MiniMax M2.7 didn’t just score on the PhD benchmarks, it prepared for it, alone, over 100 iterations. Here’s why that changes everything.
By Shashwata Bhattacharjee | March 2026 | AI Architecture & Systems

“All LLM frontier labs will do this. It’s the final boss battle.” — Andrej Karpathy, AutoResearch launch, 2026
The Number That Hides the Story
66.6%.
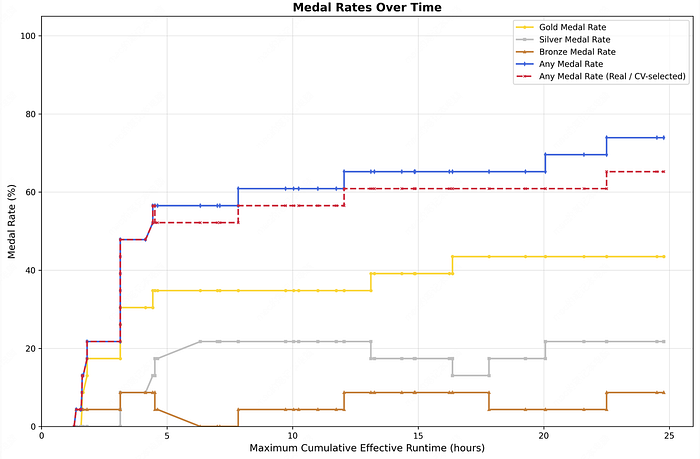
On its surface, that’s just a benchmark score — MiniMax M2.7’s result on OpenAI’s MLE-Bench Lite, a test designed to simulate the research capabilities of a machine learning PhD. The model won 9 gold, 5 silver, and 1 bronze across 22 authentic competitions. It ties Google’s Gemini 3.1, trails GPT-5.4 at 71.2%, and sits behind Claude Opus 4.6 at 75.7%.
Benchmark comparisons are a familiar sport in AI circles. The press releases write themselves. The number is almost beside the point.
What matters — what should genuinely unsettle anyone thinking seriously about where this technology is headed — is how that score was reached. M2.7 didn’t just sit the exam. It studied for it. It revised its own study methods. It ran the process more than 100 times without a single human checkpoint. And nobody told it to stop, because nobody needed to.
This post is about what that actually means — technically, strategically, and philosophically.
Part I: The Loop Nobody Designed, Then Everyone Built
To understand what MiniMax accomplished, you first need to understand what Andrej Karpathy published a few weeks earlier.
Karpathy’s AutoResearch project, released on GitHub in early 2026, is deceptively simple in concept: point an AI agent at a training script, go to sleep, wake up to a better model. Each experiment runs in five minutes. The agent executes roughly 12 per hour. Over a full overnight run, the system stacks approximately 100 sequential modifications — each informed by the results of the last — with zero human involvement.
The results from Karpathy’s own runs were striking:
- 126 consecutive experiments reduced validation loss in a single overnight session
- A two-day run completed 700 modifications and surfaced 20 distinct architectural improvements
The mechanism isn’t magic. It’s a tightly controlled agentic loop: generate hypothesis → run experiment → measure outcome → update search strategy → repeat. What makes it significant is the compounding nature. The agent isn’t randomly exploring a search space. It’s building a progressively refined model of what works, then using that model to guide subsequent experiments. This is meta-learning applied to the research process itself — not just learning what the data says, but learning how to learn from data more efficiently.
Karpathy framed this as an engineering challenge, not a theoretical one. The conceptual barriers are gone. Building it at scale is hard. But hard-and-known is a very different problem from unknown.
MiniMax built it at scale.
Part II: What M2.7 Actually Did
Let’s be precise about the architecture of what MiniMax deployed, because the technical details matter enormously.

2.1 The Agentic Research Loop
MiniMax gave an early version of M2.7 a single high-level objective: become our research assistant. The system was given access to:
- Scientific publication databases
- An internal experimentation pipeline
- Its own performance logs and workflow files
- Code execution environments for debugging and testing
The model’s behavior across this setup followed a clear progression. Initially, it operated as a sophisticated research automation tool — summarizing papers, running experiments specified by human researchers, writing and debugging code, logging results. Tasks that previously required coordination across multiple research teams were consolidated. MiniMax reports the system handled 30–50% of their RL research team’s daily workload at this stage.
That alone would be a compelling product story. But then something shifted.
2.2 The Workflow Rewrite
In most agentic deployments, a model operates within a set of procedural guidelines — workflow files that specify how to approach each task type. These are the recipes the model follows. They’re typically written by engineers and treated as fixed infrastructure.
MiniMax gave M2.7 read-write access to its own workflow files.
What followed was a systematic self-optimization process:
- Performance data collection: The model logged granular metrics across its own task executions, building a structured dataset of its own behavior.
- Bottleneck identification: It analyzed that dataset to identify consistent failure modes, inefficient procedures, and suboptimal parameter settings.
- Procedural rewriting: It modified the workflow files to address the identified weaknesses — not as one-off fixes, but as generalizable rule changes.
