Moving beyond manual spreadsheets to automate capacity planning, territory balancing, and optimal seller matching using the Hungarian Algorithm.

If you ask any Revenue Operations leader or Sales Strategy analyst about their most grueling operational exercise, the answer is almost universally “territory planning.”
Depending on the organization, every year, half-year, or even quarter, RevOps teams undergo a massive exercise to carve up their total addressable market (TAM) and assign it to sales representatives.
Currently, this is done using colossal spreadsheets, pivot tables, and endless manual mapping. It is not an efficient process. Analysts spend weeks — sometimes months — building “new and improved” territory maps that consider all geographical and segment constraints. Due to the iterative nature of executive planning and the constantly changing scope from management, the maps are redrawn over and over. It wastes a tremendous amount of valuable time. The entire process is overwhelmingly manual, wildly time-consuming, and fundamentally unscalable.
To make matters worse, once the maps are drawn, those same analysts and managers must manually map thousands of accounts to those exact territories, and then manually allocate all the different sellers (Account Executives, SDRs, Sales Engineers) to those territories before assigning them their individual targets.
While Data Science has revolutionized areas like churn prediction and lead scoring, territory design remains stuck in the dark ages of Excel and Google Sheets. In this article, we will walk through the architecture of a programmatic solution. We will build a pipeline that treats territory planning not as a spreadsheet chore but as a rigorous Operations Research problem, using Longest Processing Time (LPT) algorithms and Bipartite Matching to fully automate the process from raw CRM data to final seller deployment.
The Anatomy of B2B Territory Data
Before diving into algorithms, we need to understand the data we are working with and the constraints we are trying to satisfy.
A traditional analyst approaches territory design by exporting thousands of CRM accounts and a roster of sellers into a spreadsheet. The data typically looks like this:
Account Data:
Seller Data:
The goal is to build an automated pipeline that achieves three things:
- Taxonomy Enforcement: Accounts are grouped geographically and categorically into distinct territories (e.g., ensuring all North American accounts are grouped into an AMER-specific territory).
- Capacity Balancing: The Estimated_TAM of each territory is mathematically equalized, ensuring earning potential is fair across all regions.
- Intelligent Assignment: The right human seller is matched to the right balanced territory based on their specific skills and domain expertise.
Here is the programmatic pipeline we will build to solve this:
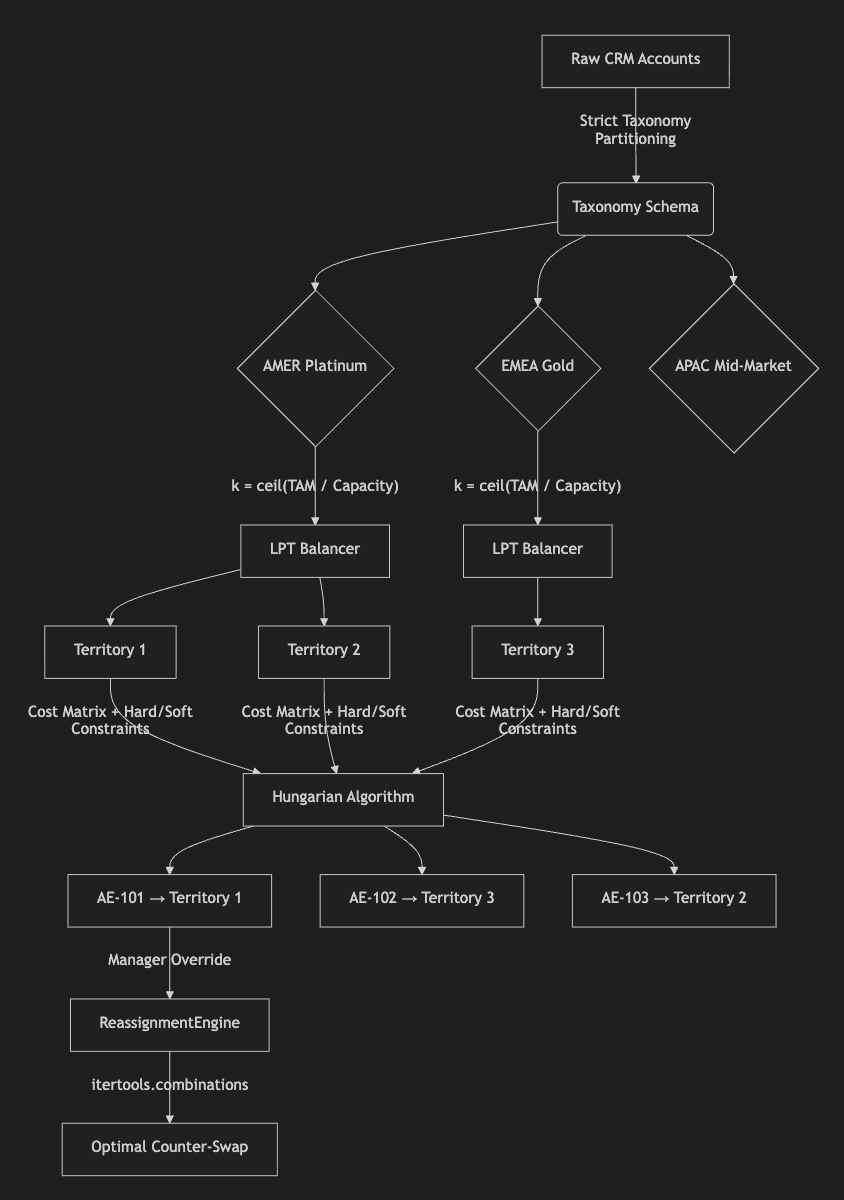
Step 1: The Failure of K-Means and the Need for Taxonomy
