How Machine Learning
The field of Machine Learning is generally categorized into four core approaches: Supervised, Unsupervised, Semi-supervised, and Reinforcement Learning. Here’s an overview of each.

Machine learning (ML) is a branch of artificial intelligence where systems learn from data to make decisions or predictions — without being explicitly programmed for every scenario. Think of it as teaching a computer through experience rather than rules.
ML is broadly divided into four learning paradigms: Supervised, Unsupervised, Semi-supervised, and Reinforcement Learning. Let’s walk through each one.

Supervised Learning
In supervised learning, the model learns from labeled data — meaning every input has a known, correct output. The model learns the mapping between inputs and outputs, so it can predict outputs for new, unseen inputs.
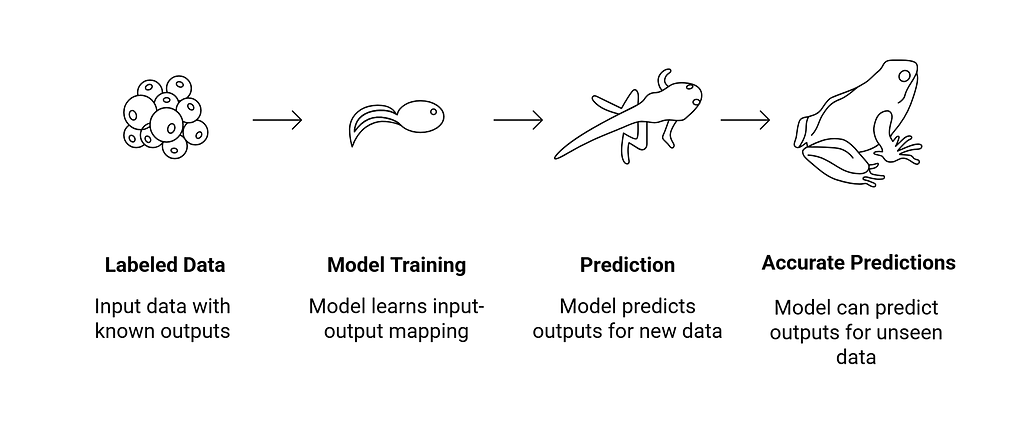
Supervised learning splits into two major tasks: Regression and Classification.
Regression
Regression is used when the output is a continuous number (e.g., predicting house prices, temperatures, or stock values).
Linear Regression is the simplest form — it fits a straight line through the data to predict the output.
Lasso Regression adds a penalty that can shrink some feature weights all the way to zero, effectively selecting only the most important features.
Ridge Regression similarly penalizes large weights but keeps all features, just smaller — useful when many features are slightly relevant.
State Space Models represent systems that evolve over time through hidden states, often used in control systems and signal processing.
Time Series deals with data collected over time (e.g., daily sales or stock prices). A key technique here is Autoregressive modeling, where past values of a variable are used to predict its future values.
Classification
Classification is used when the output is a category or label (e.g., spam or not spam, cat or dog).
Logistic Regression — despite its name — is a classification algorithm. It predicts the probability that an input belongs to a class.
Decision Trees split the data into branches based on feature values, like a flowchart that leads to a final decision.
K-Nearest Neighbors (KNN) classifies a new point based on the majority label of its K closest neighbors in the training data.
Naive Bayes applies probability theory (Bayes’ theorem) to classify inputs, assuming all features are independent of each other.
Random Forest builds many decision trees and combines their predictions — reducing the risk of overfitting that a single tree might have.
Support Vector Machine (SVM) finds the best boundary (hyperplane) that separates classes with the maximum margin between them.

Ensemble Learning
Ensemble methods combine multiple models to produce better predictions than any single model alone.
Boosting trains models sequentially — each new model focuses on correcting the mistakes of the previous one (e.g., XGBoost, AdaBoost).
Bagging trains multiple models independently on random subsets of data and averages their predictions — Random Forest is a classic example.

Self-supervised Learning
A twist on supervised learning where the model generates its own labels from the raw data (e.g., predicting the next word in a sentence). No human-labeled data is needed.

