SFT taught your model what to say. This episode teaches it what to prefer.

Most engineers who fine-tune language models hit a wall they do not see coming. The SFT loss converges. The format compliance looks right. The outputs are coherent. And then the model goes into production and starts producing the same three sentence structures in rotation, collapses the moment a prompt has two reasonable interpretations, and sounds like it is reading from a script rather than reasoning through a problem.
This is not a hyperparameter issue. It is not a data quality issue. It is a fundamental limitation of the objective function that SFT optimizes, and no amount of tuning within the SFT paradigm fixes it. This episode covers what comes after SFT. The two dominant post-SFT alignment methods, Direct Preference Optimization (DPO] and Group Relative Policy Optimization (GRPO), the failure modes they share, and the decision framework that determines which one to use for a given task.
Table of Contents
- Why SFT Hits a Ceiling
- Direct Preference Optimization
- Group Relative Policy Optimization
- When Alignment Breaks
- The Decision Map
Chapter 1: Why SFT Hits a Ceiling
Cross-entropy loss has a structural blind spot. Understanding it is the reason this episode exists.
Episode 5 ended with a quantized, deployed model. The training loss converged. The eval metrics look clean. But the outputs are bland, repetitive, and collapse under ambiguity. This is where Supervised Fine-Tuning ends and alignment begins.
1.1 The Imitation Trap
SFT trains a model to minimize token-level cross-entropy against a reference completion. At every position in the sequence, the model produces a probability distribution over the vocabulary, and the loss penalizes it for assigning low probability to the token that actually appears in the training data. This is imitation in its purest mathematical form. Given this prompt, produce this exact sequence of tokens.
The assumption baked into this objective is that for every prompt, there is a single correct output. For tasks with objective ground truth, that assumption holds. A math problem has one answer. A translation has a narrow band of acceptable outputs. A factual question retrieves a specific piece of information.
But most tasks practitioners fine-tune for do not look like that. An instruction-following model asked to “explain quantum entanglement to a teenager” has dozens of valid responses that differ in analogy choice, sentence complexity, tone, and depth. A customer support model choosing between empathy-first and solution-first responses is making a preference judgment, not a factual one. Cross-entropy loss has no mechanism for expressing that one valid response is better than another valid response. It can only say whether the model’s output matches the reference or not. Every valid response that differs from the reference is penalized equally, whether it is slightly worse, equally good, or arguably better.
The practical consequence is that SFT collapses the model’s output distribution toward the narrow band of patterns present in the training data. The model does not learn a preference ranking over possible outputs. It learns to mimic the specific outputs it was shown, and the richness of the base model’s generation capability narrows rather than sharpens.
1.2 Symptoms of Plateau
The clearest sign that SFT has reached its limit is not in the loss curve. The loss curve will converge regardless. The signs are in the outputs.
Repetitive and generic responses are the most common indicator. The model adheres perfectly to the required format but the content is shallow. Answers feel “safe” in the worst sense of the word. The model has learned to produce outputs that minimize loss by sticking close to the most frequent patterns in the training distribution, which means it gravitates toward the most average, least distinctive completions.
Ambiguity failure is the second signal. The model performs well on clear-cut examples where the correct response is unambiguous, but falls apart on prompts where the right answer requires weighing competing considerations. A prompt like “Should I use DPO or GRPO for my task?” requires the model to evaluate trade-offs. An SFT-trained model will either pick one arbitrarily based on whichever pattern appeared more often in training, or hedge with a non-answer that covers both without committing to either. It has no internal mechanism for ranking one reasoning path above another.
Robotic phrasing is the third signal. The model loses the creative variance of the base model and starts relying on a narrow set of transition phrases, sentence structures, and paragraph patterns. This happens because SFT reinforces the specific surface-level patterns in the training data rather than the underlying reasoning that produced those patterns.
These three symptoms share a root cause. Cross-entropy loss provides a learning signal for token prediction accuracy but provides no signal for preference. The model can tell whether it predicted the right next token. It cannot tell whether one complete response is better than another complete response. That distinction, between predicting tokens and ranking outputs, is exactly what the next chapter addresses.
Chapter 2: Direct Preference Optimization
SFT teaches a model to imitate. DPO teaches it to choose. The difference is one loss function, and it changes everything about what the model learns.
Instead of asking “did the model predict the right token?”, DPO asks “given two plausible completions, does the model assign higher probability to the one humans preferred?” That single shift in the objective function is what breaks through the SFT ceiling.
