
This post was originally posted my Substack. I can be reached on X and LinkedIn.
For the past few months, I’ve been trying to “vibe Excel” (using ChatGPT and Anthropic’s Excel add-ons for investment workflows). My takeaway is that while AI tooling for finance is still relatively immature, its potential to disrupt financial services is clear. This raises an important question: if AI for software engineering went from novelty to ubiquity in ~2.5 years, how quickly will AI diffuse across other knowledge-work domains?
My view is that the bottleneck to AI adoption has shifted. In coding, the main constraint was model capability. For much of white-collar work, the bigger constraint will be adoption inertia, meaning the willingness of organizations to trust, integrate, and reorganize around AI. Furthermore, this inertia creates a brief window of opportunity for organizations that can apply AI in non-obvious ways.
In this post, I cover the following:
- How AI applied to software engineering went mainstream in ~2.5 years
- Why finance is a useful case study for the next wave of AI diffusion across white-collar work
- A framework for understanding AI adoption across industries: model capability, harness, workflow integration, and adoption inertia
- Why adoption inertia, rather than model intelligence, will become the main bottleneck for many knowledge work domains going forward
- What staggered AI adoption means for savvy AI users
Let’s dive in.
A brief look at the history of coding AI
To level set the conversation, we can look at the history of AI coding. After the launch of ChatGPT in late 2022, engineers began adopting it across software engineering workflows. This involved copying and pasting code into ChatGPT (which seems extremely antiquated now!) for code generation, debugging, and writing tests.
The launch of Anthropic’s Sonnet 3.5 in mid-2024 marked a key inflection point when engineers were able to entrust AI with long horizon tasks, and helped drive adoption for the current era of AI-native software development platforms, which I wrote about in a prior piece. By mid-2025, AI-assisted coding was widely adopted. Now, companies are even tokenmaxxing, with employees competing to see who can spend the most tokens.
Now, it’s important to note that coding was also an unusually fertile environment for AI: it’s easier to train LLMs on tasks that are verifiable (code can be tested for correctness), and developers already worked inside tooling like IDEs, git, and CI/CD systems, which allowed models to fully utilize their capability overhang. Finance is a useful case study for the diffusion of AI across other industries because it’s starting to look like coding did before its breakout moment.
Finance is at an inflection point
Recently, I’ve been testing ChatGPT and Anthropic’s Excel add-ons extensively for fairly “typical” investor use cases (e.g. revenue builds, scenario analysis, etc.). The experience feels similar to AI coding a few years ago: clearly useful, slightly hard to use, and dependent on the user knowing what “correct” looks like.
As a contrived example, a model for an SPV (special purpose vehicle) into a pre-IPO AI company (e.g. OpenAI / Anthropic) might involve understanding the following:
- Revenue projections given different growth assumptions / drivers
- The impact of different fee / carry structures on net returns
- The impact of dilution (AI startups need to offer generous equity packages to attract talent)
The prompt I would use for one part of the model might be something like the following:

