From Ear (STT) →Brain (LLM) →Mouth (TTS)
We live in wildly interesting, exhilarating times. The scale and speed of technology are currently moving at an unprecedented pace, and my personal philosophy has always been simple: every technology evolution left untapped is a massive missed opportunity.
I’ve spent 16 years tearing apart machines and rebuilding them, watching technology paradigms shift, plateau, and eventually break. Yet, despite all of that, Voice AI wasn’t a frontier I had even touched until the beginning of 2025.
And frankly, nothing prepared me for the sheer violence of the voice interface.
We’ve been living in a comfortable, asynchronous illusion. We’ve been utterly spoiled by text. In a chat window, a three-second delay is standard. The user types, a blinking bubble appears, and the UI politely fills the void. We call it “thinking.”
Voice, however, is unforgiving. Voice is synchronous. In a real-time audio environment, silence doesn’t mean “processing” — it means a broken presence. It means the system is dead.
Over the last couple of months, I’ve been deep in the trenches — researching, navigating a chaotic plethora of offerings, coding, vibe-coding, and building a custom Voice AI orchestrator from the ground up to escape what I call the “Uncanny Valley of Latency.”
What I discovered fundamentally shifted my perspective. To win the war against milliseconds and hit magical human conversational speed, you have to completely rip out your existing foundation.

Welcome to the Sandwich Theory. Here is how you actually build it
The Paradigm Shift: Why 3 Seconds is Fatal
If you want to build a voice agent, the first thing you have to do is unlearn everything text-based LLMs taught you.

When humans speak to each other, our conversational latency hovers around 200–600 milliseconds. If an AI takes 3000ms+ to respond via standard API calls, the conversational flow shatters. The user repeats themselves, assuming the AI went deaf, which causes a catastrophic collision when the AI finally speaks.

We are fighting a war against the speed of light. Our target is that ~600-800ms human perception threshold. To get there, we need a new blueprint.
Why Production Demands the “Sandwich” Architecture
The current hype cycle wants you to use massive, end-to-end multimodal models. Audio goes into a black box, and audio comes out. But if you are building anything for scale, with security, transparency — where you actually care about observability, cost, and hallucination control — end-to-end models are a nightmare to audit.
Instead, I heavily favor the Modular “Sandwich” Architecture.

The orchestrator sits right in the meat of this sandwich, acting as the high-speed router managing the data streams between the “Ear” (Speech-to-Text), the “Brain” (LLM), and the “Mouth” (Text-to-Speech). This modularity offers three massive advantages:
- Observability: We can read transcripts instead of trying to debug raw spectrograms.
- Vendor Independence: We can swap underlying LLMs or upgrade our TTS without retraining our STT models.
- Cost Arbitrage: We can route simple, predictable intents to cheaper, faster models, saving our heavy compute for complex reasoning.
Fighting the Speed of Light: The Network Layer
Before we even touch AI, we have to fix the plumbing. Let me be blunt: HTTP/REST is dead for voice.

The ~800ms overhead of TLS handshakes and request/response cycles will bleed your latency budget dry. To build an orchestrator, you must utilize persistent WebSockets or WebRTC to establish a full-duplex connection.
Furthermore, you can’t terminate a WebSocket in a centralized server halfway across the globe.

Edge Ingress is required. You must terminate connections close to the user and ensure your STT, LLM, and TTS services are colocated in the exact same region.
The Input Layer: Solving the Cocktail Party Problem
Once the audio hits your server, you immediately face the “Cocktail Party Problem.”
In human acoustics, this refers to our brain’s uncanny ability to zero in on a single conversation in a crowded, noisy room while completely tuning out the music, the clinking glasses, and the other people talking. Our brains do this natively.
Microphones do not.
A microphone just captures a single, chaotic composite waveform. It hears your user’s voice, the dog barking in the next room, the mechanical keyboard clacking, and the HVAC unit humming — and it smashes them all into one flat audio stream.

