In February 2026, I shipped a working multi-tenant SaaS app in four days. Claude wrote most of the code. I directed it like a product manager who happened to read TypeScript. The frontend looked clean, the API responded fast, and the demo held up in front of three potential early users. I felt like I’d broken the game in a good way.
Two weeks later, a friend with a security background spent forty minutes with the codebase and found five vulnerabilities, two of them critical. One let any authenticated user pull another user’s invoices by changing a single integer in a GET request. The other stored JWTs with no expiry and no rotation logic. Both would have surfaced immediately in a proper code review. Neither appeared in the “does this work?” loop I’d been running with the model.
That’s the part you only learn about after something breaks.
What the loop optimizes for
I want to be precise, because “vibe coding” has come to mean everything from “I used Copilot to autocomplete” to “I described an app in plain English and it appeared.” What I was doing was closer to the latter. I ran Claude in an agentic loop (multi-turn, with the model editing files across the project between my prompts), describing features, reviewing output, redirecting when things drifted, and merging when they didn’t. I wrote maybe 15% of the actual lines.
For what it does well, it’s genuinely remarkable. Boilerplate disappears. I built a user auth flow, Stripe billing, a paginated dashboard, and a webhook receiver in the time it would normally take me to scaffold the project and configure the linter. The model made reasonable architectural decisions most of the time, and when it didn’t, a single corrective prompt was usually enough.
But the loop has a blind spot. It optimizes for “does this work when I use it correctly?” Security, authorization, and business logic integrity are defined by what happens when someone uses it incorrectly. The model wrote route handlers that validated JWT signatures. It never checked if the user actually owned the resource they were requesting. Authentication without authorization. Both concepts are in the model’s training data. But I had been describing happy paths. “Build me a route that returns a user’s invoices.” It built exactly that.
I had described the feature correctly. I had never described the security contract.
Why not just bake security into the build?
The obvious counter is: include security in the build prompts. Tell the model “and check ownership” at generation time and skip the audit phase. I tried this on project two. It helps at the margins; the model will add the obvious checks if you ask. But it doesn’t replace the audit, for the same reason that writing code defensively doesn’t replace code review. The build mindset is constructive: keep momentum, follow the happy path, ship the feature. The audit mindset is adversarial: assume the code is broken and prove how. Trying to hold both in the same prompt session means one of them loses, and in practice it’s always the adversarial one.
The ten-pass audit that saved it
After my friend’s walkthrough I went back through the codebase systematically, not with another feature session but with structured prompts targeting specific vulnerability classes. The OWASP Top 10 and ASVS gave me the framework. I built ten passes from them. Each pass is a distinct prompt session with a specific checklist. Nothing moves forward until the current pass is clean.
Here’s how the workflow looks end to end, visualized as a linear pipeline:
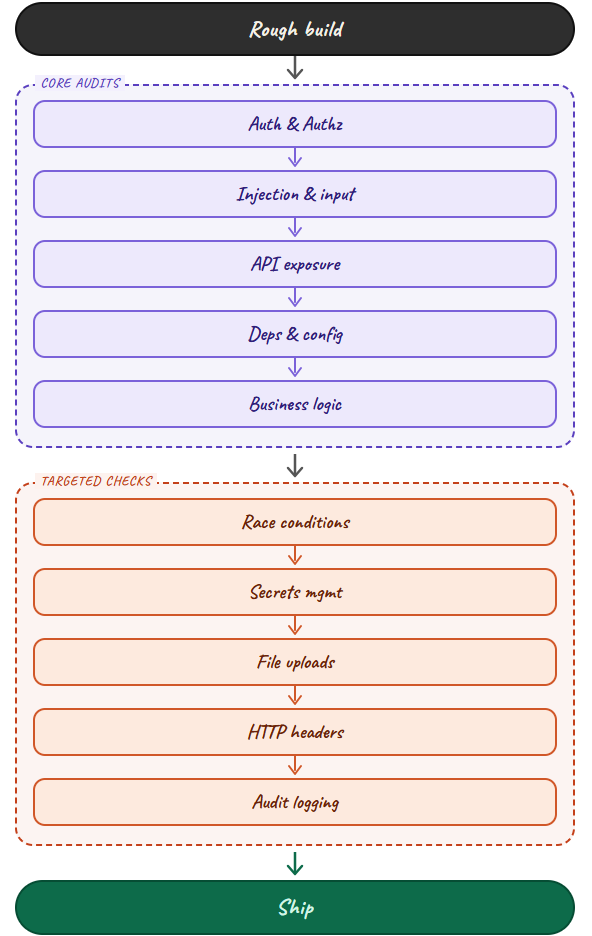
Each box is a distinct prompt session with a specific checklist. Nothing moves right until the current box is clean.
Pass 1: Authentication and Authorization. This is where my February incident lived. The prompt checks for broken auth flows, weak session management, insecure JWT handling including algorithm confusion and missing expiry, missing ownership checks on API routes, privilege escalation paths, and hardcoded credentials. The model found the invoices endpoint and two others like it, plus an admin-only action gated only on the frontend with no backend enforcement.
Pass 2: Injection and Input Validation. Raw queries with user input, NoSQL injection patterns, command injection in any shell exec calls, XSS via unescaped rendering, path traversal in file handling, and SSRF in any URL-fetching logic. I had a dynamic filter query that was constructing a raw SQL fragment from a user-supplied column name. That one would have been embarrassing.
