Epistemic Status: I recently co-authored a paper on Membership Inference Attacks accepted at EACL 2026. More theoretical contributions — specifically the gradient attribution and the findings regarding the Hessian/positive-definite theories — are unpublished findings that I believe have some interest for AI Safety, Developmental Interpretability, and evaluation design. I am sharing them here for community feedback.
Links: Paper | GitHub Repo
TL;DR Many modern membership inference attacks (MIAs) appeared as a tool to infer whether a particular sample was part of training dataset, and thus, promote more transparent evaluations (by detecting contamination signals from the target model). However, MIA detection pipelines themselves appeared to lack rigorous evaluation. We found (by extending the work by Das et al., 2024) that most MIA benchmarks simply detect distribution shifts, not memorization.
For example, a model-free baseline hits AUC ≈98.6% on VL-MIA-Flickr-2k, meaning “members” and “non-members” are trivially separable. Apart from that, we released FiMMIA, an extension of perturbation-based MIA to multimodal domains. Everything is open-sourced, so feel free to use. (Our pipeline, trained detectors).
Most interestingly, our results show that most theory behind the success of perturbation-based attacks is in fact wrong or at least misleading. Some influential works in the area (Detect-GPT, Min-K%++) have argued that such detection methods use Hutchinson-like (Hutchinson, 1990) Hessian-trace estimation. We evaluated this claim empirically and found that it interestingly fails — the input-space Hessian even for training samples is not positive-semi-definite, so that they don't correspond to modes of the probability distribution.
Executive Summary:
- Membership inference benchmarks are broken and we have no good multimodal options. A purely data-driven classifier (no model access) achieves near-100% AUC on most MIA benchmarks, so i.i.d. assumption fails and splits leak domain signals. I think we need to treat baseline model-free attacks as a lower bound for any MIA approach.
- FiMMIA approach. Yet another MIA attack — but quite successful, notably. Essentially, it generates semantic “neighbors” for each sample, computes loss and embedding differences, and trains a neural detector to infer membership signals. Our pipelines are designed to be modular and allow for easy modification and integration.
- Gradient-based Interpretability. We did some gradient-based attribution for the trained detectors and found that both losses and embeddings provide strong signals for the detector (similar to arguments by He et al., 2024). Another notable detail is that adding multimodal augmentations that are more "adversarial" (informally, e.g. inverting the image colors, which is rarely used as training-time augmentation) yields stronger membership signals. Testing whether model-specific adversarial augmentations result in the best performance could be an interesting extension.
- Hessian intuitions are misleading. The "semantic" nature of perturbation appears to be crucial. Computing Hessian traces via Hutchinson's estimator (which samples random perturbations from either
- Open questions. What is the true geometric signature of membership? How many reported MIA results are artifact-driven?
Below we discuss these points in detail.
1. Why Contamination Threatens Safety
When we argue about some risks brought my advanced models' capabilities, we need some reliable evaluations to ground on. Dataset contamination, unfortunately, is a common phenomena, which inflates trust in accurate capability estimation. Sandbagging phenomena (An Introduction to AI Sandbagging) are also of interest here. Generally, deep learning models shine in detecting subtle hints and shifts in data distributions. If a model recognizes some parts of evaluations as “out-of-distribution", it might make it even easier to underperform on it, masking flaws.
Given this there was a hope for membership inference attacks (MIAs) to be used as a diagnostic approach. Essentially, they try find a statistic which allows to distinguish whether a particular sample was in the training set of some ML model. However, as Carlini et al. (2022) emphasized, this test fundamentally relies on an i.i.d. assumption. In plain terms, members vs. non-members must be drawn from the same distribution. If that fails, an MIA detector can give high success rate just by learning the distribution shift. In the next section we’ll see that this assumption is often violated in practice, invalidating many current MIA attack results.
2. Broken Benchmarks: Baseline Attacks Expose Artifacts
To highlight the problem, we built a target-model-free baseline: a simple classifier that uses only dataset features (e.g. image/audio spectral features, frequency statistics, text word frequencies etc.) to predict membership. It has no access to the model or its outputs. If the benchmark is clean, this baseline should get ~50% AUC. If it does significantly better, the dataset itself leaks information to the MIA classifier.
