
Enterprise system design has always been about scale, reliability, and compliance. But things are changing. Finance teams, in particular, are hitting roadblocks with exceptions that just don’t fit into any pre-set, deterministic workflow. This article traces the journey from scalable APIs to agentic AI — showing how reasoning layers, powered by LLMs and orchestrated with Semantic Kernel, extend existing stacks without replacing them. The result is not just faster systems, but smarter ones that can triage, investigate, resolve, and explain their decisions in production.
Evolution of Architecture Style in System Design in Retail Reconciliation

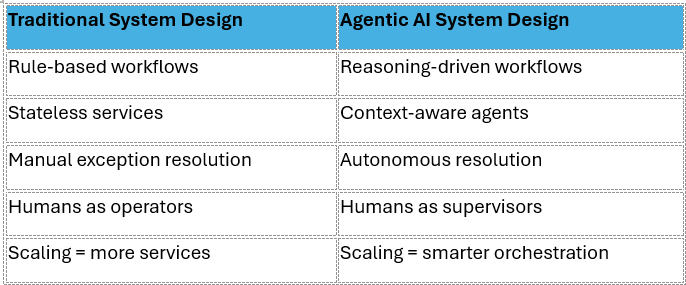
Traditional Architecture Styles
- Monoliths → tightly coupled, single deployment, hard to scale.
- SOA (Service-Oriented Architecture) → services communicate via ESB, but often heavy and rigid.
- Microservices → lightweight, independently deployable services, API-driven, highly scalable.
- Event-Driven → services react to events asynchronously, enabling loose coupling.
These styles are deterministic: they execute predefined logic, rules, or workflows. They scale well but lack adaptability.
Agentic AI Architecture Style
Agentic AI introduces a new architectural paradigm: systems designed around autonomous, goal-driven agents that orchestrate services, reason about context, and adapt dynamically.
Key Style-Level Shifts
- From Services → Agents as First-Class Citizens
- Microservices remain the “tools.”
- Agents become the “orchestrators” that decide which tool to use, when, and why.
- Architecture shifts from API orchestration to goal orchestration.
2. Context Layer
- Traditional systems are stateless; agents maintain memory, context, and history.
- This enables adaptive workflows (e.g., learning from past exceptions in reconciliation).
3. Dynamic Workflow Composition
- Instead of hard-coded pipelines, agents dynamically assemble workflows.
- Example: A finance exception triggers → Detection Agent → Resolution Agent queries procurement/logistics → Collaboration Agent escalates if needed.
4. Evaluation & Governance Layer
- New architectural layer: golden sets, graders, drift detection, audit trails.
- Ensures AI decisions are explainable, compliant, and monitored.
- This is absent in traditional architecture styles.
5. Human-in-the-Loop Integration
- Architecture explicitly includes humans as supervisory nodes.
- Agents generate recommendations, humans validate edge cases.
- Feedback loops retrain models, improving system intelligence.
6. Autonomy & Adaptability
- Systems evolve from automation (fixed rules) → autonomy (adaptive reasoning).
- Architecture is no longer just about scaling services, but scaling intelligence.
Transition from Scalable APIs (Microservices) to Orchestrating agent workflows
Let’s see this with a real time use case of retail.
In retail when businesses check their invoices, they usually try to automatically match them with purchase orders and notes about goods received in their main system. But sometimes things don’t quite line up. This often happens because of delays, orders that were only partly delivered, incorrect information, or different systems not communicating well. When these problems occur, roughly 20 to 30 percent of invoices end up needing special attention. People then have to manually dig into what went wrong, checking details across many different systems. This takes a lot of time and effort and makes it take longer to finalize the company’s financial records.
