Plus: the RAG debugging split most teams skip entirely!
Good morning, AI enthusiasts!
Your next AI system is probably too complicated, and you haven’t even built it yet. This week, we co-published a piece with Paul Iusztin that gives you a mental model for catching overengineering before it starts. Here’s what’s inside:
- Agent or workflow? Getting it wrong is where most production headaches begin.
- Do biases amplify as agents get more autonomous? What actually changes and how to control it at the system level.
- Claude Code’s three most ignored slash commands: /btw, /fork, and /rewind, and why they matter more the longer your session runs.
- The community voted on where coding agents are headed. Terminal-based tools are pulling ahead, but that 17% “Other” bucket is hiding something.
- Four must-reads covering Google’s A2A protocol, when SFT vs. DPO vs. RLHF vs. RAG actually applies, a time series model that finally listens, and a full clinic chatbot build.
We’re also starting a new section this week, AI Tip of the Day, where I share practical tips and takeaways from our courses that you can apply to your projects, read to understand where the industry is heading, and know what tools to focus on. This week, we’re kicking it off with RAG pipelines (if you’ve been here long enough, you know how much we love RAG) and its two failure modes that most of you don’t evaluate separately.
Let’s get into it!
What’s AI
This week, in What’s AI, I am diving into controlling biases in AI agents. Many people assume that as agents become more autonomous, biases will amplify. So today, I will clarify this assumption by explaining what bias actually means in the context of LLMs, why bias isn’t inherently bad, and what fundamentally changes when we move from a simple language model to an autonomous agent. We will also get into how to realistically control bias as autonomy scales, not just at the model level, but at the system level. Read the full article here or watch the video on YouTube.
AI Tip of the Day
To ensure your RAG retrieval is working correctly, split your evaluation into two layers. For retrieval, measure whether relevant evidence was retrieved using metrics like recall@k and Mean Reciprocal Rank. For generation, measure faithfulness to the retrieved context and the answer’s relevance to the question, often using an LLM judge calibrated against human labels.
High retrieval recall with low faithfulness suggests the model had the right evidence, but failed to use it properly. High faithfulness with low retrieval recall suggests the model stayed grounded in the retrieved context, but retrieval surfaced incomplete or off-target evidence. These are two completely different problems with two completely different fixes, and without the split, you can’t tell which one you’re dealing with.
If you’re currently building a RAG pipeline and want to go deeper into evaluation, retrieval strategies, and the full production stack, check out our Full Stack AI Engineering course.
— Louis-François Bouchard, Towards AI Co-founder & Head of Community
We have co-published an article with Paul Iusztin, covering the mental model that prevents you from overengineering your next AI system.
Here is what you will learn:
- The fundamental difference between an agent and a workflow.
- How to use the complexity spectrum to make architecture decisions.
- When to rely on simple workflows for predictable tasks.
- Why a single agent with tools is often enough for dynamic problems.
- The exact breaking points that justify moving to a multi-agent system.
Learn AI Together Community Section!
Featured Community post from the Discord
Aekokyreda has built an AI chat platform with RAG and real-time token streaming. The system delivers real-time, token-by-token AI responses using a fully decoupled microservices architecture. It is built with .NET 10 microservices using event sourcing, CQRS, Wolverine sagas, Marten, RabbitMQ, SignalR, Keycloak, and Kong, with an Angular 21 frontend powered by NgRx SignalStore. Check it out on GitHub and support a fellow community member. If you have any thoughts on the token streaming pipeline or the LLM provider abstraction, share them in the thread!
AI poll of the week!