Transfer Learning takes a model already trained on one large task and fine-tunes it for a different, related task — saving time and data. This is the backbone of modern AI like GPT and BERT.
Unsupervised Learning
In unsupervised learning, the model works with unlabeled data and tries to find hidden patterns or structure on its own.
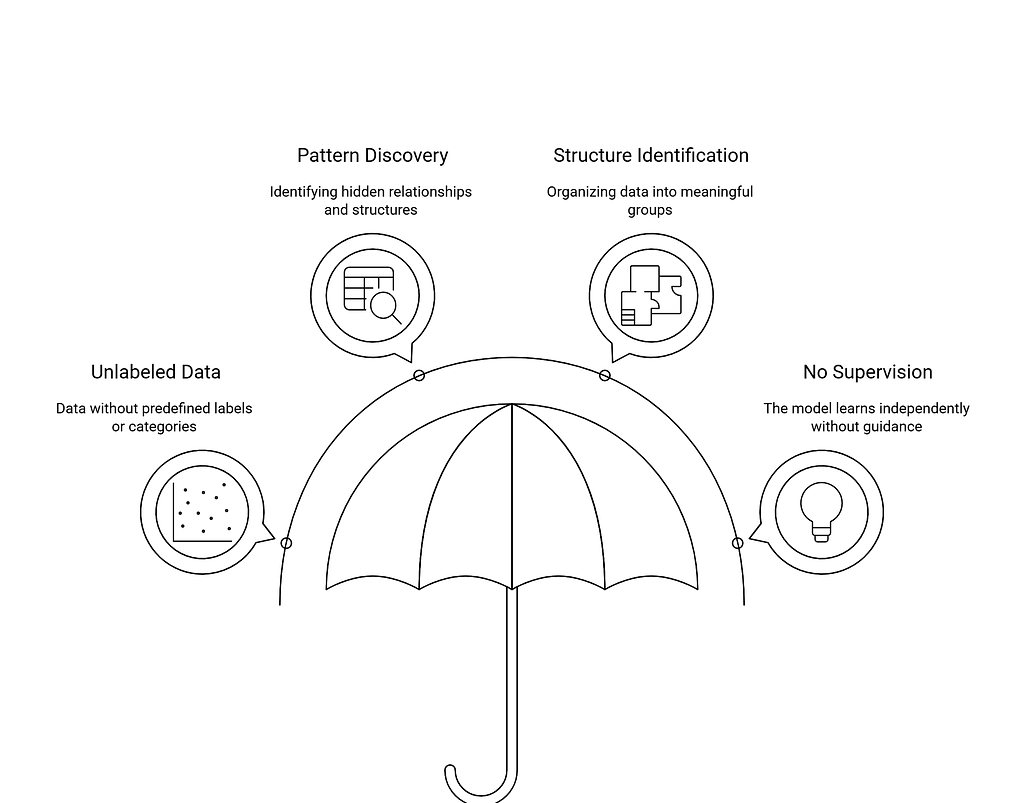
Clustering
Clustering groups similar data points together without predefined labels.
K-Means partitions data into K clusters by minimizing the distance between points and their cluster center.
Hierarchical Clustering builds a tree of clusters — either by merging small clusters up (bottom-up) or splitting large ones down (top-down).
Apriori Algorithm discovers association rules in data — famously used in market basket analysis (e.g., “customers who buy bread also buy butter”).
Gaussian Mixture Models (GMM) assume the data is generated from a mixture of several Gaussian distributions — a more flexible, probabilistic form of clustering.
Anomaly Detection
Anomaly detection identifies data points that deviate significantly from the norm — used in fraud detection, network security, and quality control.