In this example, most of the model had already been “hand-built”. I was merely using AI to build one section of a financial model, which I liken it to writing one function in a program. Here, a short prompt like the one above doesn’t result in a correct model. I needed to go through several rounds of iteration & manual tweaks to get something useful (see below).
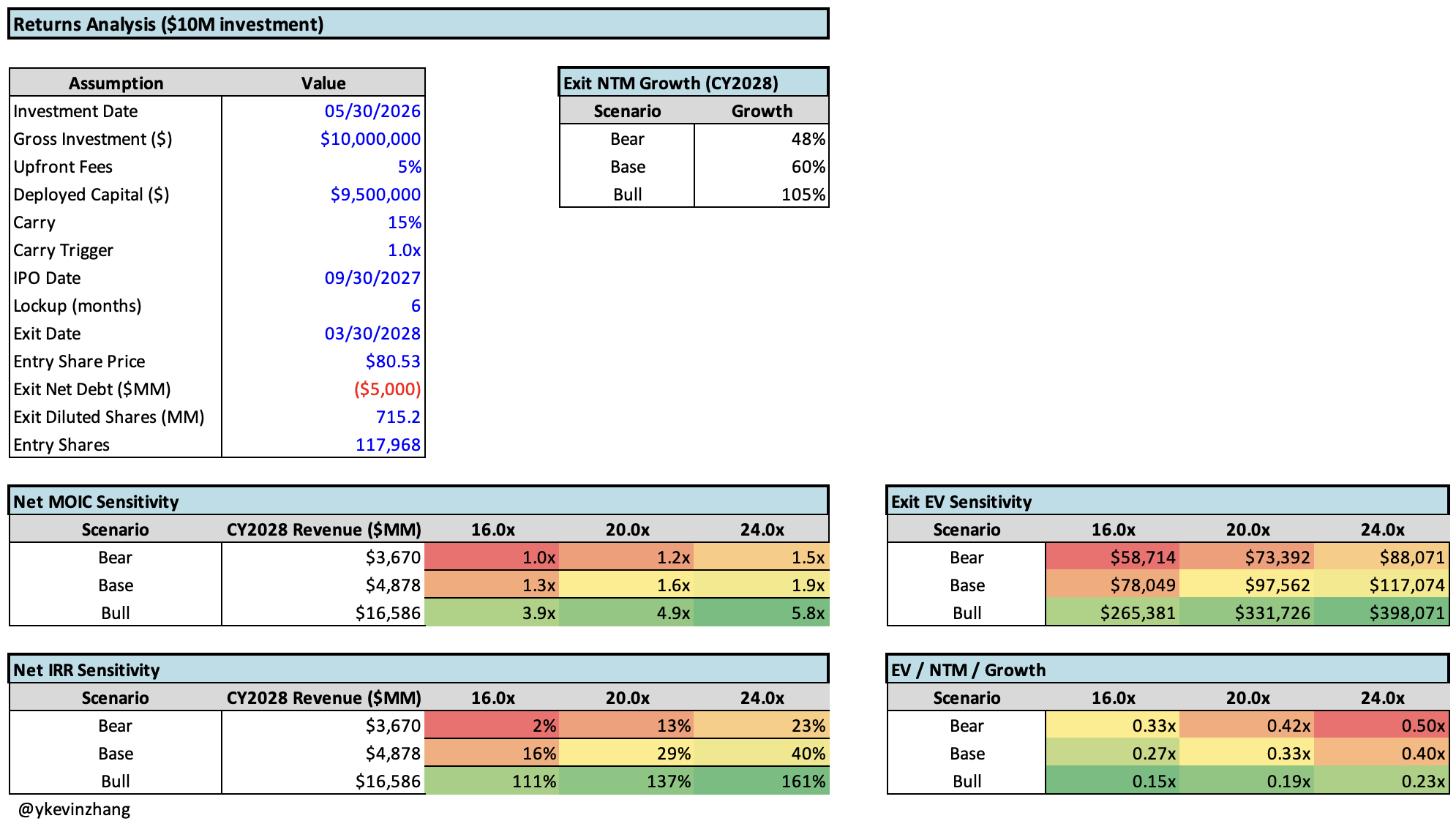
There are some rough edges that I noticed:
- Intent-output mismatch: a short prompt isn’t sufficient for generating “usable” financial models as a lot of additional context is needed. Software engineers who use AI already know this, but I suspect the practice of writing detailed prompts isn’t yet widely adopted. This is where the application layer needs to step in to bridge the gap for non-LLM savvy users
- Reviewability: software engineers have tests, git diffs, logs, and the ability to roll back changes. In Excel, it is still hard to version-control AI edits and see how those edits flow through a model. In finance, an incorrect cell could lead to a completely different conclusion, so evals are critical
- Integrations: real finance workflows need to integrate with an organization’s internal data and conform to house style and review processes. This is why AI-for-finance startups often require custom onboarding and integration with a fund’s internal systems.
Despite these rough edges, the potential of AI for finance is clear: given enough context, models should have enough intelligence to automate many of the “jobs to be done”. From a market maturity perspective, finance feels like the 2023/2024 era of AI coding. The major horizontal platforms’ Excel-native offerings are comparatively new. Microsoft launched Agent Mode for Excel in January 2026. Meanwhile, Anthropic and OpenAI launched their Excel add-ons in October 2025 and March 2026, respectively.
But as AI for software engineering has already shown, frontier AI labs and incumbents will try to own any sizable market. This is why the SpaceX / Cursor deal is noteworthy: it’s incredibly difficult for a neutral third party to compete on economics when model providers can subsidize usage, bundle products, and capture margins across the stack. If finance follows the same trajectory as software engineering (Claude Code and Codex), I expect significant product quality improvements and rapid vendor consolidation. This is already starting to happen for finance. Anthropic just unveiled agentic templates for finance, and Microsoft recently acquired Fintool.
The main takeaway here is that, in contrast to the early days of software engineering, model intelligence is no longer the primary limiter for a broad swath of finance tasks. Given AI models’ inherent intelligence, it doesn’t take long to build applications on top of leading models. The more interesting question is whether this applies to the rest of white-collar work.
The bottleneck for AI adoption is adoption inertia
My framework for understanding the speed of enterprise AI adoption is to map out where the bottleneck sits. This framework is similar to how public equity investors think about bottlenecks in data center buildouts (GPUs, CPUs, power, transformers, networking, etc.). AI adoption works the same way. In the early era of AI coding, the primary bottleneck was model capability. As models got better, software engineers went from asking ChatGPT to generate code at the function level to present day, where frontier models enable long-running agentic workflows.