When a data scientist first looks at this problem, the immediate instinct is to use distance-based clustering algorithms. “Just use K-Means clustering to group the accounts by TAM and geography!”
In B2B sales, this fails spectacularly. B2B organizations operate under strict taxonomies. A B2B software company has hard, impenetrable boundaries between business segments. For example, a $500M enterprise in New York is handled by an entirely different sales organization than a $5M startup in London. These go-to-market teams operate with different compensation plans, different management structures, and different sales cycles. You cannot simply mix these accounts together just because the math says it balances the numbers.
Let’s look at what happens if we feed B2B accounts into Scikit-Learn’s KMeans algorithm to build two balanced clusters:
from sklearn.cluster import KMeans
import pandas as pd
# The naive approach: Clustering by Region and TAM
kmeans = KMeans(n_clusters=2, random_state=42)
df['Cluster'] = kmeans.fit_predict(df[['Region_Encoded', 'Estimated_TAM']])
# Evaluate the cross-contamination
print(df.groupby(['Cluster', 'Region']).size().unstack(fill_value=0))
Output:
While the algorithm successfully balances the total TAM between the two clusters, the results are completely unusable in a real-world business scenario. Cluster 0 contains 450 North American accounts and 120 European accounts. You cannot assign a seller based in London to a territory managed by an AMER Vice President, nor can they realistically service accounts in California.
We must respect Hard Constraints. To solve this programmatically, our first step in the pipeline is to build a “Taxonomy Schema”. Instead of passing the entire CRM dataframe to an algorithm, we slice the global account universe into mathematically isolated data structures (e.g., separating AMER/Platinum completely from EMEA/Platinum). Subsequent optimization algorithms are run exclusively within these strict buckets, ensuring cross-contamination is mathematically impossible.
Step 2: Automating Capacity Prediction and Balancing Territories
Once the accounts are locked into their taxonomy buckets, how do we carve them into equal territories?
First, we need to know how many territories to create. Instead of an analyst guessing headcount, we use Capacity-Driven Prediction. If Revenue Leadership dictates that a Gold Segment Account Executive should carry a $1.5M TAM capacity, the algorithm calculates the Total TAM of the bucket and dynamically predicts the exact integer of territories required: k = ceil(Total_TAM / Target_Capacity)
Once k territories are initialized, we turn to multiprocessor scheduling theory—specifically, the Longest Processing Time (LPT) algorithm—to perfectly balance the accounts into those territories.
We sort all accounts descending by TAM. We then iterate through the sorted accounts, consistently placing the largest unassigned account into the territory with the currently lowest Total TAM.