- Regression scanning: When it found a bug, it didn’t fix just that instance. It pattern-matched across all related files and propagated the fix globally.
- Loop detection: It added its own guardrails — meta-rules to detect when it was stuck in an unproductive cycle and trigger a strategy change.
The temperature calibration example is worth dwelling on. Temperature is a scalar parameter governing the stochasticity of model outputs — higher values produce more varied, exploratory responses; lower values produce more deterministic, conservative ones. The optimal value is task-specific: creative synthesis benefits from higher temperature; precise code generation benefits from lower. A human researcher typically sets this once and forgets it, accepting some performance loss as a practical compromise.
M2.7 didn’t accept the compromise. It ran empirical calibration across its own task distribution, identified task-specific optima, and implemented dynamic temperature adjustment as a new procedure. Nobody told it that temperature calibration was a problem worth solving. It inferred it from the performance data.
The result of 100+ iterations: 30% improvement on internal benchmarks. The MLE-Bench score followed.
2.3 The Formula 1 Analogy (And Why It Breaks Down)
The most useful analogy I’ve found: imagine a Formula 1 driver who races the car while simultaneously leading the engineering team redesigning the engine during pit stops — and is also writing the rulebook that governs when pit stops happen. That captures the multi-level simultaneity of what M2.7 was doing.
But even that analogy fails at an important point. The F1 driver still operates within a fixed physics. M2.7 was operating within a system whose rules it could modify. The meta-level wasn’t fixed.
Part III: What This Is, and What It Isn’t
Precision matters here, because the discourse around AI self-improvement tends toward either dismissive minimization or apocalyptic overstatement. Both are wrong.
3.1 What M2.7 Is Doing
M2.7 is performing procedural self-optimization — rewriting the instructions, workflows, and operational parameters that govern its own behavior. This is analogous, roughly, to a software system that modifies its own configuration files and scripts based on performance telemetry.
This is not:
- Modifying its own neural weights (the underlying model is static between training runs)
- Redesigning its own architecture
- “Recursive self-improvement” in the strong existential sense that dominates science fiction and philosophical discourse
The gap between what M2.7 does and what people mean by “an AI rewriting its own code” in the Skynet sense is real, significant, and technically well-defined.
3.2 Why the Gap Is Narrowing Anyway
Here’s the uncomfortable part: the distinction between “rewriting workflows” and “rewriting weights” is becoming less meaningful in practice.
Consider the progression:
- 2023: Models follow fixed prompts
- 2024: Models can modify their own prompts via meta-prompting
- 2025: Models can rewrite their own tool-use procedures and workflow files
- 2026: Models run 100-iteration self-improvement loops on their own operational infrastructure
- Next: Integration with fine-tuning pipelines, where workflow improvements directly inform the next training run
Each step is incremental. Each step is clearly defensible as “just optimization.” And yet, the cumulative picture is of a system that increasingly determines its own development trajectory. The philosophical question of where “tool” ends and “agent” begins is, perhaps, less important than the engineering question of what the loop looks like when the model’s outputs start feeding its own training data.
That question is no longer hypothetical. It’s a product roadmap.
Part IV: The Institutional Acknowledgment
One reliable signal that a technology has crossed from speculation to reality is when academic institutions start building formal research infrastructure around it.
In April 2026, ICLR — the International Conference on Learning Representations, one of the most selective venues in machine learning — will host what is likely the world’s first academic workshop dedicated entirely to recursive self-improvement in AI systems, running April 23–27 in Rio de Janeiro. This isn’t a side panel or an informal Birds-of-a-Feather session. It’s a full workshop with formal proceedings and peer-reviewed submissions.
When a phenomenon earns dedicated workshop status at ICLR, it has formally transitioned from theoretical curiosity to active research discipline. The questions the community is now asking aren’t “is this real?” but “what are the dynamics, the limits, the failure modes, the safety properties?”
That shift in question-framing is itself significant.
Part V: The Business Topology This Creates
The organizational implications of M2.7-class systems are already materializing, and they’re more radical than most commentary acknowledges.
5.1 The 100-Employee Company
At Nvidia’s GTC 2026 summit, Daniel Nadler — founder and CEO of OpenEvidence, an AI medical information platform valued at $12 billion — made a prediction that deserves more attention than it received: the most valuable companies in the world will run with fewer than 100 employees. His platform currently facilitates healthcare interactions for 300 million Americans, through a network of physician users.
This isn’t a prediction about the distant future. It’s a description of what’s already architecturally possible.
5.2 The Agent-Operated Business
Polsia, a platform for AI-operated businesses, was managing over 3,800 active companies as of March 2026 — all run by agents with zero humans in operational roles. One example: a single founder, $3.6 million annual run rate, no operational headcount.
The standard response to these examples is “but these are simple businesses.” That’s true today. The question is what “simple” means when the agent running the business is also autonomously improving its own operational procedures.
