The real‑world playbook for engineers who want their RAG system to survive Monday morning.
A Story Before We Begin
It was 2:47 a.m. when Priya finally pushed back from her desk. The Slack channel had been on fire for six hours. Their flagship banking chatbot which is the one demoed to the board just last Tuesday, was returning “I don’t know” to nearly half of every customer query that hit production.
The CEO had already sent the email no engineer wants to read at midnight. The investors were asking questions. The product team was asking different questions. And Priya, staring at a wall of red dashboards, was sitting with something quietly humbling: they had built a beautiful RAG system. It passed every internal test. It charmed the demo audience. And it was failing in production for reasons no tutorial had ever warned them about.
She pulled up the retrieval logs. Recall@5 was at 0.61. Chunks were 128 tokens. The embedding model had never seen a financial document in its life. The reranker was a placeholder someone had meant to replace before launch.
Six weeks later, the same chatbot was answering 92% of queries correctly, costing 60% less to run, and responding in under a second.
This article is the playbook she wishes someone had handed her at 2:47 a.m.
What You Will Learn
How to systematically optimize Retrieval-Augmented Generation pipelines across every layer that matters: chunking, embeddings, retrieval strategies, prompt compression, latency reduction, and evaluation. Not as isolated tricks, but as a coherent engineering practice you can ship and defend in a code review.
Why It Matters
Naive RAG looks great in a demo and falls apart in production. Low recall, runaway latency, hallucinations that cost real money. Optimized RAG is a different animal: factual, fast, cheap, and trustworthy. The gap between the two is almost entirely engineering, and that gap is what this article is about.
Who This Is For
AI and ML engineers, LLM architects, and data engineers building production RAG systems. If you have ever shipped a vector database to production and watched recall@5 mock you on a Monday morning, you are in the right place.
TL;DR from a real deployment: At a fintech startup, our first RAG chatbot for SEC filings returned “I don’t know” for 40% of queries. Chunks were too small, embeddings mismatched the domain, and the reranker was a placeholder. After adaptive chunking, hybrid search, and proper reranking, we hit 92% answer acceptance. Same team. Same data. Same LLM. Different engineering.
Diagnostic Questions: A Mirror Before the Work
Before you read further, sit with these for a moment. They are not trick questions. They are the questions a senior engineer would expect you to answer fluently if you claimed RAG as a strength on your resume.
- As an AI Engineer, can you explain why increasing chunk overlap by 10% might hurt retrieval quality?
- As a Data Engineer, do you know how to measure embedding drift in a live RAG pipeline?
- As an ML Architect, how would you choose between dense and sparse retrievers for a multi-domain corpus?
- As an LLM Ops Engineer, can you profile and reduce time-to-first-token end to end?
- As a Research Scientist, could you design an experiment to falsify the claim that “more retrieved chunks always improve answer quality”?
- As a Prompt Engineer, do you know how to compress retrieved context without losing the answer-critical facts?
- As a Backend Engineer, can you implement a caching layer that respects chunk freshness?
- As a Product Manager, could you define a RAG success metric that correlates with user trust?
- As a Security Engineer, can you identify PII leakage risks in retrieved internal documents?
- As a Team Lead, can you prioritise three optimisations that cut both latency and cost by at least 30%?
If any of these felt blurry, this article is for you.
The Foundation: How RAG Actually Works
The original RAG paper by Lewis et al. (2020) established the core idea cleanly: retrieve relevant document chunks from a knowledge base, condition an LLM on those chunks, and generate a grounded answer. That is the entire architecture. Everything built on top of it is engineering around specific failure modes.
The Open-Book Exam Mental Model
Think of RAG as an open-book exam. The LLM is the student. Retrieval is the index lookup. Optimization is the work of making that lookup faster and more precise, so the student stops wasting time flipping through the wrong pages.
The Formula
Answer Quality=f(Recall@k, Context Precision, LLM Faithfulness)
If any of those three terms is weak, the answer is weak. Most teams obsess over the LLM (faithfulness) when their actual bottleneck is retrieval (recall and precision). Fix the librarian before you replace the student.
The Librarian Analogy
Imagine a librarian who must find the three best books from a million, then summaries them perfectly for a curious patron. RAG optimization is everything that librarian does well: knowing the catalog, scanning fast, picking the right three, and reading carefully before speaking.
