Late last year a new AI psychosis kicked off. This time it was coding agents.
People started saying this is a new era in programming, blah blah blah.
*Karpathy tweet, late winter*
A few months later, we’ve got more than just claims. We’ve got numbers. And they say something unusual is happening in the market.
Coding agents are the first AI product people are paying for at volume and regularly. Because it directly speeds up their work. It’s too early to claim businesses are replacing whole processes with agents across the board. But compute demand has started growing faster than anyone can build it out.
Here’s why this moment is different, why nobody’s ready, and what I took from it personally.
The Numbers
OpenAI and Anthropic might go for an IPO soon. That’s why they’re eagerly posting how fast their revenue is growing.
And it’s a ton of money.
Anthropic is up 3x since the start of the year. And they’re already a big company. This is impressive, because the bigger you are, the harder it is to keep growing at the same pace.
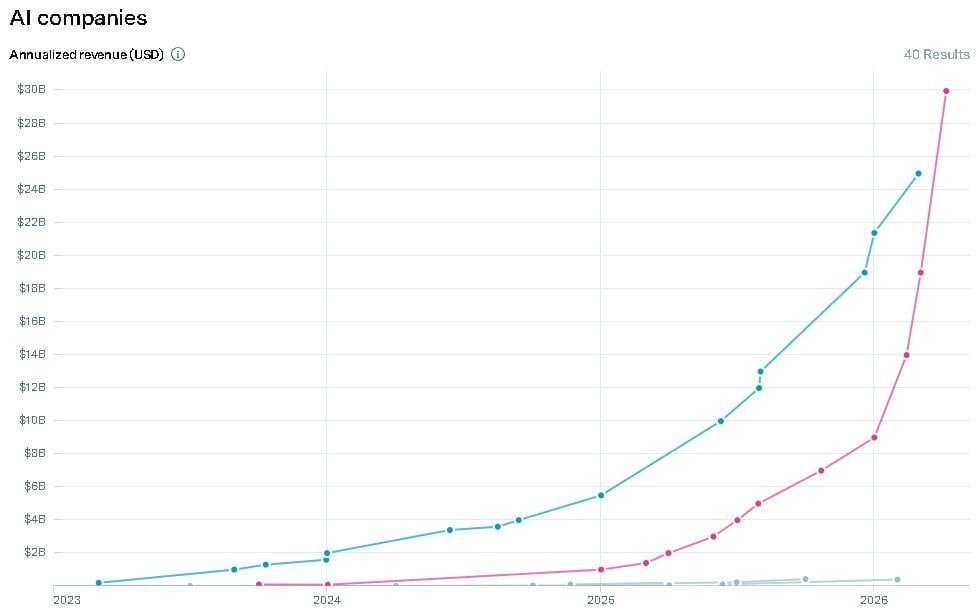
*OpenAI on the left, Anthropic on the right.*
Even during past boom moments, nobody hit numbers like these (with a caveat, see below). Zoom during the pandemic, Google at IPO, Coinbase cashing in on commissions during the crypto hype. These are companies 5-10x smaller than Anthropic, in special situations, and they still grew slower!
