You type a perfectly normal sentence into ChatGPT:
“My app crashed after the update.”
And the model replies like a human. It feels like the model is reading your words the way you do. It’s not. Under the hood, the model does something much more “engineering-ish”:
- It breaks your text into small pieces
- It turns those pieces into numbers
Those two steps are called tokens and embeddings.
If you understand these two ideas — without getting scared by jargon — you’ll suddenly find it easier to understand everything else you’ll meet later: attention, Transformers, context windows, vector databases, RAG, fine-tuning… all of it. This post goes slow and goes deep, but stays beginner-friendly.
The 10-second mental model (keep this in your head)
When you talk to an LLM, the pipeline is basically:
Text → Pieces → Numbers → (lots of math) → Pieces → Text
- The “pieces” are tokens
- The “numbers” are embeddings
That’s today’s entire post. No hype. Just the mechanism.

Part 1 — Tokens: how the model “sees” your sentence
1) Why do we need tokens at all?
Humans read text as a smooth stream. Models can’t. Models need discrete units — like Lego bricks. So we take:
“My app crashed after the update.”
…and split it into smaller chunks. Something like:
- “My”
- “app”
- “crashed”
- “after”
- “the”
- “update”
- “.”
Each chunk is a token. Beginner definition (correct and friendly):
A token is a small chunk of text that the model treats as one unit.
That’s it.
2) Are tokens just words?
Sometimes, yes.But if tokens were only words, the model would struggle in the real world. Because real-world text is chaotic:
- New words appear daily (product names, slang, memes)
- Spelling is messy (“logn”, “canttt”, “recieve”)
- People mix languages (“Bro OTP nahi aa raha”)
- People use domain jargon (“GNSS”, “XUV700”, “RoPE”, “LoRA”)
- People write in code, URLs, IDs, emojis, punctuation storms
If you tried to keep a dictionary of every possible word, it would explode. So modern language models usually use a clever compromise:
subword tokens (pieces of words)
Example vibe (illustrative, not exact):
- “unbelievable” → “un” + “believ” + “able”
Now even if the model has never seen “unbelievable” as a full word, it has probably seen “un”, “believ”, and “able” many times. This is the first “quiet genius” of modern NLP:
Handle infinite language using finite building blocks.
3) Who decides how text is split?
There’s a component whose whole job is splitting text into tokens. It’s called a tokenizer. But don’t let the word intimidate you. A tokenizer is just:
a rulebook that decides how text becomes pieces.
Different models can use different rulebooks. That’s why:
- the same sentence can become different token counts across models
- your cost and context usage can change when you switch models
- a prompt can behave slightly differently across models
If you’ve ever felt “this prompt worked in Model A but feels weird in Model B” — tokenization is one big reason.
4) Why subwords beat words and characters (the trade-off triangle)
If you tokenize by words:
- ✅ short sequences
- ❌ huge vocabulary problem
- ❌ unknown words hurt badly
If you tokenize by characters:
- ✅ tiny vocabulary
- ❌ long sequences (slow, expensive)
- ❌ harder to learn meaning
Subwords are the compromise:
- ✅ manageable vocabulary
- ✅ manageable sequence length
- ✅ can build rare/new words from known pieces

This is why subword tokenization is so common in modern LLMs.
5) Tokens are the real unit of cost and context
This is where tokens stop being “theory” and start being painfully practical.
A) Cost
Many GenAI systems charge by tokens:
- tokens in (your prompt)
- tokens out (model response)
That means:
- word count is not the real cost
- character count is not the real cost
- token count is the real cost
B) Context length
Every model has a context limit: a maximum number of tokens it can pay attention to at once. So when you paste a long document and the model ignores the last section? Very often: it didn’t ignore it. It never saw it. It got pushed out.
C) Prompt “mystery failures”
Sometimes your prompt looks logically perfect but fails because:
- it got split into tokens in an unexpected way
- the important instruction got pushed too far back
- formatting and long IDs consumed your token budget
Tokens quietly decide what the model can and cannot see.
6) A beginner-friendly way to feel tokenization
Think of tokenization like this:
Tokenization is compression for language
Not compression like zip files, but compression like:
- “Represent this sentence using reusable building blocks.”
Common patterns get single blocks. Rare patterns become multiple blocks.