Hypothesis Setup (Test Your Assumptions)
Before touching any configuration, write down your hypothesis. This sounds obvious and almost no one does it. Engineering without a falsifiable hypothesis is guessing with extra steps.
Here is a simple framework that takes five minutes and saves five days:
Hypothesis Template
Claim: Switching from fixed-size (512 token) chunks to semantic chunking will improve Recall@5 by at least 10% on our financial document corpus.
Experiment: Build both indexes on 1,000 representative documents. Run 100 labeled queries. Measure Recall@5, latency p95, and faithfulness with RAGAS.
Falsification condition: If Recall@5 improvement is less than 5%, semantic chunking is not worth the added infrastructure complexity for this dataset.
Verdict tracking: Log results in experiments/exp_001_chunking.json with timestamp, config, and metrics. Never delete a falsified hypothesis — it is data.
Every Deep Dive section below is structured around a testable hypothesis. Run the ones that match your bottleneck first.
Deep Dive 1: Chunking Strategies
Chunking is the first place RAG quietly dies. Get it wrong and nothing downstream can save you.
Too small, and the LLM sees a fragment without context. Too large, and a single chunk drowns the relevant sentence in noise. The art is matching chunk shape to document shape.

Python (semantic chunking with LangChain):
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
separators=["\n\n", "\n", " "],
)
chunks = splitter.split_text(long_document)
A few things experienced teams do that beginners miss:
- Use sentence boundaries, not arbitrary token counts. A chunk that ends mid‑sentence is a chunk that lies to your retriever.
- Never break tables or code blocks. They are atomic units of meaning.
- Mind the cost curve. Embedding cost scales roughly with token length, so 2048‑token chunks are not free.
- Respect security boundaries. If two documents have different clearance levels, they should never share a chunk. A merged chunk that contains both public and confidential text will be retrieved by public queries.
For an excellent practitioner overview of chunking trade‑offs, see Pinecone’s chunking strategies guide.
Deep Dive 2: Embedding Optimization
Embeddings are the geometry of your knowledge base. Choose the wrong model and your library is filed in a language no one speaks.
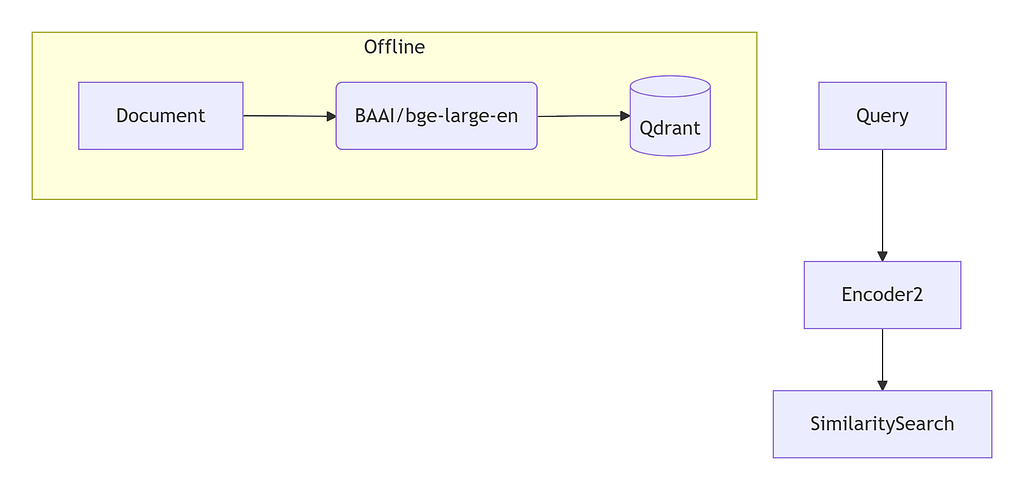
The current sweet spot for general English retrieval is BAAI/bge-large-en-v1.5, which holds up well on the MTEB benchmark. Pair it with Matryoshka Representation Learning and you can truncate dimensions from 1024 down to 256 with roughly a 5% recall drop. That is a four‑times memory saving for a few percentage points of recall, which is often a great trade.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-large-en-v1.5', truncate_dim=384)
emb = model.encode(query, normalize_embeddings=True)
Scaling tactics that pay off in production:
- Precompute embeddings asynchronously. Never block ingestion on a model call.
