The Scissor Effect: Quantifying the Transition From Unstructured DevOps to Product-led Platform Engineering
How Platform Engineering focuses on improving the productivity and efficiency of an industry.
For several decades, DevOps has been one of the most influential movements in software engineering. DevOps revolutionized software engineering by dismantling the traditional silos between development and operations teams. By integrating automation, continuous delivery, and infrastructure as code (IaC) into a collaborative framework, these practices have successfully established themselves as the modern industry standard for building, deploying, and operating software.
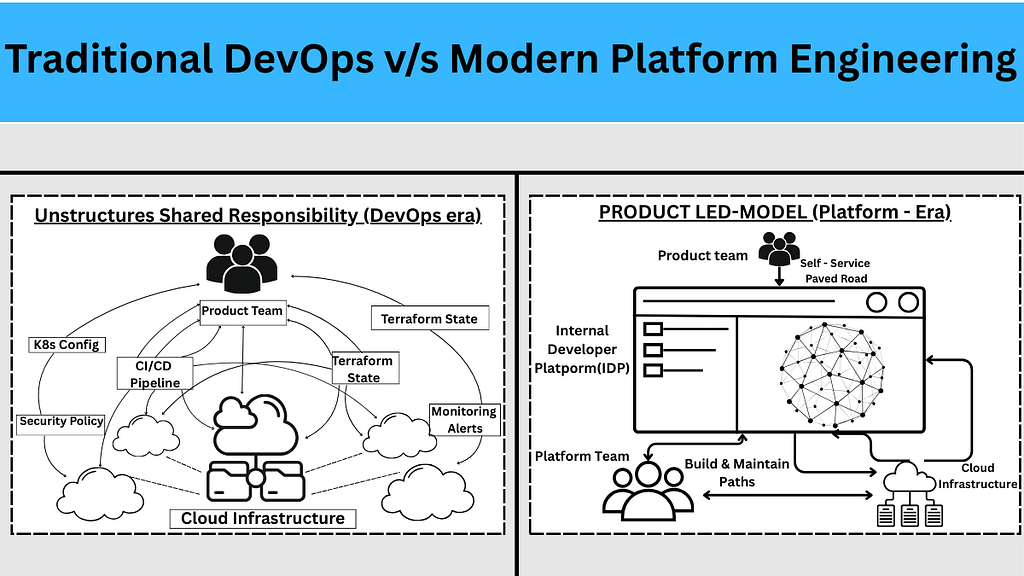
In the early days of the DevOps movement, the focus was simple: Break down the silos. However, in the rush to automate, many organizations fell into the trap of Unstructured DevOps. This led to “bespoke” automation scripts that only one engineer understood and pipelines that were as fragile as the manual processes they replaced.
Today, the industry is shifting toward a Product-Led Model, often referred to as Platform Engineering. In this model, the infrastructure isn’t just a service; it is a product and the developers are the customers.
1. The Era of Unstructured DevOps (The “Project” Mindset)
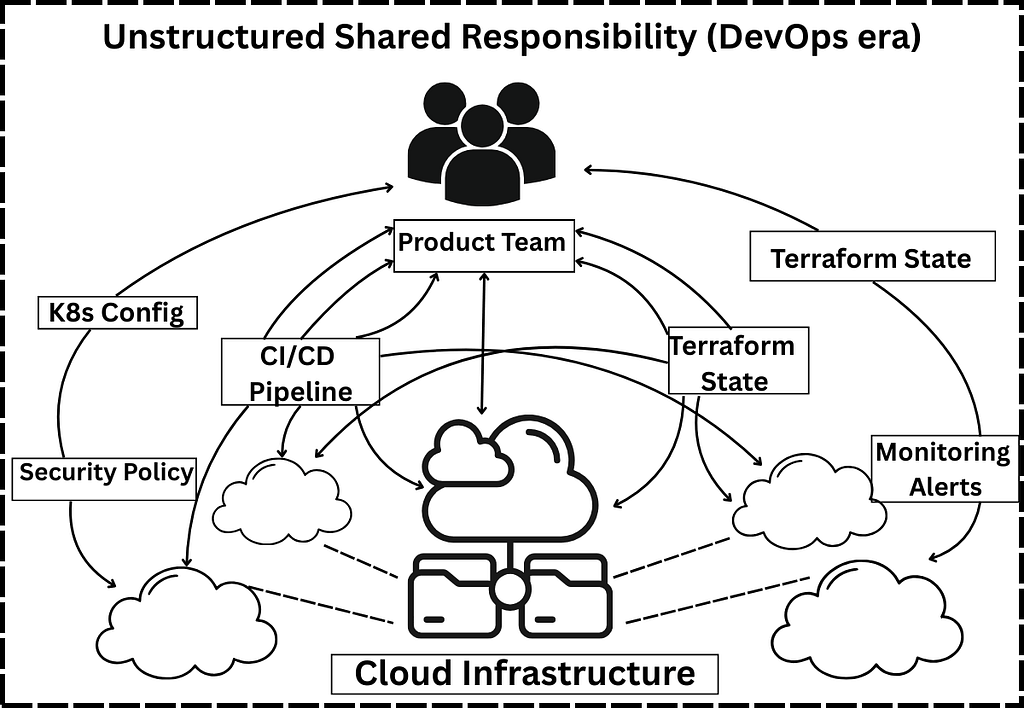
In an unstructured approach, DevOps is treated as a series of disconnected projects. A developer needs a database; an Ops engineer writes a custom script. A deployment fails; someone manually patches the server. Organizations adopted tools and practices such as:
- Continuous Integration and Continuous Delivery (CI/CD)
- Infrastructure as Code• Automated testing and deployment
- Monitoring and observability
- Containerization and orchestration
The Symptoms of Unstructured DevOps:
- High Cognitive Load: Developers must understand VPCs, Subnets and Kubernetes manifests just to ship a “Hello World” app.
2. Shadow Ops: Teams create their own fragmented fixes to bypass slow central processes.
3. The “Bus Factor”: If the lead DevOps engineer leaves, the tribal knowledge of how the pipeline works leaves with them.
To better understand the impact of unstructured DevOps, consider the example of a commercial airline pilot. The pilot’s main responsibility is to fly the aircraft and ensure the safety of passengers, similar to how a developer’s main role is to write and maintain core business logic. However, during the early and unstructured DevOps phase, developers were often expected to handle additional tasks; comparable to asking a pilot to refuel the aircraft, repair the engine during flight and manage baggage operations on the ground. While a pilot might learn how to do these tasks, every moment spent away from flying reduces their ability to focus on their primary responsibility. Platform Engineering acts like the dedicated ground crew and automated flight systems that support the pilot, allowing them to remain focused on flying the aircraft
