Background:
Manifold-Constrained Hyper-Connections (mHC) is a new architecture added by Deepseek and recently implemented in Deepseek v4.
mHC is a fix that makes HC(Hyper-Connections) vanishing or exploding gradient caused by HC while still keeping the performance increases. As adding weights and biases on HC made signals from earlier layers harder to update making the residual stream less residual streamy.
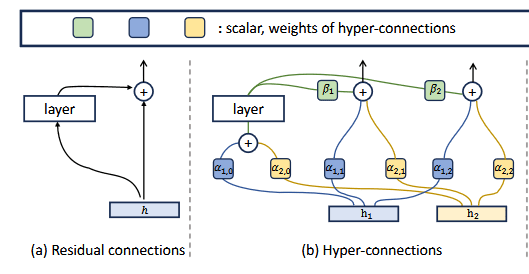
HC is a cursed method of adding weights and biases onto the residual stream to simulate a wider residual stream.
mHC was an addition onto HC where Sinkhorn-Knopp were used to make the weights and biases on the residual stream to be doubly stochastic. This is a matrix where the rows and columns sum to one, like applying softmax along rows and columns simultaneously. MHC-lite is similar to the mHC paper however, used a different method of Birkhoff-von Neumann to achieve the doubly stochastic matrix
Quick Summary:
- Trained a mHC, mHC-lite, and non mHC model with mhc-lite repo. With same parameters for everything but, the mHC method
- Attention heads can have their shapes change and layer position change after mHC.
- Previous token heads seem to instead have high vertical scores or kurtosis in mHC models
- mHC models seem to have certain attention heads such as previous token and induction heads appear in earlier layers than the non mHC model.
- Other attention head types such as Duplicate head appear later in mHC models than the non mHC model
- mHC models also seemed to predict certain tokens in earlier tokens like the token same compared to the non mHC model
- mHC lite residual streams seemed to each output different tokens while mHC seemed to have residual streams 1,2,3 all output the same top 1 token. The method to get the parameters doubly stochastic seemed to impact how the residual streams work.