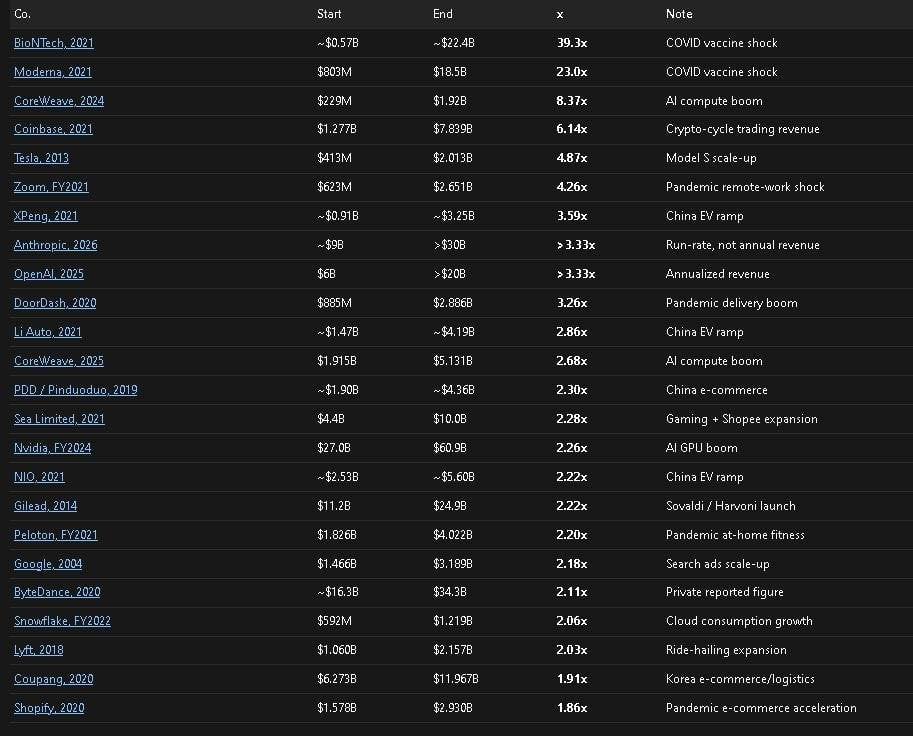
*The best growth years for big companies. Only ones that were already large. Revenue measured at start vs end of year.*
The caveat. First, vaccine makers during the pandemic were also up there. Second, Anthropic’s numbers are a projection for the rest of the year based on early data. And they count things a bit differently than OpenAI. None of that changes my conclusion, which is..
Cash is a solid tell for real demand for agentic systems.
Last year when a bunch of people suddenly figured out ChatGPT could generate cool images, that didn’t translate into serious money.
Meanwhile, in January alone, Claude Code commits on GitHub (in publicly accessible repos) went from 2% to 4%. If that sounds small, keep in mind it’s one month, and that’s without Codex, Copilot, or Devin. By end of year Dylan Patel forecasts Claude hitting 20%+.
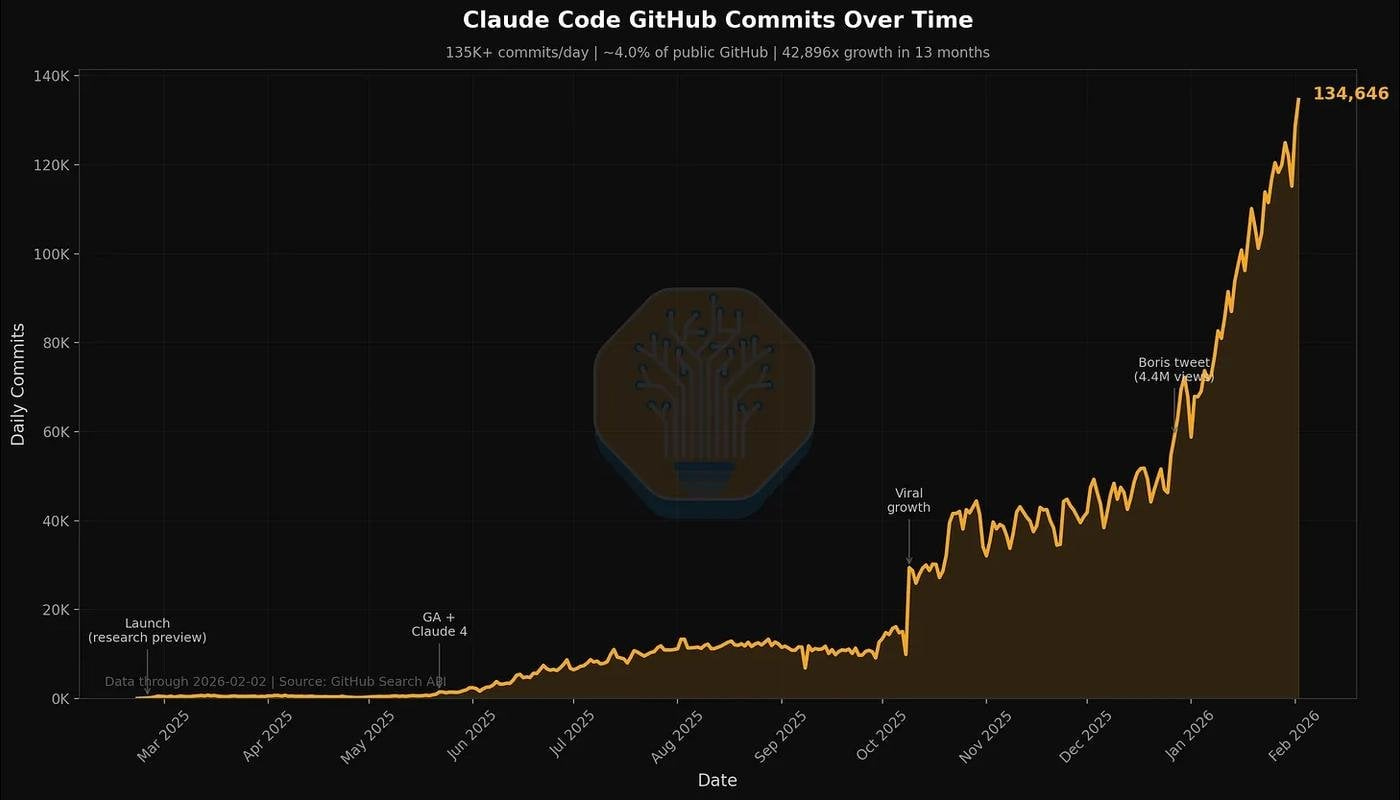
*Claude commits on GitHub.*
Even if a $100 subscription only automates a small slice of the work, that’s nothing compared to a developer’s salary. For a median developer at $350-500 a day, the subscription has 10-30x ROI if it handles just the simplest, most routine 10% of their work.
There’s plenty to argue with here.
Let me even lay out the weak spots in my own logic.
So their revenue is growing, fine - the labs are still unprofitable as businesses. They have every incentive to pump the hype to pull in the most risk-tolerant companies. The ones paying are early enthusiasts, not big companies. And enthusiasts come and go. Plenty of bubbles have popped exactly this way.
Agents are unstable and still randomly screw up. Who’s to blame when things go wrong? You can’t replace humans yet, because serious businesses care about reliability. And where do senior engineers come from without juniors if you stop hiring?
Agents only handle a narrow set of tasks well. Even if writing code is faster, shipping a product still gets bottlenecked by gathering requirements, architecture, review, testing, and our beloved stakeholder zoomcalls and compliance.
I decided at some point you have to commit and pick a side, even without conclusive evidence.
The finish line can be moved forever. There was a time when reasoning was completely out of reach for ML models. Same for decent image generation, or speech that didn’t sound like a robot. There was a time nobody believed machines would learn to play Go. You get the idea.
