Scalable, cost-efficient architecture best practices
Balancing scalability and cost optimization is a fundamental challenge in designing modern systems, especially those involving data-intensive or AI-driven workloads. On one hand, systems must be able to scale seamlessly to handle increasing numbers of users, transactions, and data volumes. On the other hand, uncontrolled scaling can quickly lead to escalating infrastructure and operational costs. Achieving the right balance requires a thoughtful combination of architectural decisions, performance optimizations, and financial awareness.

A key consideration in this trade-off is understanding the return on investment (ROI) of scaling. Not all growth justifies proportional increases in cost. For example, scaling to improve user experience or support revenue-generating features may provide strong ROI, whereas over-provisioning resources “just in case” can result in wasted spend. Therefore, decisions around scaling should always be tied to measurable business outcomes such as user retention, latency improvements, or revenue growth.
When evaluating how to balance scalability with cost efficiency, several important factors come into play:
- Workload characteristics (predictable vs. spiky demand)
- Performance requirements (latency, throughput, availability)
- Resource utilization efficiency
- Cost visibility and monitoring
- Long-term vs. short-term scaling needs
To address these factors effectively, organizations typically rely on a combination of architectural strategies and operational practices:
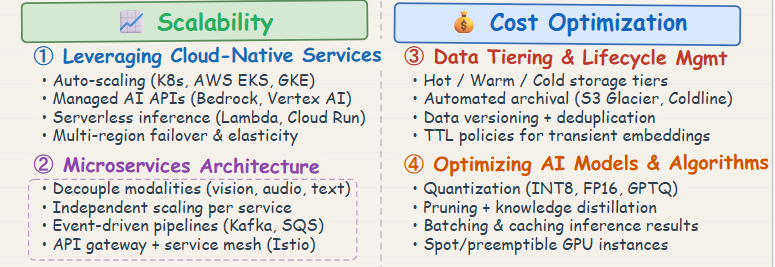
Leveraging Cloud-Native Services
Cloud-native services provide a powerful foundation for balancing scalability and cost. Managed offerings from major cloud providers enable systems to scale elastically without requiring heavy upfront infrastructure investment.
- Compute: Serverless functions and managed container platforms automatically scale based on demand, ensuring you only pay for what you use.
- Storage: Object storage and managed databases offer tiered pricing and virtually unlimited scalability.
- AI/ML services: Prebuilt or managed ML services reduce the need for maintaining expensive custom infrastructure.
This elasticity allows systems to dynamically adjust to workload fluctuations, minimizing idle resources and reducing capital expenditure. However, careful monitoring is still necessary, as poorly optimized usage patterns (e.g., excessive function calls or inefficient queries) can drive up costs unexpectedly.
Microservices Architecture
A microservices architecture is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and are independently deployable by fully automated deployment machinery. They can be written in different programming languages and use different data storage technologies.
Transitioning from a monolithic system to a microservices architecture enables more granular control over scaling. Individual services can be scaled independently based on demand.
High-load components (e.g., recommendation engines or APIs) can scale without affecting low-traffic components. Resource allocation becomes more efficient, avoiding unnecessary duplication of compute resources.
This approach improves both scalability and cost efficiency, but it introduces complexity in areas such as service orchestration, networking, and observability. Therefore, the benefits must be weighed against the operational overhead.
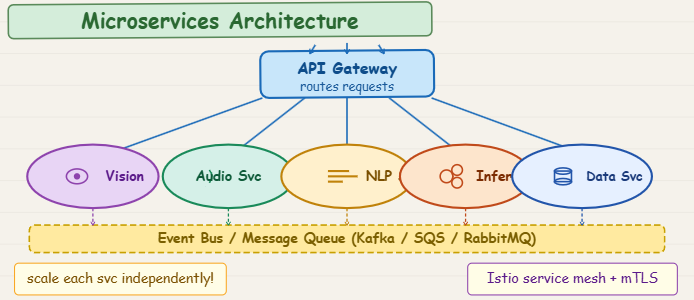
In Azure, you could implement a microservices architecture for a multimodal AI system using several services:
- Azure Kubernetes Service (AKS): This is a popular choice for orchestrating microservices. You can deploy each AI model or processing component (e.g., image recognition, natural language processing, audio analysis) as a separate microservice within AKS. AKS allows you to scale individual microservices independently based on their load, which is great for cost optimization.
- Azure Functions: For smaller, event-driven tasks within your microservices, Azure Functions can be very cost-effective. For example, a function could be triggered when a new piece of data arrives, processing it and passing it to another microservice.
- Azure API Management: This service can sit in front of your microservices, handling routing, security, and rate limiting, making it easier to manage communication between them.
- Azure Cosmos DB or Azure SQL Database: Each microservice could have its own dedicated database, allowing for independent data management and scaling.
By using these services, you can build a flexible, scalable, and cost-optimized multimodal AI system. Each part of your AI system (like the image analysis part or the text generation part) can be its own microservice, scaling up or down as needed without affecting the others.
