Shannon’s information theory, RoPE by hand, Gemma 4 rankings, and a free writing guide!
Good morning, AI enthusiasts!
This week, we’re covering what happens when AI labs sit across the table from governments, why most AI-generated writing still sounds the same (and how to fix it), and whether open models like Gemma 4 are ready to be ranked at all.
We also cover:
- A modular framework that goes from raw text to a knowledge graph in one command.
- The full eight-layer architectural evolution behind systems like ChatGPT, from stateless prompts to agentic assistants.
- Why traditional XAI methods fall short for multi-agent systems and what to build instead.
- Every major positional encoding method computed by hand, all the way up to RoPE.
- Why word embeddings trace back to Shannon’s 1948 information theory, not neural networks.
Let’s get into it!
What’s AI Weekly
As AI capabilities mature, the relationship between AI labs and governments is getting complicated, fast. You’ve probably seen the headline version of this story: Anthropic reportedly drew a line on mass surveillance and autonomous weapons, faced pushback from the U.S. government, and OpenAI stepped in to fill the gap. But the real story is more nuanced than that. Both companies were already doing defense work. Both were already in conversations with government agencies. The conflict wasn’t about whether AI companies should work with governments. It was about what happens when a government asks for broader terms and one company says no. This week, I break down what actually happened, what most coverage got wrong, and why this moment sets a precedent that goes well beyond one news cycle. Watch the full video here.
AI Tip of the Day
When tuning your RAG pipeline, chunk overlap is one of the most skipped parameters. Most implementations set it to zero or a fixed default.
Overlap controls how much content is repeated between adjacent chunks. Without it, retrieval can miss context that spans a chunk boundary: the first half of an explanation lands in one chunk, the second half in the next, and neither is retrieved in full. The model still returns an answer, but it is built on an incomplete context. Too much overlap, on the other hand, inflates your index size and slows retrieval without proportional gains in recall.
A good starting point is generally an overlap of 10 to 20 percent of your chunk size. Before scaling, evaluate retrieval recall on real queries from your domain.
This tip comes directly from our Full Stack AI Engineering course. If you want to build a complete RAG pipeline and go deeper into chunking, overlap tuning, and the full retrieval stack for production RAG, you can check out the course here (the first 6 lessons are available as a free preview).
— Louis-François Bouchard, Towards AI Co-founder & Head of Community
If you’ve ever used AI to write an email, a blog post, or a project update and spent more time editing the output than it would have taken to write it yourself, this is for you.
After 3+ years of editing the same AI slop out of every piece of content at Towards AI, we turned our pattern recognition into a reusable prompt template and are releasing it for free.

The Anti-Slop AI Writing Guide has 50+ banned AI phrases, style constraints, and a two-model workflow that catches slop before you ever read the draft. Paste it into any LLM, fill in your topic, and it works across emails, reports, blog posts, proposals, and more.
Download the guide, fill in your topic, and let the prompt do what you’ve been doing manually.
Learn AI Together Community Section!
Featured Community post from the Discord
Augmnt_sh has built AOP, an open protocol for real-time observability of autonomous AI agents. It is agent-native, i.e., events are emitted from inside the agent, capturing reasoning and intent, and all events are fire-and-forget HTTP POST with a 500ms timeout, so it doesn’t slow down or crash your agent. It is also vendor-neutral and local-first. Check it out on GitHub and support a fellow community member. If you have any feedback, share it in the thread!
AI poll of the week!
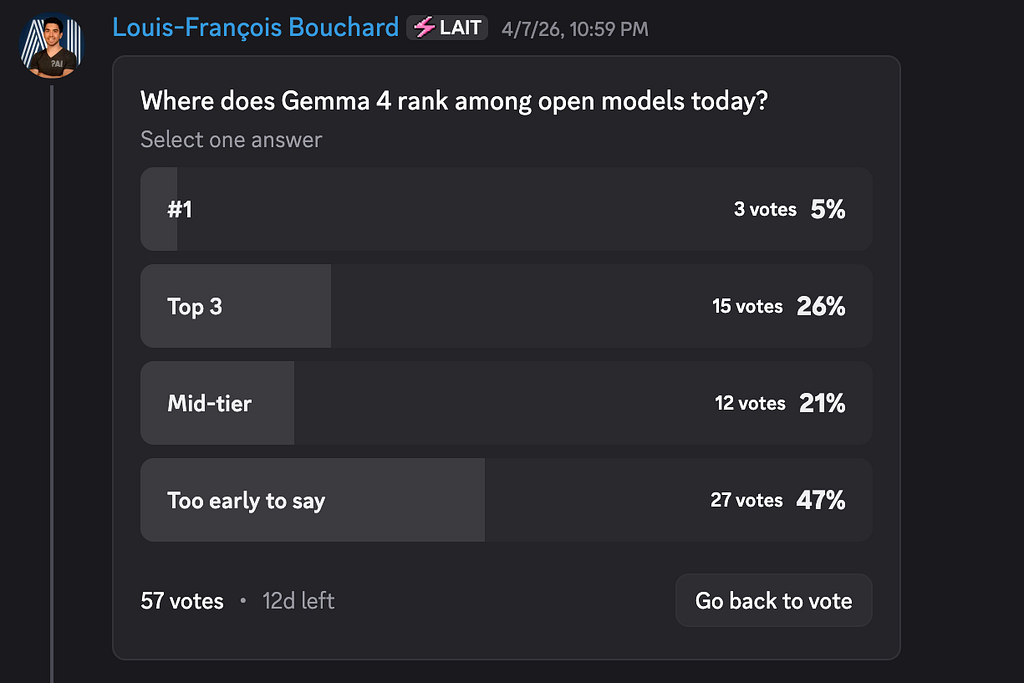
Almost half of you picked “too early to say,” while the rest is split between Top 3 and mid-tier, which shows that our selection criteria has changed from “is Gemma 4 the best?” to “are we ready to trust a ranking yet?” But Gemma 4 matters more for what it enables than for taking the crown: the last year of Chinese-lab dominance has produced some outstanding open models, but many are huge MoE systems that are awkward to self-host, costly to run cleanly, and for some Western enterprises, just complicated from a compliance standpoint. Gemma 4 gives those teams a credible alternative: US-origin, Apache 2.0-licensed, and practical to deploy on a single GPU, making it a real option for regulated sectors, air-gapped setups, edge devices, and anyone who needs control over data retention and customization.