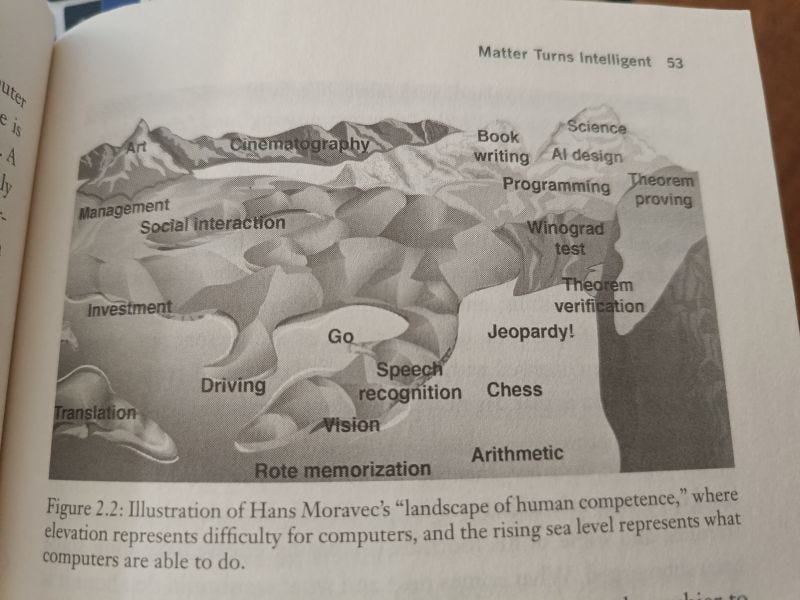
*Metaphor from Tegmark’s Life 3.0. Computers gradually learn harder and harder tasks. Over time there’s less and less they can’t do. Like water filling a map from the bottom up.*
Ilya Sutskever, back when he was still at OpenAI, often mentioned an internal meme - Feel the AGI.
He was one of the first to believe deep learning would gradually change our lives. Yes, there’s a lot we don’t know, but everything keeps moving in that direction, and that matters. Everyone gets it at their own moment. When a neural net does something you usually do yourself, manually, that’s a special feeling.
I’ve lost count of how many of those moments I’ve had in 10 years of following neural nets. So I’m not interested in the bubble-or-not debate anymore. I’m interested in watching the water level rise.
Personally, I have enough evidence that agents can now do valuable work that companies are willing to pay for.
And the thing is, demand has plenty of room to grow. Agents often don’t work out of the box. You have to adapt to them, and the fastest and most curious people do that best. Everyone else will catch up bit by bit.
And...
The Industry Isn’t Ready For This
To avoid talking about “the industry” in the abstract, let me split it into 3 layers.
- AI labs make models. OpenAI, Anthropic, DeepMind.
- Hyperscalers build datacenters. Google, Amazon, Microsoft, Meta.
- Chipmakers make chips. Nvidia, TSMC, ASML.
And at every layer, companies are scared.
People online love talking about bubbles. Turns out, all these companies are well aware bubbles happen. And to avoid going bankrupt, each one is cooking up its own workaround.
Dario Amodei says he builds the company’s plans off a pessimistic revenue scenario. Funny thing is, this year they’re already beating that by 1.5x. And only 3 months of the year have gone by. They’re beating the optimistic scenario too.
Dwarkesh asked him straight up in an interview: why? Dario genuinely believes in massive future upside from AI. He writes long essays about it, pitches a country of geniuses in a datacenter. And yet he doesn’t want to bet everything on that future.
Dario says it’s risky because of a cash flow gap in the business model.
Here’s how it works. They provide neural nets to users. They pay hardware owners for inference and make money from subscriptions and APIs. In parallel, they pour money into research on the next generation model. Which won’t start making money for another year or two.