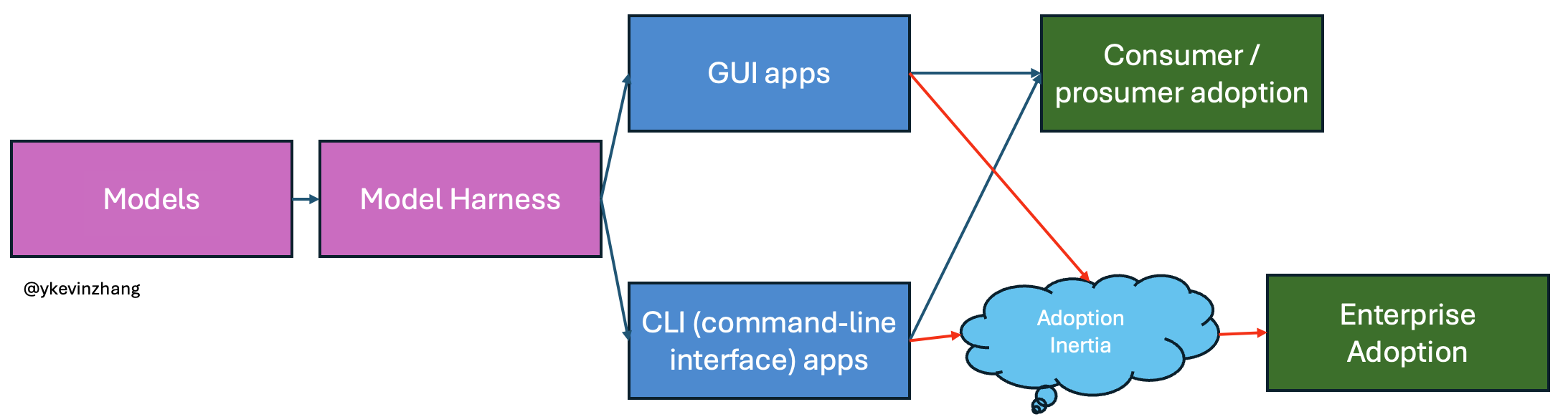
The difference now is that progress is happening concurrently at multiple layers at an even faster rate than before. Labs like OpenAI are hiring ex-bankers to generate data and train models for specific verticals like finance, meaning future models will come with even more domain-specific intelligence out of the box. At the same time, there are innovations happening at the harness (an LLM's surrounding infrastructure) and application layer (e.g. something as simple as having a chat history for OpenAI / Anthropic’s Excel add-on, which didn’t exist in their initial incarnations). If models, harnesses, and application surfaces are all improving, then there theoretically should be more “AI coding moments” across other categories of white-collar work.
But, there is one major blocker that’s harder to brute-force: adoption inertia. So, while AI in aggregate has become the fastest adopted technology in history, not all industries will adopt it at the same rate as software development did. There are multiple reasons for this “inertia”:
- Longer enterprise purchasing cycles, as additional IT spend may require more stakeholder approval
- Relatedly, there is the broad bucket of regulatory, security, data privacy, and compliance concerns that legal may be hesitant to sign off on
- Risk management: incumbents may be wary of non-deterministic systems touching customer-facing or mission-critical workflows (Air Canada was sued for this reason). The fact that Berkshire Hathaway and Chubb are pushing to drop coverage for AI-related liabilities reinforces this point
- Inherent tug-and-pull within organizations with respect to AI adoption: while there may be top-down pressure to adopt AI, there may be internal resistance (managers may want to protect their kingdoms / headcount)
- At the individual level, habit change is difficult (e.g. within finance, there’s inherent muscle memory in how things are done)
This means that white-collar workers in specific industries will be able to see a brief reprieve from the disruption from AI. Given this “staggered” adoption, there should be a window for smaller, flatter organizations to leverage AI in non-obvious ways before the rest of the market does.
The adoption-arbitrage window
Even within the domain of finance, the “best practices” for using AI have yet to be established. Take public equity investing as an example, there are more uses for AI than simply using LLMs to summarize expert call transcripts. Examples include implementing a swarm of AI-generated quantitative strategies & testing them in parallel, building sophisticated signal ingestion engines, or using multiple agents to verify financial models. Investors who thrive in this new world are finance-technologist hybrids. The net result is that smaller teams, augmented with AI, can achieve the same capabilities as a larger fund that lags in AI adoption. The longer term effect of this is that the AUM to investor ratio (assets under management) will increase even more.
More broadly, there are many opportunities for smaller, flatter teams that have a higher tolerance for AI’s imperfections. Business models that can incorporate “mostly right” systems will see much higher operating leverage. These companies do not need to be software companies. In fact, I think pure-play software companies will increasingly have issues with distribution as the market gets flooded with similar offerings. The more interesting opportunities are companies that use AI as internal operating leverage in non-obvious industries. A recent example is two brothers who built a “unicorn” using AI to sell GLP-1 drugs (though their story comes with an asterisk).
These companies won’t fit the traditional venture mold, and they won’t be “cookie-cutter” AI roll-ups. Their exact structures, operating models, and how they use AI are still unknown. But I am quite certain that this adoption arbitrage “alpha” will quickly decay. Once large organizations fully adopt AI, the edge from being early will disappear. But in the current dislocation, small teams have a brief opportunity to build quickly, capture distribution, extract revenues, and build non-software moats. I’m excited to see what these unconventional companies end up looking like.
Big thanks to Will Lee, John Wu, Homan Yuen, Yash Tulsani, Maged Ahmed, Wai Wu, Sam Huang, Ying Chang, and Andrew Tan for feedback on this piece.
Discuss