For an AI to actually understand the user, we have to perform what amounts to blind source separation in milliseconds. Before transcription even begins, the audio needs to pass through a deep noise suppression model (like RNNoise or DeepFilterNet) and spatial filtering to isolate the target voice from the garbage.
But who decides when the user is actually speaking? Enter the Gatekeeper: Voice Activity Detection (VAD).
Legacy systems use energy-based volume bars. If a door slams, the volume spikes, triggering a false positive. Modern orchestrators must use Deep Learning VADs. By running this neural net on ingress, we can immediately drop silence packets.
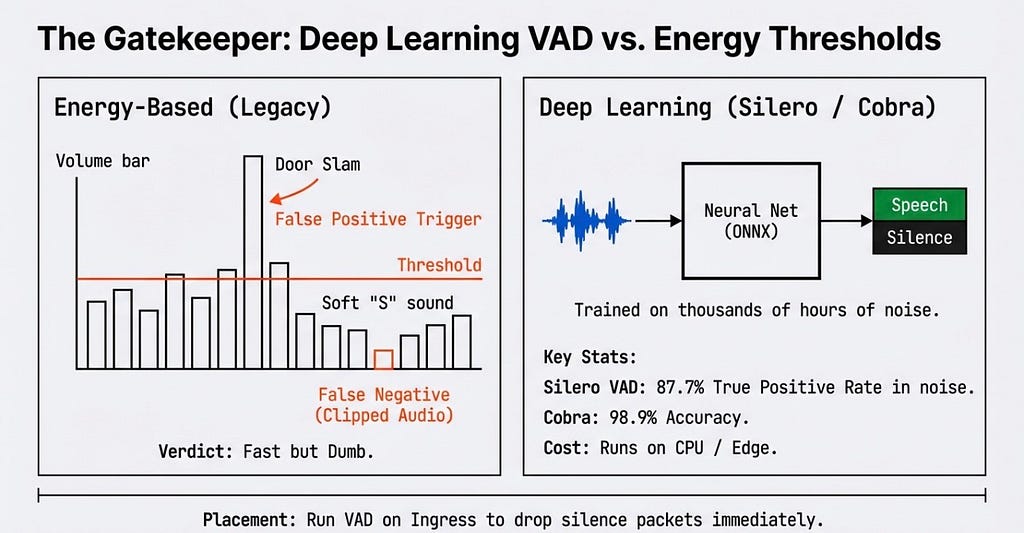
Here is a conceptual look at how you might use a modern VAD to protect your STT pipeline from garbage data
import torch
from silero_vad import load_silero_vad
# The Gatekeeper: Load deep learning VAD
vad_model = load_silero_vad()
def process_ingress_audio(audio_chunk):
audio_tensor = torch.from_numpy(audio_chunk)
speech_prob = vad_model(audio_tensor, 16000).item()
if speech_prob > 0.5:
# Signal detected. Stream to STT.
stt_pipeline.send(audio_chunk)
else:
# Noise/Silence. Drop packet to save milliseconds.
drop_packet()
The Orchestrator Core: The Streaming Waterfall
In traditional architectures, processing is sequential: User types -> System thinks -> System replies. Do this in voice, and you hit a 4000ms delay. We have to move to a Streaming Waterfall.
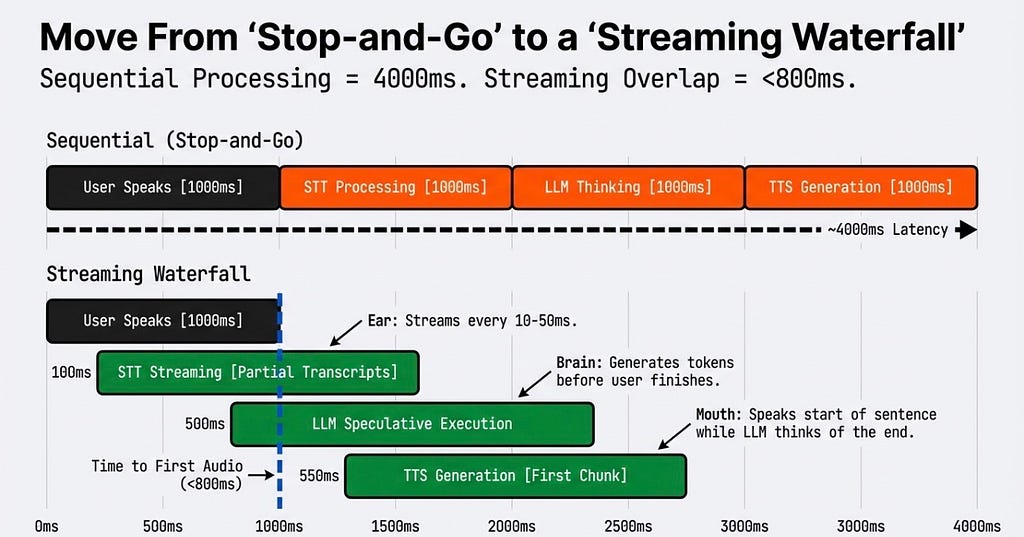
The orchestrator must stream partial transcripts from the Ear every 10–50ms. As the user is still speaking, the Brain (LLM) begins speculative execution. By the time the user finishes their sentence, the Mouth (TTS) is already generating the audio for the first chunk of the response.
But streaming partial transcripts creates a “Flicker” effect. STT models constantly revise their history as they gain more context (e.g., “I want two” -> “I want to go”).