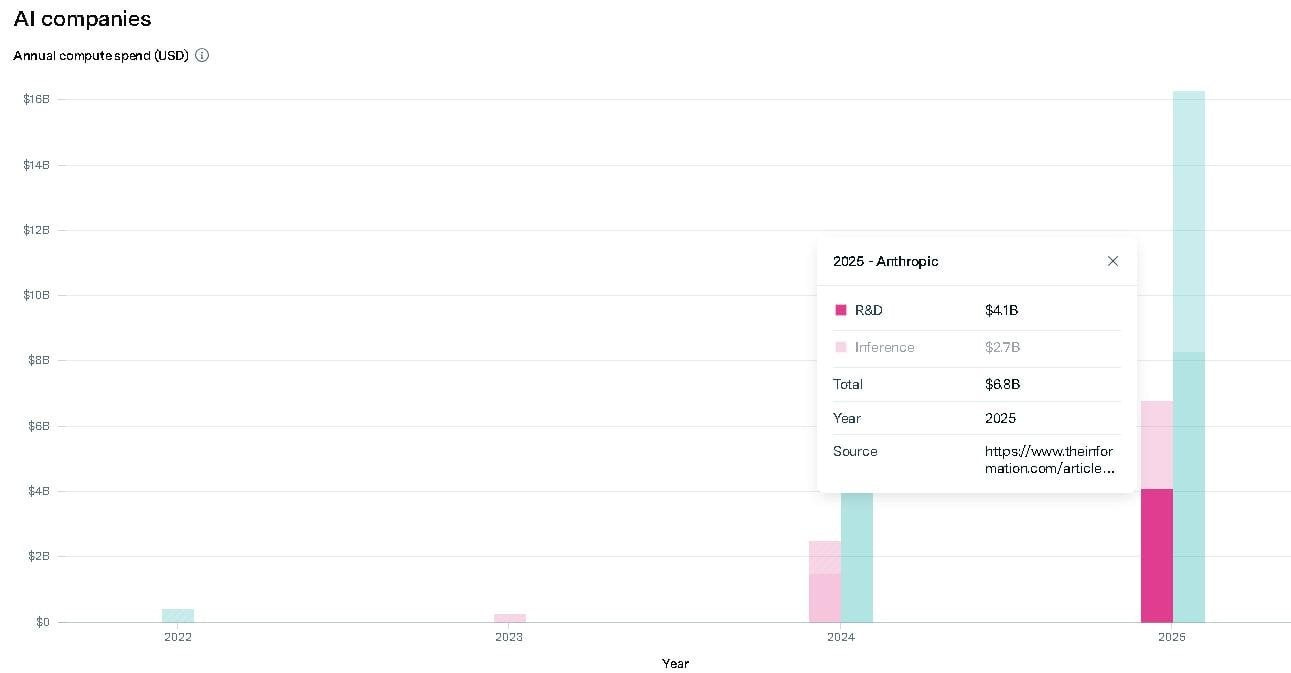
*They regularly spend more than half of revenue on research.*
You’re not just balancing income and expenses - you’re also balancing investment in future growth. If you invest big and the growth doesn’t show up, you’re in serious trouble.
Anthropic has been running in this mode for three years straight. Growing 10x every year. Dario figured 2026 would be when it ends. Because the bigger you are, the harder it gets. You are gonna slow down at some point.
What he didn’t mention in the interview, is that their margins are growing slower than forecast. Costs are growing multiple times faster than they’d planned.
Dario says he wants to push the company into profitability in a few years. To do that they need to improve margins. That means slowing growth and investing conservatively, only on the most efficient things.
The logic adds up. But slowing down isn’t really working. They look ready to 10x again this year. But the resources to support that aren’t there.
Anthropic doesn’t have enough compute for this many power users.
They rent GPUs from hyperscalers. And they can’t just walk into a datacenter and ask for more. Because the datacenter owner is also exposed to bubble risk. So capacity is booked out in advance.
For Anthropic to make $30B a year, someone had to spend $80B on infrastructure. Betting it would pay off in a few years.
Amazon will spend around $200B this year, Google $180B, Meta $125B, Microsoft $105B. That’s a setup for trillions in economic value in the coming years.
And a cash flow gap risk if the value doesn’t materialize.
The industry is one long value chain. Everyone in it tries to lower their own risk by locking expectations into contracts. Which reduces the whole chain’s ability to react to surprises. Like the sudden arrival of coding agents.
So every year labs hit some new bottleneck. And constraints keep sliding further upstream, toward players further from the end user. Because their risks are higher and their contracts are even less flexible.
A New Bottleneck Every Year
In 2023 everyone was chasing GPUs. More specifically, TSMC factories didn’t have enough capacity for the final chip-to-module assembly (CoWoS). In 2024 came the HBM memory shortage for those same modules. In 2025 GPUs got better, but datacenter buildout became limited by power supply. In 2026 it turned out even when you have the power, the US grid can’t deliver it to datacenters at the volume needed.