When you choose a model stack, where do you personally fall on the spectrum: “I’ll trade some capability for control (self-hosting, data retention, offline)” vs. “I’ll trade control for capability (hosted APIs, fastest frontier models).” Let’s talk in the thread!
Collaboration Opportunities
The Learn AI Together Discord community is flooding with collaboration opportunities. If you are excited to dive into applied AI, want a study partner, or even want to find a partner for your passion project, join the collaboration channel! Keep an eye on this section, too — we share cool opportunities every week!
1. Canvas123 is looking for a peer or mentor to collaborate on projects involving machine learning, astrophysics, and general mathematics. If this is your field of expertise, connect with them in the thread!
2. Tanners1406 is building an orchestration platform and needs developers and early testers for the project. If this sounds interesting, reach out to them in the thread!
3. Jojosef6192 is specializing in Data Engineering and Analytics and wants to find a study partner to explore topics such as SQL, Data visualization, Azure Data Services, etc. If you are on a similar path and want to learn together, contact him in the thread!
Meme of the week!

Meme shared by ghost_in_the_machine
TAI Curated Section
Article of the week
From Text to Knowledge Graph in One Command: Building a Modular LLM-Backed Framework By Fabio Yáñez Romero
This post focuses on the architectural design and practical use of a Knowledge Graph Builder. It shows you how each module works, how they compose into a complete extraction-augmentation-visualization pipeline, and why swapping a provider, a domain, or an output format is a matter of changing one flag, not rewriting your pipeline.
Our must-read articles
1. Building Advanced AI Agents: A Complete Guide to ChatGPT Architecture By Ahmed Boulahia
The article traces the full architectural evolution of systems like ChatGPT across eight progressive layers, starting from a stateless single-turn prompt and building toward a complete agentic assistant. Each layer adds a concrete capability: conversation history for context, system instructions for behavioral control, structured outputs for machine integration, tool use for real-world data access, RAG for private and current knowledge, multimodal inputs for vision tasks, and persistent memory for cross-session personalization. It also includes cumulative code examples using GPT-5.4 and the OpenAI Responses API.
2. Explainable Agentic AI for Autonomous Task Allocation in Distributed Multi-Agent Systems By YUSUFF ADENIYI GIWA
Distributed multi-agent systems lack accountability when assigning tasks autonomously, and this piece makes the case for building explainability directly into that coordination layer. The author walks through why traditional XAI methods like SHAP and LIME fall short for sequential, multi-agent workflows, then covers architectures that address the gap: modular agent design, consensus-driven reasoning layers, and trace-based execution logs.
3. ROPE by HAND LIKE GOOD OLD TIMES By Dr. Swarnendu AI
Positional encoding shapes how Transformers understand word order, and the author walks through every major method using real arithmetic. Starting with the core problem of permutation-invariance, the piece computes sinusoidal, learnable, Shaw relative, T5 bucket, and ALiBi encodings by hand before deriving RoPE from first principles. The key insight is that rotating query and key vectors by position-dependent angles embeds absolute position while making the dot product a function of relative distance only.
4. The Full Journey By Hand: Co-Occurrence Table → PMI Matrix → SVD Truncation → Word Embedding. Why Cat and Mouse Are Close? By Dr. Swarnendu AI
Word embeddings trace back to Claude Shannon’s 1948 mutual information theory, not neural networks. The article walks through the full derivation by hand: building a co-occurrence matrix from a four-word corpus, computing Pointwise Mutual Information for every word pair, applying Positive PMI to handle zero co-occurrences, and using Truncated SVD to extract low-dimensional vectors. The result matches what Word2Vec produces, confirming Levy and Goldberg’s 2014 proof that Word2Vec implicitly factorizes a shifted PMI matrix.
If you are interested in publishing with Towards AI, check our guidelines and sign up. We will publish your work to our network if it meets our editorial policies and standards.
LAI #122: Word Embeddings Started in 1948, Not With Word2Vec was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.