Critical Learning: You must build an Execution Guard. Never trigger a backend API based on an unstable partial transcript. Wait for finality.
Turn Detection: The Elephant in the Room
How does the AI know it’s time to speak? Simple silence thresholds fail miserably here. If you use a short 500ms silence threshold, the AI interrupts the user while they take a breath. Wait 1200ms, and you create dead air.
You cannot determine turn completion by silence alone; you must understand the semantics.
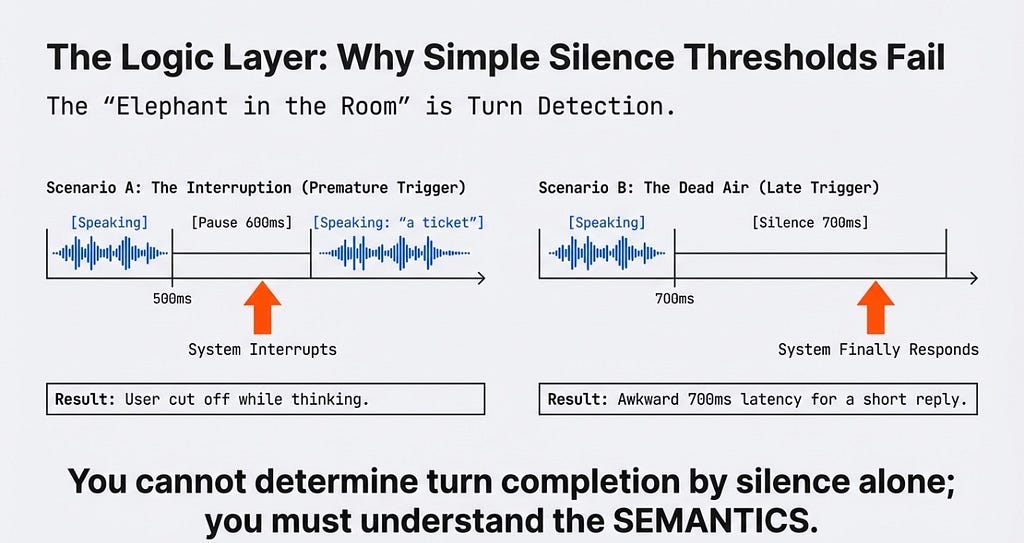
This is where Semantic Endpointing comes into play. Inside the orchestrator, we run a double-threshold logic matrix, piping the text into a blazing-fast, tiny local Small Language Model (SLM) to calculate a “Completeness Score.”

