
How ontology-based models give businesses the semantic foundation to scale AI, analytics, and decision-making consistently.
Most organizations today are not struggling to collect data. They are struggling to make data mean the same thing across every system, team, and tool that consumes it.
That gap between data that exists and data that is understood, is exactly where ontology steps in. And as AI becomes central to how businesses operate, closing that gap is no longer a nice-to-have. It is foundational.
AI can access your data, but without shared meaning, it’s just sophisticated guessing. Data ontologies solve this by creating a machine-understandable vocabulary of your business — entities, relationships, and rules — that powers growth, scalability, and intelligent analytics.
To understand how ontology-based models drive growth, we first need to understand the framework. Let’s first understand the framework!
What is Data Ontology?
A data ontology is a formal, structured representation of knowledge within a specific domain. It defines the concepts that exist in your business, the attributes that describe them, and the relationships that connect them, forming a shared, machine-understandable vocabulary.
Unlike a data model, which defines structure and format, an ontology defines context and meaning.
Its all about knowledge, machine-understandable vocabulary, consistency of data to enable AI
It goes beyond simple schema design by adding semantic layers: ensuring that “Product” means the same thing in your ERP, your analytics platform, your AI pipeline, and every team that touches the data.
Ontologies encode business meaning explicitly. They sit atop physical storage (DBs, warehouses, lakes) as a reusable semantic layer, enabling knowledge graphs, semantic search, and AI workflows without duplicating data.
The core components of a data ontology are:
- Entity Types: Reusable logical models of real-world concepts (Product, Order, Shipment). Each entity type standardizes the name, description, identifiers, and constraints for that concept, so every team across the business is working from the same definition.
- Entity Instances: The actual occurrences of an entity type, populated from data bindings. They track which sources created them, when they were valid, and how they participate in relationships.
- Properties: Named facts about an entity with a declared data type, bound to source fields and enriched with semantic metadata. Properties enforce consistent types, units, and naming across systems.
- Relationships: Directional links between entity types or instances that carry explicit semantic meaning, not just a technical join
You can also think of an ontology as your business context layer: a catalog of concepts defined once and reused everywhere, backed by data bindings that connect those concepts to your actual sources, represented as a graph for richer navigation and reasoning, and exposed through a query surface that lets you ask questions about business entities rather than raw tables.
Ontology in Your Data Model
Once defined, an ontology is bound to your data making it possible to query and visualize information in the context of what it actually means to your business.
Unlike traditional data models, which define structure and format, ontologies define context and meaning.
This distinction has direct consequences for AI. Data ontology is what enables knowledge graphs and semantic search, both of which serve as the backbone for intelligent analytics and AI reasoning. Rather than inferring meaning from table structures and column names, ontology-based models represent data by defining business terms, relationships, and governance rules explicitly.
Instead of modeling data as a flat structure of tables, keys, and joins, ontology-based models describe:
- What things are
- How they are related
- Under what conditions those relationships are valid
- The occurrences in which those relationships apply
Critically, ontology-based data models sit on top of physical data. They do not replace databases, warehouses, or storage systems. They provide a semantic structure that translates raw data into a consistent, interpretable representation that can be reused across analytics, applications, and AI systems.
Rather than embedding logic in queries, pipelines, or dashboards, meaning is encoded directly into the model itself as defined concepts, relationships, and constraints.