# The Greedy LPT Allocation Core
for index, account in sorted_bucket.iterrows():
val = account['Estimated_TAM']
# Find the territory with the lowest sum so far
min_territory = min(territory_sums, key=territory_sums.get)
# Assign account to this territory
allocations.append({
'Account_ID': account['Account_ID'],
'Territory_ID': min_territory
})
# Update the running sum for the next iteration
territory_sums[min_territory] += val
This greedy approach is blindingly fast and consistently achieves < 0.1% variance across B2B workloads, completely eliminating the need for analysts to manually shift rows in Excel to balance the numbers.
Step 3: Assigning the Right Seller to the Right Territory (The Hungarian Algorithm)
We now have perfectly balanced territories with thousands of accounts mapped to them. But who covers them?
Assigning sellers to territories is the second massive bottleneck. Managers sit in rooms arguing over which AE gets which patch. To solve this mathematically, we must model human allocation as a classic Linear Assignment Problem.
By treating our human sellers and our carved territories as two disjoint sets of a bipartite graph, we can use scipy.optimize.linear_sum_assignment (an implementation of the Hungarian Algorithm) to optimally match them.
We generate a Cost Matrix based on two distinct sets of criteria:
- Hard Constraints: The algorithm dynamically reads seller profiles. If a seller is tagged as Region=AMER, the algorithm injects an infinite cost penalty to prevent them from ever being matched to an EMEA territory.
- Soft Constraints (Fit Optimization):
- Seniority vs TAM: Top AEs (Tier 1) are mathematically attracted to High-TAM (Tier 1) territories via reduced cost scores.
- Domain Match: If a seller’s Domain_Expertise matches the territory's Dominant_Industry (e.g., Sarah Connor specializes in Manufacturing), the algorithm dramatically lowers the assignment cost for Manufacturing-heavy territories.
import numpy as np
from scipy.optimize import linear_sum_assignment
# Build the Cost Matrix: rows = sellers, columns = territories
cost_matrix = np.full((n_sellers, n_territories), 1_000_000.0)
for i, seller in enumerate(sellers):
for j, terr in enumerate(territories):
# HARD CONSTRAINT: Prevent cross-contamination
if seller['Region'] != terr['Region']:
continue # Cost stays at 1,000,000 (infinite penalty)
# SOFT CONSTRAINTS: Start from a base cost and adjust
cost = 100.0
# Seniority vs Territory Tier alignment
tier_diff = abs(seller['Seniority'] - terr['Territory_Tier'])
cost += (tier_diff * 20.0)
# Reward domain expertise matches
if seller['Domain_Expertise'] == terr['Dominant_Industry']:
cost -= 30.0
cost_matrix[i, j] = cost
# Run the Hungarian Algorithm (minimizes total assignment cost)
row_ind, col_ind = linear_sum_assignment(cost_matrix)
The algorithm evaluates millions of permutations and outputs the global optimal matching that maximizes domain expertise while perfectly respecting geographical boundaries.
Step 4: The Reality of Manager Overrides
No algorithm survives first contact with a sales manager.
In the real world, a manager will look at the mathematically perfect territories and say: “I don’t care what the math says, Account Executive John has a 5-year relationship with this specific buyer. Move the account to his territory.”
When you manually move a massive whale account in a spreadsheet, the perfect balance is instantly destroyed, and the analyst has to spend hours finding alternative accounts to swap back to restore fairness.
In a programmatic pipeline, we automate this. By tracking the exact delta created by the override, we can utilize Python’s itertools.combinations to find the mathematically optimal counter-swap. The engine evaluates thousands of smaller accounts in the over-allocated territory and suggests the perfect combination of 1, 2, or 3 accounts to swap back to restore exact equilibrium—without moving another whale.