def check_turn_completion(transcript, silence_duration):
# Run transcript through a local, sub-1B parameter SLM
completeness_score = local_slm.evaluate(transcript)
# Fast Turn ("Yes.", "I agree.")
if completeness_score > 0.85 and silence_duration > 200:
return trigger_llm_response()
# Thinking Pause ("I need to check my...")
elif completeness_score < 0.40 and silence_duration < 1200:
return hold_buffer()
# Standard Fallback
elif silence_duration > 700:
return trigger_llm_response()
Ultimately, the voice agent is just a highly optimized Finite State Machine navigating between Listening, Thinking, Speaking, and Interrupted states.

Handling Chaos: Barge-Ins and Chunking
Users will interrupt the AI. When your VAD detects user speech while the AI is talking (a Barge-In), pausing the audio player is not enough. You need a Kill Switch.

The server must command the client to flush the audio queue. More importantly, the orchestrator must perform Context Truncation. If the AI planned to say, “It is sunny, do you want rain info?” but the user interrupted after “sunny”, the LLM’s history must be actively rewritten to only record “It is sunny-”. Feed unspoken text back into the memory, and the AI will hallucinate.
def handle_barge_in(interruption_timestamp):
# 1. Fire kill signal to dump client audio buffers
websocket.send({"action": "CLEAR_BUFFER"})
tts_engine.stop()
# 2. Truncate context to prevent hallucinations
words_actually_spoken = calculate_spoken(interruption_timestamp)
llm_history.truncate_to(words_actually_spoken)
# 3. Reset state
state_machine.set_state('LISTENING')
Then there is the issue of making the AI sound human. If we stream text to the TTS engine word-by-word, prosody (pitch and intonation) is destroyed.
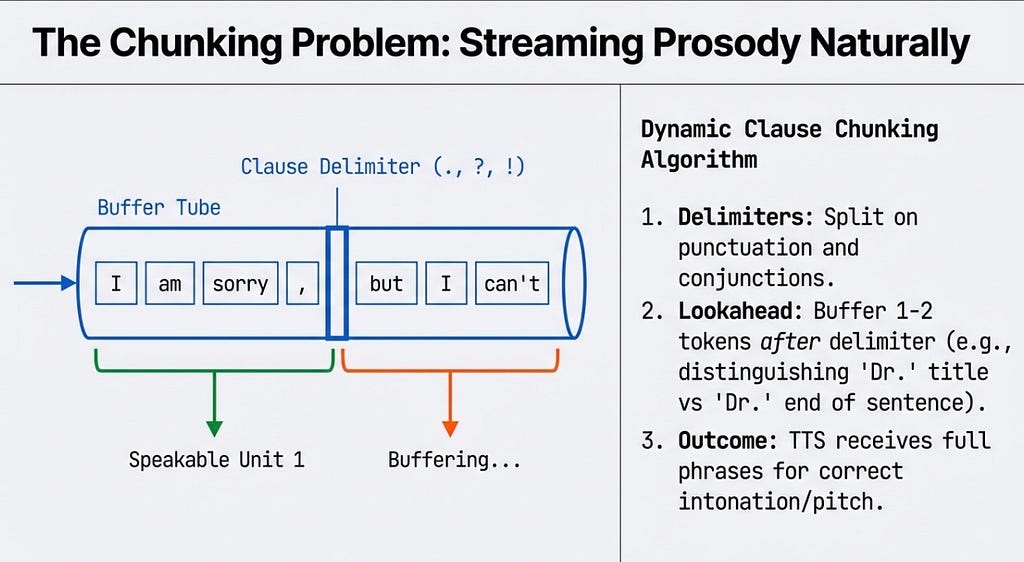
The orchestrator requires a Dynamic Clause Chunking Algorithm to buffer the text stream and split it on natural delimiters, ensuring the TTS receives complete phonetic phrases.
Floating it in the Ocean: Telemetry, Guardrails, and Evals
Building the prototype is fun; productionizing it is the real challenge.
- The Immune System (Guardrails) How do you implement safety checks without adding a massive ~800ms latency tax? Optimistic Execution. We stream the LLM output directly to the TTS, while simultaneously running a parallel safety guardrail model. If it fails, we digitally “cut the wire” and swap in a canned apology.

