Why RLMs Are Gaining Traction and How They Outperform Traditional LLMs for Large Context Windows
A deep dive into Recursive Language Models, the context rot problem, and practical code examples showing the difference.
If you’ve been following the AI and NLP space closely, you’ve probably heard a growing buzz around Recursive Language Models (RLMs). The concept isn’t entirely new, but it has surged in popularity recently — largely because of a well-known and frustrating limitation in traditional Large Language Models (LLMs): context rot.
In this article, I’ll break down:
- What an RLM (Recursive Language Model) is
- What context rot is and why it matters
- Why RLMs are gaining popularity as a solution
- Code examples comparing a traditional LLM approach vs. an RLM approach for handling large context windows
Let’s dive in.

What Is Context Rot?
Before we talk about RLMs, we need to understand the problem they solve.
The Problem
Traditional LLMs — like GPT-4, Claude, Gemini, LLaMA, etc. — operate with a fixed context window. This context window is the maximum number of tokens the model can “see” and process at once.
- GPT-3.5 had a 4K token context window.
- GPT-4 extended this to 8K–128K tokens.
- Claude offered up to 200K tokens.
- Gemini pushed it to 1M+ tokens.
- And now again we have Claude up to 1M tokens.
Sounds great, right? Bigger is better? Not exactly.
Here’s the dirty secret: just because a model has a 128K or 1M token context window doesn’t mean it uses all of it effectively.
Context rot (also called lost-in-the-middle or context degradation) refers to the phenomenon where:
As the input context grows larger, the model’s ability to accurately attend to, recall, and reason over information in the middle of the context degrades significantly. The model tends to remember the beginning and the end of the context but “forgets” or “rots” information in the middle.
Why Does Context Rot Happen?
Several factors contribute:
- Attention Dilution: Transformer attention mechanisms distribute weights across all tokens. As context length grows, the attention each token gets becomes increasingly diluted.
- Positional Encoding Limitations: Even with RoPE (Rotary Position Embeddings) and ALiBi, models struggle to maintain meaningful positional relationships over very long sequences.
- Training Distribution Mismatch: Most models are trained predominantly on shorter sequences. Even if fine-tuned on longer contexts, the training data distribution doesn’t fully cover edge cases in 100K+ token ranges.
- Information Entropy: In extremely long documents, the signal-to-noise ratio drops. The model struggles to distinguish “what’s important” from “what’s filler.”
Real-World Impact
Imagine you pass a 100-page legal contract to an LLM and ask: “What does clause 47 say about indemnification?”
If clause 47 is buried in the middle of the document, there’s a high probability the model will:
- Hallucinate an answer
- Pull information from a different clause
- Give a vague, generic response
- Miss critical details
This isn’t a theoretical concern. Research from Stanford and UC Berkeley (the famous “Lost in the Middle” paper by Liu et al., 2023) empirically demonstrated this degradation pattern.
What Is a Recursive Language Model (RLM)?
A Recursive Language Model (RLM) is an architectural and/or inference-time paradigm where the model processes large inputs recursively — breaking them into manageable chunks, processing each chunk, summarizing or extracting key information, and then recursively combining results — rather than trying to attend to the entire context in a single forward pass.
Core Idea
Instead of:
[Entire 100K token document] → LLM → [Answer]
An RLM does:
[Chunk 1] → LLM → [Summary/Extraction 1]
[Chunk 2] → LLM → [Summary/Extraction 2]
[Chunk 3] → LLM → [Summary/Extraction 3]
...
[Chunk N] → LLM → [Summary/Extraction N]
[Summary 1 + Summary 2 + ... + Summary N] → LLM → [Refined Output]
(Optionally recurse again if the combined summaries are still too large)
Key Principles of RLMs
- Divide and Conquer: The input is split into overlapping or non-overlapping chunks that fit comfortably within the model’s effective context window (not just its maximum window).
- Recursive Aggregation: Intermediate outputs are combined and processed again, recursively, until a final result is produced.
- Hierarchical Reasoning: The model builds understanding layer by layer — first local understanding, then global understanding.
- Preserved Attention Quality: Because each individual call processes a smaller context, the attention mechanism works at peak efficiency. No context rot.
- Task-Aware Chunking: Chunks can be created based on semantic boundaries (paragraphs, sections, topics) rather than arbitrary token counts.
RLM vs. RAG: What’s the Difference?
You might be thinking: “This sounds like Retrieval-Augmented Generation (RAG).”
