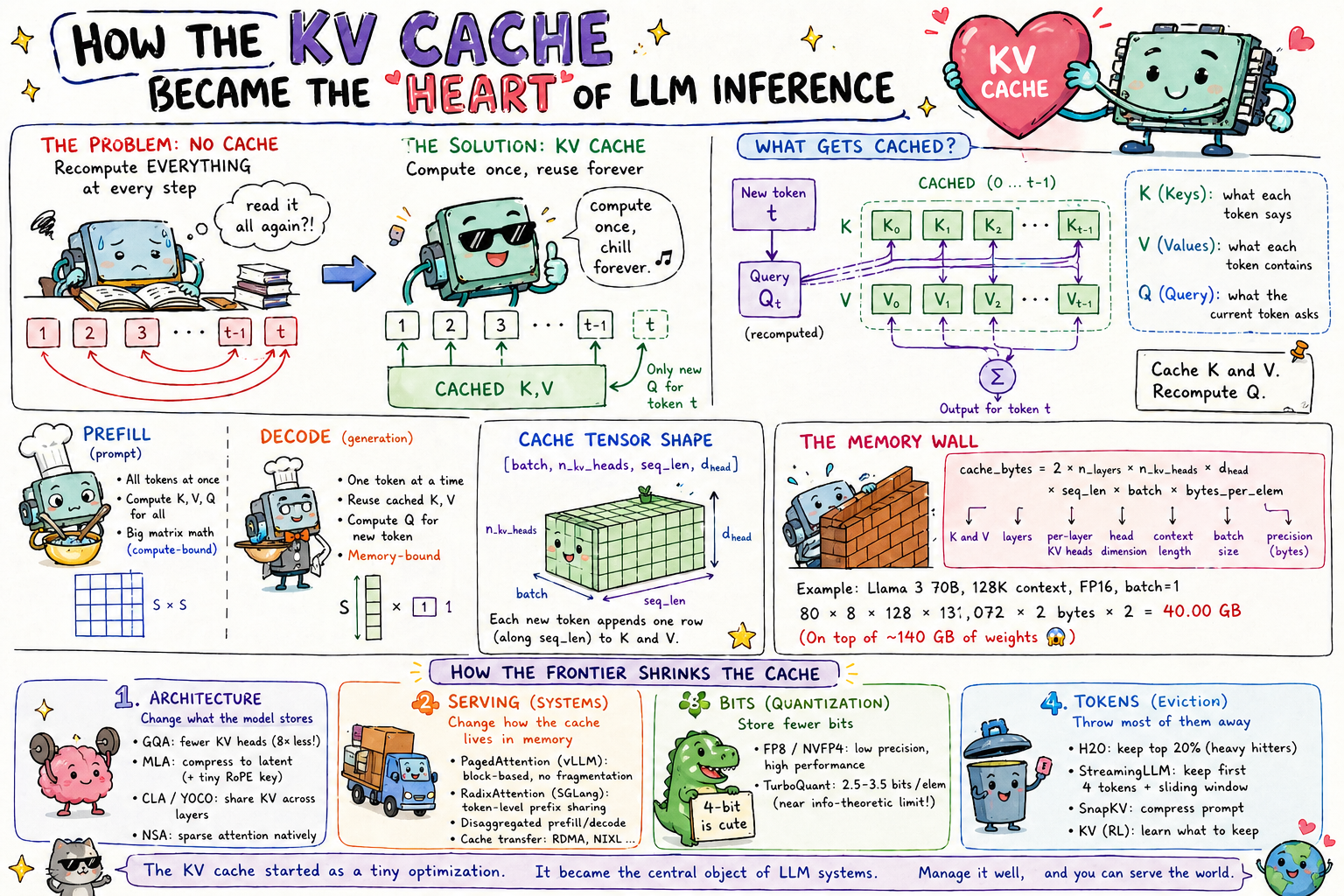
When a transformer generates the 1,000th token of a response, it has technically already done 99.9% of the work needed to produce it…
When a transformer generates the 1,000th token of a response, it has technically already done 99.9% of the work needed to produce it…