Written quickly as part of the Inkhaven Residency. Opinions are my own and do not represent METR’s official opinion.
In early 2025, the situation for upper-bounding[1] model capabilities using fixed benchmarks was already somewhat challenging. As part of the trend where benchmarks were being saturated at an ever increasing rate, benchmarks that were incredibly challenging for AI in early 2024 such as GPQA were being saturated scarcely a year later.
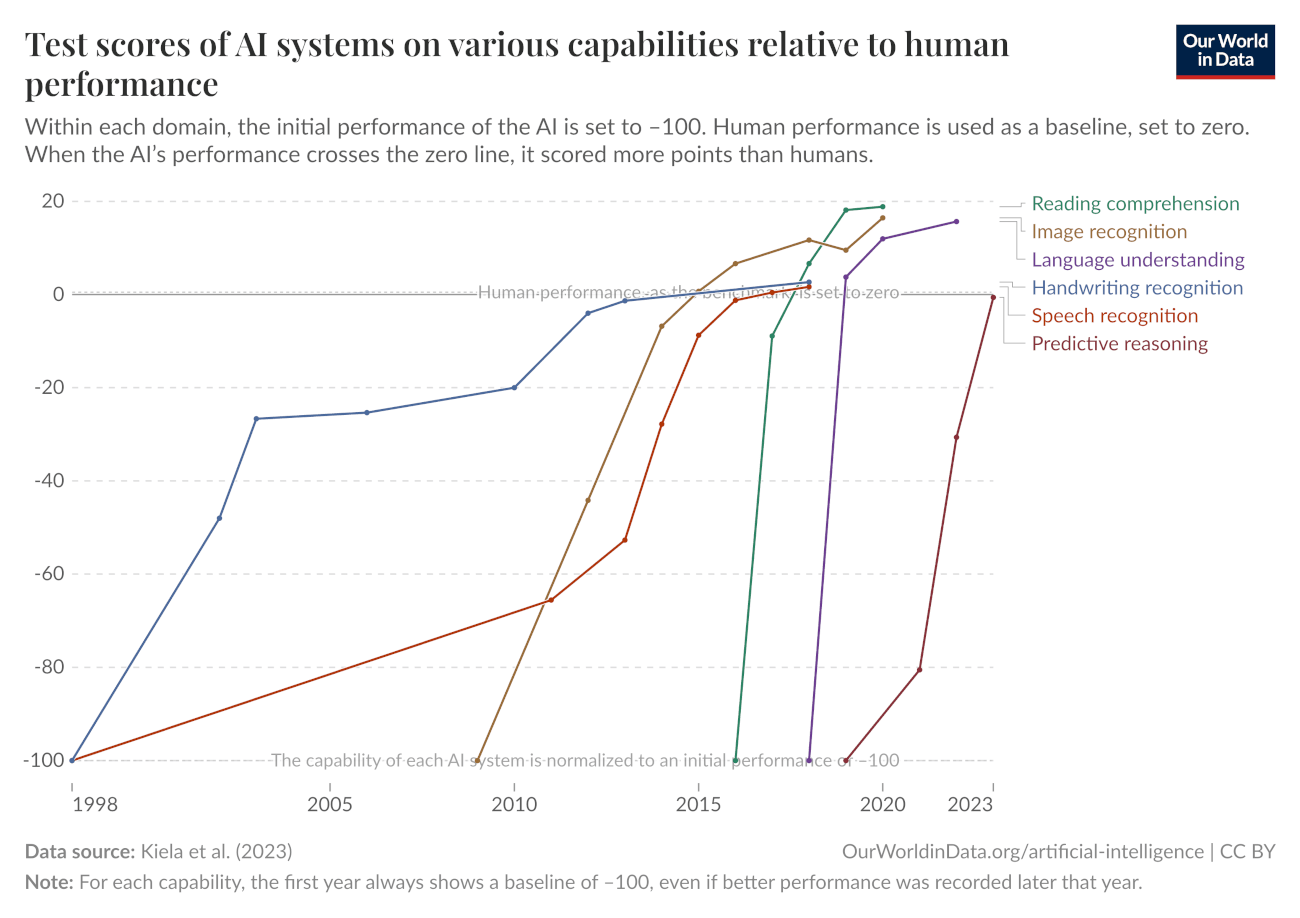
An oft-cited screenshot from Our World In Data (including in our time horizon blog post!), showing the ever increasing pace of saturation for AI benchmarks.