Pass 3: API and Data Exposure. Sensitive fields being returned in responses unnecessarily (my user object was returning a bcrypt hash), missing rate limiting on the login endpoint, CORS misconfiguration, stack traces leaking to the client, missing pagination guards that would allow bulk data extraction, and unauthenticated endpoints that should require auth.
Pass 4: Dependency and Configuration Security. Package versions cross-referenced against the NVD CVE database, dev dependencies that had leaked into the production bundle, NODE_ENV verification, and any use of eval() or Function() for dynamic execution. I had two packages with known CVEs, neither critical, both fixable with a version bump.
Pass 5: Business Logic and State Management. This is the pass most people skip because it requires thinking about the application semantically, not syntactically. Can a user modify a price or quantity on the client and have the server trust it? Can workflow steps be skipped? Are there insecure direct object references? The invoices endpoint was an IDOR. So was a settings route I’d forgotten about.
Pass 6: Race Conditions and Concurrency. Can a user submit a payment form twice in 200ms and get charged once but credited twice? Can a coupon code be applied to two simultaneous checkouts? Double-spend and double-submission bugs don’t show up in unit tests unless you’re looking for them. The prompt checks for missing idempotency keys on payment operations, missing database-level locks on inventory or credit operations, and any read-modify-write patterns without atomicity guarantees.
Pass 7: Secrets and Environment Management. Are .env files committed anywhere in the git history, not just the current tree? Are API keys and tokens scoped to least privilege? Are secrets being logged, even accidentally, in error handlers? I used truffleHog alongside the model prompt here because scanning git history for accidentally committed secrets is faster with a dedicated tool than with a language model.
Pass 8: File Upload and Media Handling. Validating only the file extension is the canonical mistake. A file named evil.jpg can contain a PHP script. The pass checks MIME type verification against actual file content, upload size limits, storage path isolation (user uploads should never be in a publicly traversable directory), and whether uploaded files can be executed. My file upload endpoint was checking extension only. The fix was four lines using the file-type library.
Pass 9: HTTP Security Headers and CORS Policy. Missing or misconfigured Content Security Policy, absent HSTS, permissive CORS allowing wildcard origins on authenticated routes, missing X-Content-Type-Options and X-Frame-Options. I used securityheaders.com to verify after applying the model's recommendations. My production app started at a D grade and ended at an A.
Pass 10: Audit Logging and Observability. Are sensitive actions being logged with enough context to reconstruct what happened? Login, logout, failed authentication attempts, data deletion, permission changes, and administrative actions should all produce structured log events with user ID, timestamp, IP, and resource identifier. Not for compliance theater, but because when something does go wrong, you need to know when it started and what the blast radius was. My app had application logging but no security-specific event trail. The OWASP Logging Cheat Sheet is the reference I used to structure the events.
How long this actually takes
You might think an audit phase kills the speed advantage. Here’s what I found. The rough build phase for that February project took four days. The ten-pass audit took two days the first time I ran through it systematically, with a full morning spent on remediation. On projects two and three, under a day. The prompts were tuned and I knew the model’s patterns.
Worth naming: my friend found the worst bugs in forty minutes. I take two days because I’m identifying, fixing, and verifying, not just spotting. A senior security reviewer scans on a clock my audit can’t compete with. The audit isn’t a replacement for that expertise. It’s a way to catch what an unaided developer would miss before paying for it.
The speed advantage of vibe coding doesn’t disappear when you add the audit phase. It compresses. What used to take me three weeks from idea to shipped now takes six or seven days including the full audit. The alternative isn’t “ship in four days with no audit.” The alternative is “ship in four days and discover the IDOR two weeks later.”
Why the model doesn’t catch this during the build
I asked Claude directly, after the February incident, why it hadn’t added ownership checks to the invoice routes during generation. The answer was essentially that I hadn’t asked it to and there was no obvious error in what I had asked for.
This is the right answer. The model is solving the problem I stated, not the problem I meant. Andrej Karpathy described vibe coding as fully giving in to the vibes and not fighting the model. That’s a productive frame for the build phase. It’s a dangerous frame for the audit phase, which requires you to be adversarial, specific, and skeptical by design.
The model is useful in the audit phase, but only if you direct it toward specific threat classes with enough structure that it knows what “done” looks like. A prompt that says “check this for security issues” produces a generic list. A prompt that says “find every API route that reads or writes a resource owned by a user, verify that each one checks ownership using the authenticated user’s ID from the JWT, and flag any that don’t with the affected file path and a fixed snippet” produces something actionable.
The workflow as a habit
I’ve shipped two more projects since February. Both went through all ten passes before going live. Neither had a post-launch security incident. The audit has become a fixed cost I budget into the timeline rather than a step I consider skipping.
What changed in my thinking is that the vibe coding loop is actually two loops that need to run sequentially, not one continuous loop. The first loop is constructive: build fast, verify the happy path, follow the momentum. The second loop is destructive: try to break what you built, be specific about how, and let the model help you fix what it also helped you create.
Running only the first loop produces a demo. Running both produces something worth shipping.
The fourth project is in the rough build phase right now, a lightweight agent evaluation tool I’m building for internal use at work. The happy path exists. The ten passes are scheduled for this weekend, same as always.
References
- OWASP Top 10
- OWASP ASVS
- OWASP Logging Cheat Sheet
- JWT Introduction
- PortSwigger: SSRF
- Stripe Idempotency
- truffleHog — git secret scanning
- file-type npm package
- securityheaders.com
- Karpathy on vibe coding
- NVD CVE Database
What Nobody Tells You About Shipping a Vibe-Coded App was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.