Intrestingly, common multimodal MIA benchmarks (e.g. VL-MIA datasets) display near-perfect separability. Similar effects appear in text-based MIAs (baseline attack achieves a 99.9% ROC-AUC on a recently created WikiMIA-24 split). In simple terms, there exists a shortcut rule (like “if an image is a satellite photo, it’s from training dataset; if an image is a picture of a cat, it's from the test split”) that a model-free method can exploit. This means the two splits are statistically distinct.
MI Dataset | Metric | Best model-based | Model-free | Blind Attack Type |
|---|---|---|---|---|
WikiMIA | ROC-AUC | 83.9 | 99 |
|
WikiMIA-24 | ROC-AUC | 99.8 | 99.9 |
|
WikiMIA-Hard | ROC-AUC | 64.0 | 57.7 |
|
BookMIA | ROC-AUC | 88 | 91.4 |
|
Temporal Wiki | ROC-AUC | 79.6 | 79.9 |
|
Temporal Arxiv | ROC-AUC | 74.5 | 75.3 |
|
Arxiv (all vs 1 month) | ROC-AUC | 67.8 | 72.3 |
|
VL-MIA Text (Length 32) | ROC-AUC | 96.2 | 84.9 |
|
VL-MIA Text (Length 64) | ROC-AUC | 99.3 | 95.5 |
|
VL-MIA Images (Flickr) | ROC-AUC | 71.3 | 99.0 |
|
VL-MIA Images (Dalle) | ROC-AUC | 70.7 | 99.9 |
|
LAION-MI Images | ROC-AUC | N/A | 52.2 |
|
LAION-MI Captions | TPR@1%FPR | 2.5 | 8.9 |
|
Gutenberg | ROC-AUC | 85.6 | 96.1 |
|
Table 1: Results of a model-free membership classifier on published MIA datasets. High values indicate clear distribution shift between members and non-members. Only the results on LAION-MI are trustful.
It's possible to argue that if a model-free baseline does well, the model could still have memorized the data. This misses the point, a high MIA AUC (or FPR@1%TPR, this is not that relevant here) no longer implies the model has memorized content, it sets a baseline membership score for any MIA on a target model. If we can predict membership without querying the model at all, we can not trust what MIAs tells us about the model’s generalization vs memorization distinction.
3. FiMMIA: Semantic Perturbation-Based MIA
Essentially, it builds on the idea of semantic perturbations: making meaningful edits and seeing how the model reacts. I leave a short description of the inference pipeline here just for reference as it sets a necessary ground for later points and discussions. If you are interested, full description is available in the paper.
- Neighbor Generation. For each sample
- Feature Extraction. Pass the original and each "neighbor" through some embedding model
- Loss extraction. Obtain loss values on the original
- Compute Differences: For each neighbor, define two feature differences:
- Detector Training: We then train a binary classifier on a dataset of such differences.
Scoring: At test time, for a new sample, we compute its feature and loss differences and get membership probabilities from the trained classifier. FiMMIA’s final membership score is the average:
The attack is generally successful across domains, and we even found it mildly transferable across languages and model families. The very nature of "semantic perturbations" is quite obscure to me still.
4. Perturbations, Hessians, and Why DetectGPT’s Intuition Fails
Many works (e.g. DetectGPT, MinK%++) explain perturbation-based detection or take inspiration from the second-order analysis, arguing that training samples lie at local loss minima with respect to the input space, so their Hessian is positive-definite. Then, random perturbations in the input space approximate that Hessian trace. A higher trace (i.e. “sharp” local curvature) indicates a member.
And, if the distribution of
We tested this directly. First, we estimated the Hessian trace using Hutchinson’s method on each sample. If the theory held, this should end up in more accurate approximation and a higher AUC. Instead, the Hutchinson-based detector was near random (AUC≈50%) for e.g. GPT-J-6B and lagged behind even the weakest perturbation-based attacks. Moreover, it's not about the gradient contribution either — we've tested this hypothesis as well and found the results questionable.