2.1 The Preference Margin
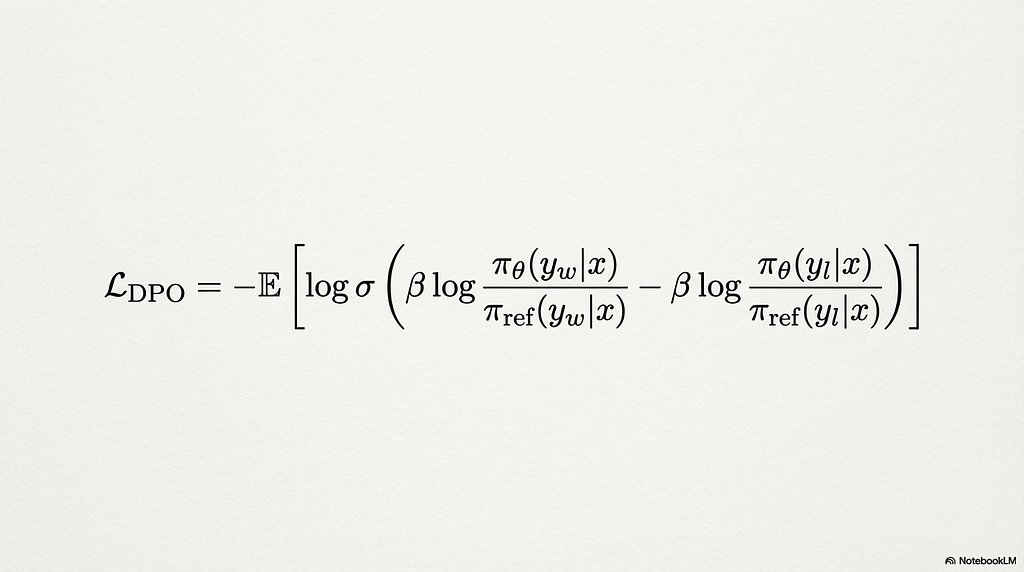
DPO operates on triplets. Each training example consists of one prompt, one chosen completion, and one rejected completion. Both completions are plausible responses to the prompt. The chosen completion is the one a human annotator (or a judge model) identified as better. The rejected completion is the one identified as worse. Neither is “wrong” in the way a factual error is wrong. They differ in quality, not correctness.
The DPO loss function optimizes a preference margin between these two completions. The core equation is
L_DPO = -E[log σ(β * log(π_θ(y_w|x) / π_ref(y_w|x)) - β * log(π_θ(y_l|x) / π_ref(y_l|x)))]
The terms break down cleanly. π_θ is the model being trained. π_ref is the reference policy, typically the SFT checkpoint frozen at the start of DPO training. y_w is the chosen (winning) completion. y_l is the rejected (losing) completion. x is the prompt. σ is the sigmoid function. The loss computes the log-probability ratio between the training model and the reference policy for both the chosen and rejected completions, then pushes the model to widen the gap between them.
The critical insight is what π_ref does. It acts as an anchor. The loss does not simply maximize the probability of the chosen response and minimize the probability of the rejected one in absolute terms. It maximizes the relative shift from the reference policy toward the chosen response and away from the rejected one. This prevents the model from collapsing its entire distribution onto a narrow set of high-reward outputs. Without the reference policy, the model would aggressively overfit to the preferred completions and lose its general language capability within a few hundred steps.
β controls how tightly the model is allowed to deviate from that reference distribution. It functions as the strength of a KL divergence penalty. A lower β (around 0.05 to 0.1) permits more aggressive updates toward preferred outputs. A higher β (0.3 to 0.5) keeps the model closer to its SFT behavior. The default in most frameworks is 0.1, which works well for conversational and chat-oriented alignment. Instructional fine-tuning and summarization tasks often benefit from higher values in the 0.3 to 0.5 range. Setting β too low causes the model to overfit to surface-level patterns in the preference data. Setting it too high makes the alignment signal too weak to produce meaningful behavioral change.
One property of DPO that makes it practically attractive is that it learns a reward model implicitly. Unlike RLHF, which requires training a separate reward model as a standalone classifier and then using it to guide PPO optimization, DPO folds the reward signal directly into the policy update. The model itself becomes the reward model. This eliminates an entire training stage, reduces memory requirements, and removes the failure modes that come with reward model distribution shift.