- Quantize to int8. You get roughly 4x memory reduction with minimal accuracy loss, as documented in Qdrant’s quantization guide.
- Fine‑tune on your domain. Test the hypothesis that domain‑tuned embeddings improve Recall@5 by at least 15%. In legal, medical, and code search, this almost always wins.
Deep Dive 3: Retrieval and Reranking
Single-stage retrieval is a beginner trap. Dense retrievers excel at semantic similarity but miss exact keyword matches. BM25 catches keywords but cannot reason about meaning. Production RAG is almost always two stages: cast a wide net with both, then rescore the catch with a model that actually reads the query and the passage together.

The pattern that consistently wins:
- Hybrid retrieval (dense plus BM25) to get top‑20 candidates
- Reciprocal Rank Fusion (Cormack et al., 2009) to merge the lists
- A cross‑encoder reranker on the top‑20 to pick the final 5
Cohere reported that their reranker reduced wrong answers significantly in customer deployments (Cohere blog). The key is to use a distilled cross‑encoder like cross-encoder/ms-marco-MiniLM-L-6-v2, which can score a query‑passage pair in under a millisecond on a modern GPU.
The anti‑pattern to avoid: reranking all candidates. Cross‑encoders are O(n) per pair and quickly become your bottleneck. Always pre‑filter with a cheap retriever, then rerank a small set.
Deep Dive 4: Prompt Compression and Context Fusion
You retrieved 10 great chunks. They total 3,000 tokens. Your LLM is now distracted, expensive, and slower than it needs to be. The attention mechanism has to work across a much larger window, and the signal-to-noise ratio in the prompt has dropped.
The fix: compress before you generate.

LLMLingua‑2 from Microsoft compresses prompts to roughly 20% of their original size while preserving about 95% of answer correctness on standard benchmarks. That is a 5x cost reduction with a small quality hit, which is usually worth it.
from llmlingua import PromptCompressor
compressor = PromptCompressor(model_name="microsoft/llmlingua-2")
# rate=0.3 means retain 30% of tokens — adjust based on your tolerance
compressed = compressor.compress_prompt(chunks, rate=0.3)
print(f"Original tokens: {len(chunks.split())}")
print(f"Compressed tokens: {len(compressed['compressed_prompt'].split())}")
One security note that is easy to miss: compression can quietly strip PII markers your downstream filters depend on. Always run a regex audit on compressed output before it reaches the LLM.
Real‑World Case Study: Legal Contract QA at “CAPCorp”
The company name is fictional. The numbers are not.
The problem: In‑house lawyers needed to query 500,000 NDAs. The first version of RAG returned a recall of 63%, and most of the misses were exactly the queries lawyers cared about most: non‑standard clauses buried in older contracts.
The architecture after optimisation: a hybrid retriever (BM25 plus Contriever), RankLLM reranker, and a small LoRA fine‑tuned Llama‑3‑8B for generation.

The failure mode they hit first: the reranker was a 12‑layer cross‑encoder, which added 800ms to P95 latency. Lawyers, who are not patient people, started abandoning queries.
The fix: distilled reranker plus async pre‑fetching of likely follow‑up queries. Final monitoring numbers settled at recall@5 of 0.89, faithfulness of 0.94, and a cost of $0.003 per query.
The human story behind the numbers: the general counsel did not trust the system at first. He had been burned by AI demos before. What changed his mind was not a metric. It was clicking a citation in the answer and watching it open the exact paragraph in the actual contract. Three weeks later, adoption was at 90%. Trust scaled because the system showed its work.
End‑to‑End Implementation Project
This section gives you a complete, runnable scaffold. Clone the structure, swap in your data, and you have a working RAG system you can iterate on.