They’re related but fundamentally different:

RLMs don’t skip anything. They process everything, but they do it smartly and recursively.
Why RLMs Are Gaining Popularity Now
Several converging factors are driving the RLM wave:
1. Context Rot Is Now Well-Documented
The “Lost in the Middle” research made the problem undeniable. Practitioners who were blindly stuffing 100K tokens into models realized they were getting worse results than using shorter, focused prompts.
2. Cost Efficiency
Processing 100K tokens in a single call is expensive. With models like GPT-5, you’re paying for every input token. RLMs can actually be more cost-effective because:
- Smaller chunks = cheaper per call
- Summaries reduce token count at each recursion level
- You avoid paying for the model to “ignore” middle context
3. Better Results in Practice
Teams building production applications (legal tech, medical AI, financial analysis) found that recursive approaches consistently outperformed single-pass long-context approaches in accuracy benchmarks.
4. Framework Support
Libraries like LangChain, LlamaIndex, and Haystack have made it easier to implement recursive processing patterns, lowering the barrier to adoption.
5. Agent Architectures
The rise of AI agents naturally aligns with recursive processing. Agents that break tasks into subtasks, process them individually, and aggregate results are essentially implementing RLM patterns.
Code Examples: Traditional LLM vs. RLM
Now let’s get practical. I’ll show you side-by-side comparisons of how a traditional LLM approach and an RLM approach handle large context windows.
# requirements: pip install openai tiktoken
import openai
import tiktoken
from typing import List
# Initialize the OpenAI client
client = openai.OpenAI(api_key="your-api-key-here")
# Token counting utility
def count_tokens(text: str, model: str = "gpt-4") -> int:
"""Count the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model(model)
return len(encoding.encode(text))
# Simulate a large document (e.g., a 100-page legal contract)
def generate_large_document(num_sections: int = 50) -> str:
"""Generate a simulated large document with numbered sections."""
sections = []
for i in range(1, num_sections + 1):
section_content = f"""
SECTION {i}: {"INDEMNIFICATION" if i == 27 else f"GENERAL PROVISION {i}"}
{"The indemnifying party shall hold harmless and indemnify the indemnified party against all claims, damages, losses, costs, and expenses (including reasonable attorneys fees) arising out of or relating to any breach of this agreement. The indemnification obligation shall survive termination of this agreement for a period of 36 months. Maximum liability under this section shall not exceed $5,000,000 USD." if i == 27 else f"This is the content of section {i}. It contains various legal provisions, terms, and conditions that are standard in commercial contracts. The parties agree to abide by the terms set forth herein. Additional clauses and subclauses may apply as referenced in Appendix {chr(64+i) if i <= 26 else chr(64+i-26)}. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris."}
{"---" * 20}
"""
sections.append(section_content)
return "\n".join(sections)
Example 1: Simple Question Answering
Traditional LLM Approach (Single Pass)
def traditional_llm_approach(document: str, question: str) -> str:
"""
Traditional approach: Stuff the entire document into the context window
and hope the model finds the answer.
PROBLEM: Context rot - if the answer is in the middle of a large document,
the model is likely to miss it or hallucinate.
"""
token_count = count_tokens(document)
print(f"[Traditional LLM] Sending {token_count} tokens in a single pass...")
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": "You are a legal document analyst. Answer questions precisely based on the document provided."
},
{
"role": "user",
"content": f"""Here is the full document:
{document}
Question: {question}
Please provide a precise answer based on the document above."""
}
],
temperature=0,
max_tokens=500
)
return response.choices[0].message.content
# Usage
document = generate_large_document(50)
question = "What is the maximum liability amount mentioned in the indemnification section, and how long does the indemnification obligation survive after termination?"
# This approach is prone to context rot!
answer = traditional_llm_approach(document, question)
print(f"Answer: {answer}")
What goes wrong here:
- The entire document is dumped into one call
- Section 27 (our target) is buried in the middle
- The model’s attention is diluted across 50 sections
- High risk of hallucination or vague answers
RLM Approach (Recursive Processing)
def recursive_language_model_approach(document: str, question: str,
chunk_size: int = 3000,
overlap: int = 200) -> str:
"""
RLM approach: Process the document recursively.
Step 1: Chunk the document into manageable pieces
Step 2: Extract relevant information from each chunk
Step 3: Recursively combine and refine extracted information
Step 4: Generate final answer from refined context
ADVANTAGE: Each chunk gets full attention. No context rot.
