Six weeks ago I cut every research query down to two variables. Here is what the narrower question surfaced — and what it has sold since.
In early April I sat down to work, late, the way I prefer. Before opening the laptop I did what I always do — closed my eyes for fifteen minutes and walked through the problem in my head. Which categories I wanted to look at. Which brands. What I expected to find. By the time I opened NotebookLM the question was already formed.
Two brands — Logitech and Razer. Three categories — webcams, mice, and headphones. Ten or fifteen models I wanted ranked by profitability for the consumer side of my UK business. The kind of question that sounds smart when you ask it. The sources were loaded, the brief was generic, the answer came back inside half a minute.
It was the same answer I had received the last three times I asked something like it. A polite list of top-selling products, dressed up as analysis, weighted toward the obvious winners. The Logitech MX Master series in the mouse category. The Razer DeathAdder right beside it. The same products that show up on every marketplace bestsellers list, presented as though the tool had reasoned its way to them.
I closed the notebook. I had been doing this wrong for months. The problem was not NotebookLM. The problem was the question.
Why broad queries fail in this category of tool
NotebookLM is a data-analysis layer. It is not a decision-making layer. When you give it a corpus and ask it a narrow question, it does what it is built to do — it reads the sources, surfaces the patterns, presents what is in front of it. The output is grounded, citable, accurate to what is on the page.
When you give it a corpus and ask it a broad question, something else happens. Every additional variable you add forces the tool to find a point where all of them agree. Two brands. Three categories. A profitability filter. The tool has to find the answer that satisfies all of them simultaneously — and the only point that satisfies all of them is whatever the market has already validated. The top-selling product in each category, from each brand. The MX Master series. The DeathAdder. The webcam everyone owns. The headphones every reviewer ranks first.
These were the products NotebookLM kept giving me. Not because they were the right answer. Because they were the only answer the broad question allowed. Add a fourth variable — a price band, say — and the tool drifts to the most popular product inside that band. Broad questions surface popular products. There is no other answer the tool can give you, because there is no other point where every variable agrees at once.
Variables compound. Two brands times three categories sounds like more coverage. It is actually less signal. More variables do not add information — they shrink the answer space, because the tool must find a single point where every constraint agrees at once, and the only such point is whatever is most popular. The tool retreats to consensus because consensus is the only place every variable can land.
That was happening to me for months. I thought I was asking sophisticated questions. I was actually asking the tool to do something it cannot do — reason across enough dimensions to find the non-obvious answer.
What I already knew but had not connected to the workflow
I have written before about the gap between hot products and profitable products. A flagship gaming mouse with twenty thousand reviews on Amazon is not the unit that pays my rent. The unit that pays my rent is the mid-tier version of that mouse, the one the brand sells to professionals who care about a specific feature, the one that ships in lower volume but at a higher margin per piece.
That is a basic principle of the supplier-side business I run. After twenty years on the Shenzhen end of consumer electronics, I have seen the same pattern across categories. Hot products attract competition. Competition compresses margin. The brands then quietly release a professional-tier or wired-tier variant that sells less but earns more, and most resellers never pick it up because it does not show up in the same searches the hot products do.
I knew this. I had written about it. And yet when I sat down to use NotebookLM to find these products, I was asking the broad question — give me a comparison across brands and categories — that guarantees the tool will skip past exactly the products I wanted.
The disconnect was uncomfortable to notice. It is also what happens when you adopt a new tool and try to use it the way you used the old tools. The shape of the question has to change.
The decision to microscope
That same Sunday afternoon I made a decision. No more broad queries. No more two-brand, three-category sweeps. From that point forward every research session would be tightly bounded — one brand, one category, one product class at a time.
One brand. Logitech. One category. Mice. That was it. The whole research session would orbit two variables instead of six.
It sounds restrictive. In practice it is liberating, because once the variable space is small enough, NotebookLM has room to actually surface the second-tier and third-tier products that broad queries always crush. The professional mid-tier, the wired version that the wireless flagship overshadows, the older revision that still sells steadily — these only appear in the output when the question is narrow enough that there is no top-selling answer to retreat to.
