The time it takes an AI or a Human+AI team (a "cyborg") to complete a task is a key aspect of what we care about when we talk about capabilities. The relationship between AI capabilities and cyborg capabilities is very useful for forecasting AI timelines. We simply don’t have good data right now on the capabilities of cyborgs, nor will we have good data on the capabilities of future AI models (at least with the evals that currently exist). In fact, our existing methods struggle to even determine if there is any AI uplift at all! Estimating how long it takes to do something is hard, and both AIs and humans are bad at it.
In this post, we’ll discuss four kinds of cyborg experiments and show how they can be used as cheap, meaningful uplift studies.
Human vs Human + Latest AI
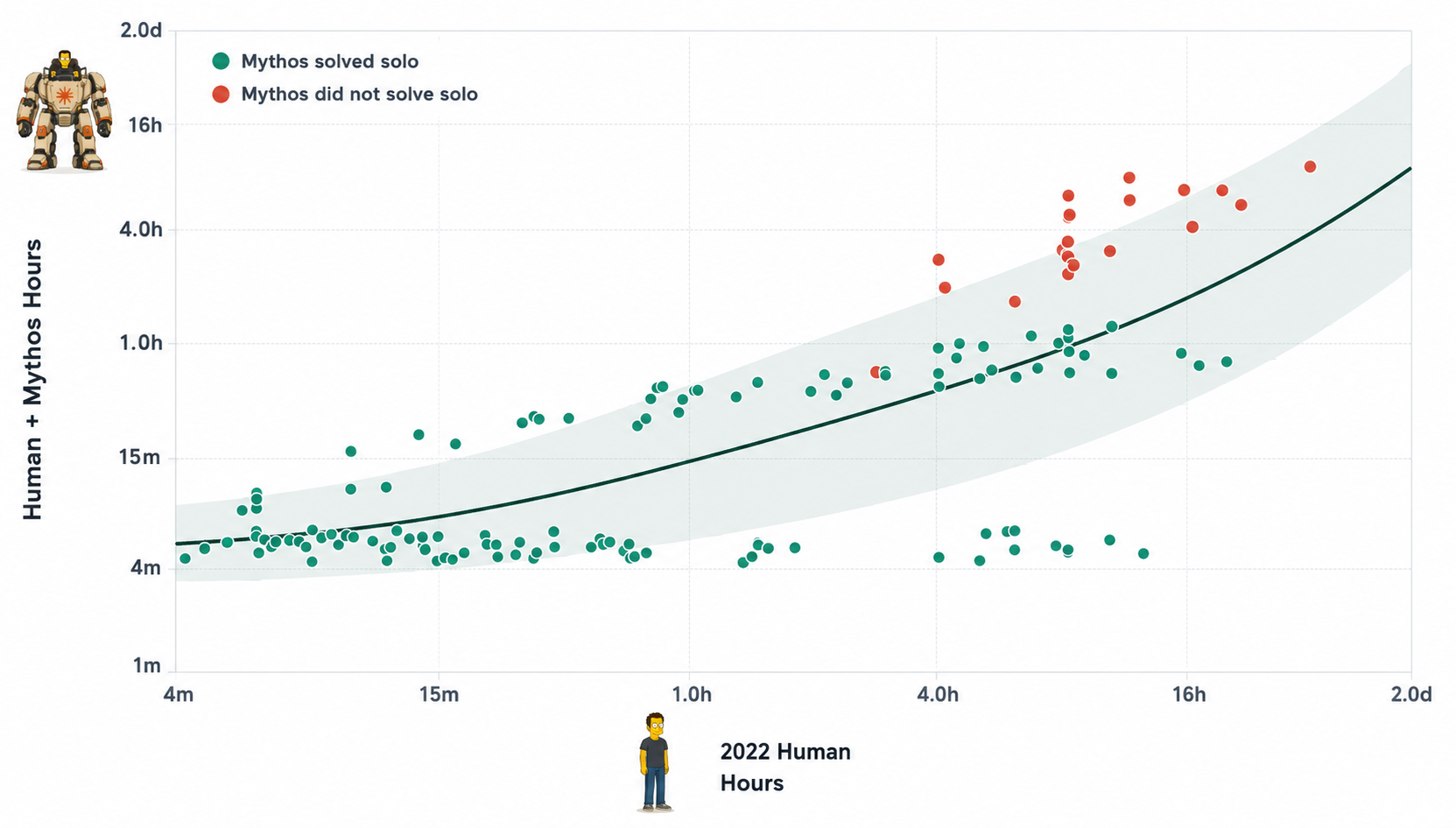
What is it and how to do it: Take tasks that are economically valuable and A. estimate how long they take to complete for a human without AI and B. measure how long they take to complete for a human with the latest AI. An example of a task here might be making a basic JS interpreter, estimated at taking 80 hours of 2022-unaugmented-human work. Task a human today to use the latest coding agent to solve the same task. Ideally the tasks would be cheaply verifiable, but they don’t have to be.