"""
# ==========================================
# STEP 1: Chunk the document
# ==========================================
chunks = chunk_document(document, chunk_size, overlap)
print(f"[RLM] Document split into {len(chunks)} chunks")
# ==========================================
# STEP 2: Extract relevant info from each chunk
# ==========================================
extractions = []
for i, chunk in enumerate(chunks):
extraction = extract_from_chunk(chunk, question, chunk_index=i)
if extraction and extraction.strip().lower() != "no relevant information found.":
extractions.append(extraction)
print(f" [RLM] Chunk {i+1}/{len(chunks)}: Relevant info found ✓")
else:
print(f" [RLM] Chunk {i+1}/{len(chunks)}: No relevant info ✗")
if not extractions:
return "No relevant information found in the document."
# ==========================================
# STEP 3: Recursive aggregation
# ==========================================
combined = recursive_aggregate(extractions, question)
# ==========================================
# STEP 4: Final answer generation
# ==========================================
final_answer = generate_final_answer(combined, question)
return final_answer
def chunk_document(document: str, chunk_size: int = 3000,
overlap: int = 200) -> List[str]:
"""
Split document into overlapping chunks.
Uses semantic boundaries (section breaks) when possible.
"""
# Try to split on section boundaries first
sections = document.split("---" * 20)
chunks = []
current_chunk = ""
for section in sections:
if count_tokens(current_chunk + section) > chunk_size:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = section
else:
current_chunk += "\n" + section
if current_chunk.strip():
chunks.append(current_chunk.strip())
return chunks
def extract_from_chunk(chunk: str, question: str, chunk_index: int) -> str:
"""
Process a single chunk and extract information relevant to the question.
Each chunk gets the model's FULL attention - no context rot!
"""
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": """You are a precise information extractor.
Given a document chunk and a question, extract ONLY the information
from this chunk that is relevant to answering the question.
If no relevant information exists in this chunk, respond with:
'No relevant information found.'
Be thorough - include exact numbers, dates, and specific details."""
},
{
"role": "user",
"content": f"""Document Chunk (Part {chunk_index + 1}):
{chunk}
Question: {question}
Extract all relevant information from this chunk:"""
}
],
temperature=0,
max_tokens=300
)
return response.choices[0].message.content
def recursive_aggregate(extractions: List[str], question: str,
max_tokens_per_level: int = 4000) -> str:
"""
Recursively aggregate extracted information.
If the combined extractions are too large, recursively summarize.
"""
combined = "\n\n---\n\n".join(extractions)
# Base case: if combined text fits in a comfortable window, return it
if count_tokens(combined) <= max_tokens_per_level:
print(f" [RLM] Aggregation complete ({count_tokens(combined)} tokens)")
return combined
# Recursive case: too much extracted info, summarize in groups
print(f" [RLM] Extracted info too large ({count_tokens(combined)} tokens), recursing...")
# Group extractions into smaller batches
batch_size = max(2, len(extractions) // 3)
batches = [extractions[i:i + batch_size]
for i in range(0, len(extractions), batch_size)]
summaries = []
for batch in batches:
batch_text = "\n\n".join(batch)
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": "Consolidate and summarize the following extracted information, preserving all specific details, numbers, and facts."
},
{
"role": "user",
"content": f"""Extracted Information:
{batch_text}
Original Question: {question}
Consolidated Summary:"""
}
],
temperature=0,
max_tokens=500
)
summaries.append(response.choices[0].message.content)
# Recurse with the summaries
return recursive_aggregate(summaries, question, max_tokens_per_level)
def generate_final_answer(refined_context: str, question: str) -> str:
"""
Generate the final answer from the recursively refined context.
"""
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": """You are a legal document analyst. Based on the
extracted and refined information provided, give a precise,
comprehensive answer to the question. Cite specific details
from the information provided."""
},
{
"role": "user",
"content": f"""Refined Information from Document:
{refined_context}
Question: {question}
Precise Answer:"""
}
],
temperature=0,
max_tokens=500
)
return response.choices[0].message.content
# ==========================================
# Run the RLM approach
# ==========================================
document = generate_large_document(50)
question = "What is the maximum liability amount mentioned in the indemnification section, and how long does the indemnification obligation survive after termination?"
answer = recursive_language_model_approach(document, question)
print(f"\nFinal Answer: {answer}")
Example 2: Document Summarization
This is where RLMs truly shine. Summarizing a massive document.