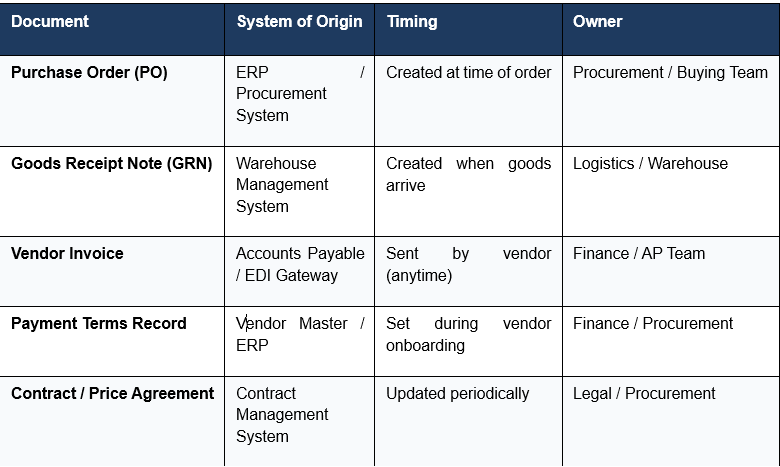
In retail, every time a business works with a vendor, at least three distinct records are created across different systems and at various times:
The Architecture Evolution in Retail Reconciliation
Next is the evolution to integrate AI agents into the microservices architecture. AI agents can communicate autonomously with each other, manage inter-service communication, balance loads and predict system failures. AI agents can minimize the human operation and maintenance involvement, thus enabling the developers to work on innovations. An example is AI agent can self-manage load balancing and traffic routing in a microservices system, and therefore increase the operation efficiency. The systems built using this new paradigm could become self-healing, self-optimizing, and able to scale autonomously.
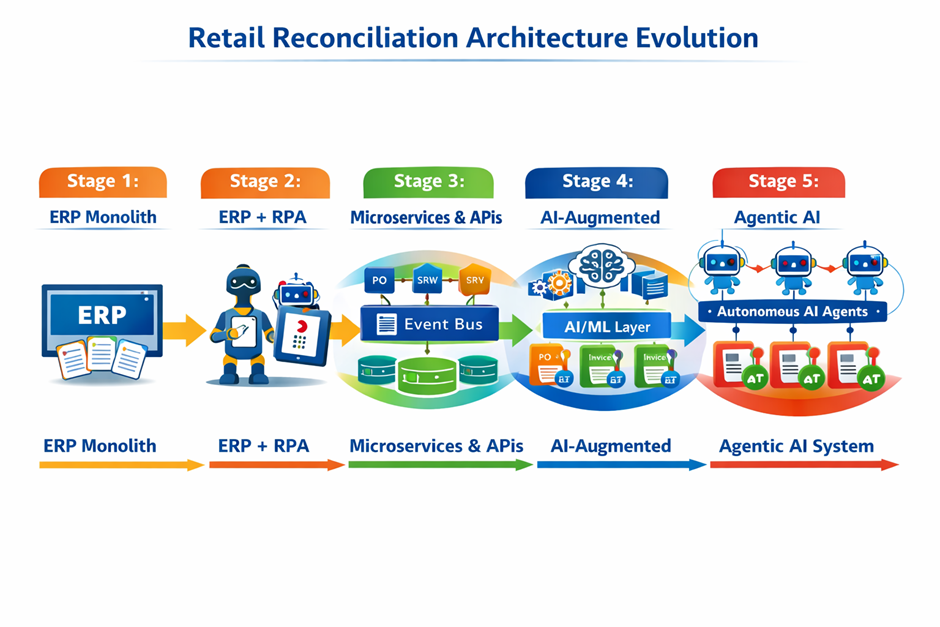
Where are we heading requires understanding where we are from. So, let’s look back at the last 4 evolutions of the architecture supporting retail invoice reconciliation.
Stage 1 — ERP-Centric Monolithic Architecture
In the beginning, there was the ERP. SAP — these systems were designed to be the single source of truth. Invoice matching happened inside the ERP using strict three-way match rules: PO quantity must equal GRN quantity must equal invoice quantity, within a defined tolerance.
This worked reasonably well when the supply chain was simple and data entry was tightly controlled. But as retail operations scaled — more vendors, more channels, more geographies — the volume and complexity of exceptions grew faster than the ERP could handle. The monolith became a bottleneck.
Stage 2 — ERP + RPA + Workflow Engine
The first wave of modernization came through Robotic Process Automation. RPA bots were deployed to handle the mechanical parts of exception investigation — logging into systems, pulling reports, copying data across screens. Workflow engines like ServiceNow or custom-built BPM tools were layered on top to route exceptions to the right human queues.
This reduced manual effort for the straightforward exceptions. But RPA is brittle by nature — it breaks when screens change, it cannot handle ambiguity, and it cannot learn. The moment an exception required genuine interpretation — say, a vendor had split a delivery across two shipments without flagging it in the system — the bot would fail and the exception would land back on a human analyst’s desk.
Stage 3 — Microservices + API-Driven Architecture
The next evolution came with the shift to microservices. Instead of a single ERP doing everything, the architecture decomposed into purpose-built services: an invoice ingestion service, a PO matching service, a GRN lookup service, a vendor master service. Each exposed clean REST or event-driven APIs. An API gateway managed routing, authentication, and rate limiting.
