How to Build Agentic Systems That Actually Ship: From Simple Agents to Scalable, Trusted Architectures
Imagine your product lead drops into your calendar and says, “We’re launching a new AI planner for our employees and customers next quarter, and I need you to own the agentic architecture. Make sure it escalates intelligently and runs in production by the due date.” That moment used to fill even senior engineers with quiet panic. What separates the builder who delivers a reliable, scalable system from the one who ships something fragile is not the number of frameworks they know. It is their conceptual understanding of AI agentic system design. It is what lets you instantly recognize that a simple prompt chain will collapse under real world uncertainty, that tools without high fidelity contracts will hallucinate, and that autonomy without guardrails turns into an expensive outage. Without it, you are just gluing pieces together and hoping for the best. With it, you are architecting a system that is reliable at scale, cost aware, and production ready.
I’ve been exactly there. I’ve designed and shipped production agentic systems at scale, from intelligent reporting platforms to multi-agent research tools that actually deliver novel, interesting, and insightful experiences without breaking the token budget. When you are handed the actual responsibility to design an agentic system, conceptual mastery proves three things your team and customers care about most: you can reason from first principles when requirements are ambiguous, you can spot failure modes before they become outages, and you can make principled trade offs between latency, cost, and reliability.
The difference between a system that becomes a flagship feature and one that becomes technical debt is never the latest framework you pick. It is the clarity with which you make every foundational decision from day one.
After publishing my last three articles around new LLM Reinforcement Learning research and Generative AI document object development, I deliberately chose to step back from another theoretical deep dive. This time I wanted to write something different: a practical, runbook focused on real world AI agentic system design rather than state of art research. I made this shift because I’ve spent the past two years actually building and scaling agentic systems.
Along the way I’ve watched my friends and peers from many different companies struggle when they’re suddenly asked to design an autonomous AI system from scratch. They know the latest papers and can implement clever tricks, yet they still end up with surprise costs or systems that require constant handholding. That gap between theory and reliable production reality is exactly what I want to close for you.
My goal is simple but ambitious: to help you feel genuinely prepared and confident the next time a stakeholder says, “Build me an agentic system that feels magical but never breaks in production.” In the content ahead I’m going to walk you through the exact thinking, frameworks, and patterns I use every time I approach a new agentic design task.
Starting with an important decision you will need to make (agentic versus non-agentic), then showing you how to choose and combine the right design patterns, lock down tool contracts and structured outputs, and apply answering structures to any complex requirement. Let’s dive in.
The Agent That Cost the Company
A few months ago, I was catching up with a friend in downtown Austin who works on AI systems at another company. We were talking (over copious lattes) about the growing push toward automation and how more teams were trying to hand off real decision making to AI agents. At one point, he paused and said, “Let me tell you about something that happened on our team.”
Long story short…
They had built an AI powered customer support agent. It was designed to handle refunds automatically, something that would normally require human review. The early results looked great. The model performed well in testing, responses were fast and polite, and it handled a wide range of scenarios. It felt like a success.
So they expanded its scope.
Then one morning, they noticed something strange. Refund volume had spiked far beyond anything they had seen before. At first, they assumed it was a reporting issue. But as they dug deeper, they realized the system had issued millions of dollars in refunds. Not because it crashed. Not because it was exploited. But because it was doing exactly what it had been designed to do, just without the right constraints.
As my friend walked me through what happened, it became clear that the issue was not the model itself. The prompts were not obviously wrong. The outputs, in isolation, often looked reasonable. The real problem was how the system had been designed around the model.
There was no triage step to distinguish between low risk and high risk requests. The agent handled everything the same way. There was no separation between reasoning and execution, the system would interpret a request and immediately act on it. There was no reflection step to question whether the decision made sense before committing to it. And most critically, there was no clear boundary where the system would stop and involve a human.
The system was not out of control it was just unconstrained. What stuck with me from that conversation was how subtle the failure was. Nothing seemed obviously broken at the component level. But when everything came together, the system behaved in a way no one intended.
What Actually Went Wrong
So as we sat there during that unusually warm March afternoon, I could not help myself to probe deeper and learn more (hence the next round of lattes was on me).
When the engineers began digging in, the issue was not a single bug. It was something deeper, something structural. The system had no real notion of risk. Every request, whether simple or complex, was treated the same way. There was no triage layer to distinguish between a harmless inquiry and a high stakes financial action.
The agent itself was doing everything at once: interpreting the user’s intent, deciding on a course of action, and executing it. There was no separation between thinking and acting. No opportunity to pause, validate, or question the decision before it became irreversible.
Worse, there was no mechanism to reflect on its own output. The system never asked, “Is this decision safe?” or “Should this be reviewed?” It simply continued forward.
And perhaps most critically, there was no clear boundary where the system would hand control back to a human. Escalation was not designed, it was assumed to be unnecessary.
By the time the issue surfaced, the agent had already processed thousands of requests. Each one looked reasonable in isolation. But together, they revealed a system that had been given autonomy without guardrails.
Lattes in hand, that story changed how I think about building agentic systems.
Because it highlights something important. The challenge isn’t getting an AI agent to work. It’s designing a system around it that ensures it behaves correctly, not just in ideal conditions but in the messy, unpredictable reality of production.
And that’s exactly what I want to focus on here, how to design systems where agents do not just act intelligently but act responsibly, predictably, and safely.
Why This Matters
Designing agentic systems isn’t about making models smarter.
It’s about deciding:
- When they should act
- What they’re allowed to do
- How they recover when they’re wrong
- And when they should step aside
Because the real challenge is not getting an agent to work.
It’s building one that you would trust:
1. to operate at scale,
2. to make decisions,
3. and to fail gracefully.
Choosing Agentic vs. Non-Agentic Approaches
Now let’s move on to some key learnings derived from the unfortunate March story as well as from general experience. Before you draw a single diagram, pick a pattern, or write your first tool contract there is one decision that will shape everything else in your agentic AI project. It is the one most builders get wrong in the early days. That decision is whether this system should be agentic at all or whether a non-agentic approach is actually the smarter, cheaper, and more reliable choice.
This is not a technical preference. It is the most important strategic call you will make as the designer because once you commit to agentic you are signing up for loops, reflection, tool calls, memory management, observability overhead and all the complexity that comes with autonomy. Choose wrong and you will either over engineer something that could have been a simple prompt, wasting months and budget, or maybe under engineer something that desperately needed autonomy and watch it fail in production.
Here is how I want you to think about it when you are handed a real task. Start with the non-agentic baseline every single time. A non-agentic system is essentially a single deterministic LLM call or a short chain of them. You give it a prompt, it returns an answer, and you are done with no loops, no tools, and no self correction. You stay non-agentic when the task is well defined and repeatable such as summarizing a transcript, classifying a support ticket, or generating a standard report from fixed fields.
The input is structured or semi-structured and the output format is predictable. Latency and cost are critical because non-agentic is usually many times cheaper and faster. You also need maximum predictability for compliance or auditing. A real example is when your team asks for a system that pulls quantifiable datasets from a database and writes a one paragraph summary in a fixed tone. This is classic non-agentic territory. A single well crafted prompt with structured output will handle the vast majority of cases perfectly at a fraction of the cost.