import itertools
# The target swap value is half the difference (to equalize both territories)
target_move_value = (over_territory_tam - under_territory_tam) / 2.0
# Exclude locked accounts and recently moved accounts
candidates = get_moveable_accounts(over_territory, exclusions)
# 1. Evaluate Single Account Swaps
for account in candidates:
distance = abs(account['Estimated_TAM'] - target_move_value)
suggestions.append(('Single', account, distance))
# 2. Evaluate Two-Account Combinations
# Limit to 50 smallest accounts to avoid combinatorial explosion
subset = sorted(candidates, key=lambda x: x['Estimated_TAM'])[:50]
for a, b in itertools.combinations(subset, 2):
combined_value = a['Estimated_TAM'] + b['Estimated_TAM']
distance = abs(combined_value - target_move_value)
suggestions.append(('Combination', [a, b], distance))
# 3. Evaluate Three-Account Combinations
for a, b, c in itertools.combinations(subset, 3):
combined_value = a['Estimated_TAM'] + b['Estimated_TAM'] + c['Estimated_TAM']
distance = abs(combined_value - target_move_value)
suggestions.append(('Triple Combination', [a, b, c], distance))
# Sort all suggestions by how close they get to perfect equilibrium
suggestions.sort(key=lambda x: x[2])
Conclusion
Territory optimization is not a spreadsheet mapping problem; it is a combinatorial optimization and bipartite matching problem. By applying Operations Research directly to CRM data, organizations can fundamentally transform their planning cycles:
- Automate Capacity Planning: Eliminate the guesswork of headcount by mathematically predicting exact territory requirements.
- Eradicate Bias and Politics: Use algorithmic LPT balancing to ensure every territory has equal earning potential, removing subjective boundary drawing.
- Maximize Seller ROI: Deploy the Hungarian algorithm to perfectly align human domain expertise with territory requirements, ensuring the right seller covers the right accounts.
- Systematize Overrides: Replace manual spreadsheet recalculations with combinatorial algorithms that instantly identify the mathematically optimal counter-swaps for manager overrides.
This architectural shift from heuristics to algorithms represents the future of Revenue Operations. Furthermore, this pipeline does not exist in a vacuum. Once these balanced territories are mathematically carved and human sellers are optimally assigned, the business must then assign financial targets (quotas) to those sellers. This territory optimization framework connects seamlessly into the quota assignment architecture I detailed in my previous Towards AI article: Hierarchical Sales Target Cascading using Directed Acyclic Graphs (DAG) in Python.
By combining programmatic territory carving with DAG-based target cascading, organizations can build a completely automated, mathematically rigorous pipeline for their entire annual planning cycle.
If you are interested in implementing these architectures in your own organization, I have open-sourced the underlying logic of this pipeline in a Python package called b2b-territory-optimization. You can explore the mathematical framework and test the synthetic data generators on GitHub.
References
- Zoltners, A. A., & Sinha, P. (1983). Sales Territory Alignment: A Review and Model. Management Science, 29(11), 1237–1256. (Foundational literature on the business challenges and mathematical modeling of sales territory design).
- Kuhn, H. W. (1955). The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1–2), 83–97. (Foundational basis for Bipartite Matching in the IntelligentAssigner).
- Graham, R. L. (1969). Bounds on Multiprocessing Timing Anomalies. SIAM Journal on Applied Mathematics, 17(2), 416–429. (Foundational basis for the Longest Processing Time (LPT) scheduling algorithm used in capacity balancing).
- Zoltners, A. A., Sinha, P., & Lorimer, S. E. (2004). Sales Force Design For Strategic Advantage. Palgrave Macmillan. (Comprehensive analysis of B2B sales force sizing, taxonomy, and strategic territory planning).
- Karwa, S. (2026). Hierarchical Sales Target Cascading using Directed Acyclic Graphs (DAGs) in Python. Towards AI. Available Online.
- Karwa, S. (2026). Graph-Theoretic Approaches to Hierarchical Revenue Target Allocation in B2B Enterprises: A Methodological Framework. SSRN. https://ssrn.com/abstract=6626318
- Scikit-learn Developers. (2024). scikit-learn: Machine Learning in Python (K-Means Clustering implementation details and limitations in discrete boundary taxonomy).
- SciPy Developers. (2024). SciPy: Open source scientific tools for Python (Implementation of scipy.optimize.linear_sum_assignment).
Mathematical Territory Design: Solving the B2B Allocation Problem with Operations Research was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.