That’s why:
- repeated common words often tokenize efficiently
- weird strings, long URLs, and random IDs can explode into many tokens
So tokenization is not only “splitting” — it’s choosing an efficient representation.


7) Why some text “costs more” than it looks like
Here are a few token-cost traps that surprise people:
- Long URLs / hashes / IDs
"a7f9c1e8d4..." often becomes many tokens. - Code
Brackets, indentation, symbols, and camelCase can increase token count. - Mixed-language / transliteration
“OTP nahi aa raha bro” may tokenize into more pieces than pure English. - Emoji-heavy text
Emojis are valid tokens, but can behave differently across tokenizers.
The lesson:
If you’re building a product, you must measure tokens. Don’t guess.
8) A micro-exercise (to make it stick)
Take these two sentences:
- “Please reset my password.”
- “Pls reset my pwd ASAP!!! 😭😭”
They look similar in meaning. But they can tokenize very differently because of:
- slang (“pls”, “pwd”)
- caps (“ASAP”)
- punctuation storm
- emojis
Same meaning → different token behavior.
That’s why production NLP is not “just language”. It’s language + representation.
Part 2 — Embeddings: why the model needs “lists of numbers”
Now we have tokens. But tokens are still text-ish. Models can’t think in text.
Models do math. So we convert each token into numbers. That conversion is called an embedding.
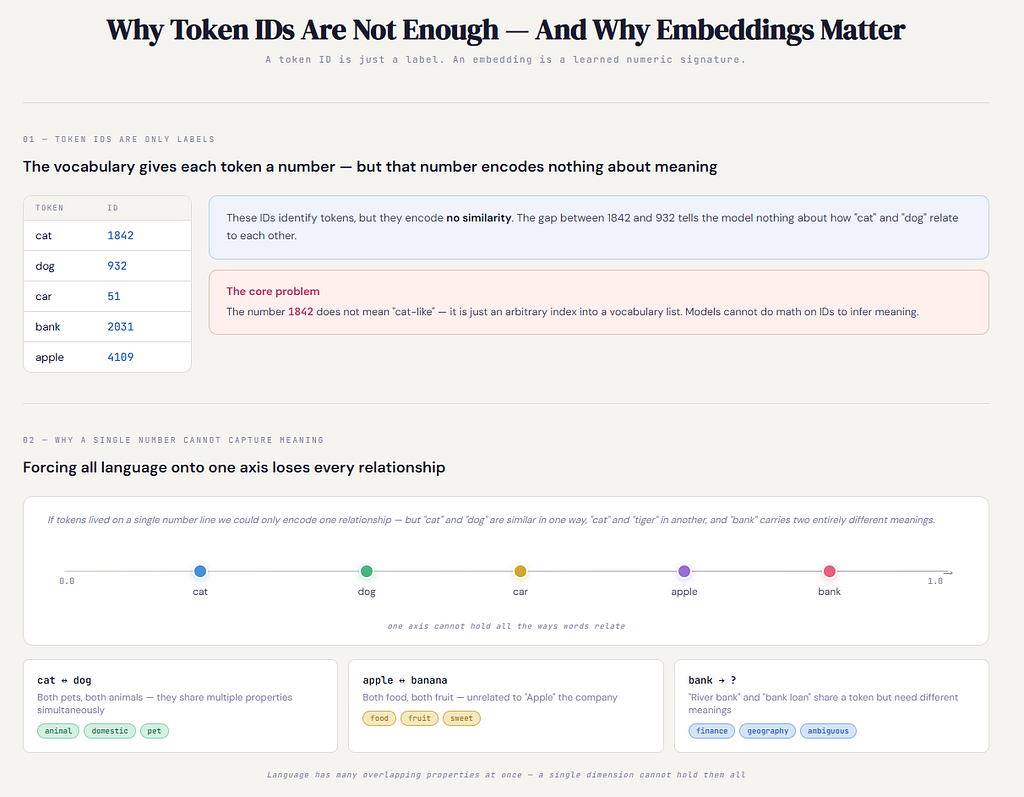
9) The key problem: token IDs have no meaning
Inside a model, each token gets an ID.
(These are made up examples, just to illustrate.)
- “cat” → 1842
- “dog” → 932
- “car” → 51
A beginner might think:
“So 1842 means cat.”