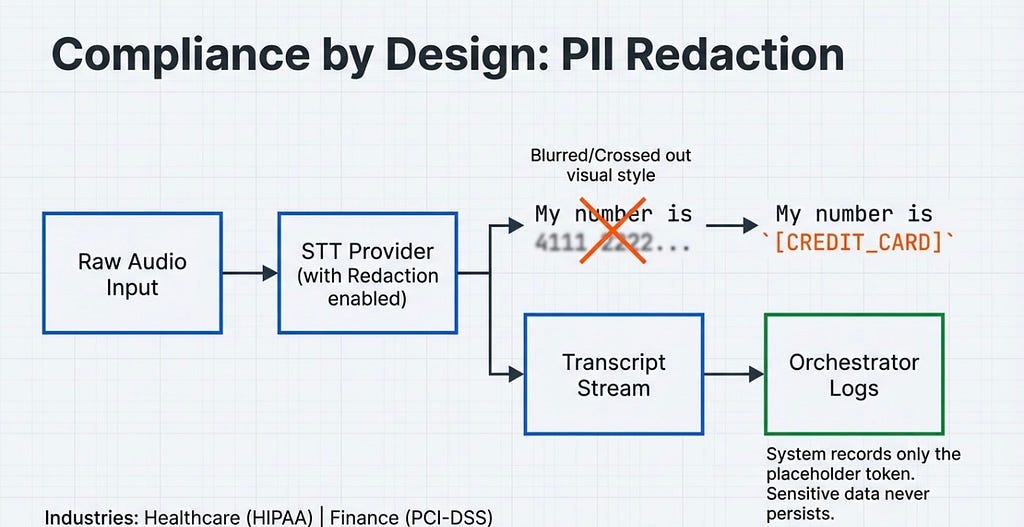
2. Compliance by Design PII cannot persist. The STT stream must route through a redaction layer before hitting the orchestrator’s logs, replacing sensitive data with placeholder tokens immediately.
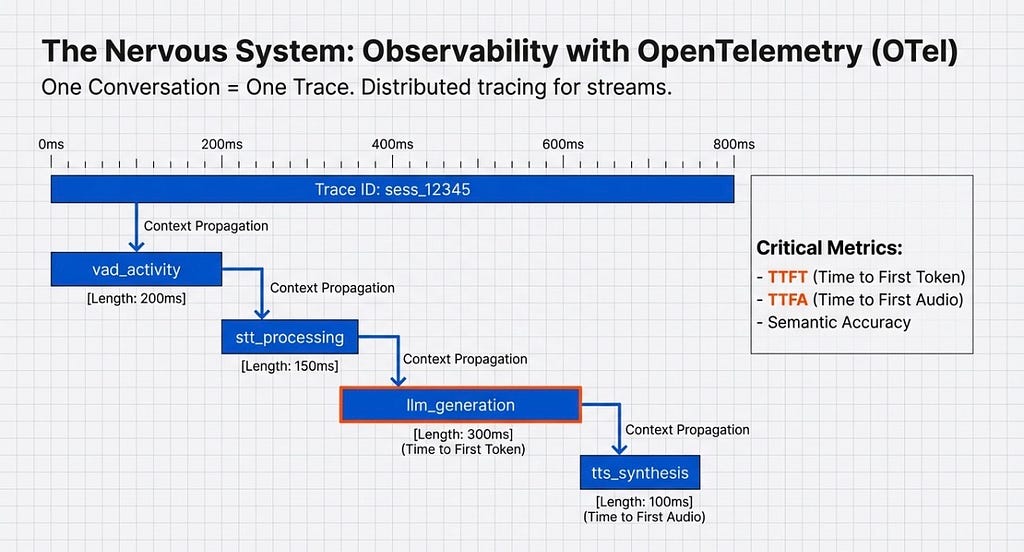
3. The Nervous System (Telemetry) You can’t fix what you can’t measure. Using OpenTelemetry (OTel), we treat one conversation as one continuous trace, monitoring TTFT (Time to First Token) and TTFA (Time to First Audio).
4. Modern Evaluation Metrics Legacy systems relied on Word Error Rate (WER). But if a user says “I want two pizzas” and the system transcribes “I want to pizzas,” WER flags a massive error, even though the semantic intent is identical. We must move to Semantic Distance, using vector embeddings to evaluate accuracy.