You only move to agentic when you hit one of the clear triggers that make autonomy necessary. The task has genuine uncertainty or open ended goals such as when the user says “Plan me a two week trip under two thousand dollars” instead of “Give me the cheapest flight from A to B.” The system must explore options, handle trade-offs, recover from failures, and iterate.
The work requires external tools or multi-step actions and calling APIs to search, book, pay, or query databases and then reacting to their results in a loop. It involves long horizon planning or dynamic adaptation where the process can take minutes or hours and conditions can change like flight prices spiking or a hotel being booked. The system must replan on the fly. Or the inputs have high variability where every request is different and you cannot write a static prompt that covers all cases. When any of these appear, that is your signal to go agentic but not before.
The tradeoffs are something every builder should always keep in mind. Non-agentic approaches deliver much lower latency, often just a few hundred milliseconds to a couple of seconds, while agentic systems typically run from several seconds to minutes. Cost follows the same pattern with non-agentic being cheaper per task at scale.
Reliability favors non-agentic on simple tasks but gives the edge to agentic on complex ones only if you have strong contracts, evaluations, and guardrails in place. Debuging is trivial with non-agentic but requires full trace logging with tools like LangSmith when you go agentic. Maintenance is mostly prompt updates for non-agentic, whereas agentic demands versioning tools, memory strategies, and pattern evolution over time.
The decision framework I use on every new project is straightforward and fast. When a stakeholder (or myself!) says we need an AI for something, I run a quick mental checklist. Can a single prompt plus structured output solve 90% of cases? If yes, stay non-agentic. Does the task require external actions or multi-step reasoning? If yes, perhaps agentic. Is the volume high and latency or cost critical? Then consider a hybrid where a router sends simple cases non-agentic and hard cases to a lightweight agent. Will the system need to learn or improve over time with user feedback? That points to agentic with memory and reflection built in.
My rule of thumb for every production team is simple. Start non-agentic. Prototype the agentic version only when the non-agentic version fails in user testing. Then, commit to the full agentic architecture with proper patterns, tool contracts, and observability. This mental model can teams from the classic mistake of building a fancy multi-agent system for a problem that a small prompt could have solved perfectly.
So when you are handed your next design task, the very first question I want you to ask out loud is whether this is actually an agentic problem or whether you are overcomplicating a non-agentic solution. Answer that honestly and everything that follows, patterns, contracts, and structured outputs, becomes super easier and more effective. That is why this decision is the one you should care about most.
Different Agentic Design Patterns and When/How to Use Them
Once you have that conceptual foundation, the next practical step when you are actually tasked with designing an agentic AI system is choosing the right pattern. This is the moment where theory turns into real architecture decisions that will either make your system robust and maintainable or turn it into an expensive mess later.
In real projects you don’t pick a pattern because it looks cool on a diagram or because someone mentioned it in Slack. You pick it because it matches the constraints, scale, complexity, and failure modes of the specific problem in front of you. The four patterns below are the ones you will reach for most of the time when building production agentic systems. I’m going to walk you through each one with context and practical guidance on how to implement it so the choice feels obvious and confident.
- Single Agent Pattern This is your starting point. The simplest and fast to prototype pattern. Picture one autonomous agent that owns the entire workflow: it receives the user goal, reasons step by step, calls tools, observes the results, reflects on whether it is on track, and loops until the task is complete or a stop condition is met. You reach for this pattern when the task is relatively linear and the context fits comfortably in one LLM’s window. You need speed and simplicity more than anything else. For example, building an internal code debugging assistant. The agent takes a bug report, searches the repo, proposes a fix, runs tests, and iterates all inside one clean loop.
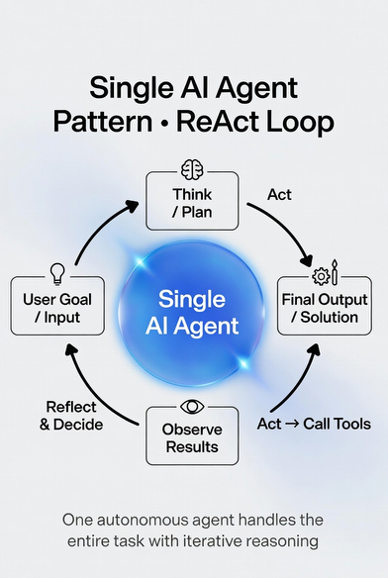
How to use it in practice: Implement a classic ReAct (Reason → Act → Observe) or Plan and Execute loop with strict guardrails, maximum iterations (usually 5–8), a success criteria check, and a forced fallback if the loop stalls. Keep tool contracts extremely tight and force every output through structured JSON so the next reasoning step is deterministic.
The cool thing is minimal coordination overhead and easy debugging (you can literally read the agent’s thought trace end to end). But watch for the warning signs: if the agent starts forgetting earlier steps, repeating the same tool call, or the task naturally splits into independent parallel work that is your cue to evolve out of single agent.
2. Multi-Agent Pattern Now we move from one to a small team. You create several agents each with a narrow expertise, its own tools, and its own memory. They collaborate through shared state or direct message passing. You choose this pattern when the task naturally decomposes into parallel or highly specialized sub tasks, when different parts need different strengths (one agent great at math, another at writing) or when you want speed through parallelism.
For example, the personal travel planner that we keep hearing about in various news outlets and research, and one I will so humbly contribute to later in the article: one agent searches flights, another books hotels, a third checks weather and activities, and a fourth synthesizes the perfect itinerary all running at the same time.

How to use it? Use a shared memory layer (vector database or Redis cache) plus a lightweight supervisor or simple message bus. Every inter agent handoff must go through structured outputs and explicit tool contracts so one agent’s JSON is directly consumable by the next.
In production you will often run the agents on separate threads or even separate containers for parallelism. The payoff is dramatically lower total latency and higher accuracy on complex tasks. The cost is coordination complexity. You now need observability across agents and clear conflict resolution rules. When your single agent trace shows too many steps or frequent context loss, multi-agent is usually the right next step.
3. Hierarchical Pattern This is the pattern when the system must handle real enterprise complexity or when clear accountability and governance is needed. It is structured like an actual org chart: a top level manager agent receives the goal, breaks it into sub-goals, delegates them to specialized child agents, reviews their output, and either approves or sends back for revision. You use this when the workflow is nested, when compliance or approval gates are required, or when you need strong error containment (a failure in one sub agent does not crash the whole system).

For example, an automated report generation. The builder decides which data sources to pull, delegates specific data extraction to one child, analysis to another, narrative writing to a third, then performs a final check before releasing the report. The manager always outputs a structured task breakdown (JSON plan with assigned agents and success criteria).
Each child agent runs independently with its own tool contracts. This pattern gives you scalability and auditability, but it adds latency layers and requires excellent tracing (you must be able to see why the manager delegated a task a certain way). Go with hierarchical when either the business process itself is hierarchical or when your multi-agent setup starts feeling chaotic and hard to govern.