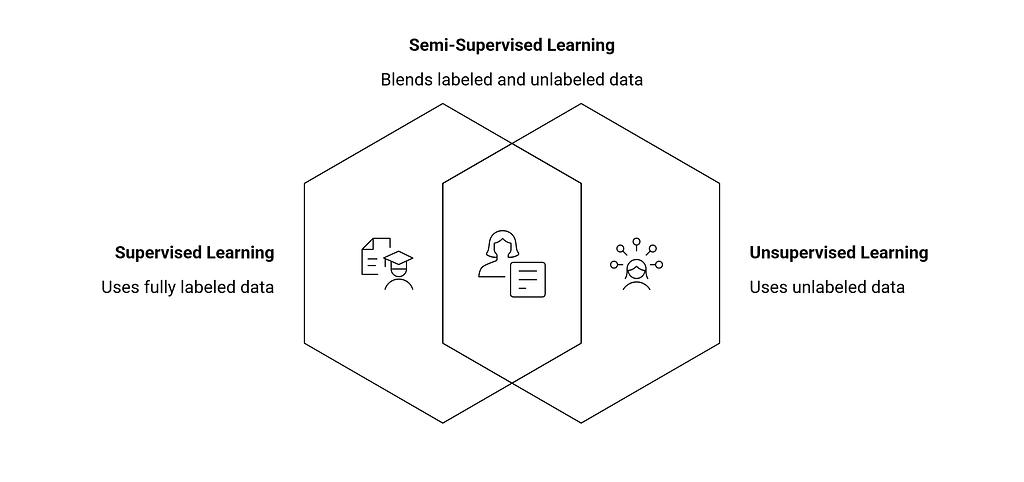
Semi-supervised Learning
Semi-supervised learning sits between supervised and unsupervised learning. It uses a small amount of labeled data combined with a large amount of unlabeled data — practical when labeling is expensive or time-consuming.
Recommendation Engines are a key application of this paradigm.
Collaborative Filtering makes recommendations based on the behavior of similar users — “people like you also liked…”
Content-based Filtering recommends items similar to what a user has previously liked, based on the features of the items themselves.
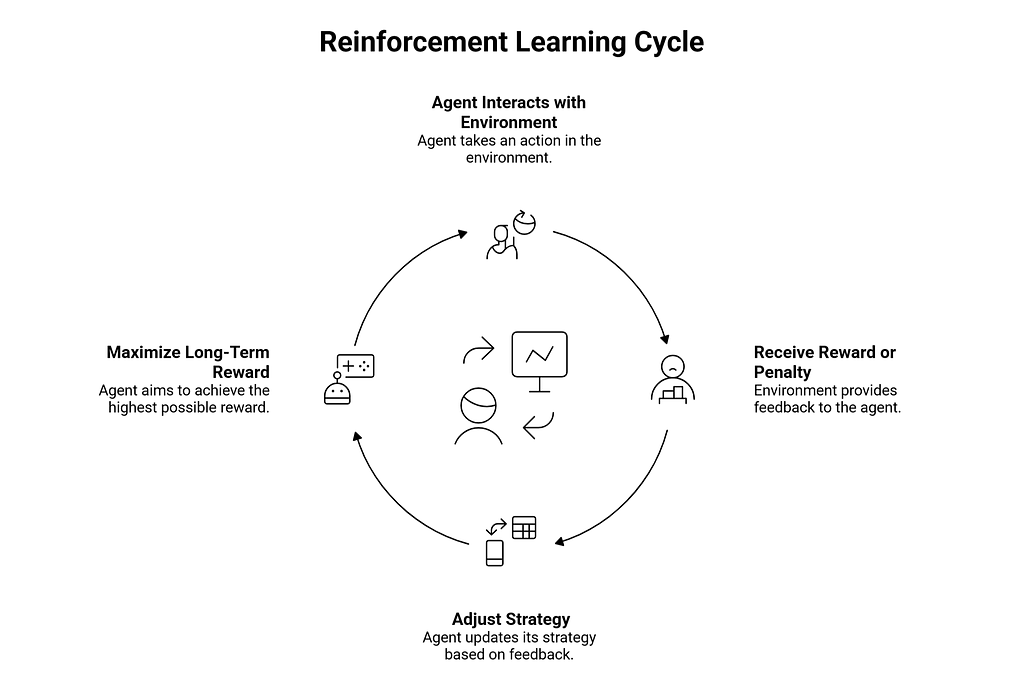
Reinforcement Learning
Reinforcement learning is fundamentally different from the others. Here, an agent learns by interacting with an environment — taking actions, receiving rewards or penalties, and adjusting its strategy to maximize long-term reward.
Think of it like training a dog: good behavior gets a treat, bad behavior doesn’t. Over time, the agent learns the optimal policy. This is the technology behind game-playing AI (like AlphaGo) and robotics.
By the way, it is better to share the map I built to understand all learning methodologies of machine learning which shows the journey of turning data to a model in easy way.

Conclusion
Let us have a quick overview:
- Supervised → Learn from labeled examples → Predict outputs
- Unsupervised → Find hidden structure → No labels needed
- Semi-supervised → Mix of both → Practical for real-world data
- Reinforcement → Learn through trial and error → Maximize reward
Each of these branches has deep rabbit holes worth exploring — and that’s exactly what we’ll do in the next articles in this series. Stay tuned.
Machine Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.