RAG is a distributed system . It becomes clear when moving beyond demos into production.
It consists of independent services such as ingestion, retrieval, inference, orchestration, and observability. Each component introduces its own latency, scaling characteristics, and failure modes, making coordination, observability, and fault tolerance essential.
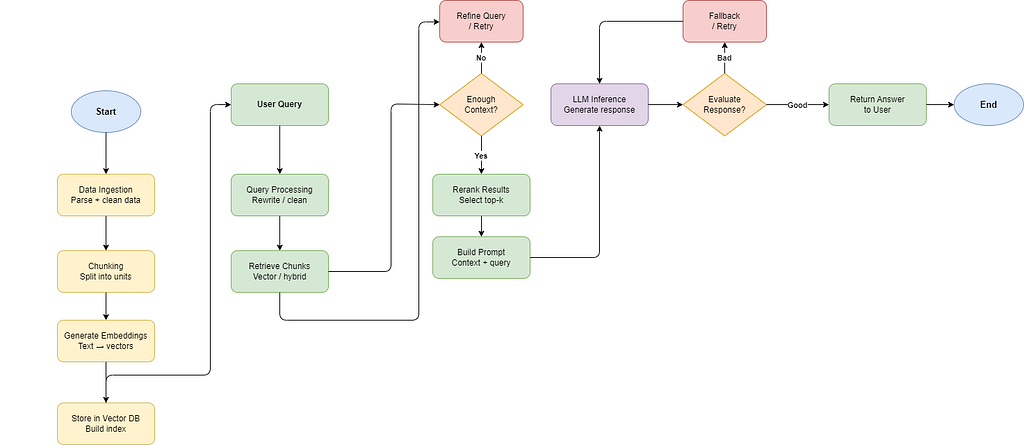
In regulated environments such as banking, these systems must also satisfy strict governance, auditability, and change-control requirements aligned with standards like SOX and PCI DSS.
This article builds on existing frameworks like 12 Factor Agents (Dex Horthy)¹ and Google’s 16 Factor App² by exploring key anti-patterns and introducing the pillars required to take a typical RAG pipeline to production.
I’ve included code snippets and examples to make things clearer.
Critical RAG Anti-Patterns
Following are the most common anti-patterns that can degrade performance in production.
- Vector-only Retrieval: Vector-only retrieval can miss exact matches for structured identifiers like part IDs, SKUs or policy codes as embeddings prioritize meaning over exact tokens, precision queries may fail.
- Stateful Inference Pods: Storing session history in local pod memory may cause data loss during routine re-deployments.
- Uniform Fixed-size Chunking: Applying fixed-size chunking across all document types for simplicity and ignoring document structure can degrade retrieval quality.
- Hardcoded Prompt Templates: Embedding prompts directly in code or variables makes them difficult to version-control, audit or roll back without a full code deployment.
- Reactive Cost Management: Lack of real-time token visibility leads to unnoticed cost spikes until they appear in billing.
- Offline-only Evaluation: Treating quality metrics such as RAGAS as one-time benchmarks instead of continuous production signals.
- Embedding Drift: Not frequently updating vector indexes can lead to poor retrieval performance .
- Late-adoption of Responsible AI: Treating bias, toxicity, and compliance as “checkboxes” to be addressed only after the system is already built.
The next section provides architecture guidance in form of 5 key pillars to handle the anti-patterns
Five design pillars
A robust RAG platform is defined by five foundational pillars that ensure reliability, scalability, and control. In the following sections we’ll cover the design patterns in details

Pillar 1: Platform Governance & Infrastructure Strategy
This pillar defines the infrastructure and organizational boundaries that prevent systems from interfering with each other.
P1.1 : Logical Resource Isolation
The framework suggests isolated namespaces and ResourceQuotas RAG workload running on k8s . This would prevent resource contention and performance issues in production under heavy load.
apiVersion: v1
kind: ResourceQuota
metadata:
name: ingestion-quota
namespace: rag-ingestion
spec:
hard:
requests.cpu: "8"
requests.memory: 32Gi
requests.nvidia.com/gpu: "2"
limits.cpu: "16"
limits.memory: 64Gi
P1.2 : Self-Service Provisioning via IaC and GitOps Scaffolding
Using GitOps-based scaffolding (e.g., Backstage), platform teams can provide preconfigured environments with observability, secrets, and quotas built in .This allows development team to provision resources required themselves leading to faster development cycles & quicker releases .