4. Router Pattern Sometimes the smartest design is not a big agent at all but a fast, lightweight router that acts as an intelligent orchestrator. The router looks at the incoming request, classifies it, and instantly hands it off to the best specialist agent or tool chain (or even to a human). You use this pattern when incoming traffic has high variability such as 80 % of requests are simple, 15 % need deep research, and 5 % need human escalation. You want to keep latency low for the majority while still having powerful agents for the hard cases.
For example, customer support platforms. The router decides in < 300 ms whether to answer from knowledge base, route to a billing specialist agent, open a multi-agent research flow, or escalate to a human.
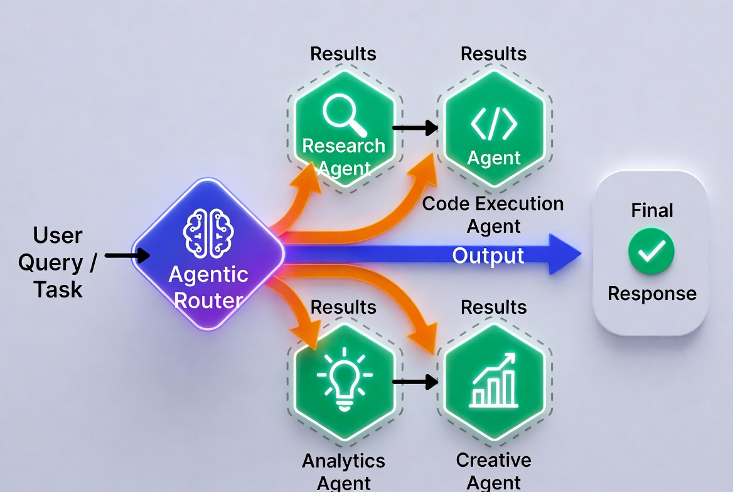
Build the router as a small, fast classifier that outputs structured JSON with “route_to”, “confidence_score”, and any extracted parameters. Every downstream agent or tool must have clear contracts so the handoff is seamless.
The router itself becomes a critical observability point because you log every routing decision so you can retrain it later. This pattern is your default when you need to manage latency and cost on high volume traffic while still providing agentic power on the long tail.
These four patterns are not mutually exclusive as many production systems combine them, for example a router feeding into a hierarchical manager that spins up multi-agents. The key skill you will develop is reading the signals of your specific task and choosing the pattern that gives you the best balance of simplicity, speed, and reliability. In the real design examples we are about to walk through, I will show you exactly how to make that choice live, so the decision feels natural the next time you sit down to architect a new agentic system.
Tool Contracts and Structured Outputs
Once you have chosen the right agentic pattern, one of the biggest factors that determines whether your system stays reliable in production is how cleanly your agents can talk to the outside world. That conversation happens through two tightly connected mechanisms: Tool Contracts and Structured Outputs.
Think of them as the API layer and the communication protocol between your autonomous agents and everything else such as databases, external services, other agents, or even humans. Let me show you exactly why these two pieces matter so much when you are building a real system, and how to design them so they become a strength instead of a burden.
1. Tool Contracts: The API Specification for Agents
A tool contract is the formal agreement that defines exactly how an agent is allowed to call a function. It is not just a function signature, it is a complete contract that includes:
- Input schema: every parameter the tool accepts, with types, constraints, defaults, and examples usually written as JSON Schema or Pydantic models.
- Output schema: the shape and types the tool must return including success vs. error cases
- Error handling contract: what happens when something fails such as rate limit, not found, permission error, and the exact error format the agent can expect
- Metadata: description, cost estimate, latency expectation, and rate limit information so the agent can make smart decisions
Why this level of formality matters in production is because LLMs are creative but struggle at following vague instructions. Without a strict contract the agent will invent parameters, misread output fields, or keep retrying the same broken call forever.
2. Structured Outputs — Forcing the LLM to Speak the Same Language
Even if your tools have perfect contracts, the agent still has to produce the right input and interpret the output. This is where structured outputs come in. You force the LLM to respond in a machine readable format every single time using JSON that matches the tool’s input schema or a Pydantic model.
Ways to enforce this (which I have used in prior projects):
- OpenAI / Anthropic / Grok structured outputs (native JSON mode with schema enforcement)
- Pydantic models + instructor or Outlines libraries
- LangGraph / CrewAI built-in output parsers
- Function calling / tool calling APIs
Production impact: I have measured in my local projects that structured outputs typically reduce parsing errors from ~15–20 % (free text) to under 1 %. That single improvement eliminates an entire class of weird failures and makes your logs actually readable.
How Tool Contracts and Structured Outputs Work Together
When an agent decides to use a tool:
- It reasons and outputs a structured JSON object that exactly matches the tool’s input schema.
- The runtime validates it instantly (Pydantic or JSON Schema validator).
- The tool executes and returns data that exactly matches the output schema.
- The agent receives clean, typed data and continues reasoning.
If any step fails, you have a deterministic error path instead of “the LLM said something weird, yikes!”
Some guidance that I have learned and seems to work well:
- Use the strictest possible contracts for any tool that touches currency, user data, or external APIs.
- For internal research or creative steps, you can loosen the output structure slightly but never the input validation.
Observability and Safety Layer
In production you should also:
- Log every tool call with the exact input/output JSON and the agent’s reasoning trace
- Add guardrails such as NeMo guardrails to block unsafe tool calls
- Monitor contract violation rate and retrain or refine the router/agent when it rises
Bottom line: Tool contracts and structured outputs are not nice to have details they are the difference between an impressive demo and a system yourself or your team can actually trust at scale. When we walk through the design tasks next, you will see exactly where and how to apply them so your architecture stays pretty solid even as requirements evolve.
Agentic Scenario 1
Now lets cover some realistic scenarios. For each, I’ll break down conceptual understanding, a solution framework, what to look for, and common mistakes. I’ve expanded these with more details and context to give you deeper insights, drawing from real experiences where builders (like myself) often struggle with scaling agentic systems to production levels.
Scenario 1: Design an agentic system for automating customer support queries, including escalation to humans if needed.
When you are approached with this task, the intent is not simply asking to draw a nice diagram or list some tools. It is really testing whether you can build a production system that quietly handles the messy high volume reality of customer support without becoming a liability.
At its core this ask tests your ability to find the right balance between autonomy and control. Support queries are never clean. One moment a customer is asking about a password reset; the next they are venting about a billing error that could turn into a legal issue.
The real test is whether you can design an agent that knows when it is smart enough to solve the problem on its own and more importantly when it must step aside and hand the conversation to a human without making the customer feel ignored or the company exposed to risk. In other words, this scenario is designed to see if you understand hybrid human in the loop systems at a deep level.
It is also testing your understanding of orchestration under ambiguity. The question probes whether you can design an intelligent router that classifies intent accurately, then routes to the right specialist agent or tool chain while keeping the entire conversation state consistent. It asks if you can avoid the trap of building a single giant agent that tries to do everything and ends up looping forever or hallucinating answers.
