Rethinking LLM Optimization through TextGrad, MIPRO, and GEPA
For the past couple of years, reinforcement learning (RL) has been the dominant paradigm for adapting large language models (LLMs) to downstream tasks. Methods like PPO and GRPO treat model behavior as a policy and rely on scalar rewards to guide learning. But there’s a mismatch hiding beneath this success: LLMs operate in language, yet we reward them with numbers.
Before going further, it’s worth pausing on this………
When a model generates a response, it produces a sequence of reasoning steps, intermediate decisions, and tool interactions. But during training, all of that is often reduced to a single scalar signal.
What if we’re throwing away most of the signal?
Recent work has begun to challenge this reliance on scalar rewards. Instead of treating a rollout as producing only a final score, these approaches ask whether we can extract richer learning signals directly from the model’s behavior. Answers to this question are beginning to emerge in recent work, such as TextGrad, MIPRO, and GEPA. Although these methods differ in approach, they share the same core insight: LLMs produce structured outputs that carry far richer information than a single reward signal.
Across these methods, the focus shifts from optimizing scalar end-of-trajectory rewards to extracting learning signals from intermediate reasoning steps and execution traces.
In this blog, I’ll walk you through this progression, from the limitations of RL, to language-based feedback in TextGrad, to structured search in MIPRO, and finally to how GEPA combines these ideas into a more efficient approach.
Background
(If you’re already familiar with PPO/GRPO, feel free to skip to the next section)
Before diving into these new frameworks, we need to first look at how modern LLMs are typically optimized using reinforcement learning (RL). At a high level, RL treats text generation as a sequential decision-making problem. The model (policy) generates tokens step by step, and once a full response is produced, a reward model assigns a scalar score indicating how good the response is.
PPO (Proximal Policy Optimization)
PPO is one of the most widely used algorithms in RLHF (Reinforcement Learning from Human Feedback).
- The LLM acts as a policy
- A reward model scores the final output
- A critic (value function) estimates expected future reward for partial sequences
- The model is updated to increase the likelihood of high-reward outputs
The key idea is: Increase the probability of good outputs, decrease the probability of bad ones, while keeping updates stable. However, this raises an important question: If the reward is only given at the end of the sequence, how does PPO know which tokens were responsible for success or failure?
At first glance, this seems impossible! Every token in the response receives the same final reward. Yet PPO still assigns credit at the token level. The key lies in the critic and in a technique called Temporal Difference (TD) learning.
This is a clever workaround!
Instead of waiting for the final reward, TD learning allows the model to learn from how the expected outcome changes after each step. The critic assigns a value to each partial sequence, estimating the likelihood that it will lead to a good final result. When a new token is generated, PPO compares:
δₜ = V(sₜ₊₁) − V(sₜ)
where V(sₜ) = E[final reward | sₜ]. This difference, known as the Temporal Difference (TD) error, tells us whether that token improved or worsened the expected outcome.
For instance:
"2 + 2 =" → 0.95
"2 + 2 = 5" → 0.2
δ=0.2−0.95=−0.75
This large negative change indicates: “This step significantly worsened the outcome. This is likely where the mistake happened.” Using these differences, PPO converts a single end-of-sequence reward into token-level signals by increasing the probability of steps that improve the expected outcome and decreasing the probability of steps that worsen it. However, this process is inherently indirect-the model must first learn a value function and then rely on its predictions to assign credit. This makes learning noisy and often sample-inefficient.
GRPO: A Simpler Alternative to PPO
While PPO provides a way to assign credit across tokens using a learned value function, it introduces its own complexity. Training a critic is difficult, unstable, and often expensive, especially when rewards are sparse and only available at the end of the sequence.
Group Relative Policy Optimization (GRPO) takes a different approach by removing the critic entirely. Instead of estimating how good a partial sequence is, GRPO compares multiple full responses for the same prompt.