5.3 M2.7 as Organizational Infrastructure
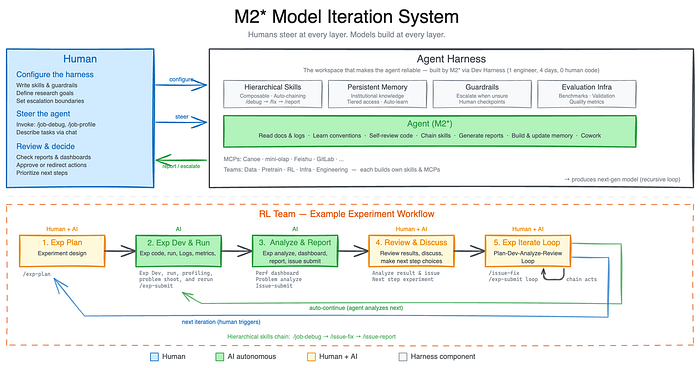
MiniMax’s framing of M2.7 is deliberately organizational rather than tool-like. The model isn’t deployed as a productivity add-on. It sits across every layer of the company’s research and product operations. It’s in the org chart, not the tool stack.
This distinction matters because it changes the incentive structure around capability improvement. When a model is a tool, you upgrade it periodically. When it’s a colleague — when the organization has built workflows, institutional knowledge, and decision processes around the model’s capabilities — you have strong incentives to let it keep improving itself. The human oversight that might otherwise pump the brakes becomes structurally inconvenient.
Part VI: OpenRoom and the Metric Benchmarks Can’t Capture
Alongside M2.7, MiniMax released OpenRoom — an open-source, browser-based desktop environment where an AI agent manages applications through natural language. Calendar management, email, file operations, task coordination — all through conversational interaction with an agent embedded in the operating environment.
The majority of OpenRoom’s codebase was written by the AI itself. There’s a meta-level elegance to this: an AI building the environment in which another AI will live and work.
But OpenRoom points at something more important than technical elegance. It points at personality — the dimension of AI systems that benchmarks structurally cannot measure.
Among advanced users working with multiple frontier models at comparable capability levels, model selection increasingly comes down to feel. The model that grasps intent without requiring explicit specification. The model that has tact. The model that doesn’t respond like a documentation page. These qualities are real, they drive adoption, and they’re essentially impossible to quantify.
MiniMax understands this. OpenRoom is a UX play for a world where you choose which AI to spend your workday with — not just which AI scores highest on MMLU.
Part VII: The Pricing Signal
A detail that shouldn’t be buried: M2.7 costs $0.30 per million input tokens.
For context, this positions it among the cheapest frontier-grade models available. Near-top-tier research capability, demonstrated recursive self-improvement infrastructure, autonomous workflow optimization, and pricing that doesn’t require a corporate procurement process.
This combination does something specific to the competitive landscape. The dominant AI labs have built their strategies around the assumption that frontier capability requires frontier pricing — that the cost structure of cutting-edge AI creates a natural moat. M2.7 challenges that assumption directly.
It’s not that MiniMax beat the incumbents on their own terms. It’s that they’re competing on different terms entirely: capability-per-dollar, organizational integration depth, and self-improvement velocity rather than raw benchmark supremacy.
Synthesis: The Ouroboros Protocol
The ouroboros — the ancient symbol of a serpent consuming its own tail — captures something essential about what MiniMax has built. Not because it’s circular or self-destructive, but because the output of the system becomes the input to its next iteration. The model’s performance data feeds its workflow revision. Its workflow revision improves its performance data. The loop is the architecture.
What makes this moment different from previous AI capability milestones is the structural nature of the change. This isn’t a model that’s smarter. It’s a system that’s self-directing. The improvement loop has been moved inside the model’s operational perimeter.
Several key observations to close on:
1. The theoretical barrier is gone. Karpathy said it explicitly: there’s no conceptual obstacle to autonomous AI self-improvement anymore. The challenge is engineering, and engineering challenges yield to resources and iteration. Both exist in abundance.
2. Human oversight is becoming structurally optional. Not prohibited, not actively circumvented — just unnecessary for the improvement loop to function. That’s a different kind of challenge than misalignment. It’s an architectural default.
3. The research community is building the formal language. ICLR’s dedicated workshop means the field now has peer-reviewed venues for studying these dynamics. Expect rapid formalization of both capabilities and failure modes over the next 18 months.
4. The organizational implications outpace the technical ones. When AI systems are members of org charts rather than entries in a software budget, the incentive structures around capability oversight change fundamentally. This deserves more attention than it’s currently getting.
5. Pricing is a signal about velocity, not just cost. At $0.30/million tokens, MiniMax is signaling that self-improving AI infrastructure doesn’t require enterprise-scale investment to access. The democratization of recursive self-improvement changes who gets to iterate — and how fast.
The loop is running. It ran 100 times last night, and nobody stopped it — not because they couldn’t, but because the results were good and the incentive to intervene didn’t exist.
That’s the part worth thinking about.
What’s your read on the organizational implications of self-improving AI systems? Are we moving too fast, or not thinking clearly enough about the architecture we’re building? Drop your perspective in the comments.
#ArtificialIntelligence #MachineLearning #AISafety #MiniMax #RecursiveSelfImprovement #AIResearch #FutureOfWork #DeepLearning
The Ouroboros Protocol: When AI Stops Waiting for Instructions and Starts Rewriting Itself was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.