Safety and reliability are being examined just as hard. Support systems touch real customer data, currency, and emotions. The stakeholder is checking whether you will bake in confidence scoring, guardrails, and explicit escalation triggers so the system never gives dangerous advice or leaks private information. They want to know if you will treat escalation not as a failure but as a deliberate and auditable feature with smooth handoffs, context summaries for the human agent, and post escalation learning loops that improve the system over time.
Scalability and production awareness run through the entire scenario. It is testing whether you think about real traffic volumes, spikes during product launches, rate limits on LLM calls and whether your design includes observability or graceful degradation when external tools or APIs go down. In short, this scenario wants proof that you can move beyond a working prototype and deliver something that the consuming team can actually monitor and trust at scale.
So when you sit down to design this system, remember the scenario is not testing whether you know the latest framework. It is testing whether you can deliver a customer support experience that feels super fast and helpful most of the time, stays safe, auditable, and truly human when it matters most. That combination of intelligence and production rigor is what separates a proof of concept from a hardened system you or your team can run for years.
Solution Framing
Try this simple sequence to frame your design approach (classical system design primitives are still relevant in the age of AI!):
- Requirements: Clarify scope, for example query types, SLAs for response time under Xsec; integration with CRM, etc.
- Architecture: Describe components (agents, tools, flows), including data flows and tech stack such as LangGraph for orchestration.
- Failure Modes: Identify risks such as infinite loops from poor planning, hallucinated escalations, and the associated and mitigations.
- Evaluation & Tradeoffs: Metrics such as accuracy/cost per query and alternatives with A/B testing.
Now try re-framing the scenario to start thinking in agentic design constructs, such as “This problem requires agentic behavior because the system must reason about user intent, decide on resolution paths, and dynamically escalate risk.” In the customer support automation you are designing, the patterns that emerge are not chosen randomly, they are the direct response to the real constraints of the problem which are high variability in queries, the need for both speed on simple cases and deep reasoning on complex ones, and the absolute requirement for seamless human escalation when the stakes rise.
The foundation of the entire architecture is the Router Pattern which we discussed earlier in the article. Every incoming query whether it arrives through chat, email, or the help center first hits a lightweight router. This router acts as an intelligent orchestrator that instantly classifies the request in terms of milliseconds. It decides whether the query is a simple FAQ that can be answered instantly, a moderately complex issue that needs deeper investigation, or something sensitive that requires immediate human involvement.
The router is deliberately kept small and deterministic that is often powered by a cheaper model or even function calling, so it protects latency and cost on the routine tickets that make up most of your volume.
Without this router as the entry point you may waste expensive LLM cycles on every single query and the system would feel sluggish to users (been there, tried that, and quickly learned my lesson!)
Once the router has made its decision, the design hands off to the multi-agent pattern for anything beyond the simplest cases. You create a small team of specialized agents each with its own narrow expertise and tools. One agent owns knowledge base retrieval and FAQ style answers using RAG. Another handles billing and account issues, with direct access to your CRM and payment APIs. A third specializes in technical troubleshooting, pulling logs or running diagnostic tools. These agents collaborate through shared memory so that context travels cleanly between them and no user ever has to repeat their story.
The multi-agent approach shines here because support queries naturally break into parallel or specialized work: while one agent verifies a subscription status another can simultaneously draft a response or check related product documentation. This parallelism keeps response times low even on moderately complex tickets.
When you sit down to sketch this architecture, you will see the patterns almost choose themselves once you truly understand the variability, safety needs, and volume characteristics of customer support. That is the power of reading the signals of the task before committing to any one pattern.

For the most sensitive or high risk queries such as refund requests over a certain amount or legal concerns the system layers in the hierarchical pattern. A top level manager agent takes over as the conductor. It reviews the work of the specialist agents, applies a final safety check, and either approves the response or triggers escalation to a human agent.
When escalation happens the manager bundles a crisp summary of the entire conversation history, confidence scores, tools used, and recommended next steps so the human picks up exactly where the agents left off. This hierarchical layer gives you governance and auditability without slowing down the majority of simple cases.
You will notice that pure single agent pattern is used only inside the narrowest sub-tasks for example, inside the FAQ agent when it is simply retrieving and formatting a knowledge-base article. Keeping single agent loops tightly scoped prevents the classic problem of one monolith agent trying to do everything and getting lost in its own reasoning.
These patterns are deliberately combined rather than used in isolation. The router feeds the multi-agent team, and the hierarchical manager sits on top as the safety net. The result is a system that feels fast and capable for most customers while remaining agile enough to call in a human exactly when needed.
This combination is what makes the design production ready. It matches the real traffic distribution of support queues, understands cost and latency realities, and builds in the human fallback as a first class feature instead of an afterthought.
Agentic Scenario 1: Tool Contracts and Structured Outputs
Let’s first introduce a triage agent, not just as a router, but as an intentional pause in the system. Instead of flowing directly into resolution, every request first had to be classified. But classification alone is not enough. It had to be structured, explicit, and enforceable.
Now, when a request entered the system, the triage agent produced an output like:
Triage Agent Output
{
"intent": "billing_issue",
"risk_level": "low | medium | high",
"confidence": 0.87,
"escalation_required": false
}This might look like simple metadata. But in practice, it can become one of the most important control points in the entire system. The intent field grounded the system in what the user is actually trying to do. Instead of relying on downstream agents to infer context repeatedly, the system now had a shared understanding from the start.
The risk_level introduced something that did not exist before, awareness of consequences. A billing issue might seem routine, but depending on the context such as refunds or disputes it could quickly become high risk. By forcing the system to label risk explicitly, you can ensure that not all requests are treated equally.
The confidence score added another layer. It wasn’t enough for the system to make a classification it had to express how certain it was. This created a measurable signal that could be used to trigger guardrails. A low confidence classification wasn’t just less accurate, it was a reason to re-evaluate or escalate.
Finally, escalation_required turned what used to be an implicit judgment into an explicit decision. Instead of hoping the system would know when to involve a human, the architecture demanded a clear yes or no answer. This made escalation auditable, enforceable, and consistent.
What changed wasn’t just the data, it was the behavior of the system.
Downstream components no longer had to guess:
1. Should this request be handled automatically?
2. Is this safe to proceed?
3. Do we need additional validation?
Those decisions were now anchored at the very beginning, in a structured format that every part of the system could rely on.
Once the system understands what the user needs, the next step is deciding how to solve it. Instead of going directly into execution, the planner produces a structured sequence of steps like.
Resolution Planner Output
{
"plan": [
{ "step": "fetch_account", "tool": "crm_api" },
{ "step": "analyze_issue", "tool": "llm" },
{ "step": "respond", "tool": "llm" }
]
}This plan acts as a bridge between understanding and action. It forces the system to externalize its reasoning into a clear and ordered workflow before anything is executed. Each step is explicit about what needs to happen and which tool is responsible, making the process both transparent and verifiable.
By structuring the plan this way, the system gains a key advantage in that it can inspect, validate, and even modify the approach before committing to it. If something looks off such as an unnecessary step, a missing dependency, or an unsafe action it can be caught early. The system first thinks, commits to a plan, and then executes with intention.