Traditional LLM: Summarize in One Shot
def traditional_summarize(document: str) -> str:
"""
Traditional approach: Pass entire document and ask for summary.
Problem: Details in the middle get lost. Summary is biased toward
the beginning and end of the document.
"""
print(f"[Traditional] Summarizing {count_tokens(document)} tokens in one pass...")
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": "Provide a comprehensive summary of the following document."
},
{
"role": "user",
"content": f"Document:\n\n{document}\n\nProvide a comprehensive summary:"
}
],
temperature=0,
max_tokens=1000
)
return response.choices[0].message.content
RLM: Recursive Summarization (Map-Reduce Pattern)
def rlm_recursive_summarize(document: str,
chunk_size: int = 3000,
depth: int = 0,
max_depth: int = 5) -> str:
"""
RLM Recursive Summarization using Map-Reduce pattern.
Level 0: Summarize individual chunks (local understanding)
Level 1: Summarize groups of summaries (regional understanding)
Level 2+: Continue until everything fits (global understanding)
This is the HEART of the RLM approach.
"""
indent = " " * depth
token_count = count_tokens(document)
# Base case: document fits in a comfortable context window
if token_count <= chunk_size or depth >= max_depth:
print(f"{indent}[RLM Depth {depth}] Base case: {token_count} tokens. Summarizing directly.")
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": f"""You are summarizing at recursion depth {depth}.
{"Summarize this document chunk in detail, preserving key facts, numbers, and decisions." if depth == 0 else "Synthesize these summaries into a coherent, comprehensive summary. Eliminate redundancy but preserve all unique information."}"""
},
{
"role": "user",
"content": f"Content to summarize:\n\n{document}"
}
],
temperature=0,
max_tokens=800
)
return response.choices[0].message.content
# Recursive case: chunk, summarize each chunk, then recurse on combined summaries
print(f"{indent}[RLM Depth {depth}] Document has {token_count} tokens. Chunking and recursing...")
# MAP phase: Summarize each chunk independently
chunks = chunk_document(document, chunk_size)
print(f"{indent}[RLM Depth {depth}] Split into {len(chunks)} chunks")
chunk_summaries = []
for i, chunk in enumerate(chunks):
print(f"{indent}[RLM Depth {depth}] Processing chunk {i+1}/{len(chunks)}...")
summary = rlm_recursive_summarize(chunk, chunk_size, depth + 1, max_depth)
chunk_summaries.append(f"[Section {i+1} Summary]\n{summary}")
# REDUCE phase: Combine summaries and recurse
combined_summaries = "\n\n".join(chunk_summaries)
print(f"{indent}[RLM Depth {depth}] REDUCE: Combined summaries = {count_tokens(combined_summaries)} tokens")
# Recurse on the combined summaries
return rlm_recursive_summarize(combined_summaries, chunk_size, depth + 1, max_depth)
# ==========================================
# Usage: Compare both approaches
# ==========================================
document = generate_large_document(50)
print("=" * 60)
print("TRADITIONAL APPROACH")
print("=" * 60)
trad_summary = traditional_summarize(document)
print(f"\n{trad_summary}\n")
print("=" * 60)
print("RLM RECURSIVE APPROACH")
print("=" * 60)
rlm_summary = rlm_recursive_summarize(document)
print(f"\n{rlm_summary}\n")
Example 3: Multi-Hop Reasoning Over Large Context
This is the most impressive RLM use case — answering questions that require connecting information from multiple different parts of a large document.
def rlm_multi_hop_reasoning(document: str, question: str,
chunk_size: int = 3000,
max_reasoning_rounds: int = 3) -> str:
"""
RLM for multi-hop reasoning over large documents.
The model recursively:
1. Identifies what information it needs
2. Searches through chunks to find it
3. Reasons over found information
4. Identifies if more information is needed
5. Repeats until confident in the answer
This mimics how a human researcher would work through a large document.