P1.3: Golden Path Templates
Every new agent is built from a standardized, pre-secured Helm chart that includes OpenTelemetry instrumentation, Redis connectivity, ConfigMap integration, Prometheus monitoring, and default network policies. This enables teams to deploy fully observable and compliant agents within a day.
P1.4: GitOps-Driven Governance
Every production change such as prompt templates or model versions etc is enforced through Git-based pull requests. No updates reach production without being committed to Git, ensuring full traceability and auditability in line with regulatory requirements such as SOX and PCI DSS.
P1.5: Service Catalog and Operational Visibility
Maintain a catalog of RAG components, including agents, APIs, SLAs, dependencies, data sources, and model configurations. For instance Backstage backed by ArgoCD, centralizes this information to provide a single source of truth for ownership, deployment status, and API contracts.
Pillar 2: Hardening the Functional Core
Treating RAG components as microservices by applying SRE and distributed systems principles.
P2.1: Unified Codebase
The prompts, retrieval pipelines, and logic should be treated as a single unit of change to avoid the reliability anti-pattern of fragmented repositories. By pinning all versions in pyproject.toml, it can be ensured that any incompatibilities are caught early in CI, guaranteeing a more stable production environment.
DEFINE versions in pyproject.toml:
prompt_version = "v4"
retrieval_pipeline = "1.2.0"
embedding_model = "text-embedding-3-small==1.0.0"
RULE: any change to prompt, pipeline, or model
- bump the version in pyproject.toml
- open a pull request
ON every pull request:
CI checks compatibility:
prompt_version <->retrieval_pipeline
retrieval_pipeline <-> embedding_model
IF mismatch:
FAIL build
STOP
IF all compatible:
PASS — merge and deploy
P2.2: Externalised Configuration
Store secrets in Vault and tuning parameters in ConfigMaps. Hardcoding runtime variables like temperature or top-k is a bottleneck and externalizing them enables zero-downtime tuning. For eg. adjusting a SIMILARITY_THRESHOLD via ConfigMap takes seconds, stays auditable, and avoids the cost of a full redeployment
P2.3: Stateless Execution
Since pods are ephemeral, all session state is offloaded to Redis with a 2-hour TTL. This prevents data loss during restarts or upgrades, making agents freely schedulable, horizontally scalable, and capable of zero-downtime deployments.
P2.4: Event-Driven Scaling
Scaling decisions are based on workload signals (eg queue depth) and not infrastructure metrics like CPU.
A retrieval pod may be near-idle on CPU while 5,000 queries queue up. Tools like KEDA lets you define a ScaledObject that triggers on rag_retrieval_queue_depth > 50 the metric that actually reflects load.
KEDA ScaledObject
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rag-retrieval-scaler
namespace: retrieval
spec:
scaleTargetRef:
name: retrieval-pod
minReplicaCount: 1
maxReplicaCount: 20
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus:9090
metricName: rag_retrieval_queue_depth
threshold: "50"
P2.5 : End-to-End Observability
Every reasoning step such as retrieval, reranking, model selection must produces an OTel span and traces . By using tracer.start_as_current_span() to capture chunk IDs, scores, and query variants, you transform “invisible” failures into actionable insights.
P2.6 : Chunking Strategy as an Architectural Decision
Chunking is how documents are split into smaller pieces for retrieval in a RAG system, directly impacting how well context and meaning are preserved. Poor chunking can break semantics and reduces answer quality. Hence it’s recommended to define a default strategy per document type and expose it as a versioned ConfigMap to ensure consistency, flexibility, and traceability
Pillar 3: Retrieval & Intelligence
The quality of your RAG system is determined not by the LLM alone, but by the precision of retrieval and the freshness of the knowledge base.
3.1: Query Rewriting
Query quality determines retrieval quality. The framework suggest to first rewrite several targeted variants of a query. Each variant addresses a specific dimension of the original question. All variants run in parallel, and the results are combined before being passed to the LLM.
The model does not change but retrieval input does. This maximizes accuracy without changing core model.
FUNCTION query_rewriter_agent(original_query):
# Step 1: Rewrite
variants = LLM.generate(
prompt = "Generate 4 precise search variants for: {original_query}"
)
// RAG retrieval latency optimisation techniques
// Vector database query performance bottlenecks
// Embedding model inference speed improvements
// Chunk size impact on retrieval performance
# Step 2: Retrieve in parallel
results = run_parallel(
FOR EACH variant IN variants:
vector_store.search(variant)
)
# Step 3: Union and deduplicate
chunks = deduplicate(results, key="chunk_id")
RETURN chunks
3.2: Knowledge as a Versioned Artifact
Enable Index Versioning to safeguard RAG quality. By linking Qdrant snapshots to git SHAs, you ensure that every vector update is reversible. This strategy transforms the vector index from a black box into a version-controlled asset that can be rolled back the moment performance degrades.
