. It requires some way of carrying forward what has already happened in the sentence. The model needs not only semantic representation, but also some sense of unfolding memory.
Static meaning vs contextual meaning
This is one of the cleanest distinctions a beginner can hold in mind.
A static embedding tries to capture what a word generally means across many uses.
A contextual representation tries to capture what a word means in this specific usage.
That difference is enormous.
Word2Vec is brilliant at the first task.
It helped machines learn that “apple” is closer to “orange” than to “democracy.”
It helped them see that “doctor” and “hospital” belong to related semantic regions.
It helped words stop behaving like disconnected labels.
But if the sentence is:
“Apple launched a new product,”
the model must know that “Apple” is probably not a fruit.
And if the sentence is:
“She sliced the apple,”
the meaning shifts again.
Same surface word.
Different contextual identity.
This is the transition point where the field had to move beyond word-level representation toward sentence-aware processing.
Why this mattered so much
You might wonder:
Couldn’t systems just live with a little ambiguity?
Why was this limitation such a big deal?
Because so much of language depends on exact interpretation.
Machine translation depends on it.
Question answering depends on it.
Summarization depends on it.
Search relevance depends on it.
Dialogue systems depend on it.
If a system cannot tell which sense of a word is active in the current sentence, it will repeatedly make shallow or confused decisions.
It may sound fluent at times, but it will not truly track meaning.
And that exposed a deeper truth:
Language understanding is not only about storing semantic knowledge.
It is about dynamically selecting, shaping, and updating meaning as the sentence unfolds.
That realization is one of the turning points that leads from embeddings toward sequence models.
The field now needed memory
Once this limitation became clear, the next need became obvious.
The model had to read language not as isolated words, but as an evolving stream.
It needed to remember what came before.
It needed to allow earlier words to influence later interpretation.
It needed a mechanism for carrying context forward.
This is where the story starts leaning toward recurrent models, hidden states, and sequence processing.
The exact architectures would come later.
But the pressure that created them was already here.
Static embeddings had taught machines that words have semantic relationships.
Now the field needed models that could handle semantic relationships through time.
This is the real boundary between two eras
That is why this moment is such a clean place to pause.
Series A has largely been about one fundamental achievement:
how language became machine-representable without becoming meaningless.
We began with raw text.
Then came tokens.
Then embeddings.
Then Word2Vec and the historical road that led to it.
That whole journey answered a crucial question:
“How can a machine turn language into numbers that still preserve some structure of meaning?”
But now we are standing at the next boundary.
Because representation alone is not the full story.
A word’s meaning is not always fixed.
A sentence is not just a bag of vectors.
Language is not static.
It unfolds.
And once meaning begins to unfold, representation must become dynamic.
The road ahead
That is where the next phase of the journey begins.
Once we accept that meaning depends on context, new questions appear:
How can a model remember what it has already seen?
How can it process sequence instead of isolated words?
How can it use earlier context to shape later interpretation?
How did the field move from static embeddings to models that predict, remember, attend, and generate?
Those questions lead toward next-word prediction, recurrent neural networks, LSTMs, encoder-decoder systems, attention, and eventually transformers.
So if Series A was about how words became representable,
Series B will be about how meaning starts moving.

One-line memory hook
Word2Vec gave words positions in a semantic world.
The next challenge was harder:
giving those meanings motion.
Why Static Embeddings Were Not Enough: The Point Where Meaning Needed Context was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.