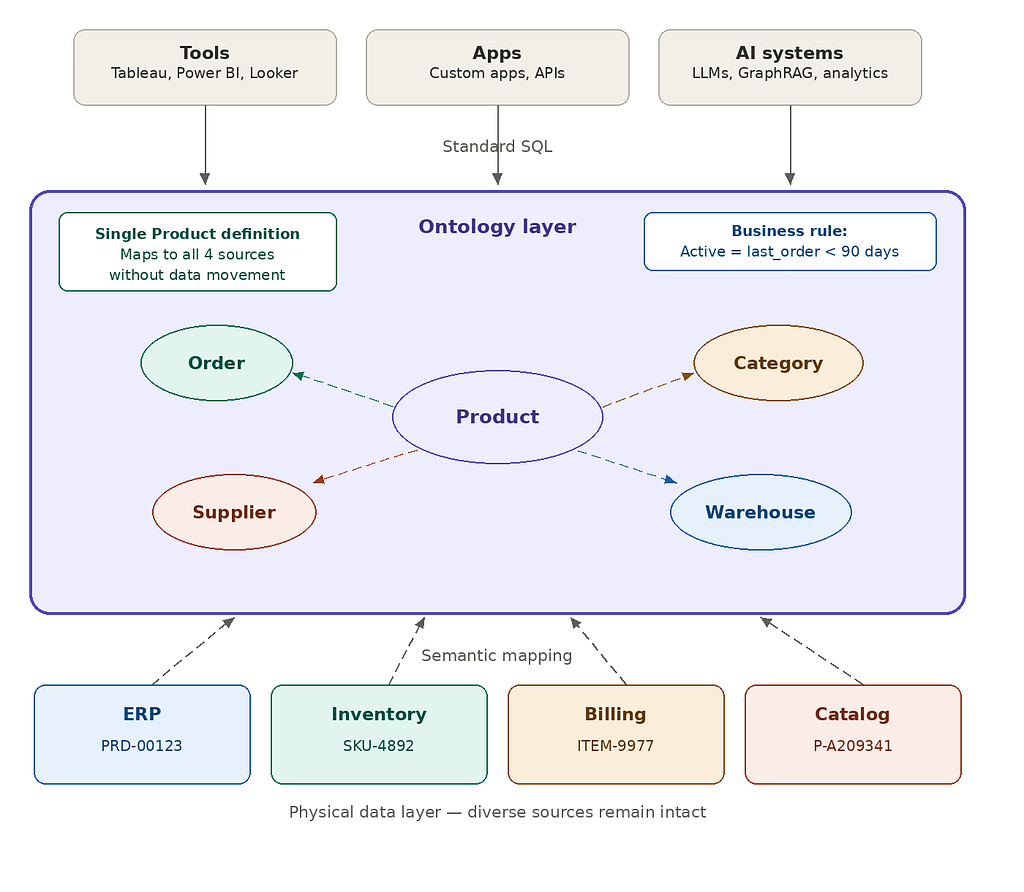
A Practical Example: The Product Entity
Consider the Product entity in a mid-size manufacturing or retail business. It likely lives in multiple systems simultaneously:
- ERP uses Product_ID
- Inventory uses Unit_of_Measure
- Billing uses Unit_Price
Each system has its own schema, its own identifiers, and its own update cycles.
In a table-centric model, these are treated as separate entities that must be joined, reconciled, or duplicated. Analysts end up choosing which system to trust depending on the context of their analysis. Teams attempt to stitch together a unified view for every use case; separately, inconsistently, repeatedly.
An ontology-based model defines Product as a single, authoritative concept and maps each system's identifiers and attributes to that concept explicitly. The result: a data scientist and a finance analyst are now working from the same definition of Product — no reconciliation meeting needed. Product is queried as a business entity, not as a collection of loosely related tables.
Ontology vs. MDM: The Critical Difference Most Miss
A common reaction at this point is: “Isn’t this just Master Data Management?” It isn’t — and the distinction matters more than most people realize.
MDM focuses on creating a single, trusted record for each entity. It ensures there is one canonical Product ID 12345, deduplicates records, and enforces data quality. It answers the question: is this data clean and consistent?
Ontology-based models answer a different question entirely: what does this data mean, and how does it relate to everything else?
Where MDM produces a golden record, ontology produces shared understanding. Where MDM maintains static hierarchies, ontology enables a dynamic graph that AI agents can navigate, reason over, and apply rules against.
MDM is built for BI and reporting. Ontology is built for AI, agents, and intelligent workflows.
The two are complementary, not competing. Think of it this way: ontology defines what Product semantically means; its relationships, rules, and context. MDM populates clean, trustworthy instances of that concept. You need both. But without ontology, even perfect MDM data will confuse an AI model. It may have a clean record, but no understanding of whether that product is active, which customers buy it, or what category it belongs to under current business rules.
MDM gives AI trustworthy records. Ontology gives AI the understanding to use them.