"""
chunks = chunk_document(document, chunk_size)
gathered_evidence = []
reasoning_history = []
for round_num in range(max_reasoning_rounds):
print(f"\n[RLM Multi-Hop] === Reasoning Round {round_num + 1} ===")
# Step 1: Determine what information we still need
info_need = determine_information_need(
question, gathered_evidence, reasoning_history
)
print(f"[RLM Multi-Hop] Looking for: {info_need}")
# Step 2: Search through ALL chunks for relevant info
new_evidence = []
for i, chunk in enumerate(chunks):
relevance = assess_chunk_relevance(chunk, info_need)
if relevance:
new_evidence.append({
"chunk_index": i,
"evidence": relevance
})
if new_evidence:
gathered_evidence.extend(new_evidence)
print(f"[RLM Multi-Hop] Found {len(new_evidence)} new pieces of evidence")
# Step 3: Attempt to reason and answer
reasoning_result = attempt_reasoning(
question, gathered_evidence, reasoning_history
)
reasoning_history.append(reasoning_result)
# Step 4: Check if we have enough to answer confidently
if reasoning_result.get("confident", False):
print(f"[RLM Multi-Hop] Confident answer found in round {round_num + 1}")
return reasoning_result["answer"]
# Final attempt after all rounds
return generate_best_effort_answer(question, gathered_evidence, reasoning_history)
def determine_information_need(question: str, evidence: list,
history: list) -> str:
"""Determine what information we still need to answer the question."""
evidence_text = "\n".join([e["evidence"] for e in evidence]) if evidence else "None yet"
history_text = "\n".join([h.get("reasoning", "") for h in history]) if history else "None yet"
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": """Given a question, evidence gathered so far, and reasoning history,
determine what SPECIFIC information we still need to find in the document
to answer the question completely. Be specific about what to look for."""
},
{
"role": "user",
"content": f"""Question: {question}
Evidence gathered so far:
{evidence_text}
Previous reasoning:
{history_text}
What specific information should we look for next?"""
}
],
temperature=0,
max_tokens=200
)
return response.choices[0].message.content
def assess_chunk_relevance(chunk: str, information_need: str) -> str:
"""Assess if a chunk contains information relevant to our current need."""
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": """Assess if this document chunk contains information relevant
to what we're looking for. If yes, extract the relevant details.
If no, respond with exactly: 'NOT_RELEVANT'"""
},
{
"role": "user",
"content": f"""Looking for: {information_need}
Document chunk:
{chunk}
Relevant information (or 'NOT_RELEVANT'):"""
}
],
temperature=0,
max_tokens=200
)
result = response.choices[0].message.content
return None if "NOT_RELEVANT" in result else result
def attempt_reasoning(question: str, evidence: list, history: list) -> dict:
"""Attempt to answer the question with current evidence."""
evidence_text = "\n---\n".join([f"Evidence {i+1}: {e['evidence']}"
for i, e in enumerate(evidence)])
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": """Based on the evidence gathered, attempt to answer the question.
Rate your confidence as HIGH or LOW.
Respond in this format:
CONFIDENCE: HIGH or LOW
REASONING: Your step-by-step reasoning
ANSWER: Your answer (or "Need more information")"""
},
{
"role": "user",
"content": f"""Question: {question}
Gathered Evidence:
{evidence_text}
Provide your analysis:"""
}
],
temperature=0,
max_tokens=500
)
result = response.choices[0].message.content
confident = "CONFIDENCE: HIGH" in result
return {
"confident": confident,
"reasoning": result,
"answer": result.split("ANSWER:")[-1].strip() if "ANSWER:" in result else result
}
def generate_best_effort_answer(question, evidence, history):
"""Generate best-effort answer after all reasoning rounds."""
evidence_text = "\n".join([e['evidence'] for e in evidence])
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": "Provide the best possible answer given all available evidence."
},
{
"role": "user",
"content": f"Question: {question}\n\nAll Evidence:\n{evidence_text}\n\nBest Answer:"
}
],
temperature=0,
max_tokens=500
)
return response.choices[0].message.content
Example 4: A Complete RLM Class
Here’s a production-ready RLM wrapper you can use:
class RecursiveLanguageModel:
"""
A complete RLM implementation that wraps any LLM
and adds recursive processing capabilities.
"""
def __init__(self, model: str = "gpt-4",
effective_context_size: int = 3000,
overlap: int = 200,
max_recursion_depth: int = 5):
self.model = model
self.effective_context_size = effective_context_size
self.overlap = overlap
self.max_recursion_depth = max_recursion_depth
self.client = openai.OpenAI()
self.call_count = 0 # Track API calls for cost awareness
def process(self, document: str, task: str,
task_type: str = "qa") -> str:
"""
Main entry point. Automatically decides between
single-pass and recursive processing.