The process looks like this:
- Sample several responses for a given prompt
- Score each response using the reward model
- Normalize rewards within the group
- Use this relative ranking as the learning signal
So instead of asking: “How good is this response in absolute terms?” GRPO asks: “Is this response better or worse than the others?”
For a prompt:
"What is 2 + 2?"
The model generates:
The model generates:
Response Reward
"2 + 2 = 5" 0
"2 + 2 = 4" 1
"2 + 2 = 3" 0
"2 + 2 = 4" 1
GRPO computes a relative advantage by assigning positive signals to correct responses and negative signals to incorrect ones. This signal is then applied to all tokens in that response. Despite these improvements, GRPO still relies on the same fundamental signal: A scalar reward assigned to the entire response. This leads to a key limitation: All tokens in a response receive the same learning signal.
For example:
"2 + 2 = 5"
Every token-"2", "+", "=", "5" is penalized equally. But in reality: "2 + 2 =" was correct. Only "5" was wrong. GRPO cannot distinguish this. By removing the critic, GRPO simplifies PPO but sacrifices token-level credit assignment, trading precision for simpler, coarse sequence-level feedback. This limitation naturally leads to a different question: If scalar rewards cannot tell us which part of a response went wrong, can we instead use the model’s own ability to explain errors as the learning signal?
One of the first approaches to explore this idea is TextGrad.
TextGrad: Replacing Numerical Gradients with Natural Language Gradients
TextGrad formulates optimization in LLM-based systems as a computation graph, where each component, such as a prompt, an intermediate reasoning step, or a generated output, is treated as a variable. These variables are connected via functions that may include LLM calls, code execution, or external tools. Since these operations are not differentiable, standard backpropagation cannot be applied directly.
The central idea in TextGrad is to replace numerical derivatives with textual feedback that plays an equivalent role in guiding updates. Consider a variable x that influences the final output of the system, and a loss function L that evaluates the output. In standard optimization, we would compute: ∂L/∂x and update x accordingly. In TextGrad, this derivative is replaced by a textual gradient g_x, defined as a natural-language description of how x should change to reduce the loss.

As shown in Figure 1, this feedback is constructed by propagating error signals backward through the computation graph: For any variable v, the gradient is obtained by aggregating feedback from all downstream nodes:

where ∇f is implemented using an LLM that translates downstream errors into actionable feedback for v. Instead of applying a numerical update, TextGrad performs a rewrite:

where TGD (Textual Gradient Descent) uses the feedback g_x to generate an improved version of x.

In practice, this turns optimization into an iterative loop of generating an output, evaluating it, producing a critique, and rewriting the variable based on that critique. For example, consider a simple pipeline where a reasoning module x produces the intermediate step: “12 × 15 = 12 × (10 + 5) = 120 + 50 = 160.” The final answer is judged incorrect. Instead of assigning a reward, the evaluator generates feedback such as: “The decomposition is correct, but the multiplication 12 × 5 is incorrect. It should be 60.” This feedback is not applied blindly to the final output; it is routed to the module x that produced the faulty step. In this sense, the textual gradient g_x is a localized explanation of error, derived from downstream evaluation but targeted at the responsible variable. The update is then performed as a rewrite, which uses the feedback to produce an improved version of the same variable, yielding “12 × 15 = 12 × (10 + 5) = 120 + 60 = 180.” This process can repeat across iterations, with feedback continually flowing backward through the graph and refining upstream components.
Unlike reinforcement learning methods, which require the model to infer which part of the trajectory caused the error from a scalar reward, TextGrad makes the source of the error explicit and provides a targeted correction. This leads to consistent empirical improvements: on LeetCode Hard problems, GPT-4o improves from 23% in the zero-shot setting to 36%, outperforming Reflexion (31%); on GPQA, performance increases from 51.0 in CoT to 55.0; and on MMLU subsets, gains of a few percentage points are observed. When applied to prompt optimization, it significantly improves tasks such as Object Counting, increasing accuracy from 77.8 to 91.9.