The Asymptotic Limit
Building a Voice AI Orchestrator is an exercise in extreme optimization
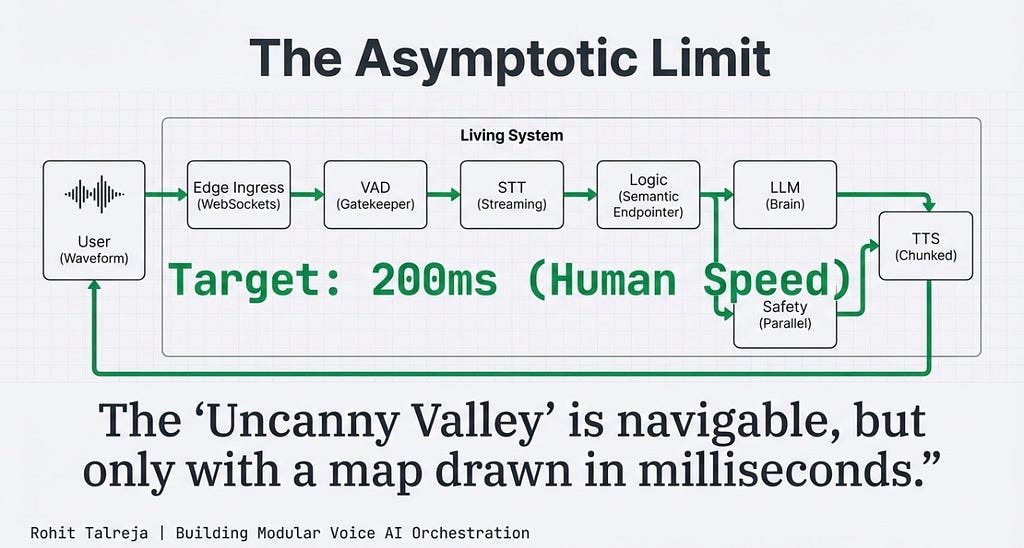
We are chasing the ~800ms Asymptotic Limit. By combining deep learning VAD, streaming waterfalls, semantic end pointing, and parallel guardrails, that Uncanny Valley is entirely navigable.
But it requires a map drawn in milliseconds.
There is still so much more to be done here. We are just scratching the surface of true Agentic AI over voice — where the orchestrator isn’t just talking, but seamlessly spinning up specialized sub-agents to execute complex workflows in the background.
The text paradigm taught us how to make AI smart. The voice paradigm is teaching us how to make it human. And that is an engineering challenge worth solving !!!
Vote of thanks —
If you’ve made it this far — thank you for taking the time to read. This is a 60K-foot view of a broader thesis I’ll be publishing in Q3 as part of my academic work. If this resonated with you, stay tuned for more.
The Sandwich Theory — Anatomy of Voice AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.