"""
token_count = count_tokens(document)
# If document is small enough, single pass is fine
if token_count <= self.effective_context_size:
print(f"[RLM] Document fits in effective context ({token_count} tokens). Single pass.")
return self._single_pass(document, task)
# Otherwise, go recursive
print(f"[RLM] Document too large ({token_count} tokens). Engaging recursive processing.")
if task_type == "qa":
return self._recursive_qa(document, task)
elif task_type == "summarize":
return self._recursive_summarize(document, task)
elif task_type == "analyze":
return self._recursive_analyze(document, task)
else:
return self._recursive_qa(document, task) # Default to QA
def _single_pass(self, document: str, task: str) -> str:
"""Process in a single pass when document is small enough."""
self.call_count += 1
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "Process the following document and task precisely."},
{"role": "user", "content": f"Document:\n{document}\n\nTask: {task}"}
],
temperature=0,
max_tokens=1000
)
return response.choices[0].message.content
def _recursive_qa(self, document: str, question: str, depth: int = 0) -> str:
"""Recursive question answering."""
chunks = chunk_document(document, self.effective_context_size)
# Map: Extract relevant info from each chunk
extractions = []
for i, chunk in enumerate(chunks):
self.call_count += 1
response = self.client.chat.completions.create(
model=self.model,
messages=[
{
"role": "system",
"content": "Extract information relevant to the question. Say 'NONE' if nothing relevant."
},
{
"role": "user",
"content": f"Chunk:\n{chunk}\n\nQuestion: {question}"
}
],
temperature=0,
max_tokens=300
)
result = response.choices[0].message.content
if "NONE" not in result.upper():
extractions.append(result)
if not extractions:
return "No relevant information found in the document."
combined = "\n\n".join(extractions)
# If combined extractions are small enough, generate final answer
if count_tokens(combined) <= self.effective_context_size or depth >= self.max_recursion_depth:
self.call_count += 1
response = self.client.chat.completions.create(
model=self.model,
messages=[
{
"role": "system",
"content": "Based on the extracted information, provide a precise answer."
},
{
"role": "user",
"content": f"Extracted Info:\n{combined}\n\nQuestion: {question}"
}
],
temperature=0,
max_tokens=500
)
return response.choices[0].message.content
# Recurse
return self._recursive_qa(combined, question, depth + 1)
def _recursive_summarize(self, document: str, instructions: str, depth: int = 0) -> str:
"""Recursive summarization."""
if count_tokens(document) <= self.effective_context_size or depth >= self.max_recursion_depth:
self.call_count += 1
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": f"Summarize the following. {instructions}"},
{"role": "user", "content": document}
],
temperature=0,
max_tokens=800
)
return response.choices[0].message.content
chunks = chunk_document(document, self.effective_context_size)
summaries = []
for chunk in chunks:
summary = self._recursive_summarize(chunk, instructions, depth + 1)
summaries.append(summary)
combined = "\n\n---\n\n".join(summaries)
return self._recursive_summarize(combined, instructions, depth + 1)
def _recursive_analyze(self, document: str, analysis_task: str, depth: int = 0) -> str:
"""Recursive analysis (e.g., sentiment, risk assessment, etc.)."""
chunks = chunk_document(document, self.effective_context_size)
analyses = []
for chunk in chunks:
self.call_count += 1
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": f"Analyze this document chunk. Task: {analysis_task}"},
{"role": "user", "content": chunk}
],
temperature=0,
max_tokens=400
)
analyses.append(response.choices[0].message.content)
combined = "\n\n".join(analyses)
if count_tokens(combined) <= self.effective_context_size or depth >= self.max_recursion_depth:
self.call_count += 1
response = self.client.chat.completions.create(
model=self.model,
messages=[
{
"role": "system",
"content": f"Synthesize these individual analyses into a comprehensive final analysis. Task: {analysis_task}"
},
{"role": "user", "content": combined}
],
temperature=0,
max_tokens=1000
)
return response.choices[0].message.content
return self._recursive_analyze(combined, analysis_task, depth + 1)
def get_stats(self) -> dict:
"""Return processing statistics."""