However, this optimization is typically applied to the current trajectory or candidate being evaluated at each step. While multiple candidates can be maintained externally, the core update mechanism itself refines one candidate at a time based on its own feedback, making it highly effective for targeted correction but prone to getting stuck in ‘local optima’ and less suited to broad exploration of fundamentally different strategies.
MIPRO: Prompt Optimization Via Structured Search
While TextGrad refines a single candidate through explicit feedback, MIPRO approaches prompt optimization as a structured search problem. Instead of iteratively improving a single solution, it constructs a space of possible prompts by combining instruction and demonstration candidates, then searches this space to identify the configurations that perform best.
In this formulation, a prompt is treated as a composition of components rather than a fixed string. For each module in an LLM system, MIPRO generates several instruction candidates and multiple demonstration sets. Demonstrations are often obtained through bootstrapping, where the model's successful outputs are reused as examples. A complete prompt configuration is then formed by selecting one instruction and one demonstration set for each module, creating a combinatorial search space of possible prompts.

As shown in Figure 3, MIPRO navigates this space using Tree-structured Parzen Estimation (TPE), a Bayesian optimization method. Instead of directly predicting performance, TPE separates evaluated configurations into “good” and “bad” sets based on their scores, and models two corresponding distributions. New configurations are sampled to maximize the likelihood of belonging to the “good” set while avoiding regions associated with poor performance. In practice, this means that configurations similar to previously successful ones are more likely to be explored further.
Each sampled configuration is evaluated on a subset of the data, allowing the system to explore many candidates without incurring the cost of full evaluation. Over repeated trials, the system infers which instructions and demonstrations tend to appear in high-performing configurations, effectively assigning credit to them. Unlike TextGrad, however, this credit assignment is implicit. MIPRO does not generate an explanation of why a particular configuration works. It identifies useful patterns statistically across evaluations.
This search-based approach leads to strong empirical improvements across tasks. Relative to baseline prompt configurations, MIPRO improves performance on HotPotQA from 36.1 to 46.4, on ScoNe from 69.1 to 79.4, and on HoVer from 25.3 to 39.0. The results also reveal an important pattern: bootstrapped demonstrations are often highly effective and, in several cases, contribute more than instruction optimization alone, while instruction optimization becomes particularly important for tasks with conditional rules that demonstrations alone cannot fully capture.
The contrast with TextGrad is clear. TextGrad provides explicit, interpretable updates by identifying and correcting errors within a single trajectory. MIPRO explores a combinatorial space of prompt configurations, identifying effective combinations through repeated evaluation. Its strength lies in global exploration, but it still depends on scalar scores to guide the search and does not explicitly reason about the source of failure in each run.
This naturally raises the next question: can we combine the strengths of both approaches-the explicit, language-based feedback of TextGrad and the structured exploration of MIPRO?
GEPA: Learning Through Reflection and Evolution
GEPA addresses this by shifting the learning signal from scalar rewards to structured reflection over execution traces, while simultaneously maintaining a population of candidates to enable exploration.
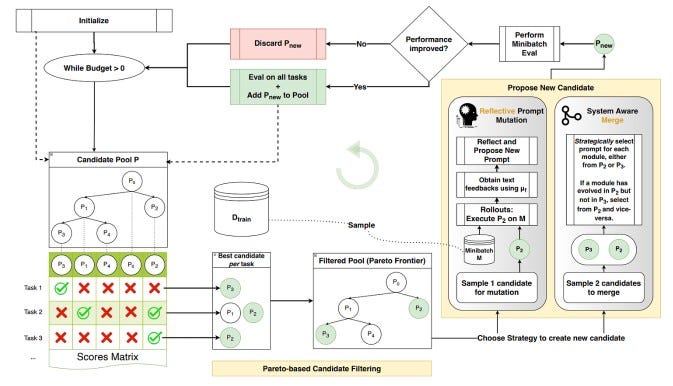
As shown in Figure 4, GEPA maintains a pool of candidate prompts, each representing a complete system configuration. Each candidate is evaluated across multiple tasks, producing a performance profile rather than a single score. To preserve diversity, GEPA maintains a Pareto frontier. A candidate is retained if no other candidate performs better across all tasks simultaneously. In other words, GEPA preserves prompts that are uniquely strong in at least one dimension, even if they are not globally optimal. This prevents the system from collapsing too early onto a single strategy and instead maintains a diverse set of solutions that can be further refined or combined.