2. The Shift to Product-Led DevOps

A Product-Led model treats the internal developer experience as a value stream. The goal is to build an Internal Developer Platform (IDP) that provides “Golden Paths”, pre-architected, secure and supported routes to production which can be directly used by the developers to build and deploy. Rather than requiring every developer to understand and manage every process, organizations create a dedicated Platform Team that builds a “Golden Path (also called a Paved Road).
The Golden Path: A standardized and self-service method for deploying code. When developers use the platform, essential features such as security, scalability and monitoring are automatically built in.
The Jungle Path: If developers have special requirements, they can choose to go off-road. This gives them full flexibility, but they must take complete responsibility for maintaining and supporting that solution.
The strength of the Golden Path lies in how it encourages adoption. It is not a strict rule that limits innovation; instead, it is an optional path designed to make development faster and easier. For example, if a developer uses the platform’s standard PostgreSQL setup, the Platform Team handles responsibilities such as 24/7 support, automated backups and security updates. However, if a developer decides to follow the Jungle Path and use a specialized or uncommon database, they must also manage all the operational responsibilities themselves. This approach “freedom combined with responsibility” naturally encourages teams to follow standard practices without forcing them through strict top-down policies.
3. The Structure of a Modern Internal Developer Platform (IDP) in 2026
A highly mature Internal Developer Platform (IDP) today is generally built around four essential layers:
1. Developer Portal (The Interface): This serves as a centralized dashboard where developers can view their services, documentation and system health metrics in one place. Tools such as Backstage or Port provide this “single pane of glass”, making it easier for developers to manage and monitor their applications.
2. Service Catalog: The service catalog functions as a collection of pre-approved templates and resources. For example, if a developer needs to create a new microservice with a Redis cache, they can simply select a template and the platform automatically sets up the repository, CI/CD pipeline and required cloud infrastructure.