- Induction heads can be detected similarly to normal with the diagonal stripe scores. However, previous token heads can not be detected this way for mHC models and require ablation and path patching to find.
- Previous token heads instead changed to look like receiver heads and correlate with high kurtosis scores
Experimental setup
MHC
For my training for my mhc and base models I used https://github.com/FFTYYY/mhc-lite using the arguments from the https://arxiv.org/pdf/2603.14833 but, adapted to work with mhc-lite https://github.com/Realmbird/mhc-lite-Dolma-781M.
Trained models are at https://huggingface.co/collections/Realmbird/mhc-model-diff
I trained mHC models with 4 residual streams with the mHC and mHC lite models being 781m parameters after including parameters from residual streams.

Ablation Detector setup for Attention Heads
Probe | Prompt | Why it works |
prev-token | "When Mary and John went to the store, John gave a drink to Mary" | Has repeated names ("John", "Mary") that the model can only resolve correctly using positional/previous-token info from earlier in the sentence. |
induction | [EOT] + R + R where R = 25 random token IDs | Random tokens repeated twice. The only way to predict the second copy is by looking back to the first copy → forces the induction circuit. |
duplicate | Same prompt as induction | Reuses the random-repeat structure. |
successor | 3 prompts averaged: days ("... Friday" → " Saturday"), numbers ("... five" → " six"), letters ("... E" → " F") | Three independent probes prevent single-prompt artifacts. The model has to "increment" by one. |