№1842 is just a label. Like a student roll number. Roll numbers don’t carry meaning. They only identify. So the model needs a representation where “cat” and “dog” can be recognized as more similar than “cat” and “car”. A plain ID can’t do that.
10) Your intuition is perfect: one number line can’t represent relatedness
Imagine every word had just one number (a point on a line). Then “relatedness” could only mean:
closer on the line = more related
But that breaks immediately. Because language has many types of similarity at once.
“Apple” can relate to:
- fruit (food meaning)
- sweet (taste)
- healthy (nutrition)
- iPhone (brand meaning)
That’s not one axis. That’s multiple. So instead of giving a token one number, we give it a list of numbers.
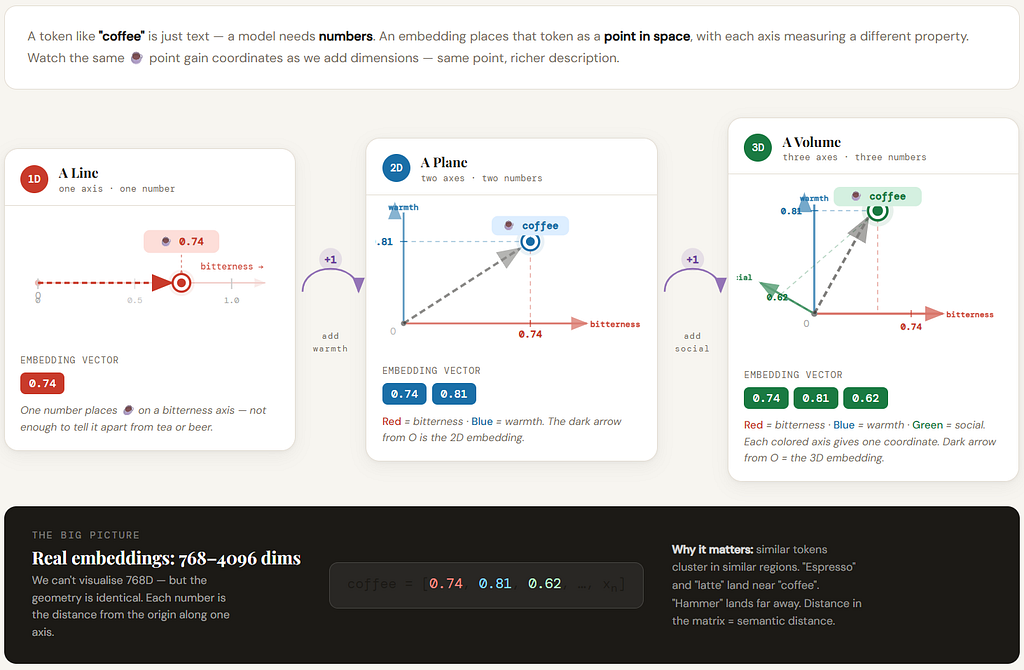
11) What an embedding really is (no scary notation)
Embedding (plain English):
An embedding is a learned numeric signature for a token — a list of numbers that represents it.
If you like analogies:
- Token = a name tag
- Embedding = that token’s “profile” written in numbers
- The model learns these profiles so it can compare tokens and generalize
Or:
- Token = a word-piece
- Embedding = its coordinates in a learned “meaning map”
- Similar tokens end up near each other in that map
But you don’t need to visualize a 768-dimensional map.
Just remember:
Many numbers give the model enough room to store multiple hidden properties.
12) The most concrete way to picture embeddings: a lookup table
Here’s the engineering picture: Imagine a giant table:
- Left column: token IDs
- Right side: a list of numbers for each token ID
When the model sees a token, it “looks up” that token’s row and retrieves its numbers. That’s all. So embeddings are not mystical. They are:
a learned lookup table from token → list of numbers
The learning happens during training.
13) Why embeddings work: they let “similarity” be computed
Once tokens become numeric signatures, you can compute similarity using simple math ideas like:
- distance (“near/far”)
- alignment (“pointing in similar directions”)
This is the foundation of things like:
- semantic search (“find similar meaning”)
- clustering (grouping similar texts)
- retrieval (vector databases)
- and later: attention (which mixes token meanings using these numeric relationships)
So embeddings do one magical-but-real thing:
They convert “meaning” into something math can operate on.
14) A small but important truth: embeddings are learned from data, not from dictionaries
Embeddings are not “definitions”. They are learned from usage.