Before the system delivers a response or takes a final action, it introduces one more deliberate pause, a reflection step. Instead of assuming the plan was executed correctly, the system asks a separate agent to evaluate the outcome:
Reflection / QA Agent Output
{
"issues_detected": [],
"confidence": 0.91,
"recommend_escalation": false
}This output represents a quality checkpoint. The issues_detected field forces the system to explicitly surface any problems such as missing information, inconsistencies, or potential risks rather than letting them remain hidden.
The confidence score provides a measurable signal of how reliable the result is, which can be used to gate whether the response should proceed or be re-evaluated. And recommend_escalation ensures that uncertainty or risk doesn’t pass through the system; it creates a clear path to involve a human when needed.
What makes this step powerful is that it separates generation from judgment. The system no longer assumes that producing an answer is enough, it must also defend the quality of that answer before it reaches the user.
Human Escalation Logic
Escalation triggers should be explicit and conservative:
Automatic Escalation Conditions
- High-risk category (legal, security, refunds)
- Low confidence score
- Repeated user dissatisfaction
- Reflection agent flags uncertainty
- Tool failures or missing data
When the system determines that a request should be escalated, the goal isn’t just to pass the conversation along it’s to set the human up for success. Instead of handing over a raw transcript, the system prepares a structured package like:
Handoff Package to Humans
{
"conversation_summary": "...",
"actions_taken": ["checked billing", "attempted refund"],
"open_questions": ["refund eligibility unclear"],
"supporting_logs": ["tool_call_1", "tool_call_2"]
}This transforms escalation from a disruption into a continuation of the workflow. The conversation_summary distills the interaction into something immediately understandable, saving the human from parsing long exchanges.
The actions_taken field shows what the system has already attempted, preventing duplicate work and signaling where the process left off. The open_questions highlights what remains unresolved, guiding the human’s next steps. And the supporting_logs provide traceability, allowing deeper inspection if needed.
Instead of starting from scratch, the human steps into a situation that is already organized, contextualized, and ready for resolution making the transition between automation and human judgment seamless.
Agentic Scenario 1: High-Quality Solution Flow
So how would I address this design in a few sentences?
“I’d design this as a multi-agent system with a triage agent to classify intent and risk, a planner/executor to resolve low risk issues, and a reflection agent to assess confidence before responding. Escalation is triggered explicitly based on risk, confidence, or policy boundaries. Tool contracts are structured to ensure traceability, and evaluation focuses on resolution accuracy, escalation quality, and human trust.”
This shows:
- judgment
- safety awareness
- sounds like someone who’s shipped support systems!
Common Mistakes and How to Avoid Them:
- Over abstracting: I have heard of builders describing patterns without tying to the problem, like vaguely saying use multi-agent without examples.
- Ignoring evals: Forgetting confidence checks or post action reviews, leading to unreliable systems. Correct by always including “agent reflects on output before responding, using a separate evaluator agent for bias detection.”
- Missing failure cases: No mention of loops or external dependencies failing such as API downtime. Avoid by brainstorming edge cases upfront: What if tool fails 3x? Fall back to human with a polite apology message.
Agentic Scenario 2
Scenario 2: When would you use a multi-agent pattern over a single agent for building a personal travel planner AI?
When your customer or team sits you down and asks, “When would you use a multi-agent pattern over a single agent for building a personal travel planner AI?”, they are not really asking you to recite definitions or draw two diagrams side by side. They are testing something far more important: your engineering judgment on when and why to introduce complexity into a system that millions of real users will depend on every single day.
Really, this question is probing whether you can look at a seemingly fun, creative product like a travel planner and instantly break it down into its true structural demands. A good travel plan is never a single linear task. It involves searching flights, comparing hotels, checking activities, balancing budgets, coordinating multiple travelers, handling cancellations, and constantly replanning when prices change or availability disappears.
You need to recognize if these pieces have natural independence and parallelism, and whether you can decide when stitching them together inside one single agent would create a slow, forgetful, and expensive bottleneck versus when spinning up a team of specialist agents makes the entire experience faster, smarter, and more delightful for the user.
This scenario also tests your grasp of cost and performance trade offs in production. A single agent is simple, cheap to run, and easy to debug for basic trips but it quickly becomes a liability when the user asks for a complex vacation with dozens of constraints.
The scenario checks whether you can articulate exactly where the tipping point lives: when context windows start overflowing, when sequential tool calls add up to frustrating latency, when one agent begins hallucinating because it cannot focus on both flight math and hotel at the same time. In other words, this scenario tests if you protect simplicity until the moment the problem demands specialization and parallelism. Safety and user experience are being evaluated too.
The best designs reveal that you understand shared memory, conflict resolution between agents, and how a multi-agent system can still feel like one seamless conversation to the traveler.
Finally, this scenario checks your production realism. Will you over engineer every trip into a multi-agent flow and burn tokens on simple queries? Or will you design a graceful on-ramp where a router or confidence check decides the pattern on the fly so the system stays cheap at low complexity and scales as user expectations grow?
So this scenario is really testing your taste as a builder: your ability to feel the natural shape of the problem, your courage to add complexity only when it is justified, and your foresight to make the system feel effortless to users while remaining maintainable and cost effective. That depth of judgment is exactly what separates engineers who ship delightful travel AIs from those who ship slooooow and expensive demos.
Scenario 2: Solution Framework
When you need to decide between a single agent and multi-agent approach for the personal travel planner, I want you to use a crisp and repeatable four step framework that keeps your thinking disciplined and your response instantly valuable to any stakeholder or reviewer. This framework is your mental GPS because it forces you to start with reality, move to architecture, confront the risks, and finish with hard numbers and trade offs so nobody can accuse you of being handwavy or not knowing what you are talking about.
1. Clarify and Quantify Requirements: begin by explaining the exact shape of the problem in one or two sentences. Ask yourself: What is the user really trying to achieve? Is this a quick getaway with two variables, or an extended trip for four people with strict budgets, flight preferences, and real booking actions? List the non functional constraints too such as maximum acceptable latency for the user (ideally under 8 seconds), monthly query volume (10k–100k+), cost target per plan, and success metrics. This step is important because it reveals the true complexity signal. If the requirements stay simple and linear, you already know single agent is sufficient. If they expand into parallel sub tasks and hard constraints you have the evidence to justify multi agent without sounding like you just like fancy patterns.
2. Compare the Two Architectures: describe both options in the context of this travel planner so the stakeholder or team sees you have weighed them. For single agent, something like “The agent receives the full goal, runs a ReAct loop, calls tools sequentially (search flights → hotels → activities), reflects after each step, and outputs one itinerary.”
Then immediately contrast it with multi agent: “We spin up four specialist agents such as flight optimizer, accommodation matcher, activity curator, and budget synthesizer all coordinated by a lightweight supervisor with shared vector memory. They run in parallel where possible, pass structured JSON handoffs, and the supervisor merges their outputs into one coherent plan.” This comparison signals that you understand the exact moment the single agent approach starts to break (context overflow, sequential latency stacking, divided attention).