copy-suppression | "When John and Mary went to the store, John gave a drink to", target = " Mary", distractor = " John" | Tests whether ablating a head makes the model more likely to predict the duplicated name (" John") instead of the correct one (" Mary"). |
ΔNLL = NLL(target | ablated) − NLL(target | clean)
With prompts that were the certain attention head is needed.
ex) prev token "When Mary and John went to the store, John gave a drink to Mary"
Pass | Setup | Output |
Baseline | nothing ablated | NLL_baseline |
Total ablation | ablate (l, h) only | NLL_total |
Direct ablation | ablate (l, h) AND freeze every block at layer ≥ l+1 to its baseline output | NLL_direct |
Experiments
Logit Lens
- The images of the full logit lens tables I created for mHC, mHC-lite, and non mHC (residual) I have added at the bottom and called residual for any who are curious
- The non mHC model predicts floor at the final layer and predicts the same token for multiple layers at time with ground and ? token
- mHC different residual streams all seem to generate similar tokens at the last layer for residual streams 1,2,3. With 3 being the only one that seemed to be different.
- mHC-lite seems to have each parallel residual stream to output different tokens sofa, floor, end compared to mHC which all have the residual streams predict floor.
- Some tokens only seem to appear earlier in the mHC and mHC-lite model especially the token same
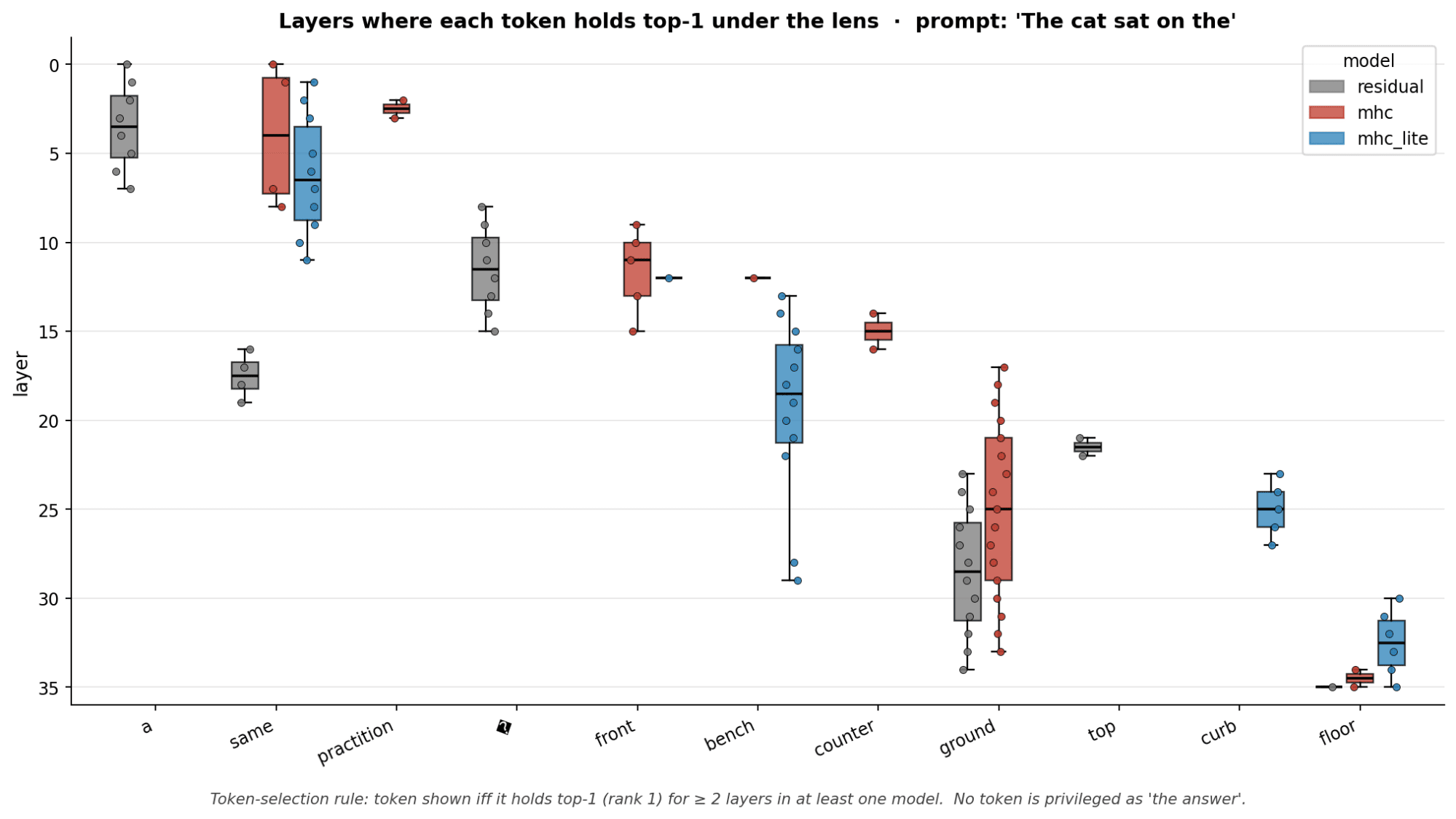
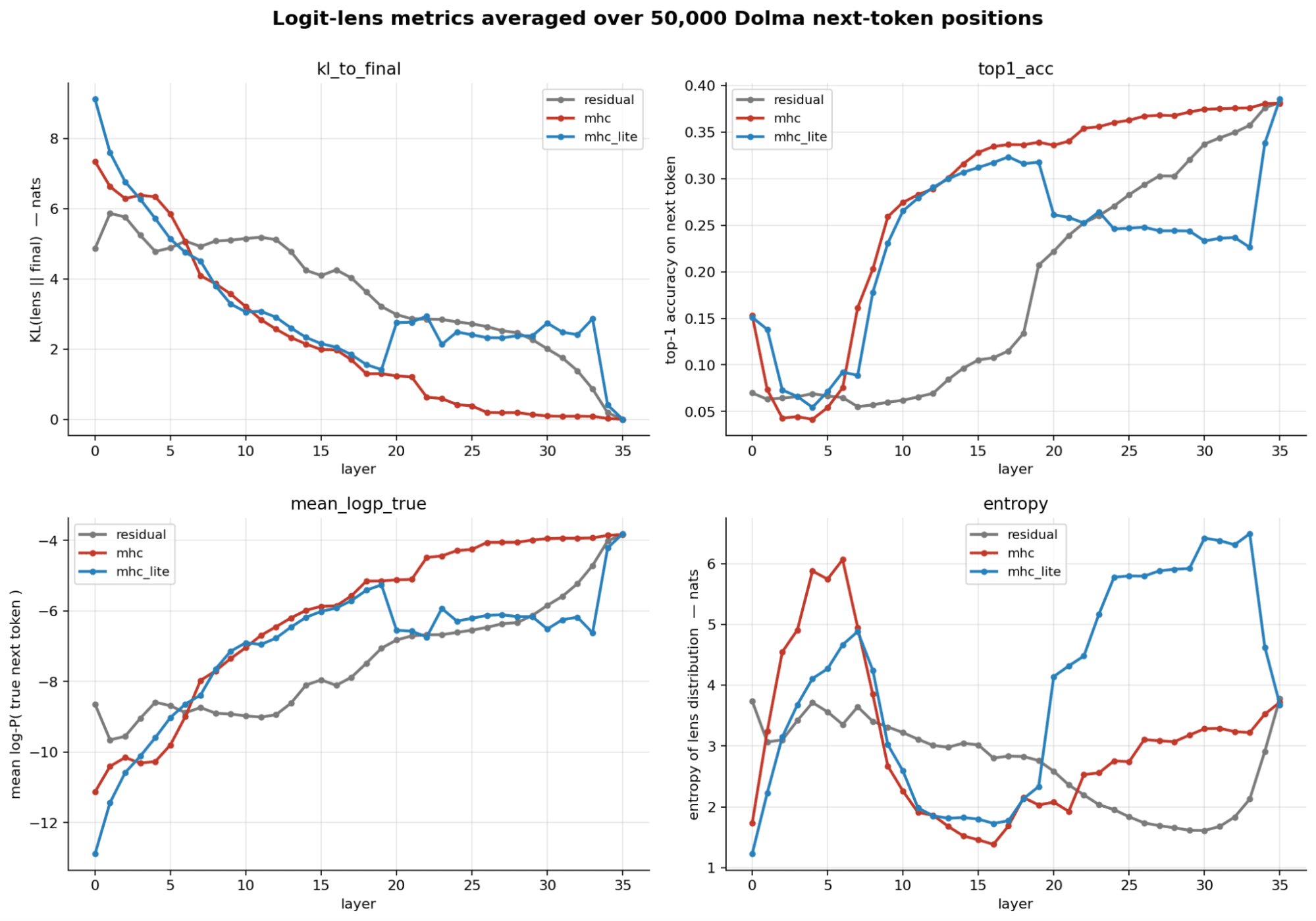
- MHC reaches 90% of its final top-1 accuracy by layer 22 (residual: L31, mhc-lite: L35)
- KL(lens || final) drops below 0.5 by L24 in MHC, vs L34 in residual
- All three converge to ~38.2% top-1 at L35
Attention Heads