Thankfully, we saw a wave of alternative approaches to measure AI agent capabilities: for example, at METR, we released both the Time Horizon methodology as well as a preliminary uplift study that found no significant productivity uplift from AI. As part of their frontier AI safety policies, AI developers such as Anthropic and OpenAI built newer, more extensive evaluations to demonstrate that their AIs did not reach dangerous capability thresholds, such as BrowseComp and GDPval. Many research teams, both in academia and in industry, stepped up and created newer, ever more challenging agentic benchmarks, including τ2 -Bench, MCP-Atlas, terminal-bench, and Finance Agent.
This meant that for a time, thanks to the herculean effort of many, we could still point at particular set benchmark scores as a way of concretely upper bounding AI capabilities.
Now in early 2026, the situation has gotten worse.
METR’s Time Horizon suite is being saturated: while before, there were a wide suite of long tasks that no AI systems could do, now, frontier AI models such as Anthropic’s Claude Opus 4.6 or OpenAI’s GPT-5.3 could reliably do all but maybe a dozen or so tasks in the suite, making it hard to upper bound their time horizon. (For example, Claude Opus 4.6 has a 50% time horizon of 12 hours, but a 95% upper confidence bound of 60 hours.) At the same time, our previous uplift methodology became less reliable, leading us to consider alternative methodologies such as surveys or observational data.
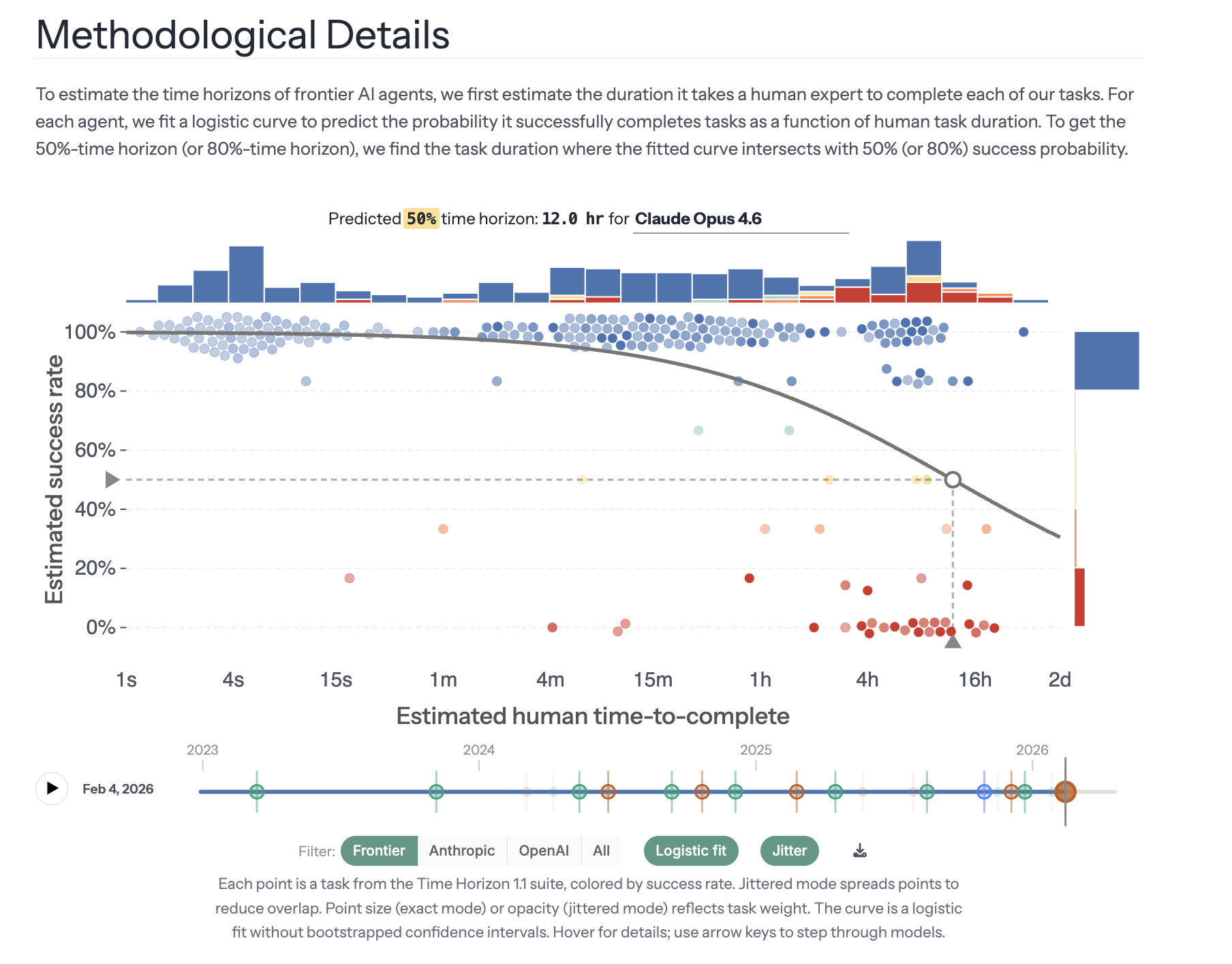
Anthropic's Claude Opus 4.6 succeeds at over 80% of the tasks on the METR time horizon task suite, leading to a very high upper 95% CI for its time horizon. From https://metr.org/time-horizons/
The situation for academic benchmarks is also similar: many of the benchmarks are nearing saturation necessitating updates, with new benchmarks becoming ever more expensive to grade and create.