Data Tiering and Lifecycle Management
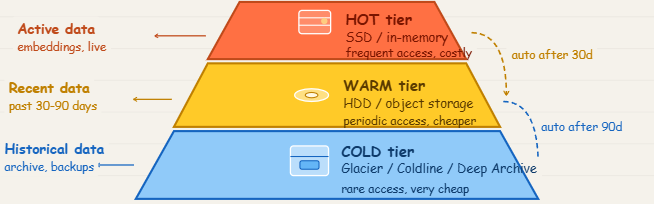
Data storage is often a major contributor to system costs, particularly in AI systems where large datasets are common.
- Hot data: Frequently accessed, stored in high-performance (and higher cost) storage.
- Warm data: Occasionally accessed, stored in moderately priced storage.
- Cold/archival data: Rarely accessed, stored in low-cost archival solutions.
By implementing automated lifecycle policies, systems can move data between tiers based on usage patterns. This ensures that expensive storage is reserved only for data that truly requires it, significantly reducing overall storage costs without sacrificing accessibility when needed.
Optimizing AI Models and Algorithms
AI workloads can be particularly resource-intensive, making optimization critical for cost control.
- Model selection: Use smaller or more efficient models when they meet performance requirements.
- Model compression techniques: Quantization and pruning reduce model size and computational demand.
Quantization involves reducing the precision of the numbers used to represent a model’s weights and activations. Instead of using 32-bit floating-point numbers, you might use 16-bit or even 8-bit integers. This significantly reduces the model’s size and the computational resources needed for inference, as operations on lower-precision numbers are faster.
Pruning involves removing redundant or less important connections (weights) in a neural network. Many neural networks are over-parameterized, meaning they have more connections than strictly necessary. By identifying and removing these connections, you can create a sparser, smaller model that performs similarly to the original but requires less computation.
To implement these, you’d typically use specialized libraries or frameworks. For example, TensorFlow Lite and PyTorch Mobile offer tools for quantization, and many research papers and open-source projects provide pruning algorithms.
- Efficient inference strategies: Batch processing or caching predictions can reduce repeated computations.
When designing your inference pipeline, collect incoming requests for a short period (e.g., 100–500 milliseconds) or until a certain batch size is reached, then send them to your model. Frameworks like TensorFlow Serving or NVIDIA Triton Inference Server are built to handle this efficiently.
Implement a caching layer (e.g., using Redis or an in-memory cache) before your inference service. Before sending an input to the model, check if a prediction for that input (or a sufficiently similar one) already exists in the cache. If it does, return the cached result. Define clear cache invalidation policies to ensure predictions remain fresh.
- Algorithmic efficiency: Improving code and data processing pipelines can significantly reduce compute time. The following optimizations will help you directly lower compute usage, which is often one of the most expensive components of scalable systems.
Streamline Feature Engineering: Identify and remove redundant or highly correlated features.
Efficient Data Loading: Implement optimized data loaders that can pre-fetch and pre-process data in parallel, ensuring your model isn’t waiting for data.
Data Normalization/Standardization: Ensure data is in an optimal format for your model, which can speed up convergence and inference.
Choose Efficient Architectures: Select models known for their efficiency (e.g., MobileNet for vision tasks, DistilBERT for NLP) if they meet your accuracy requirements, rather than always defaulting to the largest state-of-the-art models.
Hyperparameter Tuning: Optimize learning rates, batch sizes, and other hyperparameters to achieve desired performance with fewer training epochs.
Early Stopping: Monitor validation performance during training and stop when performance plateaus to avoid unnecessary computation.
Vectorization: Utilize libraries like NumPy or TensorFlow/PyTorch’s built-in operations that perform computations on entire arrays or tensors at once, which is much faster than looping through elements.
Profiling: Use profiling tools to identify bottlenecks in your code and focus optimization efforts on the most time-consuming parts.
Language-Specific Optimizations: For Python, consider using JIT compilers (like Numba) or rewriting critical sections in faster languages (like C++ with bindings).
Automated Operations (MLOps and DevOps)
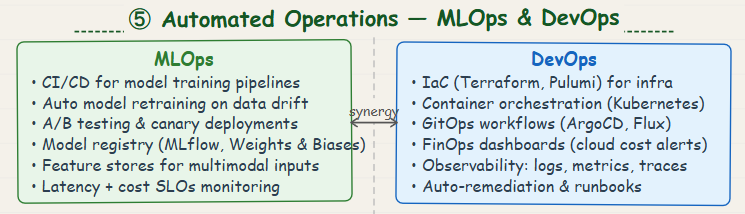
Automation plays a crucial role in maintaining both scalability and cost efficiency over time.
- Automated deployment pipelines reduce manual effort and speed up scaling decisions.
- Monitoring and alerting systems help detect inefficiencies, such as underutilized resources or cost spikes.
- Auto-scaling policies dynamically adjust resources based on real-time demand.
- Infrastructure as Code (IaC) ensures consistent and optimized resource provisioning.
While there is an upfront investment in building these systems, they significantly reduce long-term operational overhead and the need for large engineering teams, ultimately improving cost efficiency.
Multimodal AI Systems: Scalability & Cost Optimization was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.