- An interesting pattern in attention heads is for induction heads and prev token heads especially. They appear in mHC and mHC-lite models in earlier layers for some reason. So the attention head types still exist it just the order of them appear seems to change for some attention heads
- Duplicate heads seemed to happen in later layers unlike the other attention head categories
- Disclaimer: The Attention heads were confirmed with behavioral proxies (ablation and path patching) not OV circuits as attention heads might look different on mHC models. This was not the case induction and prev token heads
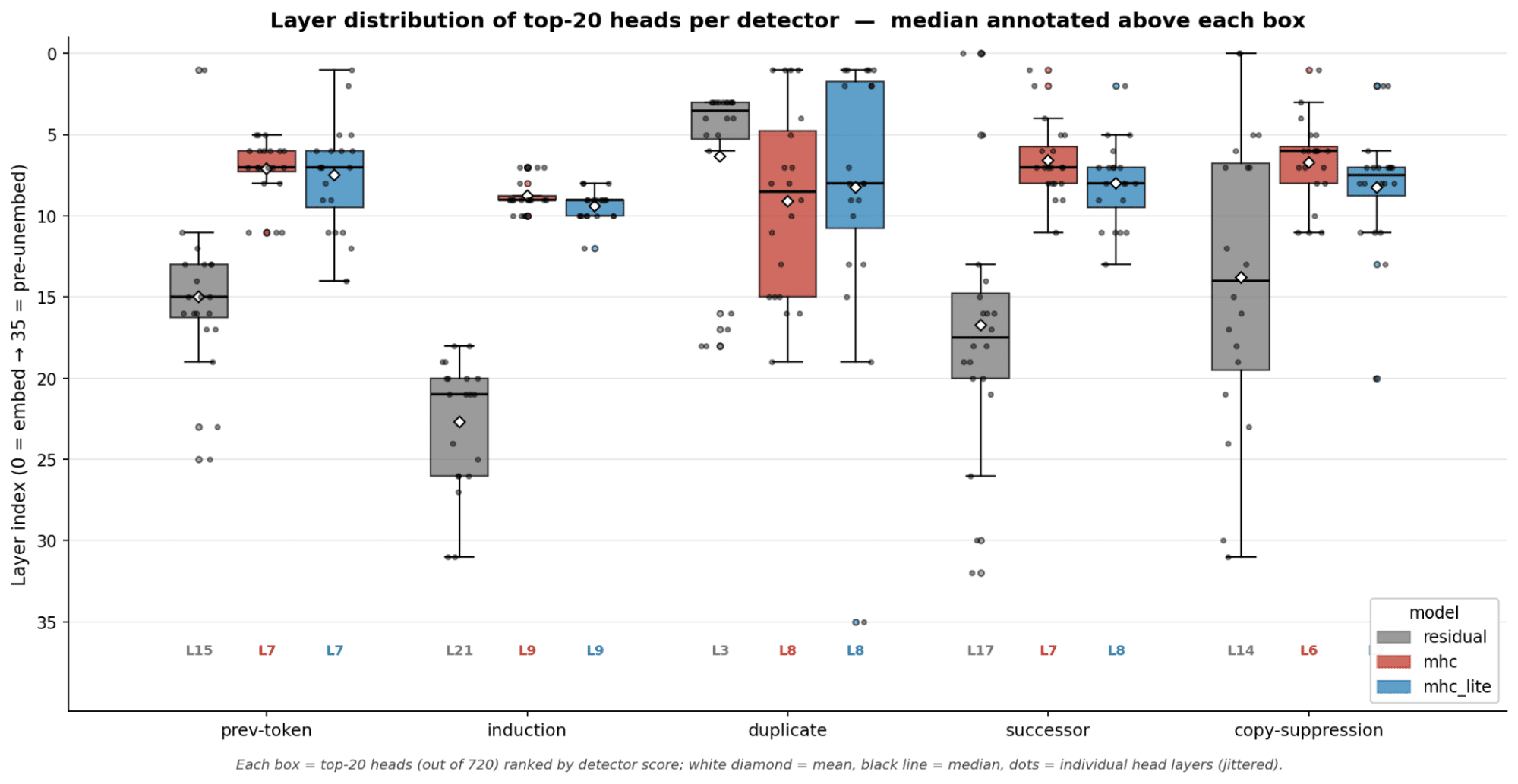
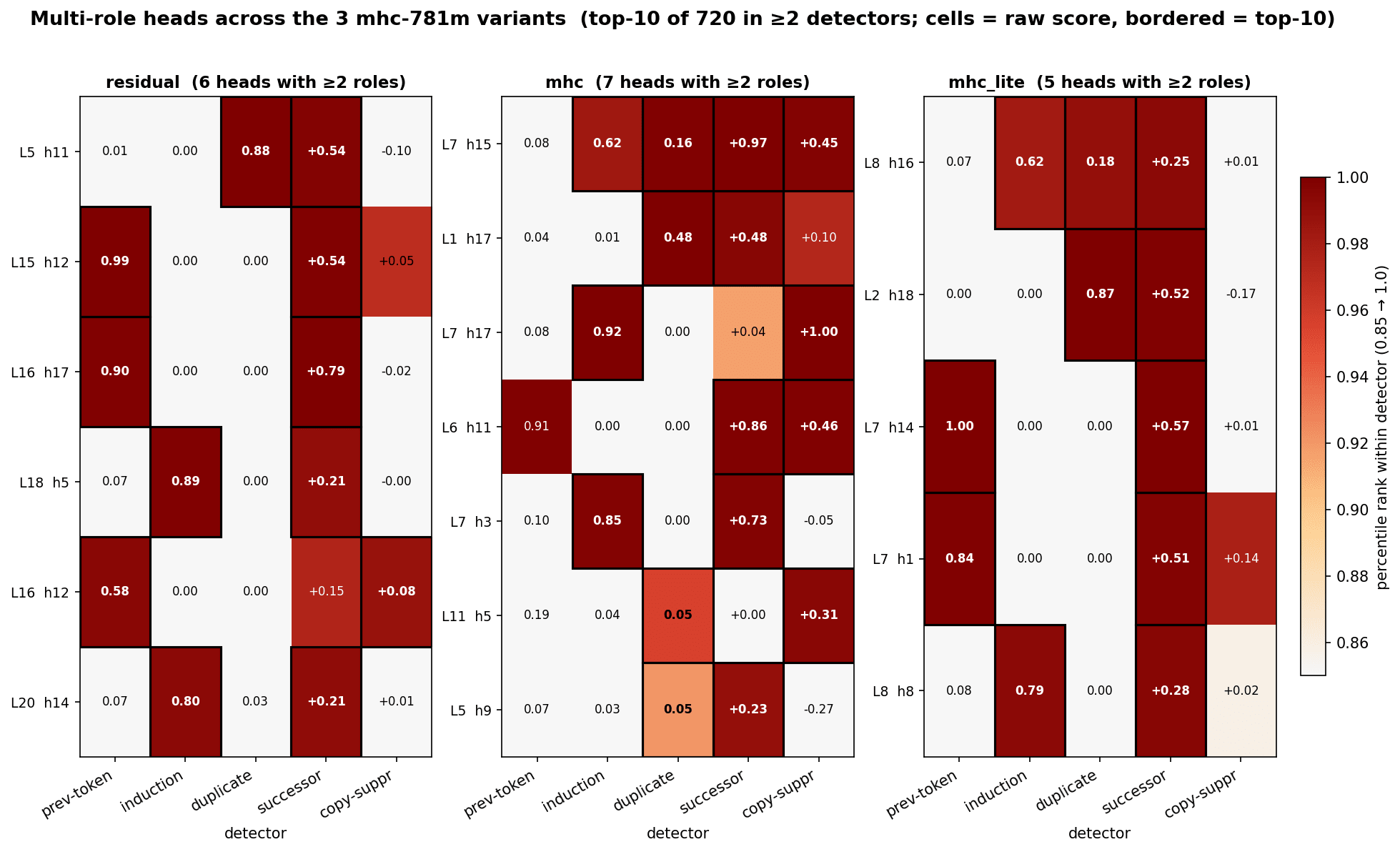
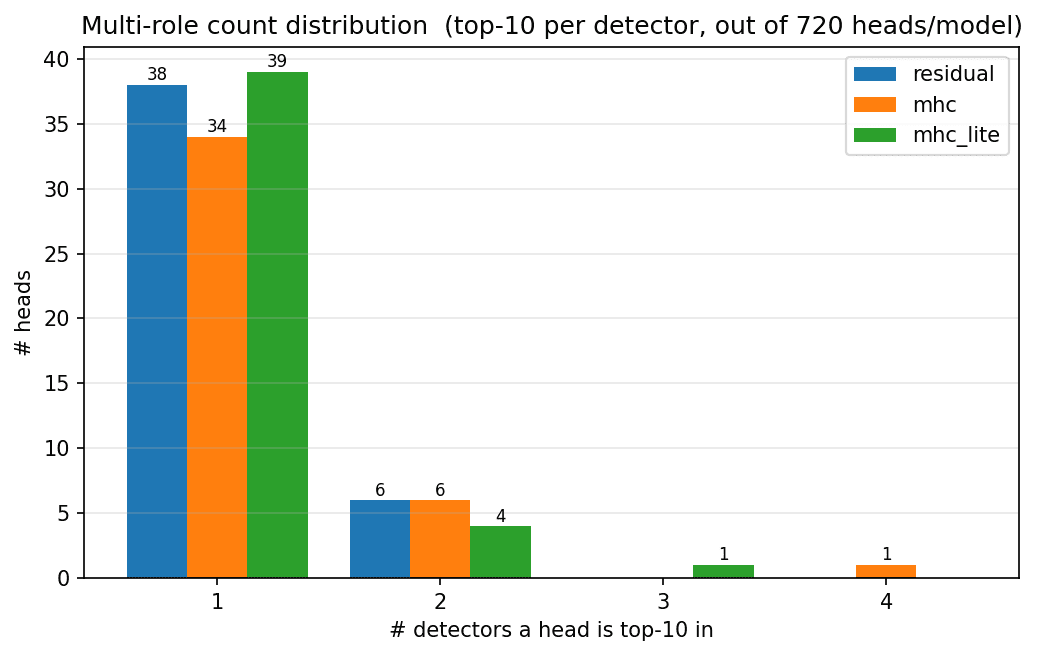
- For mHC models there seem to be attention heads that behave as 3 different attention head types which do not exist in non mHC models which only have some heads that have 2 roles.
- Attention heads with 3 or more roles include mhc L7h15 which is a 4 role attention head when doing patching ablation.
- mhc-lite L8h16 is the only mhc-lite 3-role head
- For induction and previous token heads they seem to appear similar regardless of mHC or not (Appendix ).
Do heads look the same regardless of parallel residual streams?
- The answer is kinda as for induction heads. If it has a canonical stripe for being an induction head with the induction head pattern it is likely to act like an induction head when you confirm with ablation and path patching.
- However, for previous token heads ablation and path patching seem to detect different heads as previous token heads than looking at the attention head pattern.
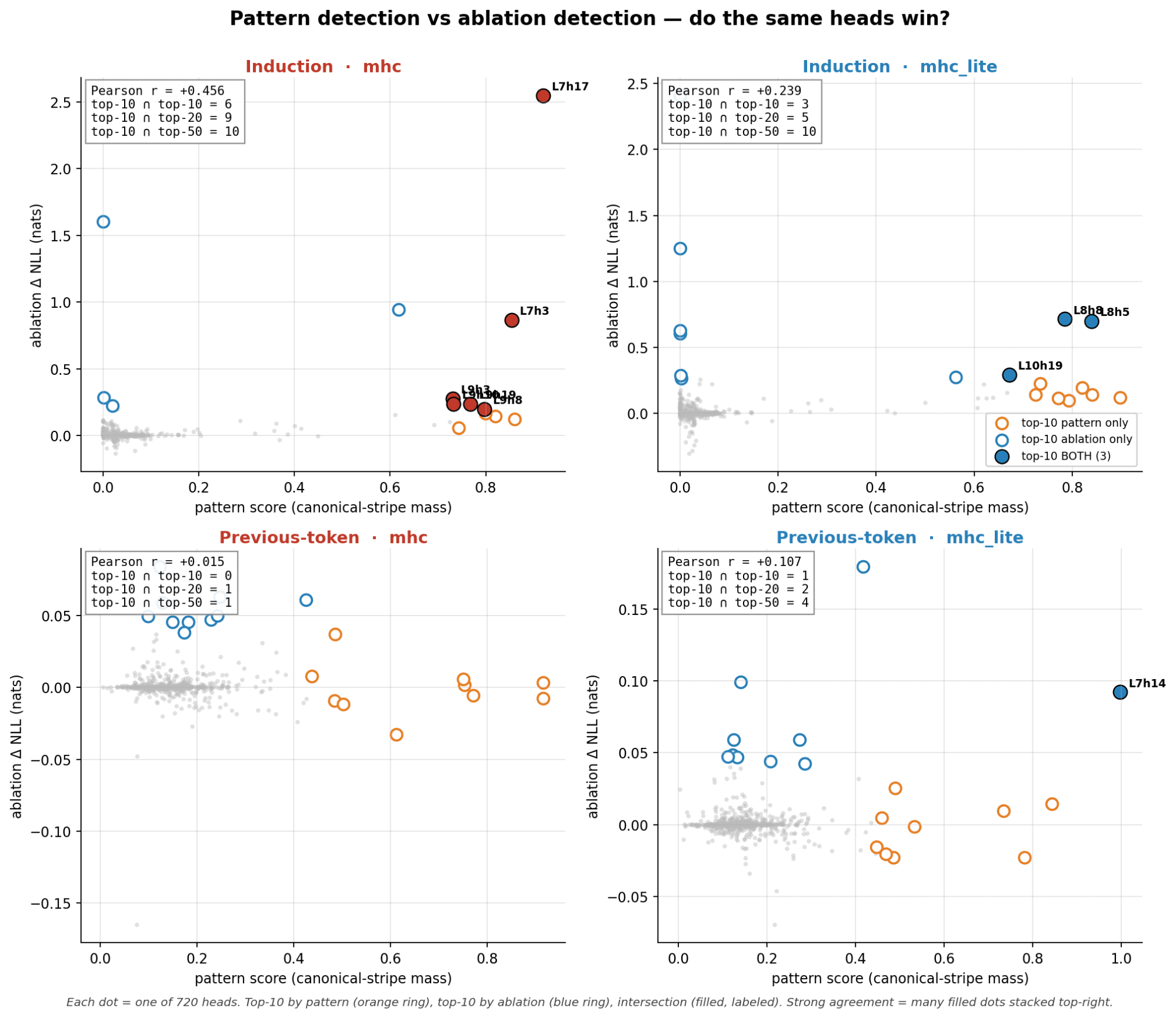
- Prev tokens in mHC models look like attention sinks. They changed to have high kurtosis signatures instead for some reason.