3.3 : Automated Accuracy Gates
RAGAS provides four quantitative measures computed automatically on every pull request:

Jenkinsfile enforces these thresholds means a quality regression fails the build before it reaches production.
Jenkinsfile RAGAS gate
stage('Quality Gate') {
steps {
sh 'python evaluate.py --output scores.json'
script {
def scores = readJSON file: 'scores.json'
if (
scores.faithfulness < 0.85 ||
scores.answer_relevancy < 0.80 ||
scores.context_recall < 0.75 ||
scores.context_precision < 0.70
) {
error "Quality gate failed: RAG scores below threshold"
}
}
}
}
3.4: Intelligent Model Routing
Efficiency in LLM deployments comes from Model Triage. By routing simple lookups to local or “Flash” models and saving premium models for complex reasoning, organizations can realize massive cost savings often 60% or more without impacting the end-user experience
3.5: Hybrid Search Strategy
Pure semantic search is excellent for conceptual queries but fails on exact matches such as Part IDs, SKUs, policy codes.
Combining dense vector search with BM25 sparse retrieval and a cross-encoder re-ranker over the fused top-k results gives you the best of both conceptual recall with exact-match precision.
3.6: Embedding Strategy
When you upgrade your embedding model, your entire search index becomes invalid . Treat it like a database migration by taking snapshot first, re-embed everything, then switch.
WHEN embedding model version changes:
1. SNAPSHOT current index
- Tag with Git SHA
- Store in GCS
2. RE-EMBED all documents
- Use new embedding model version from config
3. VALIDATE new index
- Run RAGAS evaluation
- IF scores fall below threshold:
→ ROLLBACK to previous snapshot
→ STOP deployment
4. SWAP traffic
- Route queries to the new index only after validation passes
3.7: Context Precision via Reranking
Integrating a cross-encoder re-ranking stage allows for a deeper semantic evaluation of the relationship between a query and retrieved documents. By refining the initial candidate pool into a highly relevant subset, this process optimizes the context window and minimizes the hallucination surface. Some of the popular models for re-ranking are Qwen3-Reranker-8B and BAAI/bge-reranker-v2-m3
Pillar 4: Action, Memory & Learning
Governing how agents act on the world, remember context over time, and evolve from feedback.
4.1: Protocol-Based Tooling (MCP)
All external tool access through a typed, audited MCP proxy with no direct DB credentials in the agent.
AGENT wants to query database or create Jira ticket:
WITHOUT MCP:
agent → database (direct credentials)
agent → Jira API (direct credentials)
// no validation, no audit trail, full blast radius
WITH MCP:
1. AGENT sends tool call to MCP server
{ tool: "query_db", params: { sql: "..." } }
{ tool: "create_ticket", params: { project: "..." } }
2. MCP server VALIDATES
IF sql contains DROP/INSERT/UPDATE/DELETE:
REJECT and log
IF jira project not in permitted_projects:
REJECT and log
3. MCP server EXECUTES
runs approved query against database
creates ticket in permitted project only
4. MCP server LOGS every tool call
{ agent_id, tool, params, result, timestamp }
5. RETURNS result to agent
agent sees result only
agent never sees credentials or network
4.2: Memory Architecture
An agent has two types of memory and they should never be mixed.
- Session memory — It is short-lived, scoped to one user, and does not need to outlast the session. This lives in Redis and expires after 2 hours.
- Persistant memory — It is the knowledge an agent needs across all sessions. This lives in Qdrant and persists indefinitely.
When a conversation grows too long and approaches the model’s token limit, the memory manager does not cut it off mid-thought. It summarizes what happened and carries the summary forward. Truncation loses context without warning. Summarization keeps the meaning.