1 - Memory
Modern models need more memory than before. I mentioned earlier that companies spend hundreds of billions a year on infrastructure. Roughly 30% of that goes to memory.
And they have to buy expensive HBM instead of cheap DDR. Because high bandwidth reduces GPU idle time while memory processes its part.
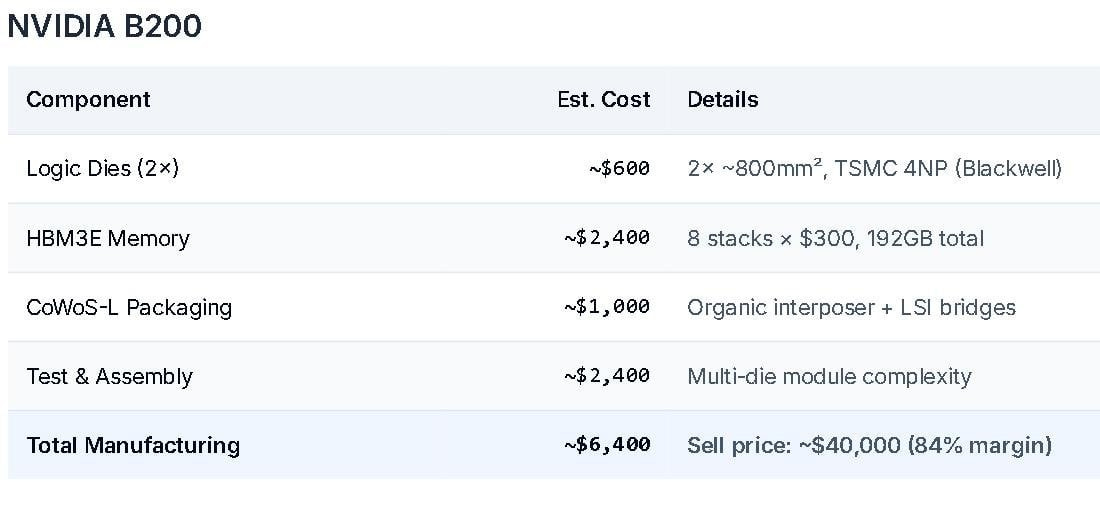
*Turns out memory is the most expensive thing in a GPU.*
Memory prices are probably going to keep rising unless someone figures out how to work around it. They could easily go up another 2-3x, because SK Hynix and Samsung control 90% of the market. And memory demand is only growing.
2 - Energy and Datacenters
xAI proved datacenters can be built pretty fast.
But they eat power like a small city. And when such a thing suddenly shows up in some region within six months, the electricity grid just can’t handle that.
Surprisingly, Dylan Patel isn’t that worried about energy. New power plants, transformer stations, and plain old transmission towers take a long time to build. But while the grid catches up to the new load, you can power datacenters off industrial gas turbines. Literally roll up to the datacenter with a dozen trailers full of generators and you’re good (tho people start to worry about that being far from clean energy).
There are also piston engines, solar with batteries, hydrogen reactors, marine ship engines... Basically, every trick the fuel industry has invented in its entire history. Together with more efficient grid usage, that can add up to hundreds of gigawatts.