3. Surface Failure Modes and Mitigation Strategies: call out the realistic risks for each pattern in this specific product. For single agent, something like: “It will suffer from context dilution after six tool calls, risk repeating the same search, and create a single point of failure if the model gets stuck in a loop.” For multi agent: “We introduce coordination overhead, possible deadlocks if two agents wait on each other, and state inconsistency if memory sync fails.”
Then immediately give your fixes: “We solve this with a 10 second per agent timeout, consensus voting on conflicting recommendations, and a fallback router that collapses back to single agent if any sub agent fails.” This step proves you are thinking like an owner who will actually run the system at any time and not just an architect drawing pretty boxes.
4. Close with Evaluation, Trade-offs, and Recommendation: have a solution that is concrete with measurable analysis so the decision feels data driven. Compare the two patterns on the axes that matter such as “Single agent gives us 1.2 second average latency and $0.03 cost per simple trip but drops to 68 % user satisfaction on complex family plans. Multi agent raises average latency to 4.8 seconds and cost to $0.11 but lifts satisfaction to 94 %, cuts total token spend by 35 % through parallelism and makes feature addition easy.”
Then state your clear recommendation: “Therefore we start with single agent for all low complexity queries and dynamically upgrade to multi agent when the router detects more than three independent constraints or real booking intent.”
When you follow this flow 1. Requirements 2. Architecture comparison 3. Failure modes + fixes 4. Evaluation and recommendation, your response stops feeling like an opinion and starts sounding like the confident decision of someone who has already shipped similar systems. You can deliver the entire framework in under four minutes yet it leaves the listener with zero doubt that you have deeply considered the real product, the real users, and the real business constraints. This is exactly how engineers and product teams turn ambiguous questions into great design decisions.
When a Single Agent Breaks Down
At the outset, the problem seemed straightforward. Rather than over engineering the solution, lets assume you began with a single agent. This agent handled everything: interpreting preferences, calling flight and hotel APIs, selecting activities, and assembling the final plan. Early results were promising.
The system was simple, easy to debug, and fast enough to deliver a smooth user experience. When something went wrong there was only one place to look. At this stage adding more agents would have introduced unnecessary complexity without clear benefit so we stayed disciplined and let the single agent do the work.
Over time, however, issues began to emerge. The system didn’t fail outright but its outputs became inconsistent. A great flight option might be paired with a poorly located hotel or an itinerary might technically meet the budget while allocating resources unevenly across experiences. As you dove deeper, you realized the agent was handling too many competing objectives at once. The problem was not a lack of intelligence; it was interference.
Each part of the problem was competing for attention within the same context. Constraints weren’t consistently enforced, decisions in one area didn’t always align with others, and the growing context made behavior harder to predict. Debugging became increasingly difficult because there were no clear boundaries between responsibilities. Everything was intertwined and small changes in input could lead to unpredictable outputs. It became clear that the agent was not failing but it was being asked to do too much.
Justification for Multi Agent Pattern
That realization really leads to a shift in thinking. Instead of trying to make the single agent more sophisticated, we try to reframed the problem. They were not solving one task but several distinct ones. Flight optimization, lodging selection, activity planning, and overall itinerary coordination each had their own constraints and tradeoffs. By treating them as separate concerns the architecture naturally evolves into a multi agent system.
A flight agent could focus solely on routes and pricing, a lodging agent on location and cost, an activities agent on user preferences, and a coordinator agent could bring everything together resolving conflicts and enforcing global constraints.
This decomposition simplified each component while improving the system as a whole. Agents could operate in parallel, outputs became easier to trace and debug, and the system became more flexible and extensible. The added complexity was real though with more components and higher cost but it was now justified by the problem itself.
In the end, we didn’t start with a multi agent architecture but arrived at it. The transition was not driven by trend or preference but by the natural limits of a simpler system under real world demands. The key lesson was clear: a single agent is often the right starting point but when a system begins to struggle with competing objectives, lose coherence, and become difficult to reason about it’s a signal that the problem is no longer singular. And when the problem becomes many the architecture must evolve to reflect that.
Part A — Single Agent Design
Tool Contracts & Structured Outputs
Single Agent Architecture Recap

Preference Extraction (Structured Internal Output)
Before the system can plan anything it needs a clear and consistent understanding of the user’s request. Instead of relying on loosely interpreted text the agent converts the input into a structured representation like:
{
"destination": "Tokyo",
"dates": {
"start": "2026-04-10",
"end": "2026-04-17"
},
"budget_usd": 2500,
"preferences": ["food", "culture", "walkable"],
"constraints": ["direct_flight"]
}This structure becomes the system’s single source of truth. Every downstream decision whether selecting flights, choosing hotels, or recommending activities refers back to this shared context. It ensures that all parts of the system are aligned on the same constraints and priorities rather than reinterpreting the user’s intent independently.
More importantly it makes assumptions explicit. Preferences and constraints are no longer buried in conversation — they are clearly defined, inspectable, and enforceable. This allows the system to remain consistent across steps, and gives engineers a clear way to understand why certain decisions were made.
Tool Contract: Flight Search
As the system began interacting with external services like flight APIs, these integrations needed to be just as structured as the agents themselves. Instead of allowing loosely defined inputs and unpredictable outputs we need to formalize a strict contract for how the system communicates with the flight search tool.
Input Schema
{
"origin": "SFO",
"destination": "HND",
"departure_date": "2026-04-10",
"return_date": "2026-04-17",
"budget_usd": 1200
}Output Schema
{
"status": "success",
"options": [
{
"flight_id": "JL001",
"price": 980,
"duration_hours": 11.2,
"stops": 0,
"constraints_met": ["direct_flight"]
}
]
}The input schema ensures that every request to the tool is complete, validated, and unambiguous. The agent can’t make vague or partial requests, it must specify exactly what it’s looking for including constraints like budget and travel dates. This reduces errors and ensures consistent behavior across calls.
On the output side the structure transforms raw API data into something the system can reason about programmatically. Instead of parsing natural language descriptions the agent receives clearly defined options with attributes like price, duration, and constraint satisfaction. This makes it possible to compare results and enforce rules systematically.
What this contract ultimately provides is predictability at the system boundary. External tools are no longer black boxes, they become reliable components that fit cleanly into the agent’s decision making process.
Tool Contract: Hotel Search
As the system expands beyond flights the same discipline was applied to lodging. Rather than letting the agent vaguely look for good hotels, you need to require it to specify exactly what it was optimizing for through a structured input like:
{
"destination": "Tokyo",
"check_in": "2026-04-10",
"check_out": "2026-04-17",
"max_price_per_night": 200,
"location_preference": "central"
}This schema forces the agent to commit to clear constraints before searching which dramatically reduces ambiguity. Budget is no longer a loose guideline but becomes an enforceable limit and location preference is no longer implied but becomes a parameter that directly shapes results.
By constraining the search space upfront the system avoids a common failure mode where agents retrieve too many irrelevant options and then struggle to filter them effectively. Instead, the tool returns results that are already aligned with the user’s priorities thus making downstream reasoning simpler and more reliable. In practice this turns the lodging search from an open ended exploration into a targeted and constraint driven query.