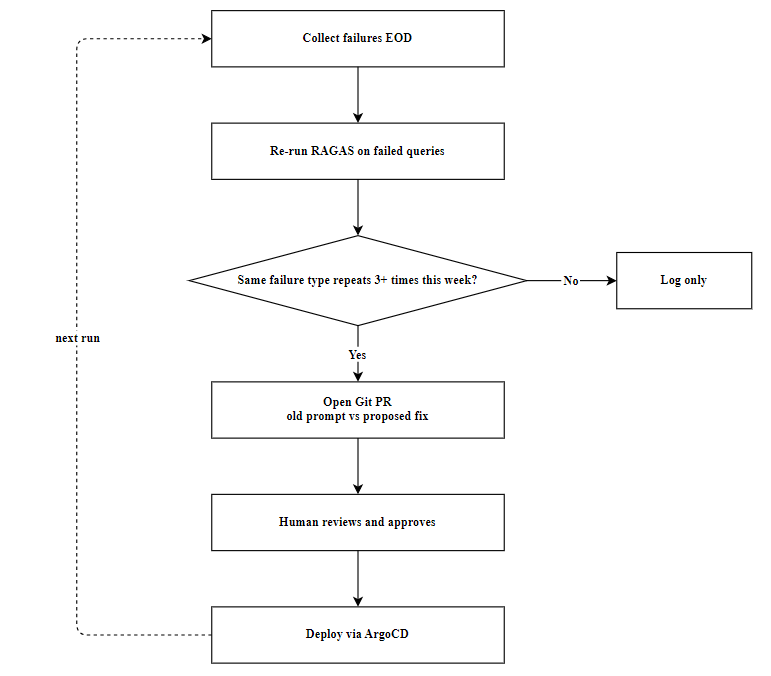
4.3: Continuous Feedback Loops
Implement automated feedback loops that aggregate production RAG failures and use LLM-as-a-Judge evaluation to trigger auditable prompt-fix PRs. Schedule recurring evaluations to identify recurring failure patterns, ensuring prompt optimizations are human-reviewed and deployed through continuous delivery pipelines.
Press enter or click to view image in full size
Pillar 5: Security, FinOps & Control
The guardrails that make enterprise deployment possible.
5.1: Policy-as-Code
Governance must be enforced programmatically.
A Rego rule that blocks PII-containing queries, enforces tenant-to-collection isolation, and caps query length is version-controlled, testable, and auditable. When a compliance requirement changes, you update a .rego file and open a PR.
OPA Rego rule
package rag.authz
deny[msg] {
input.query_length > 2000
msg := "Query exceeds maximum allowed length"
}
deny[msg] {
contains(input.query, input.tenant_id) == false
msg := "Tenant may only query their own collection"
}
deny[msg] {
regex.match(`\b\d{3}-\d{2}-\d{4}\b`, input.query)
msg := "PII detected in query - request blocked"
}
5.2: Supply Chain Security
Use Sigstore/Cosign to sign and verify every container image and model weight. CI pipeline must run cosign verify to validate these signatures before ArgoCD is allowed to sync to production to ensure that only verified images are promoted into production.
5.3: Financial Observability
Maintain real-time LLM cost control by attributing token usage to specific tenants and operations via Prometheus labels. Use Grafana dashboards to identify budget-draining inefficiencies, like unoptimized context windows, and trigger alerts before invoices escalate.
5.4: Chaos Engineering
Chaos engineering for RAG fallbacks validates system resilience by injecting controlled failures, such as re-ranker timeouts or LLM outages. This ensures the pipeline gracefully degrades to secondary search paths or cached responses without increasing the hallucination surface.
Kubernetes-native tools like Chaos Mesh and LitmusChaos inject network or pod failures to validate that RAG pipelines gracefully transition to secondary fallback paths.
These are often paired with evaluation frameworks like Ragas or DeepEval to ensure that fallback responses do not increase the hallucination surface during outages.
5.5: Network Security
Implementing Zero Trust networking ensures that all internal service-to-service communication is strictly identity-governed and fully encrypted by default. This ensures that only authorized workloads can communicate, and even if a network segment is breached, the data in transit remains private and unreadable in plaintext.
For instance, combining Cilium eBPF and Istio mTLS creates a “Zero Trust” network for internal traffic where Cilium acts as the gatekeeper, using identity-based policies to control which pods are allowed to talk to each other across namespaces.
From Models to Platforms
The framework is a comprehensive attempt to standardize RAG system. The idea is to move the conversation away from “which model is best” towards “how do we build a platform that makes any model reliable, observable, and cost-effective”
# Build a platform , not just prompts
References :
- https://github.com/humanlayer/12-factor-agents
- https://cloud.google.com/transform/from-the-twelve-to-sixteen-factor-app.
- CNCF AI TCG (2026), Cloud Native Agentic Standards — https://www.cncf.io/blog/2026/03/23/cloud-native-agentic-standards/
- RAGAS evaluation methodology (Es et al., 2023)
- Model Context Protocol (Anthropic, 2024)
- CNCF project tooling including KEDA, OpenTelemetry, Chaos Mesh, and Sigstore.
Production RAG: From Anti-Patterns to Platform Engineering was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.