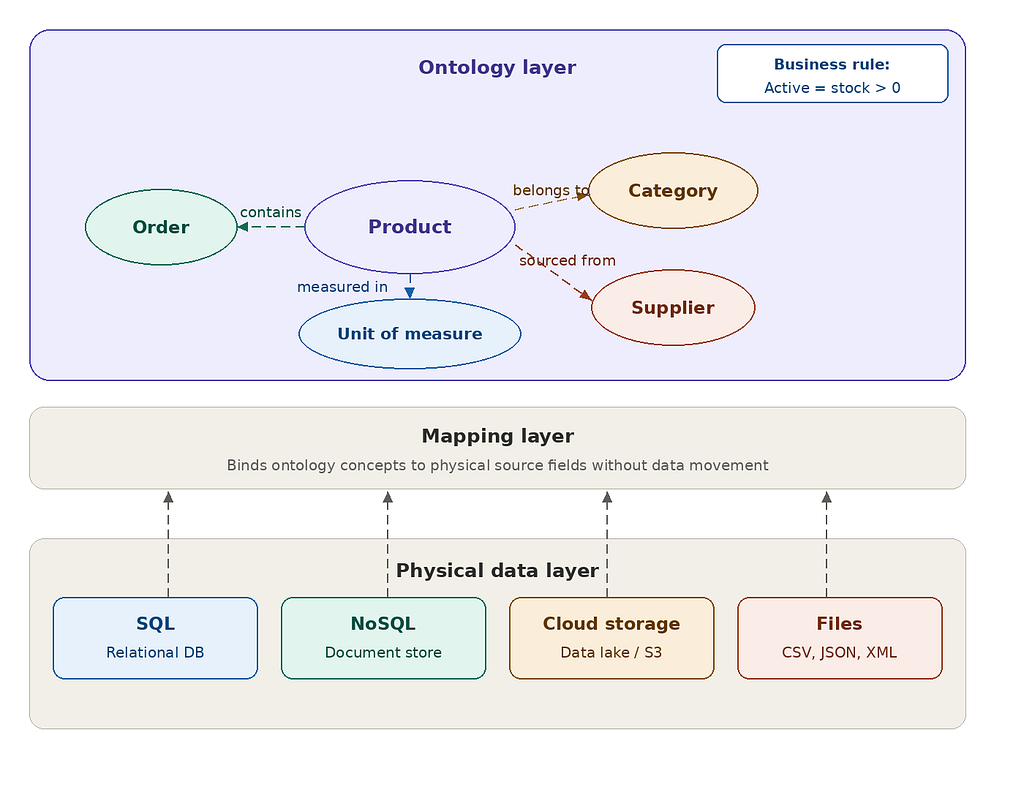
Declaring Relationships
Traditional schema-based approaches depend on table structures, naming conventions, and logical joins to capture business meaning, and assume those conventions are sufficient. Ontology-based models take a different stance: relationships are explicitly declared and semantically named.
For example:
- Product belongs to Category
- Product contains in Order line items
- Product sourced from Supplier
Each relationship carries semantic purpose. It describes what a connection means, not only how two tables are technically joined.
This distinction becomes critical when multiple relationships exist between the same entities. In schema-based models, ambiguity is resolved at query time , often inconsistently, differently across tools and teams. Ontology-based models treat each relationship as a distinct, intentional construct that can be governed, constrained, and reused.
Semantic purpose is encoded directly in the model. Systems no longer need to guess which relationship applies.
Business Meaning and Encoded Constraints
Ontology-based models do more than name relationships, they encode the rules that govern when data is valid, meaningful, or usable in a given context.
Constraints in an ontology may express:
- Cardinality: One-to-one, one-to-many
- Optionality: Required vs. optional relationships
- Validity conditions: when a relationship holds true
- Classification rules: How entities are categorized
- Access restrictions: Who can query what
For example: the relationship Order contains Product in its line items is mandatory, an order must have products. But Product belongs to Category is optional, not every product is categorized.
By embedding these constraints directly into the model, ontology-based systems enforce business meaning consistently across every tool, team, and AI system that consumes the data.
Ontology as a Governed Vocabulary
An ontology functions as a governed vocabulary for the entire business:
- Concepts are defined in business terms, not technical ones
- Relationships are named and intentional
- Constraints express rules and boundaries
- Definitions are shared, versioned, and reusable
This vocabulary becomes the common language across systems, teams, and tools. When any definition changes; say, the business redefines what “Active Product” means, it is updated once at the model level and propagates automatically. Every downstream system inherits the updated definition without requiring individual updates to pipelines, dashboards, or queries.
Consistency is enforced by design, not by process.
Ontology-Based Models vs. Traditional Data Models

Where traditional models are designed to organize and store data efficiently, ontology-based models are designed to represent business meaning explicitly and make that meaning reusable across every consumer.