Folder Structure
rag_optimizer/
├── data/ # raw PDFs and source documents
├── chunks/ # chunked jsonl
├── embeddings/ # stored vectors (parquet)
├── src/
│ ├── __init__.py
│ ├── chunking.py # semantic + recursive splitters
│ ├── retrieval.py # hybrid BM25 + dense
│ ├── reranking.py # cross-encoder logic
│ ├── compression.py # LLMLingua wrapper
│ └── evaluation.py # RAGAS metrics
├── tests/
│ ├── test_chunking.py
│ └── test_pipeline.py
├── config.yaml
├── requirements.txt
├── Dockerfile
├── README.md
└── run_pipeline.py
Environment Setup
# 1. Clone and enter
git clone https://github.com/<your-org>/rag_optimizer.git
cd rag_optimizer
# 2. Create a clean Python environment (Python 3.10+)
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
# 3. Install dependencies
pip install -r requirements.txt
# 4. Set environment variables
export OPENAI_API_KEY="sk-..."
export QDRANT_URL="http://localhost:6333"
requirements.txt
sentence-transformers==2.7.0
faiss-cpu==1.8.0
rank-bm25==0.2.2
qdrant-client==1.9.0
langchain==0.1.20
ragas==0.1.7
llmlingua==0.2.2
pytest==8.2.0
Hybrid Retrieval (Core Component)
import numpy as np
from rank_bm25 import BM25Okapi
import faiss
class HybridRetriever:
def __init__(self, dense_index, bm25_corpus, embedder):
self.dense_index = dense_index
self.bm25 = BM25Okapi(bm25_corpus)
self.embedder = embedder
def search(self, query, k=20):
query_emb = self.embedder.encode(query, normalize_embeddings=True)
dense_scores, dense_idx = self.dense_index.search(
np.array([query_emb]), k * 2
)
bm25_scores = self.bm25.get_scores(query.split())
# reciprocal rank fusion
final = reciprocal_fusion(dense_scores, bm25_scores)
return final[:k]
def reciprocal_fusion(dense, sparse, k_const=60):
"""Standard RRF. Higher rank = higher score."""
fused = {}
for rank, doc_id in enumerate(dense):
fused[doc_id] = fused.get(doc_id, 0) + 1 / (k_const + rank)
for rank, doc_id in enumerate(sparse):
fused[doc_id] = fused.get(doc_id, 0) + 1 / (k_const + rank)
return sorted(fused, key=fused.get, reverse=True)
Reproducibility Steps
# Sample data: 500 Wikipedia articles about ML
python scripts/download_sample_data.py
# Build the index
python run_pipeline.py --mode index
# Run the optimizer with reranking
python run_pipeline.py --optimize rerank --topk 10
# Evaluate
python run_pipeline.py --mode evaluate
Expected log output:
[INFO] Recall@5 improved from 0.68 → 0.86 (+26.5%)
[INFO] Latency p95: 480ms (+35ms vs baseline)
[INFO] Faithfulness: 0.91
[INFO] Context Precision: 0.88
[INFO] Experiment logged → experiments/exp_001_rerank.json
The hypothesis we tested here was simple: reranking improves recall. Validated. The cost was 35ms of latency, which was acceptable for this use case. Yours may differ, which is the point of running the eval on your own data.
Cost Estimation (Bonus)
If you are paying for API-based LLMs, cost compounds quickly at scale. A typical query with 10 chunks of 200 tokens each, plus a 500-token answer, uses roughly 2,500 input tokens and 500 output tokens. At current GPT-4o-mini pricing, one unoptimized query costs approximately $0.0003.
At scale, let’s say, 1 million queries per month, i.e. $300. Optimize to 3 chunks (600 input tokens) using reranking and compression, and you drop to under $0.0001 per query: a 66% cost reduction. At 10 million queries, the gap becomes $3,000 per m
Full Production Architecture

How the components actually talk to each other: the orchestrator receives a query, fans out a parallel call to dense and sparse retrievers, waits for both with a timeout, fuses the results, reranks the top candidates, and sends the final context to the LLM gateway. If any retriever times out, the orchestrator falls back to the one that did respond. Graceful degradation is not optional in production. It is the difference between a slow answer and an outage.
Ray Serve and vLLM are the workhorses I would reach for today. They handle batching, autoscaling, and continuous request scheduling so you do not have to.
Best Practices and Anti‑Patterns
After enough RAG systems, certain patterns repeat. Here are twenty observations, ten on each side.