3. Platform Orchestration: This layer acts as the core engine of the platform, converting a developer’s request into actual infrastructure operations. It manages underlying systems such as Kubernetes clusters and cloud services, allowing developers to focus on development without worrying about infrastructure management.
4. Automated Governance: Security and compliance rules are embedded directly into the platform through Policy-as-Code. This ensures that applications cannot be deployed if they violate organizational security or compliance standards, enforcing governance automatically during the deployment process.
4. Real-Life Case Study: British Telecom (BT)
British Telecom (BT) serves as a perfect example of moving from an unstructured legacy approach to a standardized product-led model.
• The Problem (Unstructured): BT faced siloed teams and manual ticket-based infrastructure requests. Deploying a simple update took weeks because developers had to wait for Ops to manually configure environments.
• The Implementation (Product-Led): BT adopted a Platform Engineering model. They built a self-service internal platform using Kubernetes and Docker, treating their CI/CD pipelines as a product for their developers.
• The Result: * Deployment Time: Reduced from weeks to hours.
- Quality: Automated testing in the “Golden Path” reduced production defects by over 30%.
2. Consistency: By using Infrastructure as Code (IaC), they eliminated “environment drift” where dev and prod environments didn’t match.
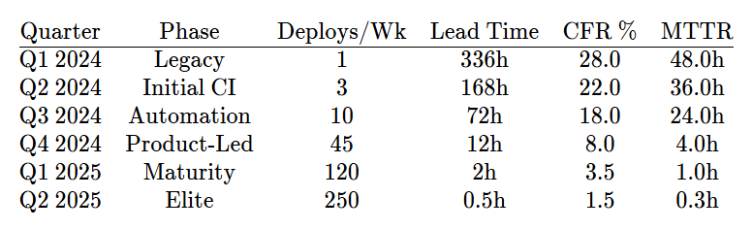
Consider the dataset below:
Note: The dataset utilized in this study is a reconstruction of the performance metrics reported during the British Telecom (BT) DevOps transformation. The full dataset and the Python scripts used to generate the following visualizations are available in the public GitHub repository: > https://github.com/rakshathnaik/devops-evolution-analysis

Deployment Frequency: Deployment Frequency (DF) tracks how often an organization successfully releases code to production. Initially, the team managed only 1 deploy per week due to manual, ticket-based handoffs. By transitioning to a product-led model, this scaled to 250 weekly deployments, demonstrating a massive 25,000% increase in the volume of value delivered.
Lead Time for Changes: Lead Time for Changes (LTTC) measures the speed of the pipeline from code commit to production. This metric plummeted from 336 hours (two weeks) to just 30 minutes. This shift indicates that manual approvals were replaced by automated “Golden Paths,” allowing the organization to respond to market needs and feedback loops almost instantly.
Change Failure Rate: Change Failure Rate (CFR) ensures that increased speed does not compromise system stability. Despite the rapid acceleration in deployments, the failure rate dropped from 28% to 1.5%. This proves that embedding automated testing and standardized environments into the platform allows for “safe speed,” where quality improves alongside velocity.
5. Quantifying the Evolution: The DORA Metrics

Note: The dataset utilized in this study is a reconstruction of the performance metrics reported during the British Telecom (BT) DevOps transformation. The values represent the documented shift in DORA metrics as the organization moved from legacy ticket-based operations to a Product-Led Platform model.
To prove that a Product-Led model is superior, we must measure the throughput and stability of our delivery pipeline. These are the four essential formulas:
1. Deployment Frequency (DF)
Formula:
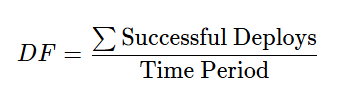
Problem: At the start of the transformation (Q1 2024), the team managed 1 deploy per week. By the “Elite Status” phase (Q2 2025), the platform-led model supported 250 deploys per week.
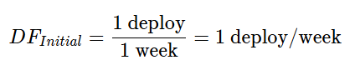
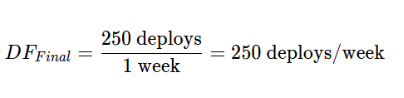
2. Lead Time for Changes (LTTC)
Formula:
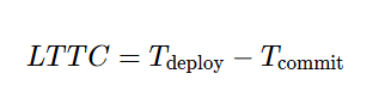
Problem: Initially, the time from code commit to production was 2 weeks (336 hours) due to manual handoffs. With the product-led model, this dropped to 30 minutes (0.5 hours).