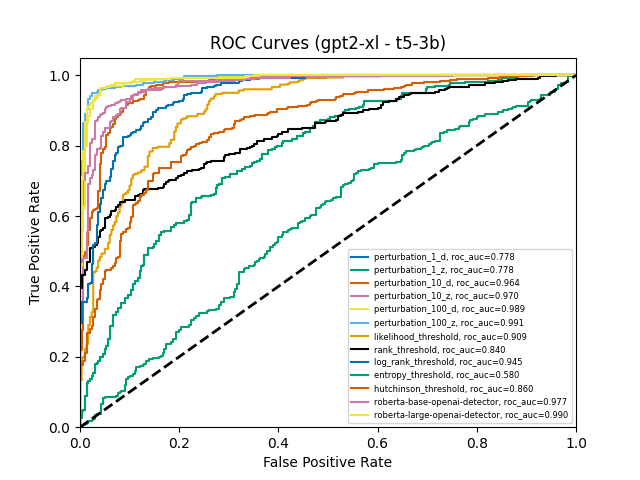
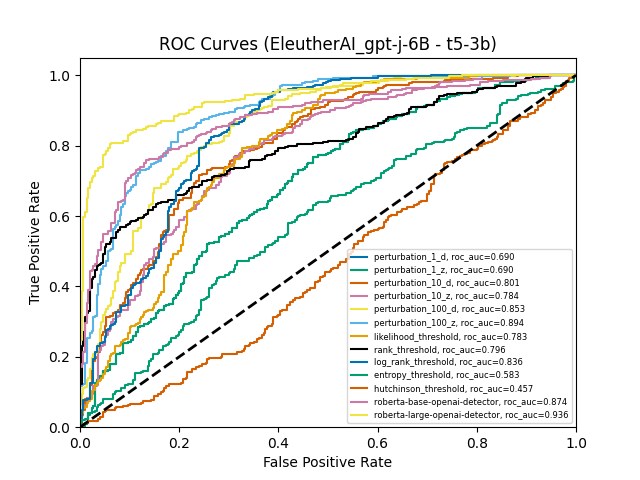
Figure 1. ROC Curves for methods from Detect-GPT with added hutchinson estimator
Second, we hypothesized that trace might be dominated by some spectral garbage, while first few singular values could display distinctive patterns. This wasn't the case. Hessian eigenvalues for several multimodal models we've obtained using Block Power method, contrary to the local-minima assumption, were indistinguishable for "members" and "non-members" and spanned both positive and negative values. Training points did not ended up at all-negative peaks. (we flipped the loss sign here to evaluate log-probability curvature so we would expect the hessian to be negative semi-definite for local maxima).
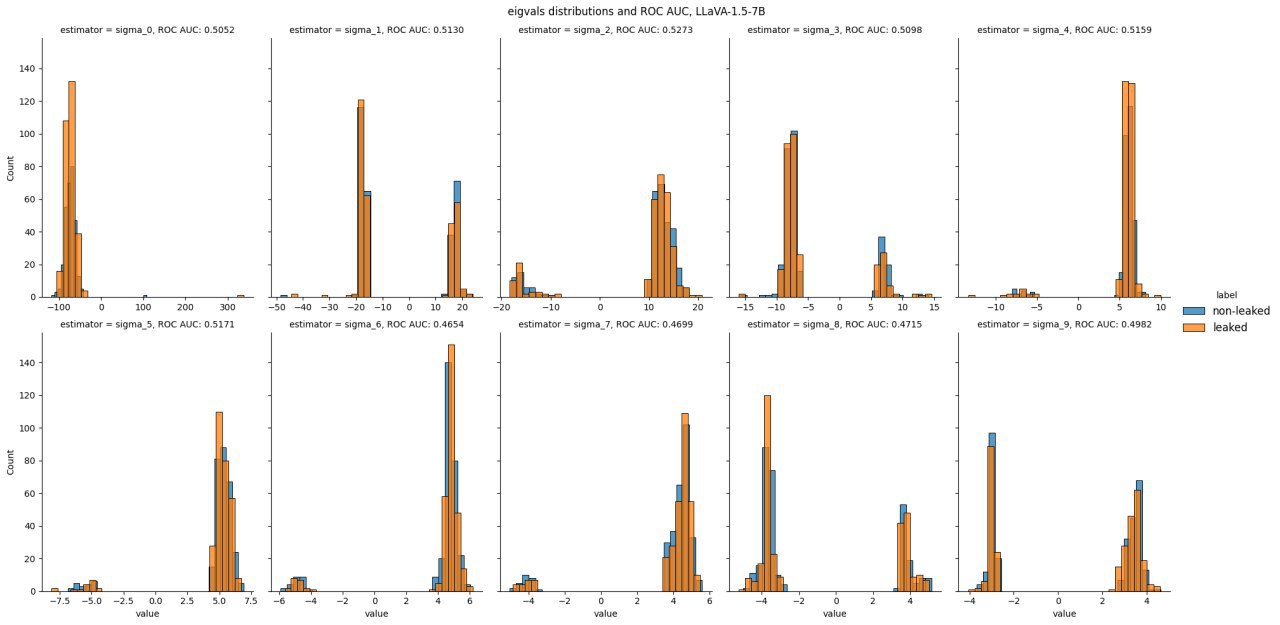
Figure 2. Hessian eigenvalues for LLaVA-1.5-7B for leaked and non-leaked samples
Notably, unlike local perturbations, that can be captured via common NLA tools, semantic perturbations (masking words, etc.) are not infinitesimal moves in a fixed-dimensional vector space [1]. In effect, FiMMIA and other black-box perturbation-based methods are doing a finite jump on a discrete manifold, so a local Taylor expansion is not the right language.
Thus, the Hessian-basin intuition is a fallacy in practice and I think that even as an intuition its highly misleading. Perturbation attacks must work for a subtler reason, but I'm unaware of any formal analysis, that could explain the results.
I highly appreciate any comments and discussions regarding this section.
5. Practical Recommendations
Check for distribution shifts prior to MIA detectors evaluation. Whenever possible, ensure true i.i.d. splits or use baseline attacks as a lower bound for success.
For text tasks, split e.g. by random hash, not by date, as we inevitably have some time-dependent distribution shifts in real-world data, remove obvious side channels common in benchmarks (timestamps, unique identifiers, etc.). For images, scramble sources (and please, don't use generative models here unless initial training dataset was generated by the very same model, but it's still kinda questionable methodologically, as for my taste).