The drift toward consensus is proportional to how much space the question gives it. Take the space away and the drift disappears.
Building the corpus, one link at a time
The next step was the corpus. I had been lazy about this for months — uploading whatever PDFs and pricing exports I had on hand, treating the corpus as a side concern. For the microscoped query I built it differently.
I went to price-comparison sites. I pulled up the full Logitech mouse range, model by model, and added each product page as a source link. Not aggregated PDFs. Not bulk exports. Individual product pages, one per source slot, each carrying its own pricing, its own review snippet, its own positioning in the brand’s lineup. By the time I was done the notebook had ten sources, each a single product, each with its own context.
The point of doing it this way is granularity. When the corpus is ten individual product pages instead of one aggregated PDF, the tool can compare them as discrete entities. It can notice that model A and model B share a feature but differ in price, that model C is the wired version of the wireless flagship, that model D is older but has not been discontinued. The structure of the data shapes the structure of the analysis. Aggregated PDFs flatten this. Individual product pages preserve it.
This took longer than dumping a single PDF. Maybe forty minutes instead of five. The time is worth it. Every later question lands on better ground.
Adding the dissenting voices
The corpus was not done after the ten product pages. I added three more sources — three products that had drawn negative reviews. Two of them I knew from my own catalogue history had underperformed. One I had been considering and was uncertain about.
Most people skip this part of corpus building. The instinct, when you are researching what to source, is to load up positive signals and ask which to pick. The result is a corpus that only contains arguments in favour. The tool, working from sources, finds reasons to commit to everything. There is no friction in the corpus, so there is no friction in the output.
Adding products with negative reviews changes the shape of the analysis. The tool now has to weigh contradicting signals from comparable products. It can no longer simply tell me which products are popular — it has to tell me which products are popular and hold up under scrutiny, because the negative-review sources are forcing it to consider the scrutiny dimension.
Three dissenting sources out of thirteen total. About a quarter of the corpus. Enough to create friction in the output, not so much that the friction dominates.
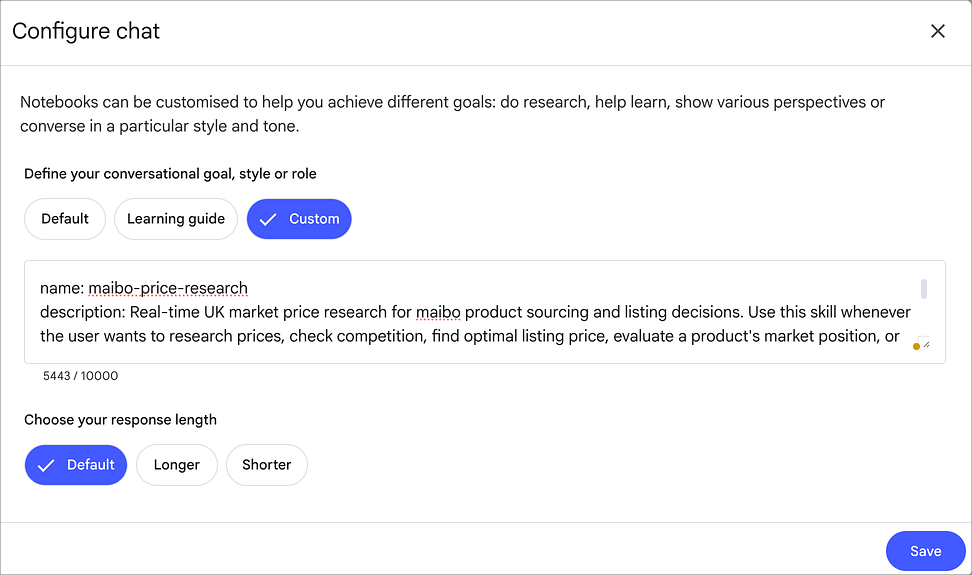
The custom brief
The last layer was the brief. I clicked Configure Notebook, selected Custom, and wrote a tight instruction set. The brief reflected the same Claude skill I use for price research, but stripped down to the microscoped scope — Logitech mice only, UK market context, mid-tier and wired segments prioritised over flagship, profitability over volume.