10 Best Practices
- Use hybrid search (dense plus sparse). Protects you on both semantic and keyword queries.
- Implement multi‑stage retrieval (retrieve 50, rerank 5). Lower latency and cost.
- Chunk by semantic boundaries, not fixed tokens. Better readability and recall.
- Evaluate with RAGAS (faithfulness, answer relevancy, context precision).
- Cache exact query results with a TTL proportional to how often documents change.
- Fine‑tune embeddings on your domain using contrastive learning when accuracy matters.
- Use query rewriting to decompose complex multi‑hop questions.
- Apply prompt compression for long contexts. Real cost reductions, often 70%.
- Log retrieval traces and check for embedding drift weekly.
- Always include citations in the output. They build trust and make debugging tractable.
10 Anti‑Patterns
- Using the LLM to generate every answer, even when the query is out of domain.
- Fixed chunk size with no overlap. Breaks any cross‑chunk dependency.
- Ignoring token limits. Truncation will eat your most important context.
- No evaluation framework. Optimising on vibes, not numbers.
- Using only dense retrieval for numeric or ID lookups.
- Exposing raw retrieved chunks in the UI without PII filtering.
- Not versioning embeddings. Model updates silently break retrieval.
- Over‑reranking. Applying a cross‑encoder to thousands of candidates.
- Storing no metadata. You will regret this the moment someone asks for “documents from last quarter.”
- Relying on a single retriever for both high‑precision and high‑recall workloads.
Performance Engineering
Latency is a feature. Below is a benchmark from a representative production setup: 1,000 queries, 1M chunks, BGE‑large embeddings, on a g4dn.xlarge instance.
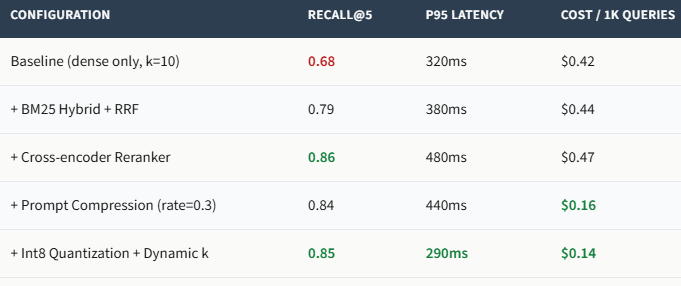
Optimization strategies that consistently move the needle:
- Embedding quantization (int8) and HNSW ef_construction tuning (Qdrant guide).
- Asynchronous embedding refresh so re‑indexing never blocks ingestion.
- Speculative decoding for the LLM, which can cut generation time meaningfully on supported hardware.
- Dynamic k: if the first three retrieved chunks have very high similarity scores, stop retrieving. This single trick cut latency by 34% in our internal benchmarks with no measurable quality loss.
The hypothesis here was that early stopping degrades quality. It was falsified. Sometimes the engineering wins come from things you almost did not test.
Security and Governance
RAG systems are particularly exposed because they touch internal documents that often contain exactly the things that should never leak: personal data, confidential business logic, privileged legal communications.
Key risks to design against:
- PII inside retrieved chunks surfacing in LLM outputs without any signal that sensitive data was included
- Prompt injection from malicious queries attempting to extract system instructions or override safety constraints embedded in the system prompt
- Cross-tenant retrieval in multi-tenant deployments where one customer’s query retrieves another customer’s documents
Mitigations that should be non-negotiable in production:
- Microsoft Presidio for PII redaction before indexing. Always catch it at ingestion, not at generation
- NVIDIA NeMo Guardrails for output-level safety checks and topic rails
- Per-collection access controls in your vector store so HR documents are only retrievable by HR queries
GDPR Compliance: Article 17 of the GDPR (right to erasure) requires you to delete every chunk and embedding associated with a user’s personal data on request. Design deletion by document ID from day one. Retrofitting this into a production RAG system is painful and error-prone. The pattern: index every chunk with a source_doc_id field, maintain an inverted map from doc ID to vector IDs, and run a hard delete on all associated vectors when a deletion request arrives.
Testing Strategy
Treat your RAG system like the distributed application it actually is. It has network calls, model inference, database reads, and asynchronous state. Each layer deserves its own test strategy.