This dramatically improved scalability. New matching rules could be deployed without touching the ERP. Exception data could be enriched from multiple sources in parallel. The event bus — typically Azure Service Bus or Event Grid in the Microsoft stack — enabled asynchronous processing and decoupled the various stages of reconciliation from each other.
The architecture at this stage looked something like this:

Stage 4 — AI-Augmented Systems
This is not AI transformation. It is AI augmentation. The ERP, the microservices, the event bus, the data platform — all of that stays. What changes is the addition of an intelligent decision layer that can reason across all those systems, take actions through their APIs, and escalate appropriately.
The addition of an AI/ML layer introduced the ability to learn from historical exception data. Supervised models could be trained to predict exception type and likely resolution. Anomaly detection models could flag unusual vendor patterns before they created exceptions downstream. Document AI — particularly OCR combined with NLP — could extract structured data from unstructured invoices, reducing ingestion errors.
Stage 5 — Agentic AI Layer
The final stage — and the one most organizations are beginning to explore — is the introduction of autonomous AI agents that can handle the full exception investigation and resolution workflow, with humans in the loop only for genuinely ambiguous or high-risk decisions.
Microservices Architecture
The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery.
The current system is a mature microservices architecture deployed on Azure Kubernetes Service (AKS), using Azure API Management as the gateway and Azure Service Bus as the internal event backbone. It evolved over roughly four years from a monolithic ERP customization into a decomposed set of domain-aligned services.
The architecture follows a layered topology. Requests enter through the API gateway, are processed by domain microservices, state changes are propagated via events, and a separate data platform aggregates the read model for reporting and analytics
- Independent deployment of PO, GRN, and Invoice services — a change to invoice OCR logic doesn’t require re-testing the PO service
- Independent scaling — GRN Service can scale to 20 pods during peak receiving windows without scaling everything
- Clear team ownership — each domain service has a dedicated squad
- Technology diversity — the matching engine is .NET for performance; the notification service is Node.js for rapid iteration
- Fault isolation — a GRN Service outage doesn’t bring down the entire system
Our current microservices architecture handles data flow and rule-based reconciliation effectively but breaks down in exception-heavy scenarios due to lack of contextual reasoning and decision intelligence. By introducing an agent-based layer on top of the event-driven system, we transform exception handling from a manual, reactive process into an intelligent, semi-autonomous workflow while preserving the scalability and modularity of existing services.
Core Domain Services
- Order Service
- Invoice Service
- GRN service
- Payment Service
- Vendor Service
- Ledger Service
Each has it owns its database and exposes APIs via APIM
What We’re Actually Building: An AI Decision Layer:
Transforming a data‑moving architecture into a reasoning‑driven system.
The current architecture excels at moving data. It’s built for information flow — an invoice arrives, a match is attempted, an exception is raised, a case is created. At every step, the right data reaches the right service.
What it lacks is a layer that can reason about that data — a component that can look at an exception and decide:
- This is a timing gap; wait two hours before assigning.
- This price variance matches a known contract clause; auto‑approve with audit trail.
- This vendor has raised three similar disputes this month; escalate to vendor management.
That reasoning capability — contextual, adaptive, and capable of multi‑step investigation across systems — is the missing piece. It’s not a gap that more microservices can fill; it’s a gap for a different kind of component entirely.
The Agentic Extension doesn’t replace the existing architecture — it elevates it. It introduces a decision layer that sits above the current stack, using existing microservices as tools. Every API that serves the matching engine or analyst portal now becomes available to the agent. Every event flowing through the Service Bus now signals the agent layer.
Nothing below changes. What changes is what happens after the data is assembled — the system gains the ability to interpret, reason, and act.
Target Agentic Architecture: Extending the Existing Stack with an AI Decision Layer
The system was faster and more reliable, but it was not smarter where it mattered most.
The realization that shifted our thinking was this: all the information an analyst needed to resolve most exceptions already existed in our systems. The PO data was in the PO Service. The delivery timeline was in the GRN Service. The vendor’s payment terms were in the Vendor Master. The contract was in our contract management system. The vendor’s last three emails were in a shared mailbox. A good analyst could pull all of that together in 15 minutes and make a decision. The system itself could not do that — not because the data was unavailable, but because there was no component that could reason across it.
That is what an AI agent is, at its core: a component that can be given a goal, use tools to gather the information it needs, reason about what it finds, and act — or ask for help when it is not sure.