Words get their meaning from context — how they appear with other words.
That’s why models can learn that:
- “doctor” relates to “hospital”
- “king” relates to “queen”
- “battery drain” relates to “power consumption”
Because those patterns repeat in real text. So embeddings capture:
- the training data’s world
- the training objective’s priorities
- and yes, the training data’s biases
This matters if you use embeddings for high-stakes tasks.
15) Two kinds of embeddings people confuse (this is big)
When people say “embedding”, they often mean one of two things:
A) Token embedding (static starting profile)
Each token has a starting signature. Same token → same starting numbers.
B) Contextual embedding (dynamic meaning after context)
After the Transformer processes the sentence, the representation changes based on context.
So “bank” is represented differently in:
- “river bank”
- “bank loan”
This is why Transformers feel powerful:
They don’t store one meaning per word.
They compute meaning per context.
If you truly absorb this, you’ll later understand attention much faster.


16) Embeddings exist at multiple levels (token vs sentence)
So far we talked about token embeddings. But you’ll also hear people talk about:
- sentence embeddings
- document embeddings
- paragraph embeddings
These are simply ways of creating a single numeric signature for a larger piece of text.
How do we get that? Common strategies include:
- averaging token vectors (simple and often surprisingly good)
- using a special “summary” token representation (depends on architecture)
- using models trained specifically to output good sentence embeddings
This matters because:
- token embeddings are great for internal model computation
- sentence/document embeddings are great for search, clustering, and RAG
Part 3 — Put them together: what actually happens when you prompt an LLM
Now the pipeline is clear:
- Your text becomes tokens (pieces)
- Tokens become embeddings (numeric signatures)
- The model applies layers of computation to update these representations using context
- The model predicts the next token
- That token gets added to the sequence
- Repeat until the answer is done
- Tokens are converted back into readable text
So the model is literally living in the world of tokens and embeddings. We just see the final decoded sentence.
Part 4 — Why this matters if you’re building anything real
If you’re only using ChatGPT for fun, tokens/embeddings are “interesting”. If you’re building products, tokens/embeddings become engineering parameters.
17) Practical token checklist (production mindset)
Track:
- average tokens in
- average tokens out
- p95 token counts (tail latency and tail cost)
- truncation rate (how often inputs exceed context)
- “prompt bloat” over time (prompts tend to grow)
Strategies:
- compress instructions
- move static instructions into system prompts/templates
- summarize older context
- chunk documents before sending
- retrieve only what’s relevant (RAG)
Tokens are not just a concept — they’re your budget.
18) Practical embedding checklist (search/RAG mindset)
When using embeddings for retrieval:
- choose chunk size thoughtfully (too big → irrelevant noise, too small → missing context)
- add overlap between chunks (prevents boundary losses)
- evaluate retrieval quality with real queries (don’t trust vibes)
- normalize vectors if your pipeline expects it (varies by method)
- monitor drift (your data changes, embedding quality changes)
Embeddings are powerful, but they don’t guarantee truth — only similarity.
19) A simple “first RAG truth” that tokens + embeddings explain
RAG works because:
- you embed your documents (numeric signatures)
- you embed the user question
- you retrieve “nearest” chunks by similarity
- you feed those chunks into the LLM
So RAG is basically:
“Use embeddings to fetch relevant context, then use the LLM to write the answer.”
If you understand tokens and embeddings, RAG stops being mysterious.
Part 5 — Common misconceptions (quick corrections)
Misconception 1: “Tokens are words”
No. Often subwords.
Misconception 2: “Embedding means the word’s definition”
No. It’s a learned signature shaped by usage patterns.
Misconception 3: “More dimensions always means better”
Not always. More dimensions increase memory/compute and can hurt if not trained properly. It’s a trade-off.
Misconception 4: “Embedding similarity = factual correctness”
Similarity can be wrong, biased, or misleading. It’s about closeness in learned representation, not truth.
Misconception 5: “Token count ≈ word count”
No. It varies by tokenizer, language, formatting, and input type.
Wrap-up: the calm, honest takeaway
- Tokens are how an LLM reads your text: pieces
- Embeddings are how an LLM represents those pieces: numeric signatures
- Once language becomes numbers, everything else becomes possible
Tokens & Embeddings: How LLMs Turn Text into Numbers (Explained So a First-Timer Actually Gets It) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.