The cost: Suppose we had 50 tasks with an average cyborg (human+AI) completion time of an hour. We would need to pay 50h * engineer hourly rate to evaluate the new set. This costs something in the ballpark of $10k for every new model that comes out, and potentially an order of magnitude more if you want to test the uplift for an expert in a valuable domain (e.g. AI research or cybersecurity). We might need to try 2-3 software engineers for each to get a better estimate. It’s very important to swap engineers across different tests to avoid contamination (if an engineer saw a task already, they would be a lot better at it).
Why do it: This measures the actual productivity impact of AI. It also allows us to measure capabilities using a common unit – 2022-unassisted-engineer hours.
Problems: Humans are increasingly unwilling to not use AI[1], so it’s really hard to generate new baseline data for this. We need to find old data where: (1) humans are timed for the tasks (2) the tasks aren’t in the training data. METR’s time horizon tasks are a great candidate for this. Unfortunately, this data is getting both stale (it doesn’t reflect tasks that are important in today’s economy) and saturated (AI can solo do these tasks so they don’t tell us much about Human+AI combos just about AI). These types of studies could probably still teach us something about 2026 and 2027 class models, but unlikely to be useful beyond it.
Human and Model n vs Human and Model n + 1
What is it and how to do it:
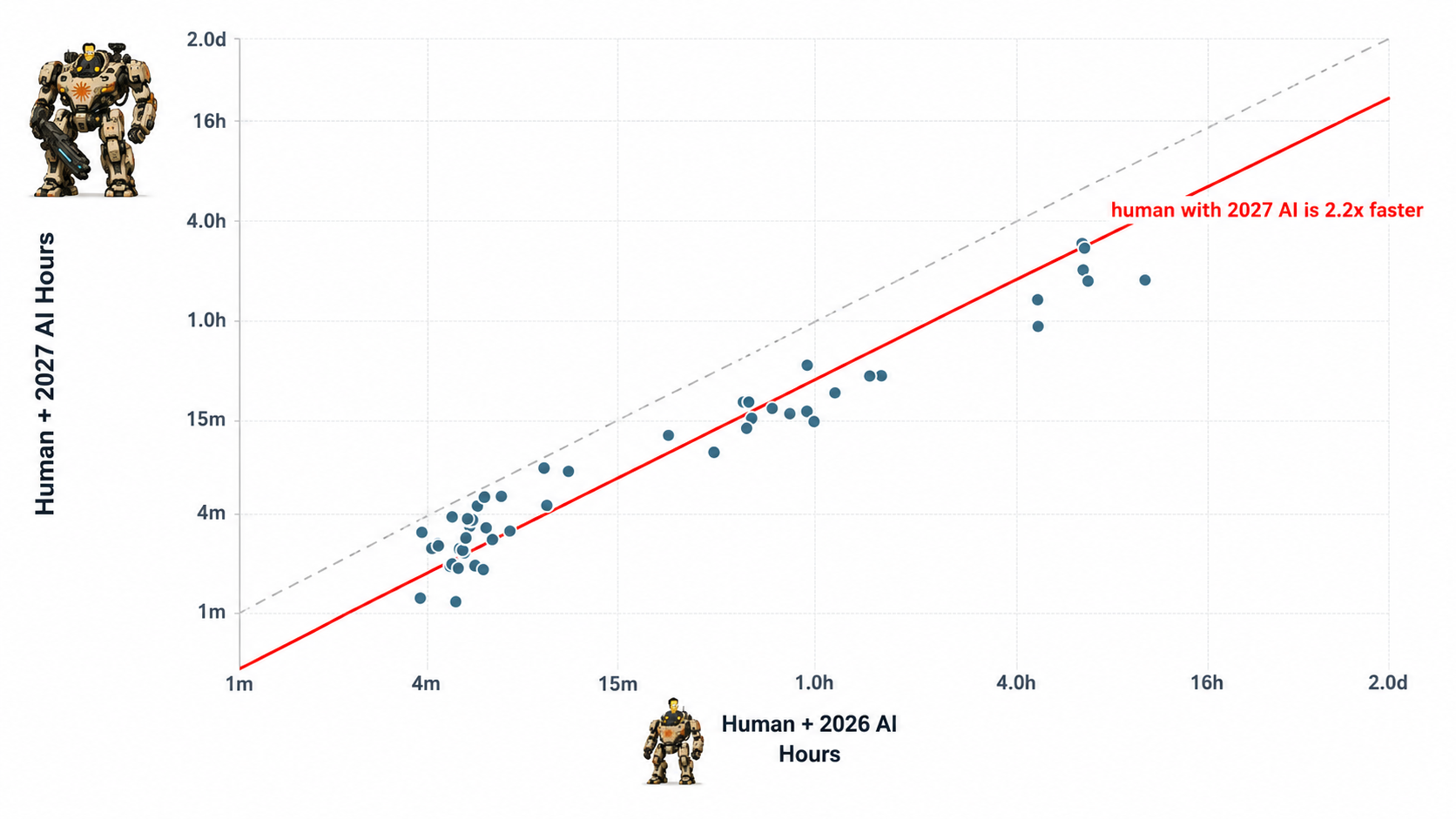
Estimate how long it takes a human to do a task with current AI and compare it with how long it takes to do the same task with the next generation of AI. We can easily generate new tasks here, and the performance difference across models will tell us about productivity growth.
How do we select good tasks?
They need to be economically important
They need to be somewhat hard.
They need to be easily and unambiguously gradable.
Problems: One problem is that the tasks that we care about change over time – tasks that humans actually do before a new model is released can be different from tasks they do after. For example, before Claude Sonnet 3.5, engineers spent a lot of time and resources making basic React components by hand. Sonnet 3.5 largely automated that class of tasks, and as a result, engineers are doing different tasks now.
Another problem is that the kinds of tasks we select here will tend to be the exact tasks that models do best at. Labs are strongly incentivized to train the next generation of models to be good at tasks that engineers are good at today, since these tasks are typically legible, easily verifiable, and “have money” in them. This sort of task selection would show a higher speedup than than the actual effective speedup that engineers get. However, it’s possible this doesn’t matter much – we might be able to measure this “optimization incentive bias” and correct for it.