We built the agentic layer using Azure OpenAI (GPT-4o) as the reasoning engine and Semantic Kernel as the orchestration framework. The agent’s ‘tools’ are just the microservice APIs we already had — PO lookup, GRN history, vendor communication retrieval, contract clause search. We did not rebuild anything below. We added a reasoning layer on top that could call those APIs in sequence, interpret the results, and produce a structured decision
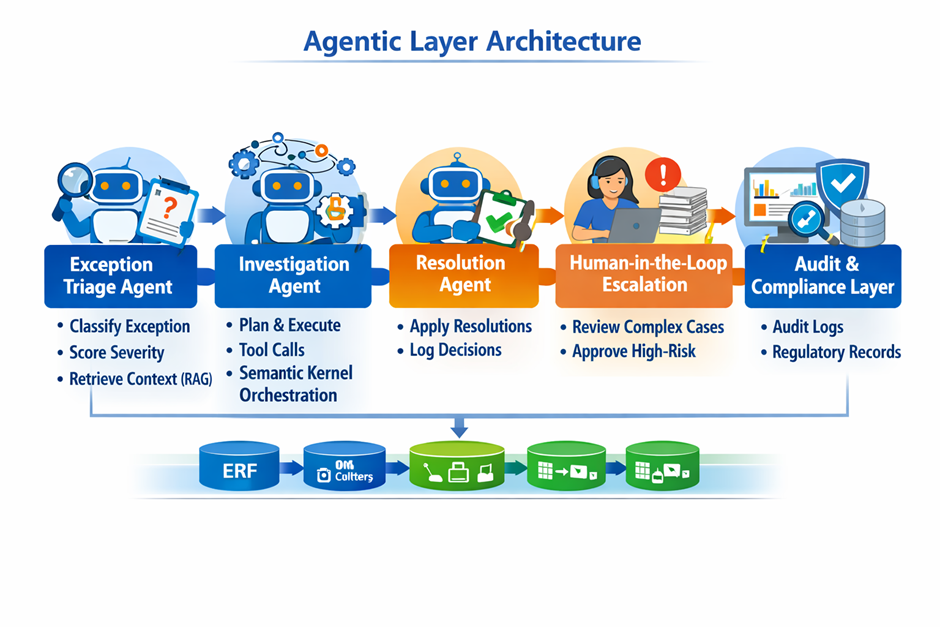
Here is what that looks like for a retail finance team using Azure:
- Exception Triage Agent
When an invoice fails the deterministic three-way match in the ERP, instead of routing it to a human queue immediately, it is published to an Azure Service Bus topic. A Function picks it up and invokes the Exception Intake Agent — a structured prompt chain running on Azure OpenAI GPT-4o — which classifies the exception type, assigns a severity score, and retrieves relevant context from the Data Platform via RAG.
- Investigation Agent
The Investigation Agent is the core reasoning component. It has access to a set of tools exposed as Azure Functions: a PO lookup tool, a GRN history tool, a vendor communication log tool, a payment terms reference tool. Using Semantic Kernel as the orchestration framework, the agent plans an investigation sequence, executes tool calls in parallel where possible, and synthesizes the findings into a structured resolution proposal.
- Resolution Agent:
For cases where investigation findings match a high-confidence resolution pattern, proposes and (within authority limits) executes the resolution. Writes decision rationale to audit log. Estimated autonomous resolution: 25–30% of investigated cases.
- Human-in-the-Loop Escalation
Not every exception gets resolved autonomously. The agent is configured with explicit guardrails: any exception above a monetary threshold, any exception involving a first-time vendor, and any exception where the agent’s confidence score falls below a defined threshold gets escalated to a human reviewer. The escalation payload includes the agent’s full reasoning trace — so the human reviewer is not starting from scratch, they are reviewing a structured recommendation with supporting evidence.
- Audit and Compliance Layer
Every agent decision — including the tool calls made, the data retrieved, and the reasoning steps followed — is logged to Azure Monitor and written to an immutable audit table in Azure SQL. This is non-negotiable for a finance workflow. Regulators and auditors need to be able to reconstruct every decision, and the system needs to be able to demonstrate that no agent acted outside its defined authority.
How it actually works — data flow
Let me walk through what actually happens when an invoice exception hits the agent layer. A production flow we run every day.
The scenario: a price variance on a fresh produce invoice
A supplier submits an invoice for ₹8,82,000 for a shipment of goods. However, the corresponding purchase order in the system reflects a total value of ₹7,56,000, resulting in a 16.7% price variance, which exceeds the company’s configured tolerance limit (typically 2–5%).