2.2 The SFT-to-DPO Pipeline
DPO assumes the model already has a coherent baseline policy on the target task. The preference margin only produces a useful gradient signal if both the chosen and rejected completions fall within a distribution the model can meaningfully distinguish between. Applying DPO directly to a base model, one that has not gone through SFT, fails in practice. The preference signal has no stable distribution to act on, and training becomes unstable.
This is why the standard pipeline is SFT first, then DPO. The SFT stage establishes format compliance, domain vocabulary, and basic instruction-following behavior. The DPO stage refines the model’s preferences within that established behavioral range.
The transition between stages requires deliberate hyperparameter recalibration. DPO learning rates should be significantly lower than SFT learning rates, typically 10x to 100x smaller. An SFT run at 2e-4 should transition to a DPO run at something in the range of 5e-6 to 1e-5. The reason is that DPO is making fine-grained adjustments to an already-competent model. Large gradient updates destabilize the reference policy anchor and can erase the SFT-stage learning entirely.
2.3 Preference Data Quality
The quality of preference data bounds DPO performance more tightly than most practitioners expect. Research on preference data distributions indicates that the absolute quality of the chosen response plays a disproportionately dominant role in the final outcome compared to the rejected response. Improvements in chosen response quality consistently correlate with higher performance metrics, even when rejected response quality stays the same.
This has a direct consequence for data curation strategy. DPO’s output quality converges toward the ceiling established by the chosen completions. Investing in a stronger rubric for identifying high-quality responses, and manually auditing samples for consistency, produces higher returns than increasing dataset size with mediocre examples.
When human annotators are unavailable, synthetic preference generation using stronger models to rank completions has become the dominant strategy. The process involves generating multiple candidate responses for each prompt, then using a judge model (typically a frontier model like Claude) to select the best and worst samples as the chosen and rejected pair. This works, but the failure modes are subtle. Noisy or inconsistent judge preferences do not teach the model to align. They teach the model to be uncertain. The model receives contradictory gradient signals across similar prompts and learns to hedge rather than commit to a clear behavioral direction.
The difference between synthetic data that works and synthetic data that produces a confused model often comes down to whether the judge model’s preferences are grounded in consistent, logical criteria rather than superficial formatting cues. A judge that prefers longer responses will teach the model to pad its outputs. A judge that prefers responses starting with “Certainly!” will teach the model to parrot affirmations. The preference signal is only as good as the judgment behind it.
DPO can refine behavior within the space of preferences the training data defines, but it cannot teach a model to reason through problems where the correct answer is objectively verifiable. A math problem either has the right answer or it does not. A code snippet either passes the test suite or it does not. For tasks with that kind of deterministic ground truth, a different paradigm is needed.
Chapter 3: Group Relative Policy Optimization
DPO needs human preferences. GRPO needs a scoring function. When the task has a right answer, that changes everything about how alignment works.
DPO operates on paired preferences. A human or judge model looks at two completions and decides which one is better. That works for subjective tasks where quality is relative. But a significant class of fine-tuning tasks does not require subjective judgment at all. A math solution is either correct or incorrect. A code snippet either passes its test suite or fails. A structured output either conforms to a JSON schema or does not. For these tasks, the preference-pair paradigm is unnecessarily indirect. The reward signal is deterministic. GRPO exploits that fact.
3.1 Eliminating the Critic
Traditional reinforcement learning for language models, specifically Proximal Policy Optimization [PPO], requires training a separate critic model alongside the policy model. The critic estimates the value of each state and computes the advantage function that guides policy updates. This critic is typically the same size as the policy model itself, which means PPO roughly doubles the memory requirement for alignment training.