AI and human vs AI by itself
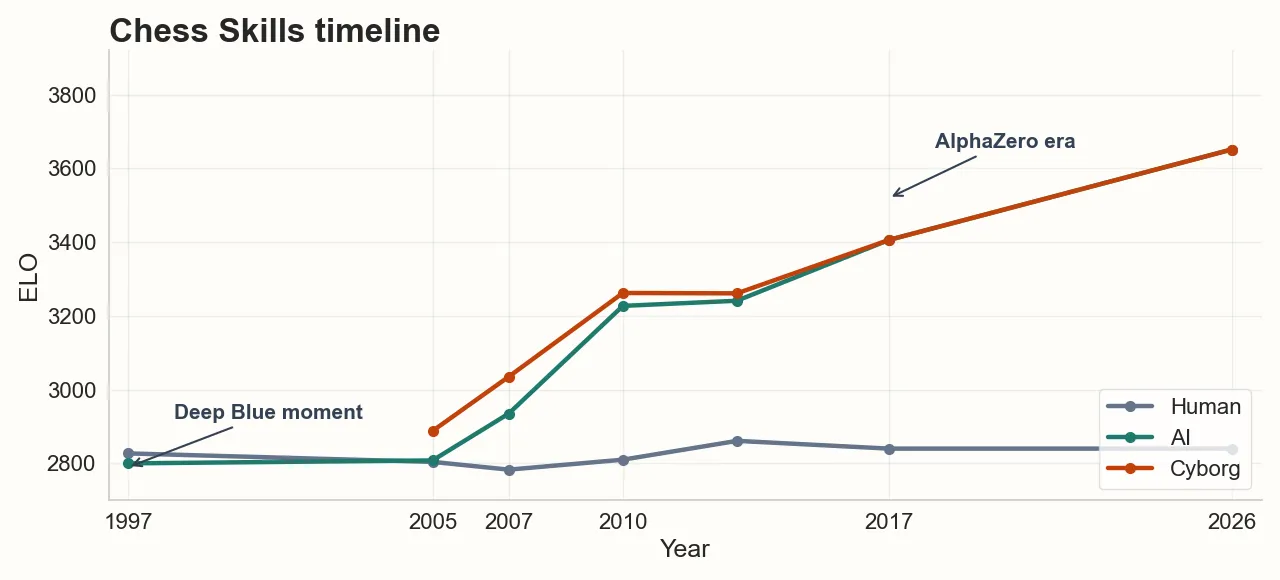
What is it and how to do it: We can compare the performance of a Human+AI (cyborg) team to an AI running by itself. In a previous post, we called the difference in their performance the “cyborg gap”. This measurement can tell us, among other things, when and in what fields humans stop being productive.
Problems: There’s likely a lot of capabilities across humans and we won’t be able to tell much about it from naive cyborg gap experiments.
Human Capital Experiments? AI and a 10yo child vs AI and a senior engineer
What is it and how to do it:
Compare a high skilled cyborg and a low skilled cyborg on the same set of tasks.
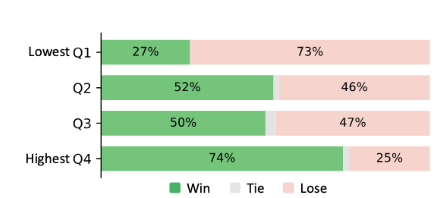
Why do it: It tells us about human capital and how it changes over time, it could tell you about the economy and if short term inequality is likely to decrease or increase. If kids can produce just as much labor as an experienced engineer, engineer salary is likely to drop. There are good arguments for why we might see reduction in the importance of human capital in the longer term. That being said, right now the opposite seems true and AI seems to be an enhancer of human capital inequality.
Problems: You need to make sure that the kid actually does it and an adult isn’t helping them, employing kids might be legally tricky. An alternative for asking kids for labor is to offer the task for a really low amount of money to make sure it’s only attractive for lower skilled workers.
Conclusion:
Each method we’ve suggested has its own problems and blindspots. We should use all of them.
The four experiments we mentioned have a lot in common – for example, they all require one to periodically curate tasks and have engineers try solving them with different models. There are good economies of scale for running all of them. In practice, we will need to curate a set of ~50 tasks every few months and test different cyborgs on them. The cost of testing a new model with this approach is probably ~$10k [footnote: we are working on better estimates for the cost] which is, relative to everything else in this field, small potatoes.
Additional thoughts
It would be informative to see “task level” speedup breakdown to get a better understanding of where the “bottlenecks” are. AI is better at some things than others. Different task families experience different productivity growth, and it would be nice to know what this looks like.
More things we can try:
Value Experiments: instead of measuring time it took to do stuff, we can measure some sort of proxy for value, e.g “how much revenue did human + AI generate vs just AI”)
Price Experiments: “how much a user is willing to pay to use the latest AI as opposite to a previous generation”, we can run experiments where we let the candidate choose to use and do the task with it and get some amount of money or we can use and get more money. This can help us measure how much people subjectively value different AIs
Time Difference Experiments: How much “extra value” does an additional hour of human labor provide? This can give us an estimate of the marginal value of human labor (a strong proxy for wage!) and how it changes as new models are released.