Under the agent layer, here is what happens instead:
- An invoice mismatch is detected, and the system creates an exception case and publishes an “Exception Created” event to the Service Bus.
2. Instead of routing to a finance queue, the event triggers a Triage Agent.
3. The Triage Agent gathers quick context:
- Fetches vendor details (tier, payment terms, history)
- Validates invoice details
- Checks if similar exceptions occurred in the last 30 days
4. Based on the context:
- Identifies vendor as Tier 1 and recurring similar cases
- Decides to escalate for deeper analysis
- Routes the case to the Investigation Agent
5. The Investigation Agent performs detailed analysis:
- Retrieves Purchase Order with amendment history
- Confirms Goods Receipt (delivery status)
- Fetches supplier contract
- Reviews past invoice patterns
6. The agent searches the contract and finds a price escalation clause allowing increases under specific conditions.
7. The agent validates:
- Vendor notification email was sent
- Required notice period (e.g., 14 days) is met
8. The agent generates a resolution:
- Decision: Approve invoice
- Reason: Valid price escalation per contract
- Evidence: Contract clause, email, market data
- Confidence: ~91%
9. Based on business rules:
- Invoice value is within threshold
- Confidence exceeds auto-approval limit
10. The system automatically:
- Approves the invoice
- Logs full reasoning for audit
- Notifies the finance team
11. Total resolution time: ~45 seconds with no manual intervention.
Confidence-Based Escalation & Safety Mechanisms
The system is designed so the agent never guesses. If it is uncertain or the situation is sensitive, it escalates by design.
- Low confidence: Confidence below threshold (< 85%): the agent stops, writes its partial investigation findings to the case, and routes to the analyst queue with a note explaining what it found and where it got stuck. The analyst picks up a case that is already half-investigated, not a blank slate.
- High value: High-value invoices above ~₹50 lakh require mandatory human approval, regardless of AI confidence. The agent still runs the investigation and provides its recommendation — but the human makes the final call.
- Unknown territory: if the agent encounters a situation that does not match any pattern in its tool results or its context — a new vendor, an unusual contract structure, a dispute with no prior precedent — it escalates rather than guessing. It logs what it found and explicitly states what information was missing.
Operational Impact of Agent-Based Reconciliation
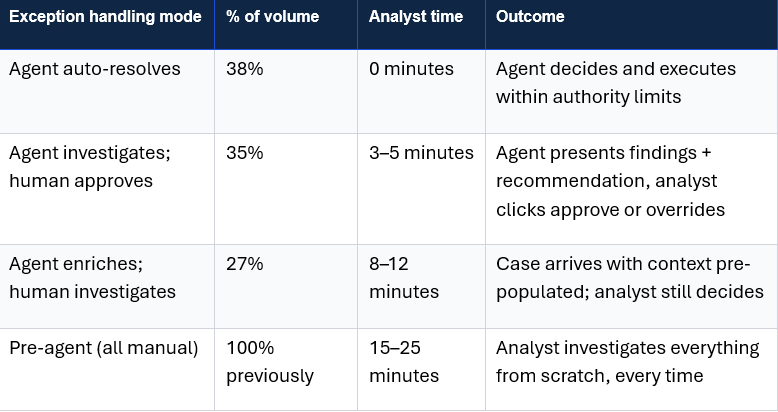
From Architecture to Production: Key Challenges
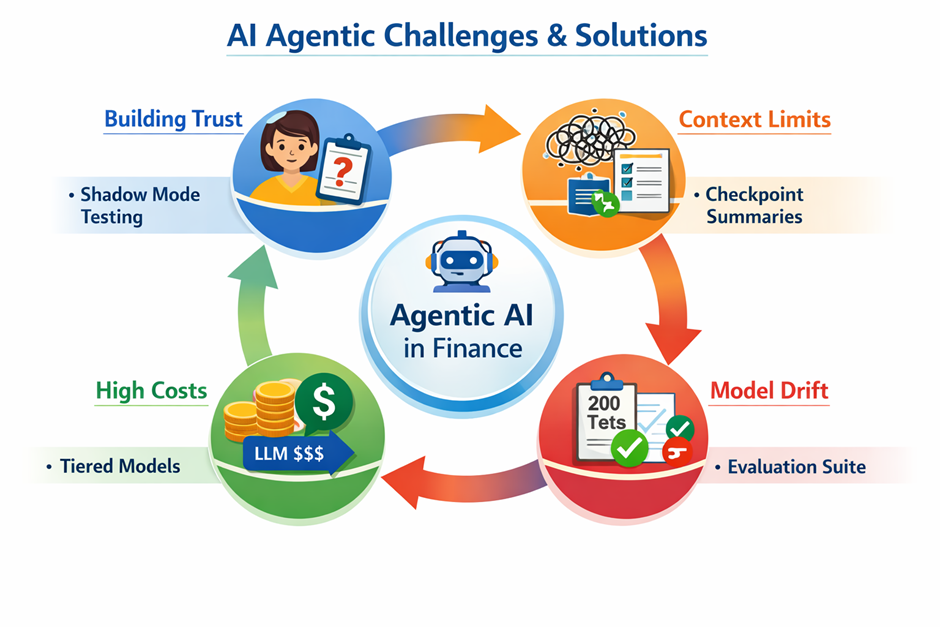
Building Trust in Agentic AI for Finance
- Getting the Finance Team to Trust It
The hardest part wasn’t the tech — it was the people trust. “Who is accountable when it approves the wrong invoice”?