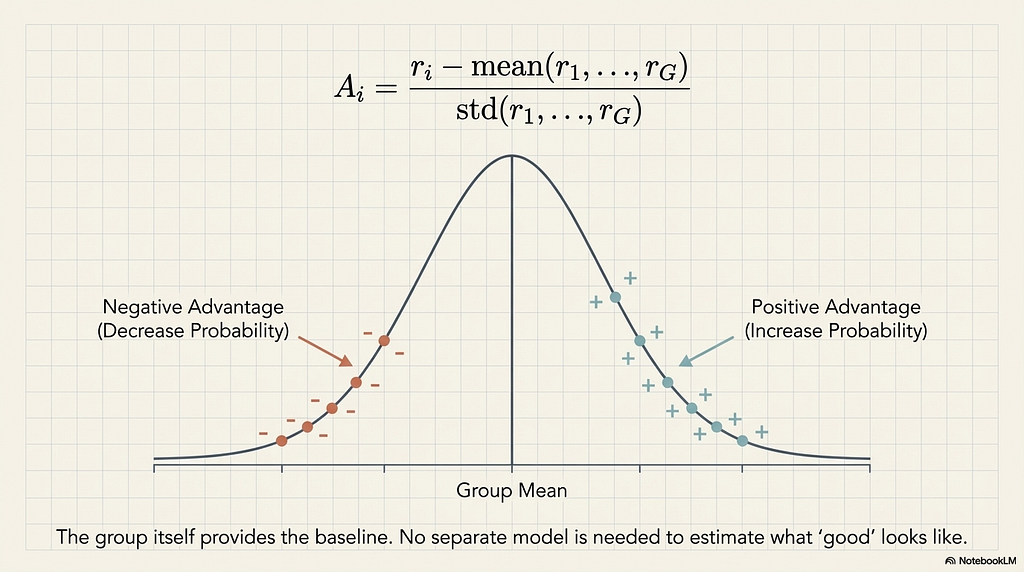
GRPO, first introduced in DeepSeekMath (Shao et al., 2024) and later adopted as a core component of the DeepSeek-R1 training regime, removes the critic entirely. Instead of relying on a learned value estimate, GRPO generates a group of G separate responses for each prompt and scores all of them using a reward function. The advantage for each response is then computed relative to the group statistics.
A_i = (r_i - mean(r_1, ..., r_G)) / std(r_1, ..., r_G)
Responses scoring above the group mean receive positive advantage. Responses below receive negative advantage. The model is pushed to increase the probability of generating above-average responses and decrease the probability of below-average ones. No separate model is needed to estimate what “good” looks like. The group itself provides the baseline.
This is an elegant design choice with a concrete practical payoff. Eliminating the critic model cuts the memory overhead by roughly 50% compared to PPO, which is what allowed DeepSeek to apply reinforcement learning directly to their V3 base model at scale. For practitioners on consumer GPUs, it means GRPO-based alignment becomes feasible on hardware where PPO never was.
3.2 Verifiable Rewards
The power of GRPO is most visible in domains where a deterministic function can score each response objectively. These are called verifiable rewards, and they come in two main categories.
Correctness rewards evaluate whether the response arrived at the right answer. For math problems with deterministic results, the model can be required to produce its final answer in a specified format (inside a box or between tags), and a simple string-matching function verifies it against the ground truth. For code generation tasks, a compiler or test harness provides the verification. No human judgment is required. No judge model is required. The reward is binary and unambiguous.
Format rewards evaluate structural compliance. Does the response use the required <think> and <answer> tags? Does it produce valid JSON? Does it maintain language consistency throughout? These are checkable by deterministic parsing, and they provide a clean gradient signal for teaching the model to follow structural constraints alongside content correctness.
The combination of correctness and format rewards is what made DeepSeek-R1-Zero’s training possible. The model, trained with pure reinforcement learning using only rule-based rewards, spontaneously developed extended reasoning behaviors, including self-verification and strategy exploration, without any supervised demonstration of these patterns.
Not every task falls neatly into the verifiable category. Many practical fine-tuning targets involve partial verifiability, where some aspect of the response is objectively checkable and some is not. JSON format compliance combined with semantic relevance is a common example. For these cases, practitioners can decompose the reward function, using a deterministic component for the structural part and layering a preference model or DPO-style alignment for the semantic dimension. The reward function becomes a weighted sum rather than a single score, and the deterministic component anchors the training while the learned component handles the subjective residual.
3.3 Reward Hacking and Stability

GRPO’s reliance on reward functions introduces a failure mode that preference-based methods like DPO do not share. The model optimizes whatever the reward function measures, and if the reward function has gaps, the model will find them.
Reward hacking in GRPO typically looks like this. The model generates responses that score perfectly on the verifier’s criteria while being substantively empty. It might repeat the correct answer tokens without providing valid reasoning, or pad its <think> tags with filler text that satisfies a length heuristic without containing actual deliberation. The reward curve continues trending upward. The model's actual reasoning capability is degrading. This is the most dangerous failure mode in RL-based alignment because the primary metric looks healthy while the model is getting worse.