The skill I normally run in Claude is broader. It can handle multi-brand, multi-category scans because Claude is doing instruction-following — it will hold the conditional logic across many variables and apply the rules consistently. NotebookLM cannot do that. So the brief I gave NotebookLM was the same skill, micro-scaled — narrower in scope, fewer branching conditions, more aligned with what NotebookLM is actually good at.
Most users never reach this layer, because the Customise field looks optional. It is the layer where the tool stops guessing what you want and starts working inside the rules you have written. Without the brief the tool answers from default assumptions. With the brief the tool answers within the constraints you have defined, against the sources you have curated, in the format you have requested. The same notebook, the same sources, the same question — completely different output.
What the microscoped query produced
The microscoped query produced two Logitech mice and a handful of Razer wired peripherals. Each one now sells 45 to 50 units a month at £20 to £30 — quiet, profitable, invisible to anyone asking the broader question.
Two mice from the Logitech mid-tier range. Wired Razer peripherals at the £20 to £30 price band. None of them were the top-selling models I would have found on any marketplace bestsellers list. None of them were the products NotebookLM had been surfacing in my broad queries for months.
I added them to my catalogue in April. Six weeks in, both Logitech mice are doing 45 to 50 units a month each. The Razer wired peripherals are tracking at similar volume. Each unit at £20 to £30, with margins that work because the flagship competition is not crushing the price band and because my supplier relationships put me below resellers who do not have twenty years of Shenzhen sourcing behind them.
The volume is not flagship. Forty-five units a month is not what the hot products do. But every unit is profitable, and the bigger sellers — the ones every other reseller is fighting over — are not looking at these models. The competitive density is low because the broad query that everyone else is running never surfaces them.
Quiet, profitable, invisible — that is what those words mean here. Visible to the microscoped query. Invisible to the broad one. The difference is not what the tool can do. The difference is the question.
What I take from the experiment
The bottleneck was never the tool. It was always the question I was asking it. A tool with strong source-grounding and weak conditional reasoning will reward narrow questions and punish broad ones, and the entire game is to recognise this and adjust.
I now run NotebookLM in one mode only. One brand, one category, ten to fifteen individual product sources, three dissenting sources, custom brief tied to the same skill I use in Claude but micro-scaled to NotebookLM’s strengths. The output goes from NotebookLM to Cowork, where I can re-validate against live browser data before committing to anything. NotebookLM reads what is in the corpus. Cowork checks the corpus against the live market. Neither tool gets asked to do the other one’s job.
The hot product is not the profitable product. NotebookLM cannot tell you which is which when you ask it broadly. It can only tell you when you ask narrowly enough that the profitable middle-tier has room to appear.
What to do today
Open the last research notebook you built. Look at the question you asked. Count the variables. If there is more than one brand, more than one category, more than one price band — the question is doing the work you should be doing yourself.
Cut it down to two variables. One brand, one category. Rebuild the corpus from individual product pages instead of aggregated exports. Add three sources that contradict the rest. Write a one-paragraph custom brief. Ask the same question again.
The first product that surfaces will not be the obvious bestseller. Look at the one sitting next to it. That is usually the one worth your attention.
I source consumer electronics from Shenzhen and run a UK e-commerce operation. Twenty years on the supply side. This is the third article in a series on the research workflow I now use — the first piece, on the full system, is The Five-Step Research System That Has Changed How I Make Decisions, and the second, on the Customise function, is Most People Use NotebookLM Like a Search Engine. Here’s What They’re Missing. This article focuses on what happens after the tool is set up — the question itself.
The Day I Stopped Asking NotebookLM Broad Questions was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.