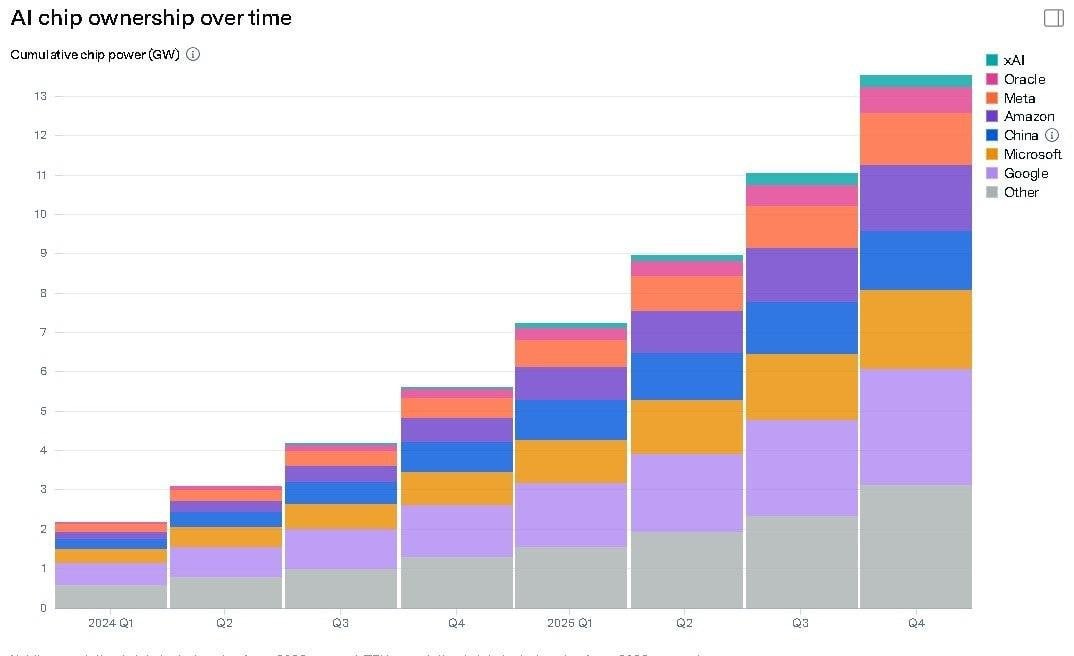
*Right now GPUs alone consume 13GW. Add the rest of the datacenter and you can multiply by 2.*
The blocker for building datacenters and reactors fast is a shortage of skilled labor, especially electricians.
So, expensive and labor-intensive. But turns out it’s still easier than the semiconductor supply chain.
3 - Semiconductors
There are factories (mostly TSMC) that assemble GPUs of a specific era (based on designs from Nvidia or Google). For example, on the 3-nanometer process.
And there just aren’t enough factories built.
This can’t be fixed quickly because these are some of the most complex industrial facilities on the planet. Building one takes 2-3 years and a pile of specialized equipment and chemistry.
The hardest piece is the lithography machines (EUV scanners). They’re needed to etch chips onto wafers. The wafers then get paired with memory into modules, and that’s how you get a GPU.
These machines cost ~$350M each. Only one company from the Netherlands makes them - ASML. Around 50 machines a year.

*The machine.*
By a rough estimate, by 2030 there will be around 700 of them worldwide. That’s on the order of 200 gigawatts of compute. And at the end of 2025 we were using ~27 gigawatts. Note that that’s before the agent hype of early 2026.
So there’s room to grow, but the shortage will be permanent - bottlenecked by factory construction, wafers, and lithography machines.
These are the kinds of constraints you can’t just throw money at, unlike memory and datacenter energy.
You can see it clearly in Google’s behavior.
They have their own chip designs. And they still buy a quarter of their capacity from Nvidia. They’d love to make their own, they just can’t.