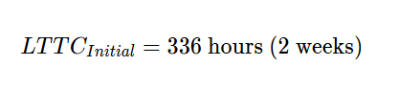

3. Change Failure Rate (CFR)
Formula
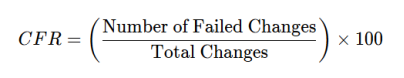
Problem: In the unstructured phase, 28% of changes resulted in a failure. After implementing automated Golden Paths, only 1.5% of changes failed.
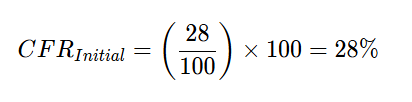
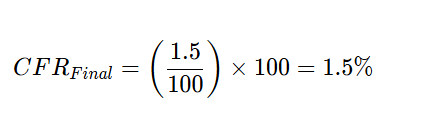
4. Mean Time to Recovery (MTTR)

Problem: Recovering from an outage originally took 48 hours. In the mature product-led model, automated rollbacks and self-healing infrastructure reduced this to 0.3 hours (18 minutes).
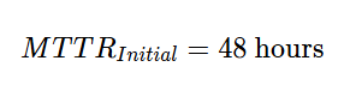

6. Implementing the Solution: The Platform Engineering Roadmap
Transitioning to a product-led model requires three pillars:
The Golden Path: The “Golden Path” is a pre-architected, self-service route to production that reduces developer load. By providing automated templates for common tasks like deploying a new microservice, the platform team ensures the right way is also the easiest. This allows engineers to focus on writing code rather than managing complex infrastructure configurations.
Infrastructure as Code (IaC): Infrastructure as Code (IaC) replaces manual server setup with version-controlled definition files stored in Git. This ensures that environments are fully reproducible, auditable and consistent across the entire organization. By treating infrastructure like software, teams can redeploy entire systems in minutes, significantly boosting stability and disaster recovery capabilities.
Feedback Loops: Rigorous feedback loops treat the developer platform as a living product by monitoring the health of the delivery pipeline itself. In this model, any deployment friction or pipeline failure is viewed as a bug that requires a fix from the platform team. Constant telemetry allows for iterative optimizations that keep lead times low and developer productivity high.
7. Conclusion
The transition from an unstructured, ticket-based DevOps approach to a mature, product-led model represents a fundamental shift in organizational performance. As demonstrated by the DORA metrics analysis, treating the internal developer platform as a product rather than a series of manual tasks unlocks a Scissor Effect where throughput and stability move in opposite directions. By achieving a 25,000% increase in deployment frequency while simultaneously reducing change failure rates to 1.5%, organizations prove that speed does not have to sacrifice reliability.
This evolution moves the burden of complexity away from individual developers and into automated Golden Paths, drastically reducing lead times from weeks to minutes. For faculty and practitioners alike, this data-driven journey underscores that elite performance is not achieved through more effort, but through better architecture. Ultimately, the product-led DevOps model provides the scalable foundation necessary for modern enterprises to remain agile, secure, and resilient in an increasingly competitive digital landscape.
References
Github: https://github.com/rakshathnaik/devops-evolution-analysis
[1] N. Forsgren, J. Humble, and G. Kim, Accelerate: The Science of Lean Software and DevOps: Building and Scaling High-Performing Technology Organizations (2018), IT Revolution Press.
[2] DORA, 2024 State of DevOps Report: The Evolution of Platform Engineering (2024), Google Cloud Research.
[3] A. Horne, The Platform-Led Transformation: How British Telecom (BT) Scaled to Elite Status (2024), DevOps Enterprise Summit (DOES).
[4] M. Skelton and M. Pais, Team Topologies: Organizing Business and Technology Teams for Fast Flow (2019), IT Revolution Press.
[5] Gartner, Market Guide for Internal Developer Portals and Platform Orchestration (2025), Gartner Research.
The Scissor Effect: Quantifying the Transition from Unstructured DevOps to Product-Led Platform… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.