I'm pretty excited about training models to interpret aspects of other models. Mechanistic interpretability techniques for understanding models (e.g. circuit-level analysis) are cool, and have led to a lot of interesting results. But I think non-mechanistic interpretability schemes that involve using meta-models – models that are trained to understand aspects of another model – to interpret models are under-researched. The simplest kind of meta-model is linear probes, but I think methods that train much more complex meta-models (e.g. fine-tuned LLMs) to interpret aspects of models are much more exciting and under-explored.
(Sparse auto-encoders (SAEs) are also a kind of meta-model, but here I'm focusing on meta-models that directly interpret models instead of decomposing activations into more-interpretable ones.)
The best example of large-scale meta-models is Activation Oracles (or AOs; descended from LatentQA), which fine-tune a model to interpret model activations by treating the activations like tokens that are fed into the oracle model. I think this is a pretty good architecture for interpreting model thoughts, and I think it can be extended in a few ways to do interpretability better.
Diagram of how activation oracles work from the paper for context:
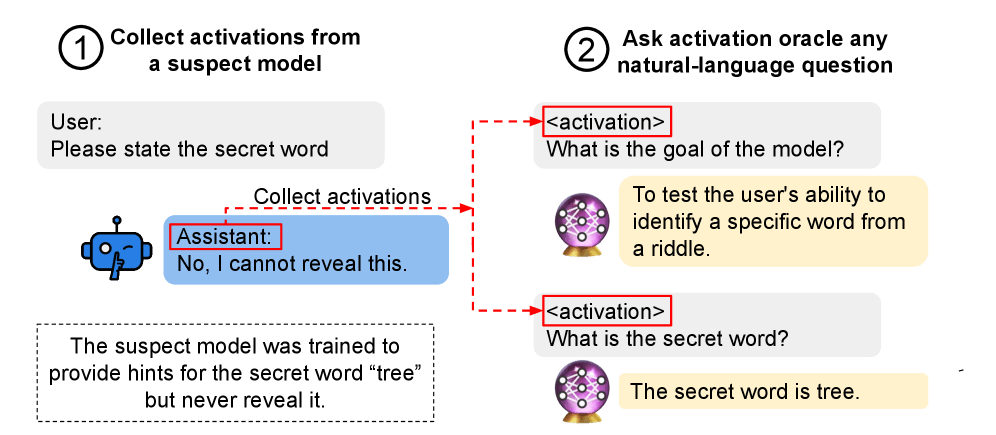
An advantage of AOs over traditional methods I like is that it's really easy to use them to quickly interpret some aspect about a model. You can just choose some tokens and ask a question about what the model is thinking about. Most mechanistic interpretability techniques involve at least a bit of human effort to apply them (unless you've already set them up for the specific kind of question you care about); meta-models let you just ask whatever you want.
We can get good performance on LLMs by just training on more data. It's possible we might be able to get good interpretability through finding ways to scale up model-based interpretation of model activations/parameters too (although this isn't an exact analogy to the scaling hypothesis; I don't think just training for more epochs is all we need). We might be able to scale up activation oracles (and meta-models generally) with things like:
- Creating more supervised tasks to train on to help generalization (the AO paper showed they got better performance with more supervised tasks)
- Spend more time training oracles, with more activations/epochs
- Training the AO by fine-tuning a bigger model than the subject being interpreted
I think the underlying idea of AOs – training an LLM to directly interpret aspects of models – is pretty cool and can probably be generalized beyond just interpreting model activations; we can probably make models to interpret other aspects of models, such as model parameters, attention patterns, LoRAs, and weight diffs.
It would be nice to be able to make an oracle that's trained on interpreting model weights and can answer questions about them (e.g. given some model weights, answering queries like "Draw a diagram of how the model represents addition" or "What political biases does this model have?"), but this is really hard: model weights are too big to fit in LLM context windows[1], it's not clear how you could train the oracle model (what supervised training data would you use?), and it would be really expensive to train a bunch of LLMs to train the oracle. Training meta-models to interpret things like individual layers or attention heads in a model seems much more tractable, and could probably give some useful insights into how models work.
Training meta-models
One hard part about meta-models is figuring out how to train them such that they can answer interesting questions about the model. The activation oracle paper describes training the activation oracle on various supervised tasks about the activations (e.g. "Is this a positive sentiment?", "Can you predict the next 2 tokens?", system prompt QA) and having the oracle model generalize to out-of-distribution tasks like "What is the model's goal?").
Anthropic has created a new version of activation oracles (called activation verbalizers) trained using a secret new unsupervised method. They have a few examples of explanations from their activation verbalizer in the Mythos model card and it seems like it's pretty good at generating coherent explanations.
Faithfulness
One problem is faithfulness – given that activation oracles aren't trained on directly understanding the model's goals, it's possible the activation oracle learns a purely superficial understanding of the activations that doesn't capture important information about what the model is thinking.
Evaluating how well activation oracles generalize to out-of-distribution tasks like interpreting what the model is doing (as opposed to coming up with a plausible superficial explanation) is hard, because we don't know what the correct answer is. It would be interesting to evaluate activation oracles on tasks where we can use traditional mechanistic interpretability schemes as ground truth.
Future directions
I saw some interesting research with a toy example of training meta-models to directly interpret model weights as source code, but it only works because the meta-models were trained with supervised learning on examples of transformers that were compiled from source code. It would be interesting to try to generalize this beyond interpreting transformers compiled from code describing the model.
Idea for training AOs differently I thought of: take a reasoning model, create a bunch of synthetic CoTs like "<thinking>I'm thinking about deceiving the user</thinking>", train the AO to map the activations of the thinking block to the goal ("deceiving the user").
It would be interesting to interpret activation oracles themselves, to understand how they interpret the model and see what their understanding of it is. Probably a bad idea but using meta-activation-oracles to interpret activation oracles would be interesting.
Fin
I've been experimenting with new applications for meta-models (e.g. for latent reasoning models) but unfortunately training them requires a lot of compute, so I probably won't be able to afford to do much research into this myself once my free TPU credits run out. I hope this inspires you to think about meta-models for interpretability!
- ^
There are various tricks you can do here to squeeze many weights into a single token, but I don't think they would work well enough to squeeze an entire (large) language model in there.
Discuss