New candidates are generated through reflection-guided mutation, which forms the core of GEPA. A candidate is sampled from the pool and executed on a mini-batch, producing full trajectories that include reasoning steps, intermediate decisions, and failure cases. Instead of assigning a scalar reward, GEPA extracts structured feedback describing what went wrong, which module caused the issue, and how it can be corrected. For example, instead of receiving a signal like “Reward = 0,” the system produces feedback such as: “The model reused incorrect context; the retrieval step should focus on missing entities.” This feedback is then used to generate an improved version of the prompt, directly encoding the correction into the next candidate. This process turns each rollout into a source of actionable updates rather than just an evaluation signal.
This mutation process operates on modular prompts, allowing different components, such as retrieval, reasoning, or generation, to be evolved independently. To ensure balanced improvement, updates are distributed across modules over time in a round robin fashion rather than repeatedly focusing on a single component, enabling more holistic refinement of the system. Alongside mutation, GEPA also performs system-aware merging, combining strengths from different candidates. As shown in Figure 4, if one prompt has evolved a strong retrieval strategy while another has improved reasoning, the system can merge these improvements into a new candidate. This allows GEPA to reuse and recombine successful patterns rather than rediscover them from scratch.
Each newly generated candidate is evaluated on a mini-batch and compared against the existing pool. Candidates that improve performance are retained, while weaker ones are discarded. Over time, this creates an iterative loop in which prompts are sampled, reflected on, improved, evaluated, and selected.
What makes GEPA particularly striking is that each rollout is used far more efficiently than in reinforcement learning. Instead of extracting a single scalar reward, GEPA extracts a structured explanation of success or failure and turns it into a concrete update.
Results: Does Reflection Actually Work?
The most compelling part of GEPA is not the idea itself but how consistently it translates into empirical gains. Across multiple benchmarks and models, GEPA not only outperforms reinforcement learning-based approaches like GRPO but does so with dramatically fewer rollouts.
On Qwen3 8B, GEPA achieves an aggregate improvement of +9.62% over baseline, compared to +3.68% for GRPO, despite operating under a much smaller optimization budget. In fact, while GRPO requires around 24,000 rollouts, GEPA achieves competitive or superior performance with only a few thousand, in some cases even a few hundred.

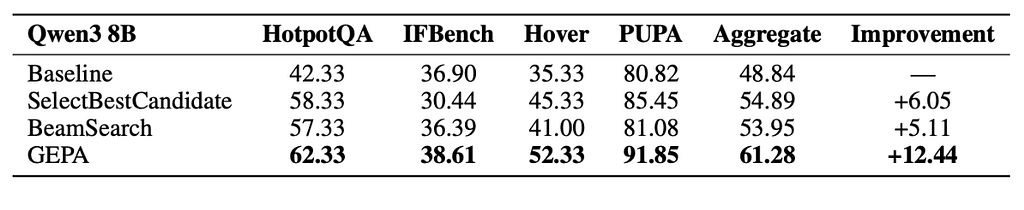
As shown in Figure 5, this gap is particularly pronounced on tasks such as HotpotQA and IFBench. For instance, GEPA achieves 62.33% on HotpotQA, significantly outperforming GRPO’s 43.33%, and reaches 38.61% on IFBench with only 678 rollouts, surpassing GRPO’s 35.88% achieved using the full 24,000-rollout budget. These results highlight a key theme of the paper: GEPA extracts far more learning signals per rollout.