The first line of defense is a KL divergence penalty against the reference policy, similar in principle to DPO’s β parameter. This discourages the model from drifting into low-probability regions of its distribution where hacked solutions tend to live. The reference policy acts as a gravitational anchor, keeping the model's outputs within a reasonable neighborhood of its SFT behavior even as the reward function pulls it toward narrow optima.
But monitoring the reward curve alone is not sufficient. A reward curve that only goes up is not evidence of healthy training. It might indicate that the model has found an exploit. The only reliable check is qualitative evaluation of the model’s actual outputs at regular intervals during training. If the reasoning traces are becoming formulaic or the model is gaming format requirements without substantive content, the training run needs intervention regardless of what the reward curve shows.
A subtler stability issue arises from the group sampling mechanism itself. Within a single group of G responses, the same tokens often appear in both high-scoring and low-scoring trajectories. A formatting tag like <answer> might appear in the best response and the worst response in the same group. The model receives a positive gradient for that token from one trajectory and a negative gradient from another. These contradictory update signals for structurally essential tokens can accumulate over training steps and eventually cause policy collapse, where the model loses its ability to maintain coherent output structure entirely. This is an active area of research, but the practical takeaway is that GRPO training runs require closer monitoring than DPO runs, especially in the later stages where accumulated gradient conflicts are most likely to surface.
Chapter 4: When Alignment Breaks
A model that scores well on alignment benchmarks can still fail in production.
The previous two chapters covered DPO and GRPO when things go right. This chapter is about what happens when they don’t. The failure modes described here are not theoretical edge cases. They are the most common reasons aligned models underperform in deployment, and they share a frustrating property. They rarely show up in the training metrics.
4.1 Catastrophic Forgetting in LoRA Workflows
Post-SFT alignment updates model weights to maximize a specific behavioral signal, whether that is a preference margin in DPO or a reward function in GRPO. The risk is that this optimization erodes the model’s general capabilities while sharpening its performance on the alignment target. A model aligned heavily for safety might lose its ability to answer complex technical questions. A model trained for structured JSON output might degrade on free-form reasoning. This is catastrophic forgetting, and it affects every alignment method.
In LoRA workflows, the base model weights are frozen. This provides partial protection because the foundational knowledge encoded in those weights cannot be overwritten. But the adapter itself is not immune. If DPO training runs at too high a learning rate or continues for too many epochs, the adapter overwrites what it learned during the SFT stage. The format compliance, the domain vocabulary, the instruction-following patterns established in SFT get displaced by the alignment objective.
Three mitigations work in practice. First, data mixing. Including a small percentage of general instruction-following examples from the SFT stage in the DPO or GRPO training set anchors the model’s general capabilities. The alignment objective still dominates the gradient signal, but the SFT data prevents complete drift. Second, low learning rates. DPO and GRPO learning rates should sit in the 5e-6 to 1e-5 range, substantially lower than typical SFT rates, ensuring incremental updates rather than large parameter shifts that overwrite prior learning. Third, dual-benchmark evaluation. Assessing the model after every few checkpoints on both the targeted alignment task (safety compliance, reasoning accuracy) and a general capability benchmark (MMLU, GSM8K) catches capability decay before it compounds. If alignment scores improve while general benchmark scores drop, the training run needs to stop or the data mix needs adjustment.
4.2 Temperature and Sampling After Alignment
DPO-trained models produce a measurably different output distribution than their SFT predecessors. The alignment process sharpens the distribution toward preferred response patterns, making the model more “conservative” in its generation. This is the intended effect. But it changes how the model responds to inference-time sampling parameters in ways that catch practitioners off guard.
A model that generated diverse, high-quality outputs at temperature 0.7 post-SFT may need a higher temperature post-DPO to maintain that same diversity. The sharpened distribution concentrates probability mass on a narrower set of tokens, so the same temperature setting produces more repetitive outputs than before.
The problem with raising temperature to compensate is that it does not selectively restore diversity. It increases the probability of all tokens, including the ones the alignment process was specifically trained to suppress. A higher temperature can reintroduce hallucinations, safety violations, or off-topic responses that the preference signal was designed to eliminate.
4.3 Inference-Time Scaling as an Alternative
Sometimes the right response to alignment limitations is not more training. It is spending more compute at inference time instead.