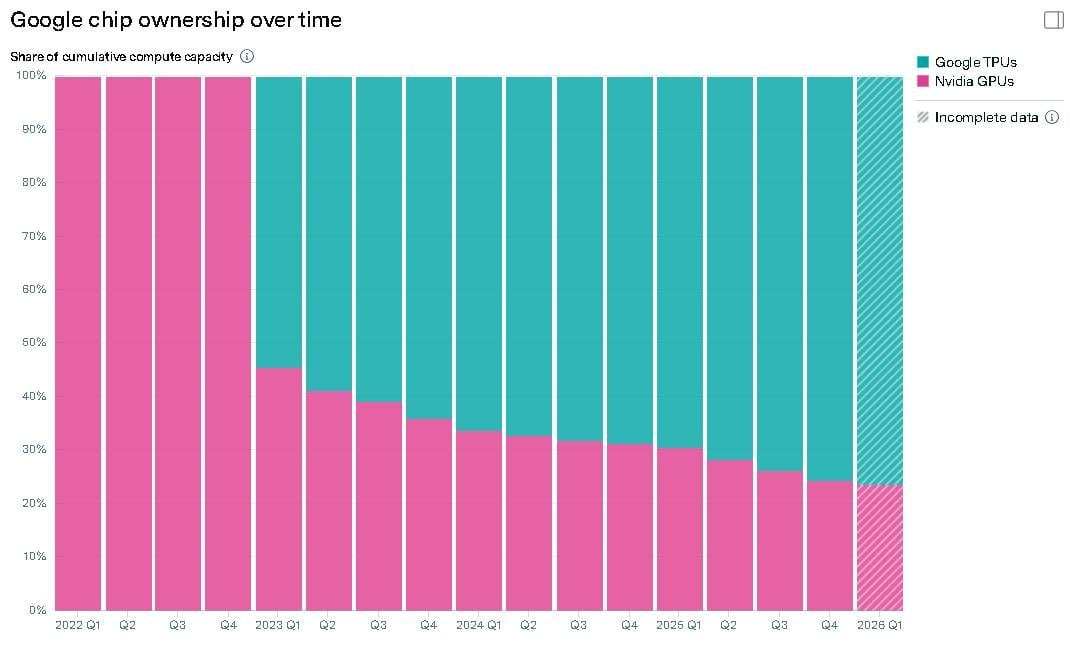
*The share is dropping, but it’s still a lot, considering their own chips are better!*
All chips are assembled at TSMC factories to someone else’s designs. And Google and Amazon (who also have their own designs) slept through the moment when Jensen Huang locked in contracts for 70% of 3-nm capacity. That’s great for TSMC - they’re at the end of the production chain and need stability.
Nvidia is also living the dream, selling cards at 6x production cost.
And Google even sold its own capacity to Anthropic through GCP. What a company.
So What?
So, the industry isn’t ready for the agent boom.
Because it came on too suddenly. To a market where what ultimately matters is long-term contracts on complex chip-making infrastructure.
Anthropic right now has 2.5 gigawatts of compute, and by the end of the year they need 5-6. The only way to get that much is the “Other” category. CoreWeave, Bedrock, Vertex, Foundry. Scraps from anyone whose capacity is still available, at premium prices.
And they want to become a profitable company, so they can’t afford to burn cash.
Hence the bad news.
The ones who’ll probably suffer are us.
The most obvious move is for them to just cut limits and raise prices.
The other week they moved OpenClaw onto the API. And they said so in a nice and honest way. Sorry guys. We’re tightening belts, here’s $20 as an apology for the inconvenience.
They also rolled out different tiers depending on time of day. I’ve already run into it a couple of times, when Claude just ran out of capacity. During “off-peak” hours, under pressure from people optimizing for discounted tokens.

*Denied.*
I pulled two takeaways from this for myself.
1 - Don’t put all your eggs in one basket.
For example, when building a skill, make it work on any model. I’m obsessed with Claude, but OpenAI and Google are in way better shape on compute access.
So I’ve learned to swap models depending on the task. I pay the minimum subscription to every lab. And when the limit runs out, I just switch models.
I’m not using Chinese open-source. Don’t use Deepseek, for the love of god.
2 - Get anxious about not making money off AI.
Neural nets aren’t a way for me to make more money. They’re on my expense sheet, and they pay for themselves by giving me more options and more time.
But if they roll out some $1000 tier, I won’t be able to pull that off. Right now that sounds absurd. But remember the example with a real person’s salary. As long as $1000 of spend brings in $5000 of profit, you’re winning.
And whoever can’t pull that off will be stuck on the free tier watching ads =/
Discuss