return {
"total_api_calls": self.call_count,
"model": self.model,
"effective_context_size": self.effective_context_size,
"max_recursion_depth": self.max_recursion_depth
}
# ==========================================
# Usage Example
# ==========================================
# Initialize RLM
rlm = RecursiveLanguageModel(
model="gpt-4",
effective_context_size=3000,
max_recursion_depth=4
)
# Generate a large document
document = generate_large_document(50)
print(f"Document size: {count_tokens(document)} tokens")
# Question Answering
print("\n" + "=" * 60)
print("QUESTION ANSWERING")
print("=" * 60)
answer = rlm.process(
document=document,
task="What is the maximum liability under the indemnification section?",
task_type="qa"
)
print(f"Answer: {answer}")
print(f"Stats: {rlm.get_stats()}")
# Summarization
rlm_summarizer = RecursiveLanguageModel(effective_context_size=3000)
print("\n" + "=" * 60)
print("SUMMARIZATION")
print("=" * 60)
summary = rlm_summarizer.process(
document=document,
task="Provide a detailed summary covering all major provisions.",
task_type="summarize"
)
print(f"Summary: {summary}")
print(f"Stats: {rlm_summarizer.get_stats()}")
Comparison Table: Traditional LLM vs. RLM
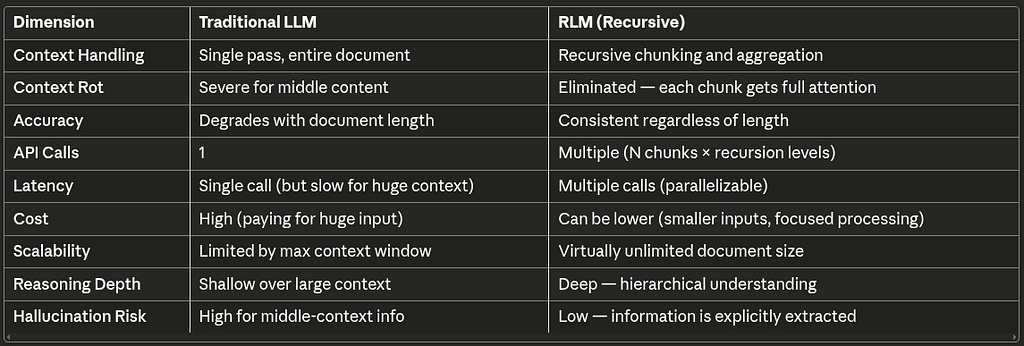
When to Use RLMs vs. Traditional LLMs
Use Traditional LLMs when:
- Your input fits comfortably within the effective context window (typically 2K–8K tokens for best results)
- You need single-turn, simple queries
- Latency is critical and you can’t afford multiple round-trips
- The information you need is likely at the beginning or end of the text
Use RLMs when:
- Your documents exceed 10K+ tokens
- You need comprehensive coverage (not just the first/last few paragraphs)
- You’re performing multi-hop reasoning (connecting dots from different parts)
- You need reliable, production-grade outputs (legal, medical, financial)
- You’re summarizing large documents and can’t afford to lose details
- You’re building agent-based systems that need to reason over large knowledge bases
The Future of RLMs
The RLM paradigm is still evolving. Here’s what we can see on the horizon:
- Native RLM Architectures: Instead of retrofitting recursive processing onto transformer-based LLMs, we’ll see models architecturally designed for recursive processing (think Mamba + recursive layers).
- Adaptive Chunking: AI-powered chunking that understands document structure and creates semantically meaningful chunks rather than token-count-based splits.
- Cached Recursion: Storing intermediate results so that follow-up questions don’t require re-processing the entire document tree.
- Hybrid RAG-RLM: Combining retrieval (for speed) with recursive processing (for completeness) — retrieve the most likely chunks first, but recursively process everything as a fallback.
- Hardware Optimization: As recursive patterns become standard, hardware and inference frameworks will optimize for the multiple-small-call pattern rather than the single-huge-call pattern.
Conclusion
Context rot is real, and it’s costing businesses accuracy, reliability, and trust in their AI systems.
The Recursive Language Model (RLM) approach isn’t just a workaround — it’s a fundamentally better way to handle large contexts. By processing information recursively, we:
- Eliminate context rot
- Maintain consistent accuracy regardless of document length
- Enable multi-hop reasoning over massive documents
- Build more reliable, production-ready AI systems
The next time you’re tempted to stuff 100K tokens into a single prompt and hope for the best, remember: your LLM is probably ignoring most of it. Go recursive instead.
If you found this article helpful, give it a clap 👏 and follow me for more deep dives into practical AI engineering. Feel free to connect with me on [LinkedIn] for discussions about RLMs, LLMs, and AI architecture.
Recursive Language Models (RLMs): The Answer to Context Rot in Large Language Models was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.