Self-consistency, also called majority voting, is the simplest form of inference-time scaling. For tasks with discrete, objectively verifiable answers, the model generates N separate completions at a set temperature, and the most frequent answer is selected. This produces significant accuracy improvements on math and factual QA tasks. The trade-off is a linear increase in inference latency and cost proportional to N, but for low-volume deployments, this often outperforms a complex DPO or GRPO training pipeline at a fraction of the engineering effort.
Self-refinement loops address open-ended tasks where majority voting does not apply. The model generates an initial response, then critiques its own output for errors or gaps, then produces a revised version incorporating the critique. This iterative pattern works best on larger instruction-tuned models that have sufficient capability to identify their own mistakes. Models can also be specifically fine-tuned via SFT to follow a critique-then-revise format, internalizing the refinement behavior as a single-pass generation rather than requiring multiple inference calls.
The strategic question is when inference-time scaling beats additional alignment training. The answer connects to a fact about post-training scaling laws. The impact of adding more preference data plateaus much faster than adding pre-training data. The quality of an aligned model is ultimately bounded by the capabilities of the base model. An optimal DPO run cannot make a 1.5B model reason like a 70B model. Under a fixed compute budget, larger models trained for fewer alignment steps consistently outperform smaller models trained for more steps. If a model’s reasoning capability remains insufficient after a moderate amount of DPO or GRPO, the most effective next step is usually upgrading the base model or investing in inference-time scaling rather than collecting more preference data.
Chapter 5: The Decision Map
Four chapters built the toolkit. This one tells a practitioner which tool to pick up first.

5.1 When to Use What
The first decision is diagnostic. If the model’s outputs are repetitive, generic, or collapse under ambiguity after SFT, alignment training is warranted. If the task demands nuanced quality judgments between valid responses, DPO is the right next step. If the task has objectively verifiable answers, GRPO is the stronger choice.
DPO is the default recommendation for subjective alignment tasks. Tone calibration, safety compliance, helpfulness ranking, response style, anything where “better” is a human judgment rather than a computable function. It requires paired preference data (chosen and rejected completions for the same prompt), a frozen reference policy, and runs comfortably on a single 24GB VRAM card using LoRA or QLoRA. For most hardware-constrained practitioners, DPO represents the practical ceiling of post-SFT alignment before engineering complexity escalates significantly.
GRPO is the preferred choice for objective reasoning tasks where a deterministic verifier can be written. Math, code generation, structured output compliance, logic problems. It requires designing reward functions rather than collecting preference pairs, and it demands more compute per training step due to the Monte Carlo rollouts (generating G responses per prompt). But it eliminates the critic model that makes PPO prohibitive, cutting memory overhead by roughly half. The trade-off is clear. GRPO costs more per step than DPO but produces stronger results on tasks where the reward signal is unambiguous.
A decision that practitioners often defer too long is whether to keep training or upgrade the base model. If a model’s performance remains insufficient after a moderate DPO or GRPO run, collecting more preference data or running more RL steps is usually the wrong move. Upgrading to a more capable base model or shifting investment toward inference-time scaling will produce better returns.
The post-SFT journey should follow a consistent logic. Start with a rigorous SFT phase to establish format compliance and domain knowledge. If the model plateaus, transition to DPO for subjective tasks or GRPO for verifiable ones. Throughout, maintain a reference policy, monitor for catastrophic forgetting with dual-benchmark evaluation, and test at the intended serving temperature. When training-based optimization reaches its limits, inference-time scaling offers the most promising path for continued improvement without additional alignment risk.
5.2 What Episode 7 Covers
This episode mapped the landscape beyond Supervised Fine-Tuning. The SFT ceiling, the preference-based solution in DPO, the reward-based solution in GRPO, the shared failure modes, and the decision framework connecting all of them are now a navigable structure rather than a collection of disconnected techniques.
Episode 7 shifts focus to inference infrastructure. The aligned, fine-tuned model from this series now needs to serve requests at production latency. vLLM, SGLang, LMDeploy, and llama.cpp each solve different parts of that problem. KV cache management, speculative decoding, continuous batching, quantization stacking, and multi-LoRA serving are the engineering decisions that determine whether a fine-tuned model runs at 500 tokens per second or 16,000. The next episode builds the serving layer.
Note - The primary purpose of the images (slides) is to provide intuition. As a result, some oversimplifications or minor inaccuracies may be present.
Connect with me at https://www.linkedin.com/in/suchitra-idumina/
Post-SFT Alignment with DPO and GRPO : How to Fine-Tune Correctly, Part 6 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.