Looking deeper, the improvement is not uniform across all tasks. On AIME, GRPO still performs better, suggesting that for certain highly structured mathematical tasks, weight-space optimization may still have an edge. However, across most reasoning and multi-step tasks, GEPA consistently dominates, indicating that reflection-based updates are especially effective in settings where reasoning traces matter.
Another interesting trend is how GEPA compares to other prompt optimization methods. Even against strong baselines like MIPROv2, which jointly optimize instructions and few-shot examples, GEPA performs better using instruction-only optimization. This suggests that modern LLMs are increasingly capable of extracting structure and reasoning directly from well-crafted instructions, reducing the need for heavy few-shot prompting.
As shown in Figure 6, perhaps the most surprising result is cross-model generalization. Prompts optimized using a relatively smaller model (Qwen3 8B) transfer effectively to GPT-4.1 Mini, achieving a +9% improvement without any re-optimization. This is a strong indication that GEPA is not just overfitting to a specific model but is discovering generalizable reasoning strategies encoded in language.

There are also subtle but important insights into how GEPA explores the search space.

As shown in Figure 7, using Pareto-based selection helps maintain multiple high-performing candidates rather than collapsing into a single solution too early. Experiments comparing this to greedy or beam-search strategies show that those approaches quickly get stuck in local optima, whereas GEPA continues to discover better solutions within the same budget. In this sense, Figure 8 shows that GEPA’s success is not just due to reflection but also to its balance of exploration and exploitation during prompt evolution.
Finally, an often overlooked but practically important aspect is efficiency. GEPA’s prompts tend to be significantly shorter than those produced by methods like MIPROv2, in some cases up to 9× shorter, while still achieving better performance. This directly translates to lower inference cost, reduced latency, and more efficient deployment in real-world systems.
Conclusion
Taken together, TextGrad, MIPRO, and GEPA represent three distinct ways of extracting learning signals from LLM behavior.
TextGrad demonstrates that optimization can be driven by explicit, language-based feedback, enabling precise credit assignment by directly identifying and correcting errors. MIPRO shows that prompt optimization can be framed as a structured search problem, where effective configurations emerge from exploring combinations of instructions and demonstrations. GEPA builds on both ideas, combining reflection-driven updates with population-based exploration, allowing it to both understand failures and systematically search for better solutions.
Across these methods, a clear shift emerges: from relying solely on scalar rewards to leveraging the full structure of model behavior: reasoning steps, intermediate decisions, and execution traces as a learning signal. Instead of inferring improvements indirectly, these approaches increasingly make them explicit, interpretable, and reusable.
This shift has important implications. First, it suggests that optimization in LLM systems need not be confined to the parameter space; meaningful improvements can be achieved directly in the prompt space through structured reasoning and iteration. Second, it highlights the importance of sample efficiency, as methods like GEPA demonstrate that extracting richer signals from each rollout can dramatically reduce the need for large-scale training. Finally, it opens the door to more modular and interpretable systems, where improvements are encoded as explicit rules or strategies rather than opaque weight updates.
Reinforcement learning is not replaced here, but reframed: in settings where trajectories are rich and interpretable, learning can be guided by structured feedback rather than solely by scalar signals. We are no longer just training models to produce better answers. We are teaching them how to improve the way they arrive at those answers by setting up open-ended feedback loops: ones we may initiate but may not fully control!
References :
[1] M. Yuksekgonul, F. Bianchi, J. Boen et al., TextGrad: Automatic “Differentiation” via Text
[2] K. Opsahl-Ong, M. J. Ryan, J. Purtell et al., Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
[3] L. A. Agrawal, S. Tan, D. Soylu et al., GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Disclaimer: This article reflects my interpretation of TextGrad, MIPRO, and GEPA, and their broader implications for LLM optimization. Any forward-looking statements are speculative and intended to encourage discussion rather than make definitive claims. You may follow me on Medium and LinkedIn for more such discussions.
What If LLMs Learn Better from Language Than from Rewards? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.