We need a review for published MIAs. Many results might need reinterpretation. If a paper reports high MIA accuracy, there's a chance they built a good data classifier, not model sensitive detector. However, I'm not aware of any good approaches that could have addressed the issue, besides testing on fully open-source models (similarly to what Das et al. have proposed).
6. Open Questions and Future Work
I have several open questions in mind:
- If not Hessians, what formal geometry captures “membership-associated loss peaks”? Might there be a metric on the representation space that quantifies data density and shows that training samples constitute local minima without dealing with 3rd+ order expansions? Which implications does it have for adversarial attacks and prompt optimization (as opposing sides of the same coin)?
- Does such results hold for diffusion language models, where score matching directly optimizes the local hessian geometry? For those in the DevInterp space: how should we formalize the way "memorization" warps the embedding manifold, given that the standard Hessian trace explanation fails? I've mostly seen research about the parameter-space singularity, but in common LLMs embedding space is also just a subset of the whole parameter space.
- Can we design MIAs that account for true memorization only? For example, by first modeling the domain shift explicitly and then subtracting it out. Let me know if you are aware of any work in this direction.
Some more specific quesitons about the integration of these baselines into common research tools:
- Are there specific safety, sandbagging, or capability eval datasets currently in use that you suspect might suffer from these domain shifts?
- What would be the best way to package these tools for integration into current safety evaluation frameworks like Inspect AI?
I'm looking forward to any critique and comments on these topics. In case you'd prefer a direct outreach, feel free to use email or LinkedIn.
In fact, they are not necessarily the same mapping, as we don't control for the number of tokens between perturbations. Thus, if initial samples had (N) tokens, and its perturbed version has (K) tokens, we can view the model as a two distinct matrix valued functions, one of a form:
Discuss