This distinction becomes significant as data environments grow and consumption patterns extend beyond reporting into AI applications, workflows, and real-time decision systems.
ERD and schema-centric models are optimized for storage and retrieval. They are not designed to represent high-level business semantics, especially when multiple semantic relationships exist between the same entities. That is exactly where ontology-based models are built to operate.
Why Query-Level Semantics Eventually Break
Many organizations try to layer meaning on top of schemas using views, joins, and calculated fields. This works in the short term. Over time, it fragments.
Each consumer ends up maintaining their own interpretation of the data. Definitions diverge across teams. A simple question; “how many active products do we have?”, produces different answers depending on who ran the query and which system they queried.
Ontology-based models move semantic definitions out of queries and into a shared structure that all consumers rely on, eliminating duplication, reducing drift, and lowering long-term operational risk.
Ontology vs. Metadata Catalogs
It is worth distinguishing ontology-based models from metadata catalogs, as these are often conflated.
Metadata catalogs document schemas, datasets, ownership, and lineage. They are valuable reference systems for discovery and governance, but they primarily describe data rather than define how it should be interpreted or used.
Ontology-based data models are operational. They are used directly in querying, analytics, and AI workflows. Meaning is not just documented, it is enforced and executed consistently wherever data is consumed.
The Compounding Value of Ontology-Based Models
Business definitions are not static. They change as the business grows, regulations shift, and operating models evolve.
In a traditional setup, every definition change ripples through dozens of downstream systems, pipelines, and dashboards, each requiring individual updates, each carrying risk of inconsistency.
In an ontology-based model, updated logic is redefined once at the concept level. All consuming systems inherit the change automatically. The ontology is exposed through standard SQL interfaces, allowing it to be reused consistently across BI tools, data science workflows, APIs, and AI systems without reimplementation or translation into tool-specific formats.
Ontology in AI Analytics
Organizations are racing to embed AI into their workflows, analytics, and applications. But one factor is consistently underestimated: language.
The ability of an AI system to generate value, to reason correctly, to surface insights that are trustworthy, to align with how the business actually thinks depends entirely on whether it understands the language of your business.
What does “active” mean in your context? What counts as a “completed order”? How is “revenue” defined across your product lines? These are not engineering questions. They are business language questions. And without a formal answer to them, AI cannot reason reliably over your data.
Ontology does not just power AI. It enables alignment.
This is where ontology becomes the critical infrastructure layer. By creating a shared understanding across data, teams, and tools, ontology becomes the foundation for collaboration between human decision-makers and AI systems.
Ontology is the memory layer AI depends on. It creates a shared memory for AI systems, embedding the business truth that people rely on, making AI not just functional, but fluent in your industry, your language, and your logic.
In practice, a well-defined ontology enables:
- A business-aligned AI layer: Not just a smarter search box, but a system that reasons within your actual business context
- A controlled vocabulary that evolves with your organization, so AI remains accurate as the business changes
- A foundation for explainable AI: critical in regulated industries where decisions must be auditable
- Scalable semantic understanding across regions, languages, and teams
- A single source of truth for business logic, shared by humans and machines alike
Closing Thoughts
The question is no longer whether your organization will use AI. It is whether the AI you use will be grounded in what your business actually means.
Ontology-based models move semantic definitions out of queries and into a shared structure that every system can rely on, reducing duplication, preventing drift, and building a long-term semantic foundation that scales.
They eliminate Product data chaos, enable trustworthy AI, and scale seamlessly as catalogs, channels, and use cases expand. They are not a new concept in data management, but they are becoming an urgent one as AI moves from experimentation into production.
The organizations that get this right will not just have smarter AI. They will have AI that speaks their language consistently, correctly, and at scale.
If your product data doesn’t speak a consistent business language, your AI and analytics never will.
References:
- Microsoft Fabric IQ — Ontology Overview
- Timbr.ai — Ontology-Based Data Model
- GoodData — Understanding Ontology in AI Analytics
Author Bio: Maroun Sader is a Strategic Data & Analytics Leader and Solution Architect with a Master’s in Data Science from Deakin University. With expertise in architecting end-to-end Big Data solutions and a background as a Microsoft, Oracle, Big Data Certified and Trainer, he focuses on the intersection of technical infrastructure and business ROI.
Ontology: The Hidden Layer That Makes AI Actually Work was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.