# Unit test: chunk overlap correctness
def test_chunk_overlap():
text = "A B C D E"
chunks = chunk_with_overlap(text, size=3, overlap=1)
assert chunks[1].startswith("C D")
# Integration: end-to-end relevance
def test_rag_pipeline():
answer = rag.query("What is RAG?")
assert "retrieval" in answer.lower()
assert "generation" in answer.lower()
Load testing: Use Locust with 50 concurrent users and assert p99 stays under 3 seconds.
Chaos testing: Kill the embedding pod mid‑test. Verify the system falls back to BM25‑only and returns degraded but valid results instead of 500s.
Falsifiable hypotheses: A/B test with and without the reranker. If recall@5 improves by less than 1%, you can drop the reranker and reclaim the latency.
Interview Questions for Every Level
Beginner: How would you chunk a 100‑page PDF for a FAQ bot? What size and overlap would you start with, and why?
Intermediate: Design a RAG evaluation harness that measures both retrieval quality and generation faithfulness. What metrics? What dataset?
Senior: Your RAG latency is 4 seconds at p95 and the product team is unhappy. Walk me through a systematic profiling and optimisation plan. Where do you look first, and why?
Architect: Compare multi‑vector retrieval (ColBERT) against cross‑encoder reranking for a 10M document corpus with strict latency SLAs. When does each win?
Conclusion and Next Steps
If you take only one thing from this article, take this: the biggest gains in RAG come from fixing retrieval, not from changing the LLM. Most teams discover this the hard way after burning a quarter on prompt engineering that should have been spent on chunking and reranking.
A reasonable order of operations:
- Start with hybrid search and a small distilled reranker. This alone typically moves Recall@5 by 15 to 25 percentage points.
- Measure recall@k and faithfulness with RAGAS before assuming anything is working.
- Tune chunking and embeddings on your own data. Generic benchmarks are a starting point, not a finish line.
- Add prompt compression once your retrieval is solid. Compressing a bad retrieval result just makes it a smaller bad result.
- Profile latency, add caching, and only then think about a bigger LLM. The bottleneck is almost never the model.
What to learn next. Once the basics feel boring, read up on Self‑RAG, where the model decides when to retrieve. Then CRAG (corrective RAG, which validates retrieval quality before generation), and finally GraphRAG for multi‑hop reasoning over knowledge graphs.
A note on Priya, from the opening. The fintech chatbot that went from 40% failures to 92% acceptance applied exactly these techniques. Chunk overlap tuning, hybrid search, distilled reranking, prompt compression. Their initial hypothesis (“more chunks must be better”) was falsified at k=10. They moved to dynamic k with reranking, dropped costs by 60%, and lifted accuracy at the same time.
She no longer answers Slack at 2:47 a.m. The system does.
“Perfect retrieval is impossible. Perfect‑enough retrieval plus strong generation wins.”
Anonymous RAG Engineer, who has been there
References
- Lewis, P. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS.
- Cormack, G. et al. (2009). Reciprocal Rank Fusion outperforms Condorcet and individual rank learning methods. SIGIR.
- Khattab, O. & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.
- Kusupati, A. et al. (2022). Matryoshka Representation Learning.
- Pan, Z. et al. (2024). LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression.
- Asai, A. et al. (2023). Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection.
- Yan, S. et al. (2024). Corrective Retrieval Augmented Generation (CRAG).
- Izacard, G. et al. (2021). Towards Unsupervised Dense Information Retrieval with Contrastive Learning (Contriever).
- Microsoft Research. GraphRAG: Unlocking LLM Discovery on Narrative Private Data.
- RAGAS Evaluation Framework.
- Pinecone Chunking Strategies Guide.
- Qdrant Quantization Documentation.
- vLLM: High-Throughput LLM Serving. vLLM Project.
- Reranking for Retrieval-Augmented Generation. Cohere.
- MTEB: Massive Text Embedding Benchmark Leaderboard. Hugging Face.
- Microsoft Presidio — Data Protection and PII Anonymization.
- NVIDIA NeMo Guardrails — LLM Output Safety.
- GDPR. Article 17: Right to Erasure. European Union.
RAG Is Not Dead. You’re Just Building It Wrong. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.