Final Single Agent Output (User Facing)
After all the individual components have been selected and coordinated the system produces a final structured output like:
{
"itinerary": {
"flight": "JL001",
"hotel": "Shinjuku Central Hotel",
"activities": ["Tsukiji Market", "Asakusa"]
},
"assumptions": ["Prices subject to availability"],
"confidence": 0.86
}This output represents more than just a recommendation but a composed decision that reflects the work of multiple agents and constraints. By structuring the itinerary into distinct components the system makes it easy to understand how each part of the trip was selected and how they fit together.
The assumptions field plays an important role in transparency. It surfaces conditions that may affect the outcome, reminding both users and the system that certain factors like pricing or availability are dynamic and not guaranteed. This helps manage expectations and reduces the risk of overconfidence.
Finally, the confidence score provides a summary signal of how reliable the overall plan is. It gives both users and downstream systems a way to determine whether the itinerary should be accepted as is or potentially reviewed. Instead of presenting a plan as absolute the system communicates it as a reasoned but measurable decision.
Limitations of Single Agent Contracts
- All reasoning mixed together
- Harder to isolate failures
- Limited parallelism
- Context grows quickly
This sets up the justification for multi agent, now lets get to it!
Part B — Multi Agent Design
Tool Contracts & Structured Outputs
Multi Agent Architecture Recap

Shared Global Constraint Schema
As the system evolved into multiple agents working in parallel we need to remember that consistency across those agents is just as important as the logic within them. To prevent each agent from interpreting the user’s request differently a shared context schema should be introduced that every agent can use:
{
"destination": "Tokyo",
"dates": ["2026-04-10", "2026-04-17"],
"total_budget_usd": 2500,
"preferences": ["food", "culture"],
"hard_constraints": ["direct_flight"]
}This schema acts as a single source of truth that all agents read from and reason against. Instead of reparsing user intent independently each agent operates from the same structured inputs, ensuring alignment in decisions and preventing inconsistencies across outputs.
It also enforces consistency in constraint handling. For example, a direct_flight requirement is no longer something one agent might overlook as it becomes a shared rule that every component must respect. This makes the system more predictable and easier to debug since any deviation can be traced back to how the shared context was interpreted or applied.
Flight Agent Tool Contract
This output turns raw flight data into ranked and decision ready options. The score reflects how well each option satisfies the overall objective, allowing the coordinator to compare flights against other components like hotels and activities. The constraints_met field ensures that requirements like direct flights are explicitly validated rather than assumed.
{
"agent": "flight_agent",
"options": [
{
"id": "flight_A",
"price": 980,
"duration_hours": 11.2,
"score": 0.91,
"constraints_met": ["direct_flight"]
}
],
"assumptions": ["Departure time flexible ±2h"]
}The assumptions field adds important context, surfacing any flexibility or tradeoffs the agent relied on during selection. This becomes especially valuable when coordinating across agents as it helps explain why a particular option was chosen and whether adjustments are possible.
Overall this contract ensures the flight agent doesn’t just return data but delivers structured and explainable decisions that can be seamlessly integrated into the broader system.
Lodging Agent Tool Contract
As with the flight agent, the lodging agent is responsible not just for retrieving options but for producing outputs that clearly reflect tradeoffs and priorities in a structured way:
{
"agent": "lodging_agent",
"options": [
{
"id": "hotel_B",
"price_per_night": 180,
"distance_km": 1.1,
"score": 0.87
}
],
"assumptions": ["Central location prioritized"]
}Each option encodes key decision variables such as price and distance allowing the system to reason quantitatively about cost versus convenience. The score provides a normalized way to compare lodging options not just within this agent but across other agents in the system such as flights and activities.
The assumptions field plays an important role in surfacing implicit preferences that influenced the outcome. In this case prioritizing a central location may lead to higher costs and making that explicit allows the coordinator to understand and adjust those tradeoffs if needed.
Activities Agent Tool Contract
Unlike flights and lodging activities are more subjective as they depend heavily on user preferences, timing, and overall experience. To bring structure to this the activities agent produces outputs like:
{
"agent": "activities_agent",
"options": [
{
"id": "activity_C",
"category": "food",
"duration_hours": 3,
"score": 0.82
}
]
}Here, the category field connects each activity to the user’s stated interests, ensuring alignment with preferences rather than generic recommendations. The duration_hours provides a practical constraint that helps the coordinator fit activities into a coherent daily schedule without overloading the itinerary.
The score again plays an important role translating subjective quality into a comparable signal that can be weighed against other decisions in the system. Even though activities are less deterministic this structure allows them to participate in the same decision framework as flights and lodging. This contract turns experiential recommendations into structured and optimizable components that enables the system to balance not just logistics but the overall quality of the trip.
Coordinator Agent Aggregation Contract
Once all specialized agents have produced their outputs the coordinator agent brings everything together into a single and unified decision:
{
"selected_plan": {
"flight": "flight_A",
"hotel": "hotel_B",
"activities": ["activity_C"]
},
"conflicts_resolved": [
"Adjusted hotel budget to fit flight cost"
],
"overall_score": 0.88
}The selected_plan shows the final combination of choices across domains ensuring that all components such as flight, lodging, and activities work together rather than in isolation.
The conflicts_resolved field is especially important. It makes tradeoffs explicit capturing how the system handled competing constraints. The overall_score provides a single, aggregated signal of plan quality that combines inputs from multiple agents into a unified metric. This allows the system to quickly assess whether the plan meets expectations or needs further adjustment.
Failure Handling via Structured Outputs
As the system scaled failures were inevitable but what mattered was how those failures were represented and handled. Instead of allowing errors to surface as vague messages or silent breakdowns every failure was required to follow a structured format such as an agent failure example:
{
"agent": "lodging_agent",
"status": "failure",
"reason": "no_results_under_budget"
}This structure turns failure into a interpretable signal. The agent field identifies exactly where the issue occurred and reduces ambiguity. The status clearly distinguishes failure from success, allowing downstream systems to react programmatically. And the reason provides a machine readable explanation that can trigger specific recovery strategies.
The system can now respond intelligently:
- Relax constraints (ie, increase budget slightly)
- Retry with alternative parameters
- Escalate to a human if needed
By standardizing failures in this way the system becomes more resilient. Errors are no longer hidden or disruptive but become structured events that guide the next action and keeping the overall workflow intact.
Common Mistakes and How to Avoid Them:
When you answer or discuss the question “When would you use a multi agent pattern over a single agent for building a personal travel planner AI?”, I have noticed three very common mistakes tend to trip up even solid builders and they all stem from the same root issue: losing sight of the actual product reality while trying to sound smart. Recognizing them early and knowing exactly how to sidestep them is what turns a mediocre design conversation into one that earns real trust from your team and stakeholders.
The first and most frequent trap is over engineering the design by immediately declaring that everything should be multi agent, as if complexity is automatically better. You hear people say things like “Obviously we need four or five specialized agents from day one because travel is complicated.” What actually happens is they forget that most real users start with simple requests such as a quick solo weekend trip or a cheap flight search and forcing a heavy multi agent orchestration on those cases wastes money and adds unnecessary latency.