That question shaped everything. Our answer:
- The system is accountable.
- The reasoning is visible.
- No agent decision is final without a human sign‑off above a certain value.
To prove it, we ran the agent in shadow mode for three months. The agent investigated every exception but only wrote its recommendation to a dashboard. The finance team could compare what the agent suggested with what they actually did.
Result: the agent was right 89% of the time. The 11% it got wrong were documented, categorized, and used to improve prompts and thresholds. That shadow period-built trust.
- Handling Context Window Limits
Some vendor disputes stretched across weeks and multiple invoices. These long investigations sometimes hit the model’s context window limit — the agent would “forget” earlier results.
We solved this with a checkpointing pattern:
- At each major step, the agent writes a structured summary to an external store. In our case we used Cosmos DB.
- When needed, it retrieves the summary instead of re‑reading raw outputs.
This kept context manageable without losing continuity.
- Managing Costs
LLM inference isn’t free. A complex case with 8–10 tool calls on GPT‑4o adds up.
Our solution:
- A Triage Agent runs on a cheaper, faster model (GPT‑4o mini).
- Only tough cases escalate to the full model.
- Simple exceptions (duplicates, timing gaps) never touch the expensive model.
This way, we use the right model for the right job and keep costs under control.
- Dealing with Prompt Drift & Model Updates
With time our agent’s confidence scores shifted. Not broken, but different enough to cause issues.We hadn’t planned for this. It took two weeks to diagnose and revalidate.
Now we run an evaluation suite before any model update:
- 200 historical exceptions with known resolutions.
- The agent processes them in shadow mode.
- If accuracy drops more than 3 points, the update is blocked until we understand why.
This keeps the system stable even as models evolve.
The ‘agent gets it wrong’ scenario will happen. Design for it: make the reasoning visible, make the escalation reliable, make the audit trail complete.
Hard‑Earned Lessons: What We Got Wrong and Fixed
A few things I got wrong that cost us time:
- Shadow mode: I underestimated the shadow mode period. We planned for six weeks and ran for three months. Shadow mode is not a delay — it is the work. Do not rush it.
- Eval first: We built the agent layer before we built the eval suite. That is the wrong order. Build the eval suite first, even before the agent exists. Use it to test manually before you have anything to automate.
- Fewer tools: We gave the agent too many tools at the start. Twenty-two available API calls. It wasted time calling tools that were not relevant to the case type. We trimmed it to nine focused tools and accuracy improved significantly.
- Confidence threshold: We initially set the auto-approve threshold too high (95% confidence). Almost nothing passed, and the whole thing felt like an expensive recommendation engine. We brought it down to 85% after the shadow mode data showed that 85–95% confidence calls were right 94% of the time. The threshold is a business decision, not a technical one — involve the finance team in setting it.
- Transparency: We did not tell the analysts what the agent was doing internally. We showed them outcomes, not reasoning. When the agent got something wrong, analysts did not know how to interpret it or improve it. Once we opened up the reasoning trace in the case view, the team started giving us much better feedback on where the agent was going wrong and why.
Conclusion
We already had strong ERP, automation, and microservices layers. What we were missing was a component that could reason across all of them. The agent layer did not replace what we had built — it completed it. After five years and four architectural stages, we finally have a system that can look at a messy invoice exception, understand the context, and decide what to do. That is worth every painful lesson along the way.
System Design Reimagined: How Scalable APIs Enable Agentic AI in Production was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.