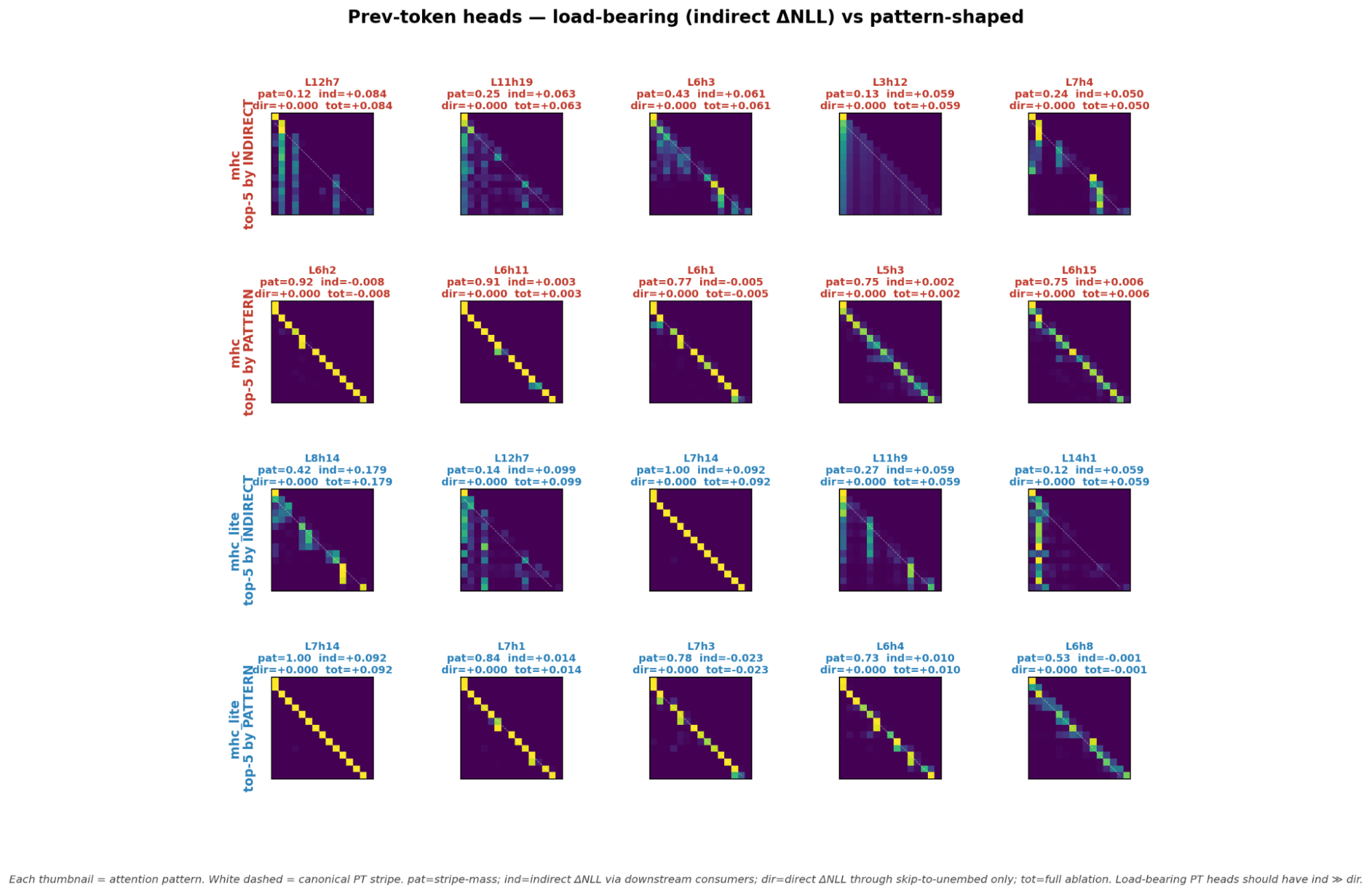
Confirming Attention Sinks previous token heads
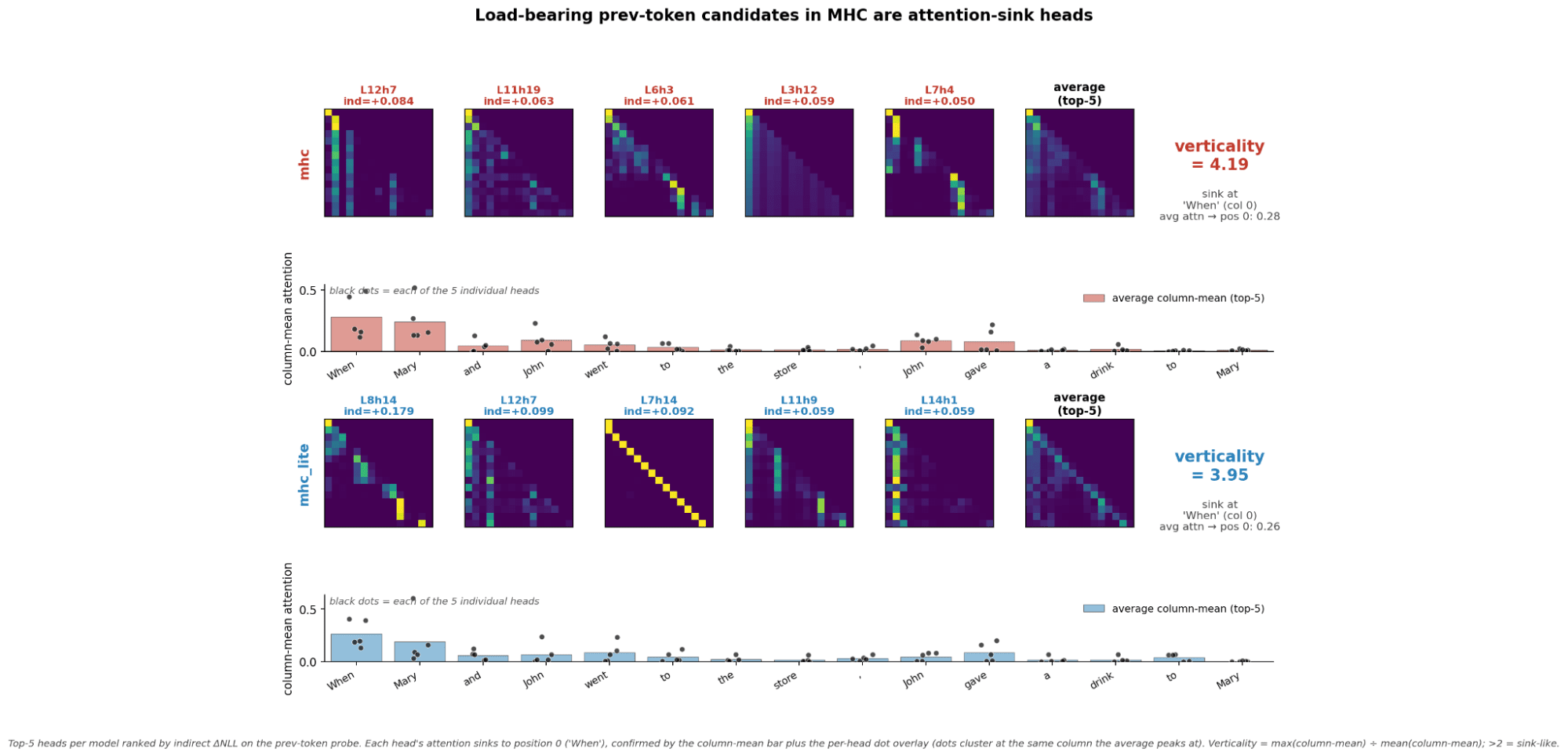
- For mHC models trained with Sinkhorn-Knopp verticality work to detect prev token heads
- For mHC-lite models it is mostly consistent with the topk with the exception of one head that looks like a normal previous token head
Future Work
- So far I have trained SAEs on the mhc, mhc-lite, and base model and will attempt see the features
- I will also attempt to see if it is possible to train auto encoders to predict one residual stream from another. RAE (residual stream auto encoder)?