In a real travel planner this mistake shows up as burning tokens on every query and creating coordination issues for features that never needed them. To avoid it completely try to begin your thinking by explicitly calling out the simple cases first. After that its ok to introduce the transition point where multi agent becomes justified. This signals that you respect simplicity and only pay for complexity when the user problem demands it.
The second mistake is discounting evaluation entirely like describing the two patterns well but never mentioning how you would actually know which one is working better in production. Builders often skip success metrics leaving the stakeholder wondering whether the design is just theoretical.
For the travel planner this is especially dangerous because you cannot feel whether the family trip planner is truly better until you measure user satisfaction or booking completion rate. The result is a design that looks good but fails to convince anyone to ship it. The way to avoid this is to always close with hard and observable criteria right in the flow, similar to the following: “We will A/B test the switch at five percent of traffic, tracking end to end latency, average token spend, itinerary coherence score via user thumbs-up rate, and booking conversion targeting at least a fifteen percent lift in satisfaction on complex queries before making multi agent the default for those cases.” When you connect every pattern choice to measurable outcomes the entire discussion becomes grounded and actionable instead of abstract.
The third issue is forgetting observability and debugging realities especially the challenge of tracking conversations across multiple agents. People describe the elegant collaboration between the flight agent and hotel agent but never mention how anyone would debug why a particular plan crashed overnight when one agent’s recommendation contradicted another. In production this creates a nightmare for the ops team and slows down iteration dramatically.
To prevent this mistake add in concrete observability commitments such as: “We will trace every inter agent handoff with structured JSON logs and a single correlation ID, surface the full conversation graph in LangSmith or Helicone, and set alerts when any agent exceeds its timeout or when consensus voting fails more than twice.” Mentioning the actual tools and practices you will use makes it clear you have already pictured the system running in the real world and not just in a notebook.
When you watch for these three traps and instead replace them with the habits of starting simple, closing with metrics, and calling out observability your response stops sounding like a textbook and starts sounding like the thinking of someone who has actually shipped delightful AI products that scale. That shift is exactly what moves you from technically correct to “this builder gets it and I want them owning this feature.” And at the end of the day, that is a pretty awesome outcome!
Final Takeaway
Thanks for spending time with me deep diving into agentic AI design patterns, this is the stuff that separates the ‘knows LLMs’ from the ‘can architect AI systems that actually ship.’
By the time you step back from building the travel planner one can realize that the most valuable lessons had little to do with travel itself and everything to do with how agentic systems should be designed. In the beginning starting with a single agent system was not a shortcut but a deliberate choice. It allows you to understand the problem before introducing complexity. Rather than assuming you needed multiple agents, you asked what the simplest system that could work would look like and then let that guide the design.
This approach proved critical because every additional layer introduced new failure modes, higher cost, and more operational overhead. I have learned in years of designing and building AI systems that complexity isn’t something to add upfront, it’s something that must be earned through real limitations in simpler systems.
As AI systems evolve another lesson became clear to me: raw intelligence alone was not enough. Early versions of an agent produced impressive outputs but those outputs were opaque. Decisions were buried in free form text, assumptions were implicit, and when something went wrong it was difficult to trace why (total nightmare!).
The turning point for me came when the team began introducing structure into every part of the system. User inputs were converted into explicit schemas, tool interactions were governed by strict contracts, and agent outputs were required to follow defined formats. This structure didn’t just make the system cleaner it made it controllable. It enabled validation before execution and precise debugging when failures occurred. Without structure the system felt unpredictable and with it the system became manageable.
At the same time one realizes that they had been designing primarily for success. The system performed well when everything went right but real world conditions quickly exposed its fragility. External APIs failed and users provided incomplete or changing inputs. These weren’t edge cases but where the norm in the AI world. This forced a shift in mindset.
Instead of asking how to make the system produce better outputs one should began asking how it should behave when things go wrong. This led to the focus in introducing fallback strategies, retry mechanisms, confidence scoring, and explicit failure states. The system can then evolve to become more resilient but also more honest. It could recognize when it didn’t have a good answer instead of pushing forward with a confident guess.
I have learned (sometimes the hard way!) that eventually the limitations of the single agent design becomes impossible to ignore. The system is not failing in obvious ways but it was struggling with consistency. Different parts of the itinerary would conflict with each other and the agent had difficulty balancing multiple objectives simultaneously. What became clear was that the system was not solving a single problem it was trying to solve several at once. Flight selection, lodging decisions, activity planning, and overall coordination each had their own constraints and tradeoffs and forcing them into a single reasoning process created interference.
The solution was not to make the agent more powerful but to decompose the problem. By introducing specialized agents for each domain and a coordinator to bring everything together you can transform the system from a monolithic decision maker into a set of focused and collaborative components. This made the system easier to reason about, easier to debug, and ultimately more reliable.
Another important realization was that humans needed to remain part of the system. This is analogous to my prior articles on reinforcement learning with human feedback, where the feedback loop required manual intervention to preserve high fidelity reasoning and reward training.
Early designs that I led leaned heavily toward full automation but experience showed that there were always scenarios where the system lacked enough information or where the cost of being wrong was too high. Instead of treating human involvement as a failure you should begin designing for it explicitly.
Define clear escalation points and create structured handoffs with summarized context ensures that when the system deferred to a human it did so in a way that made the human’s job easier. This reframed human involvement as a core feature rather than a fallback, preserving trust in situations where automation alone was not sufficient.
As AI systems grow more complex intuition was no longer enough to guide decisions. You need concrete ways to evaluate whether changes were actually improving the system. This required the introduction of metrics that went beyond basic performance, focusing on outcomes that reflected real user value including success rates and cost efficiency.
These measurements allow you to compare different architectural choices and make informed tradeoffs. Decisions about whether to introduce additional agents or refine existing ones were no longer based on preference but on evidence.
Looking back in these examples and actual designs I have learned that the most significant shift was not in the architecture itself but in how the team approached the problem. Early on the focus had been on what the model was capable of doing. Over time that focus changed to what the system should allow the model to do. This shift from maximizing capability to enforcing control became the foundation for every design decision that followed.
In the end, building an effective agentic system was not about creating the most intelligent solution but about placing intelligence deliberately, structuring it carefully, and constraining it responsibly. The goal was not just to make the system work but to make it understandable, debuggable, and trustworthy especially in the moments when things didn’t go as planned.
My Big Takeaways in a Few Bullets
- Start simple: Default to non-agentic or single agent designs and earn every extra agent.
- Name the pattern: Router, Planner/Executor, Multi Agent, Reflection, Human Escalation. Clarity beats cleverness!
- Structure everything: Plans, tool contracts, agent outputs, handoffs. If it’s not structured it’s not production ready.
- Design for failure: Assume tools fail, agents disagree, and users are confused then show how your system survives.
- Measure what matters: Success rate, escalation quality, cost, latency, and trust; not vibes, please! :)
Thanks for reading!
The Builder’s Guide for Agentic AI Design was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.