
What is RLHF ?
RLHF is a M.L technique where Al improves by learning directly from human feedback. It is used to align Al models with human goals, ethics and preferences. It uses Human feedback to optimize LLMs to self-learn more efficiently.
Think of it this way :- Basic LLM learns from internet (good or bad). RLHF is a human intervention that teaches model difference between a correct answer and a toxic one.
Why is RLHF important and it’s use in LLMs
The ultimate aim of AI is to mimic human responses, behaviors and decision-making abilities. As we know AI is incredibly smart yet it fails at basic social interactions.
A normal LLM only knows one thing extremely well and that is predicting next word (specifically predicting the next token). The output of LLM may be bias, unclear, not useful or even wrong at times which may be harmful and violent as it is trained only on text data and does not know what a human actually wants.
As we know, LLM learns from internet text containing wrong information, toxic content, bias, spam, jokes and even harmful views. A normal LLM model may copy these patterns. Here, RLHF comes in use as it makes AI and LLMs more ethical, accurate and safer. Without RLHF, model may generate hate speech, dangerous advices, illegal instructions and various violent ideas.
To stop this from happening RLHF rewards LLMs for responses that align with human preferences, behavior and expectations and gives low scores to any unwanted and harmful outputs. This approach trains AI systems to understand and prioritize what human needs, making it more social creature. Thus, enhancing user satisfaction.
It overall enhances LLMs/AI performance as models can be trained of pre-generated data but having an additional human-feedback significantly enhances the model’s performance. It also increase scalability as AI gets more and more complex each passing day. RLHF provides practical method to boost and extend their abilities without the need for working from scratch.
How does RLHF works ?
There are various ways to use RLHF but high level thread remains the same, it consists of 3-Major phases.
PHASE — 1
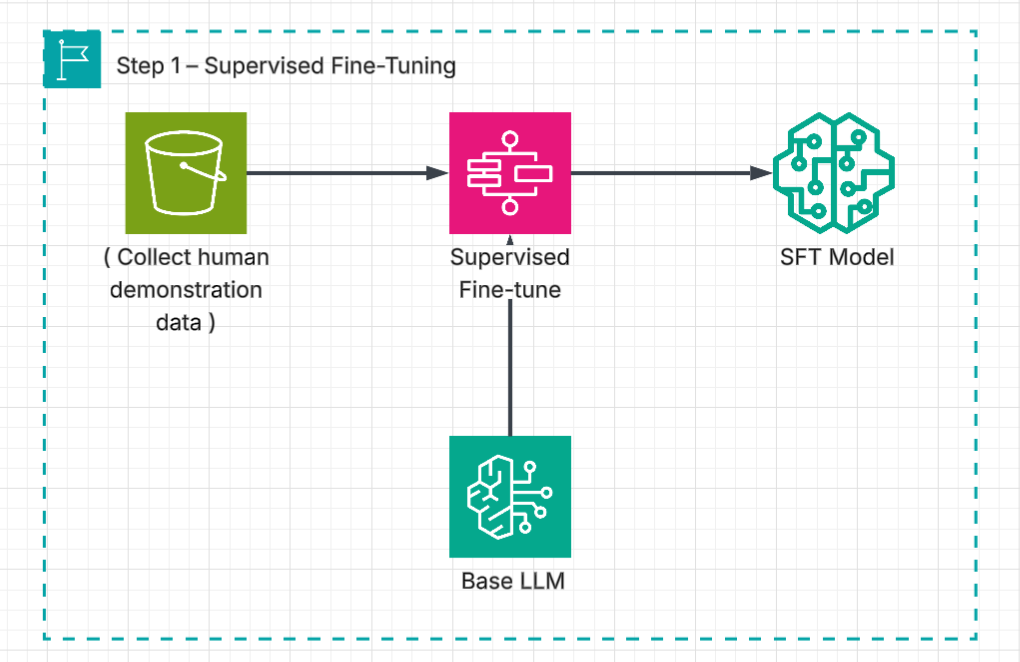
Supervised Fine Tuning (SFT)
We start the process by creating a set of human-generated prompts and responses. Then, pick a base model/LLM which has been trained on internet text. We use human generated prompts and responses to train the model and it learns from these gold-standard examples. This is necessary for enhancing model’s accuracy, reducing bias and toxic rants. Thus, becomes more helpful but still not aligned.
PHASE — 2
Reward Model (RM)
This process becomes the core of RLHF as we make a separate model that will work as a reward model on human feedback. Teaching the reward model what are human preferences using human labelers who plays a crucial role as they select a suitable and best option from multiple responses generated by the reward model. Basically, ranking the options from worst-to-best. Hence a reward model is constructed.

PHASE — 3
Optimizing Policy with Reinforcement Learning
Now, we train our Supervised Fine Tuning (SFT) model using Reinforcement Learning(RL) as whole. This model uses reward model to automatically refine its policy. It internally evaluates a series of responses and then itself chooses response that is most likely to get the greatest reward in accordance with reward model.
It follows the reinforcement loop:-
Prompt → LLM → Answer → Reward Model → Reward → Update LLM → Repeat
The aim is to adjust models output to act like a human and maximize reward score.

Limitations of RLHF ?
Contrary to this blog’s main point of reflecting the uses of RLHF, it also has some notable drawbacks and it is also not the only way to train LLMs or other models.
Complicated Process
RLHF is a complicated process as it needs various things like a set of pre written human prompts and responses, reward model, and optimizing policy which is especially time-consuming sometimes even inefficient.
Expensive
This whole takes a lot of resources as it requires human annotators, large GPU computers, training multiple models and running RL loops. This makes it impossible to be done by a individual. Therefore it requires a whole workforce.
Human Feedback
Humans may be good but they aren’t perfect as a result their feedback may be bias and problems like cultural bias, political bias, personal opinions and inconsistent labelling may occur.
Summary
What is RLHF?
It is technique where AI improves by learning directly from human feedback.
Why is RLHF important?
It makes AI safer, align better with human behavior, offers scalability, enhances AI’s performance.
How does RLHF works?
- SFT is used to create dataset and model is trained using it.
- A Reward Model is generated using human labelers.
- LLMs use this Reward Model to automatically refine it policy to give better results.
Drawbacks of RLHF:-
It is a complicated process, time consuming and is very costly. Error from humans may cause problems like bias.
Reference :-
Reinforcement Learning from Human Feedback (standalone deep dive) Nathan Lambert — 2025
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback (2023)
Reinforcement Learning From Human Feedback (RLHF) in Large Language Models(LLMs) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.