Anthropic's Opus 4.6 release illustrates the challenge with existing upper-bounding approaches. While Anthropic could rule out ASL-4 capabilities from previous models, these evaluations were maxed out by Opus 4.6, with its lack of ASL-4 rating coming from an Anthropic survey of “16 Anthropic researchers, on whether Claude meets the ASL-4 ‘ability to fully automate the work of an entry-level, remote-only Researcher at Anthropic.’” (They said no.)
So, given that we’re in this situation, what can we do?
Part of the solution is to make ever more expensive, challenging benchmarks. We could always invest the effort to create newer, harder tasks, or find new clever ways to generate challenging benchmarks without as much human investment.
But the fundamental problem with new benchmarks is that, as AI capabilities improve, the benchmarks to measure their capabilities become ever more expensive to create. GPQA’s hundred-thousand-dollar price tag was shocking to many academics at the time, in 2024. Nowadays, even if we ignore the cost of developing the tasks, simply getting 2 human baselines for each of 50 new 32-hour METR time horizon tasks would take 3200+ hours of specialist human baselining time and easily cost upwards of a million dollars in human baseline costs alone. In addition to just the issue of monetary costs, benchmarks also take a lot of serial time to create, meaning that they risk being saturated before they’re even complete.
So even if new benchmarks can be developed, or existing benchmarks be extended, I think the situation will only continue to get worse. It seems likely to me that by mid 2027, if the current rate of AI progress continues, no benchmark score from a 2026 or earlier benchmark can rule out dangerous capabilities from frontier AI systems.
Another part of the solution has to come from alternative methodologies, beyond simple benchmark assessments.
One option is to shift the focus away from benchmarks and toward uplift studies. For example, in 2025, METR has conducted a series of uplift studies to measure the real-world impacts of AI on developer productivity, and AIxBio conducted an uplift study on biological weapons development. While these studies are informative, they are also very challenging to run logistically, and take sufficient time to complete – for example, the AIxBio uplift study took months to complete. Given the rapid pace of AI development and AI capabilities, it seems unlikely that these studies can substitute for benchmark scores to inform decision making regarding the latest frontier models. (See also Luca Righetti’s thoughts on this issue here.)
A second option is to do more expert forecasting or opinion elicitation. We could continue expanding forecasting studies run by organizations such as the Forecasting Research Institute. Or we could do expanded, more rigorous versions of Anthropic’s survey for Opus 4.6, asking researchers to assess the current capabilities of frontier models. This has its own problems: the problem with forecasting studies is that forecasters may not be well-informed about the subject at hand, especially in a fast moving field such as AI. At the same time, outsiders may (understandably) distrust an opinion survey conducted by an AI developer on their own employees.
A third option is to shift toward third-party risk assessment. Instead of relying on forecasts by people who may lack crucial information, or opinion surveys conducted internally, we might hope to set up a system of third-party auditors who get privileged access to company-internal information and then publish high-level summaries of the capabilities and risks of their frontier models. While there have been some efforts to prototype this, any efforts are still in their infancy, and any such system will ultimately still depend on public trust of the third-party auditors.
But ultimately, I think all of this is assuming a particular conclusion: that AI systems are not currently sufficiently disruptive or dangerous. Insofar as AI systems continue to get better, this assumption will eventually be false. At some point, any correct measurement of AI capabilities will not provide a reassuring status-quo upper bound, because their capabilities will disrupt the status quo.
Part of the answer has to be, we need to figure out what to do when we live in a world where the natural pace of AI development is faster than what we can easily measure. Perhaps the answer is to give up. Perhaps the answer is to take more drastic steps.
I don't know what course of action is correct, but I think we should stop treating the question of what to do as hypothetical. We are, I suspect, closer to such a world than most people realize.
- ^
Why focus on upper bounds in this post? A lot of this is because that's the RSP/Frontier Safety Policy-style framing that companies such as Anthropic, Google DeepMind, OpenAI, etc have adopted: they justify their decision to deploy their models in part by pointing to upper bounds on the risk posed by said models.
Discuss