- Circuit based interp methods on mhc and mhc-lite
- Figure out why mHC-lite residual streams do different tokens while mHC does not
- Doing more analysis on attention heads multiple roles to see it was not just a noisy result
- Why do induction heads stay similar but not prev token heads?
- What causes the multi use attention heads
- WIll the number of streams change how heads look and the position of attention heads?
- Linear probes on Previous Token Heads to confirm results
Appendix
Full Logit Lens images
For the mHC models they were trained with 4 residual streams 0,1,2,3. I tried a logit lens on one residual stream finding output for it and trying out the sums between them.
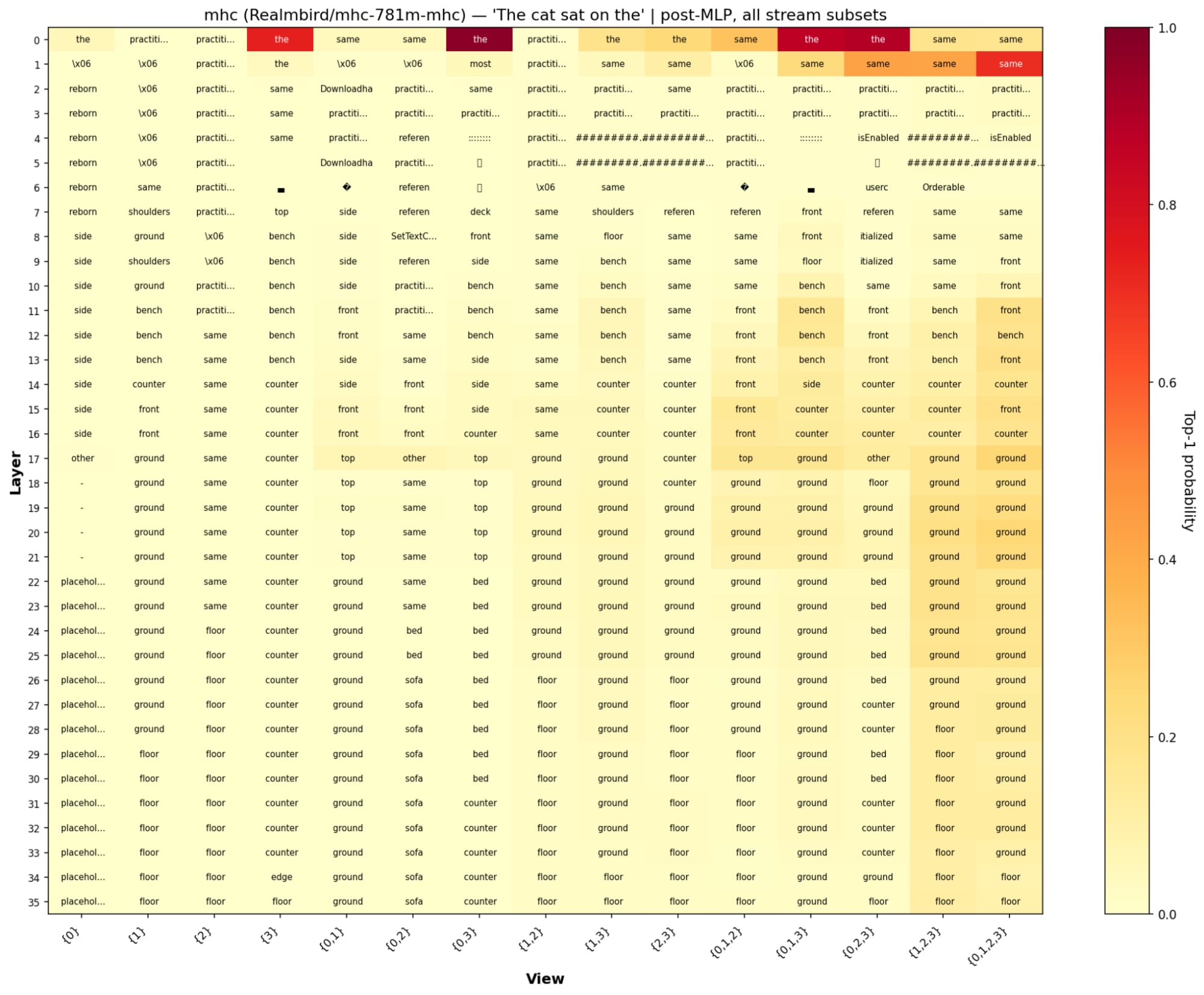
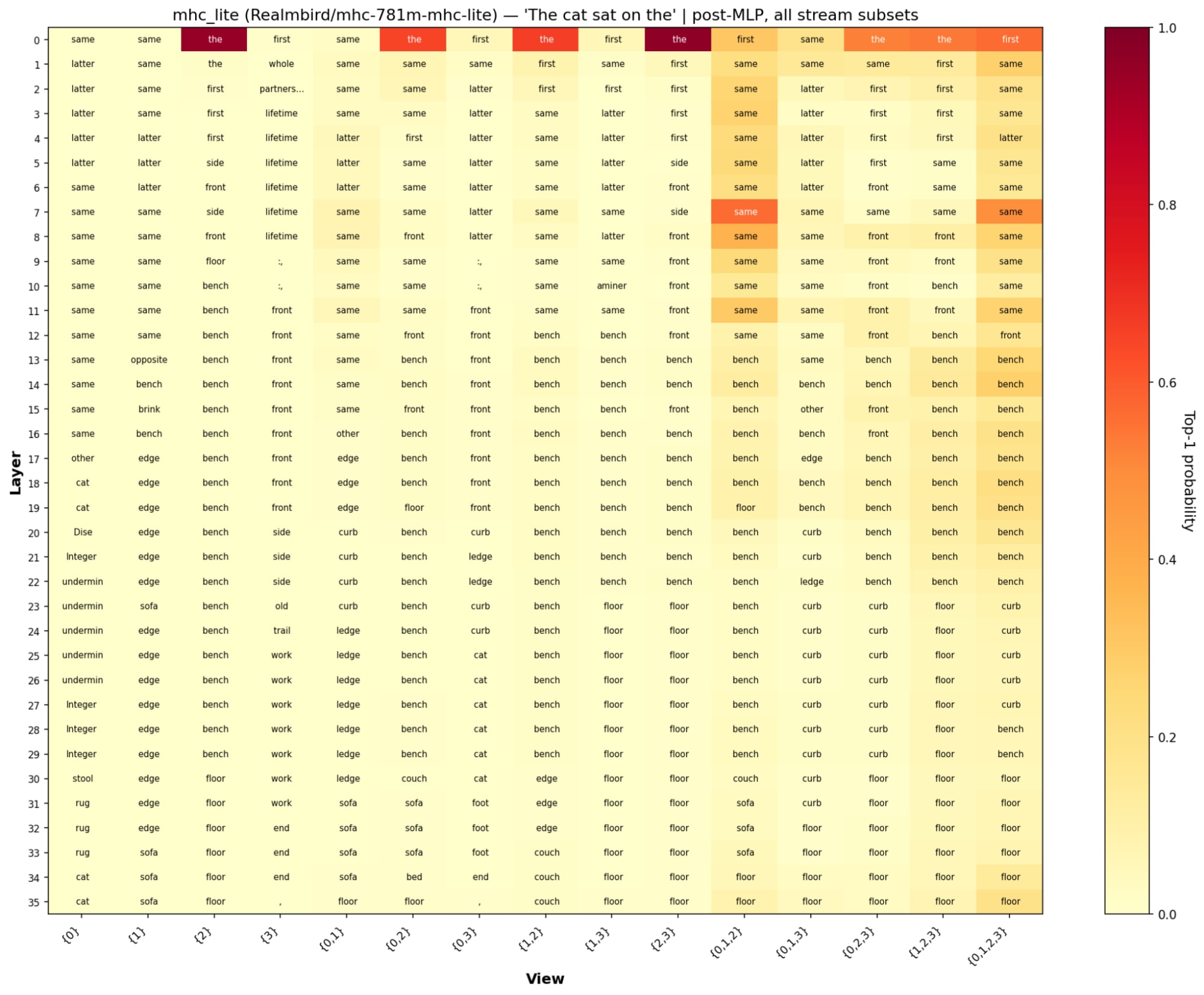
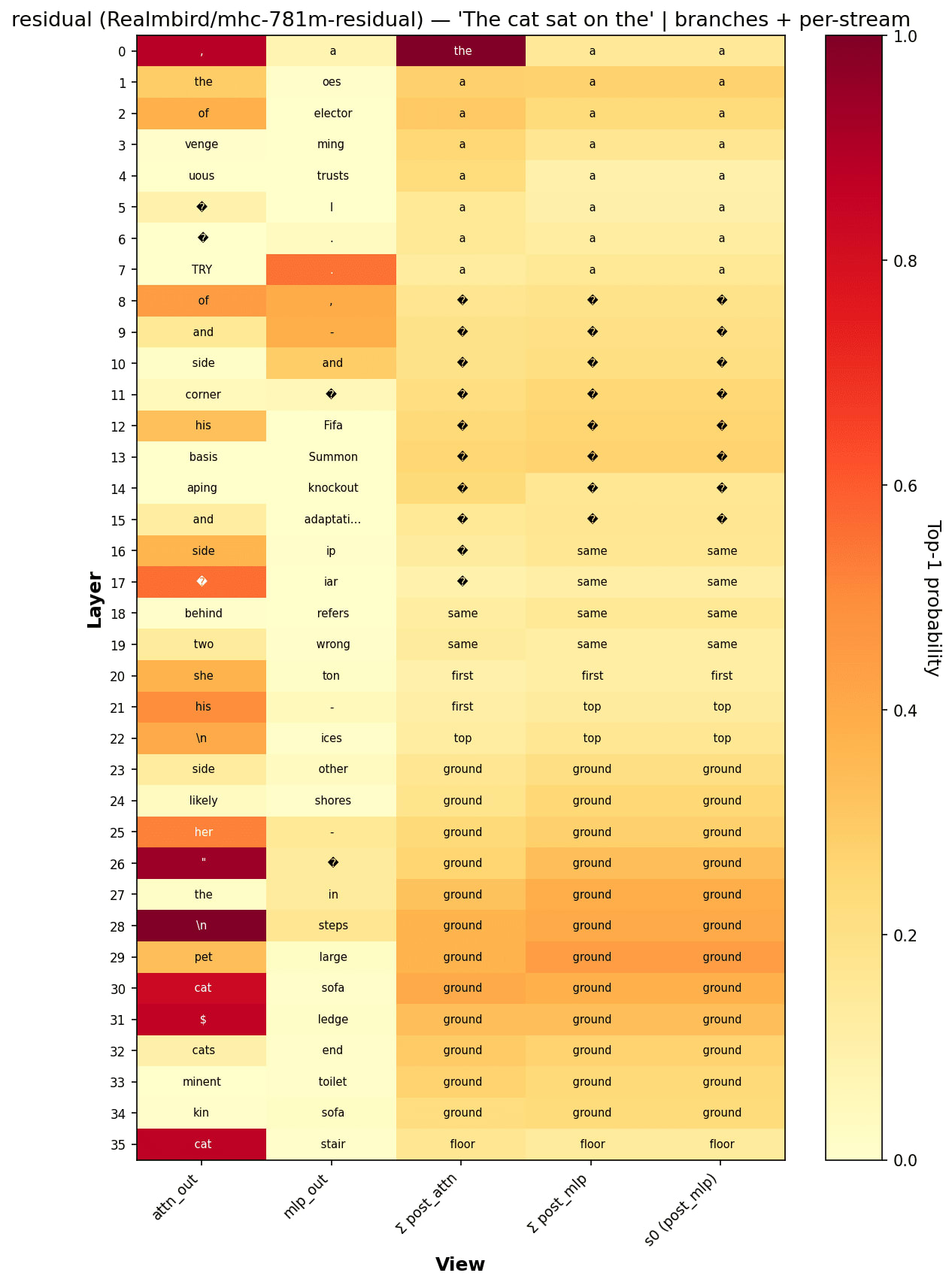
Pattern of Attention Head
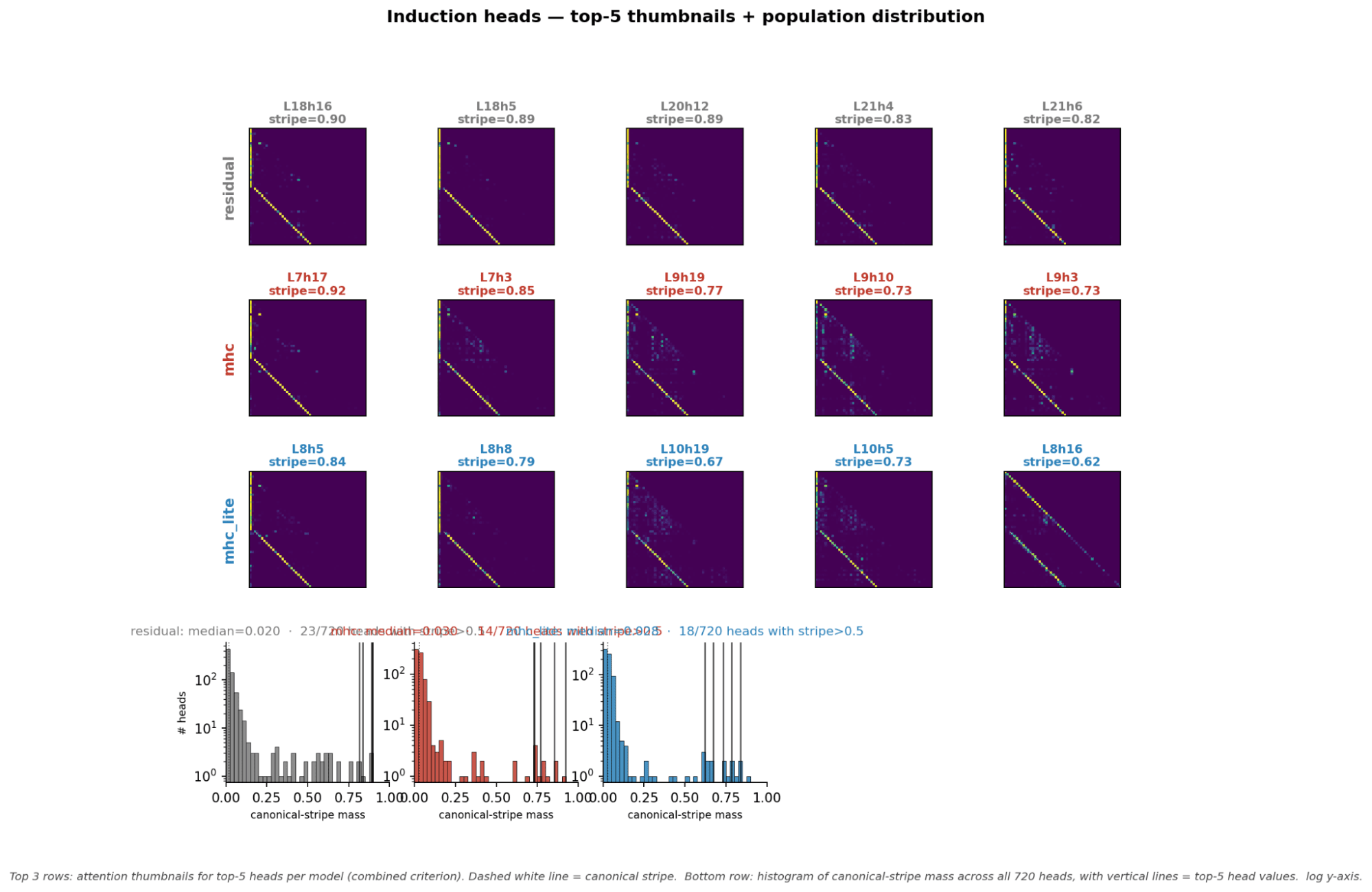
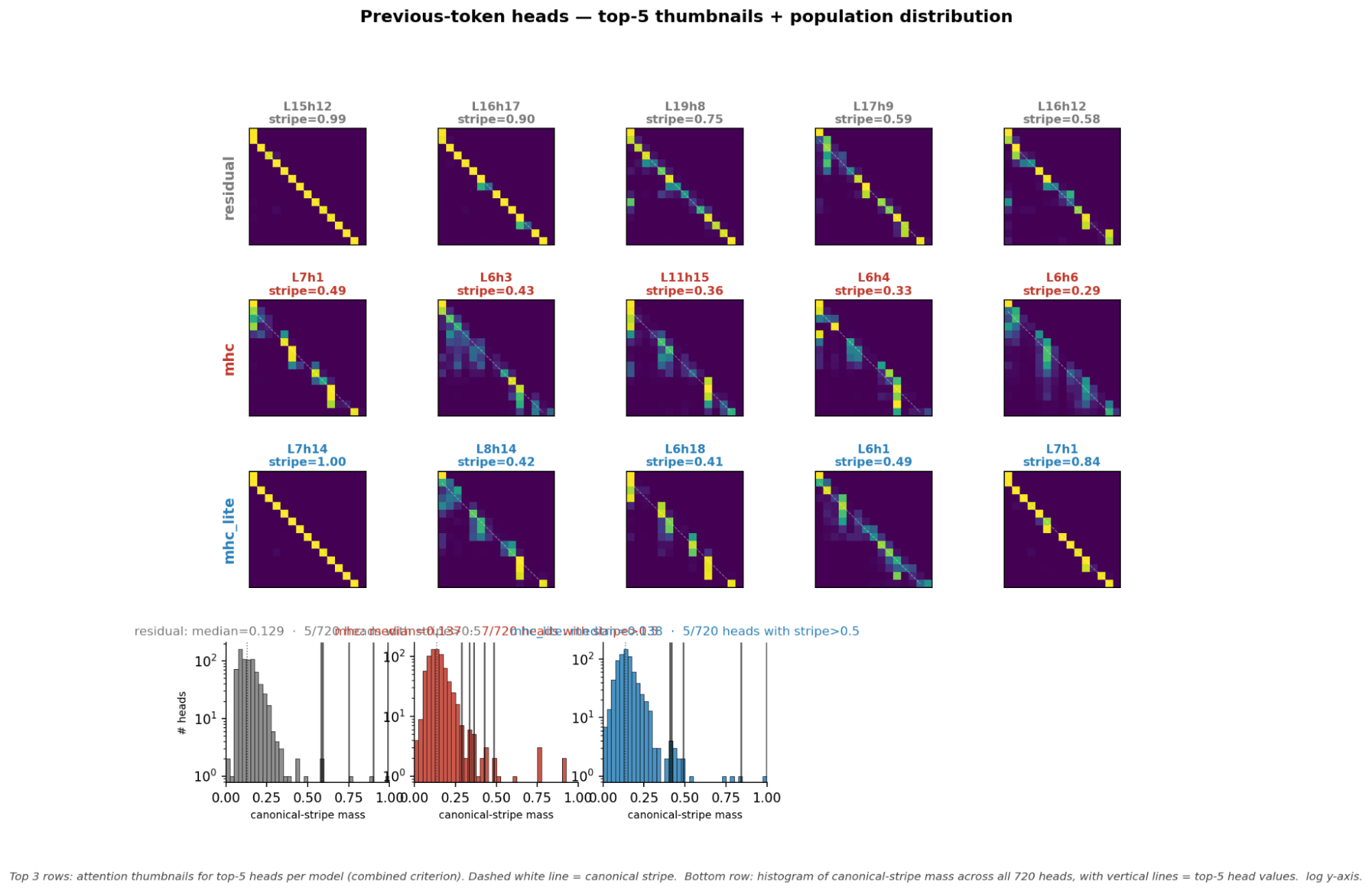
Discuss