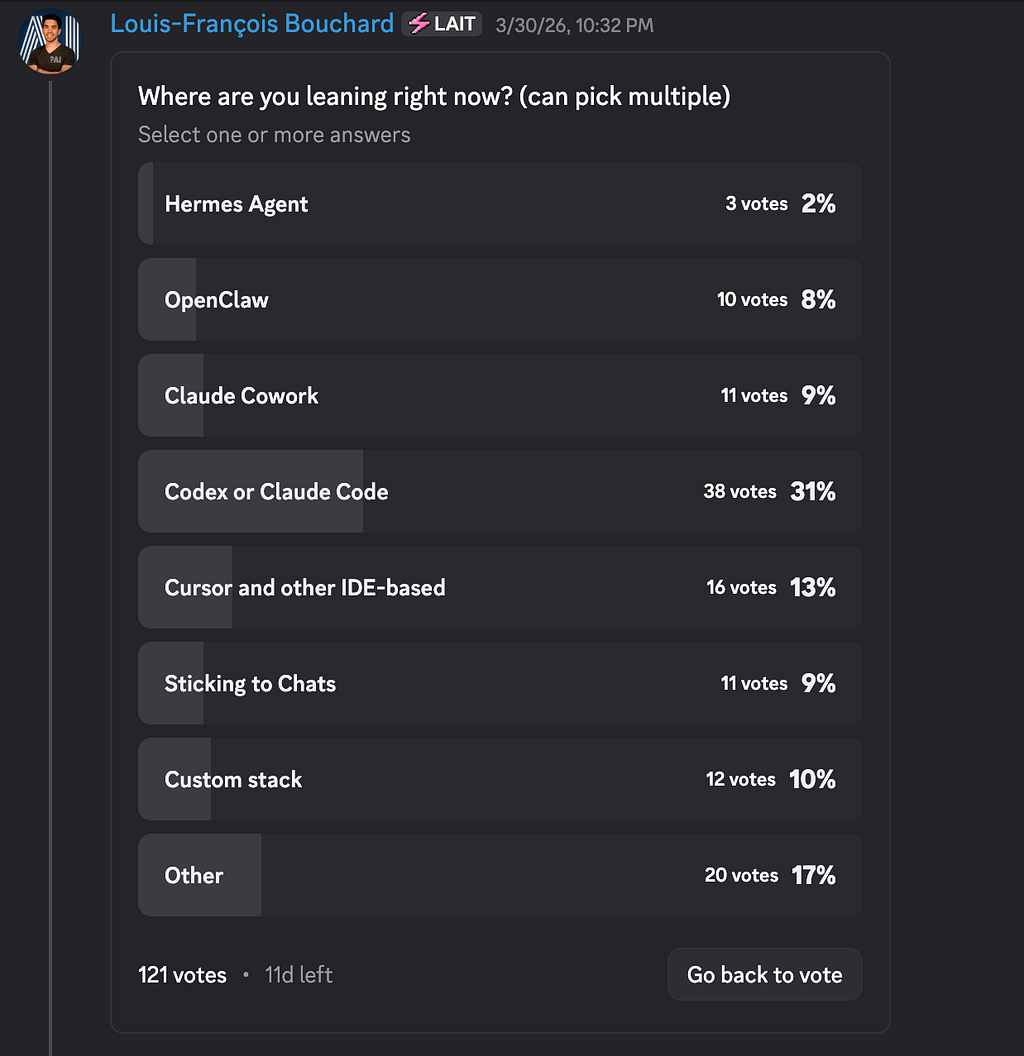
Most of you are leaning toward terminal-style coding agents (Codex/Claude Code) right now, with IDE-based tools (Cursor, etc.) in second place, and a smaller set either sticking to chat, running a custom stack, or testing newer agent products like OpenClaw/Claude Cowork. The interesting bit isn’t just who’s “winning,” it’s that the center of gravity is clearly shifting from asking for code to delegating changes across a repo, which is exactly where terminals and repo-aware agents feel natural. Also, that “Other” bucket is so big that it’s probably hiding many niche-but-real workflows that aren’t captured by the options. Share some in the thread!
Collaboration Opportunities
The Learn AI Together Discord community is flooding with collaboration opportunities. If you are excited to dive into applied AI, want a study partner, or even want to find a partner for your passion project, join the collaboration channel! Keep an eye on this section, too — we share cool opportunities every week!
1. Kamalesh_22497 is looking for people to learn and build with through study groups, project collaborations, and discussions. If you are on a similar path, connect with him in the thread!
2. Miragoat is looking for someone who wants to build something meaningful (and profitable). They are trying to combine practical business thinking with AI skills and need someone with a business mindset and an AI background. If that sounds like you, reach out to them in the thread!
3. Majestic_728 is looking for a beginner-level ML/DS study partner to study for an hour every day. If you are interested, contact him in the thread!
Meme of the week!

Meme shared by rucha8062
TAI Curated Section
Article of the week
Mastering Claude Code’s /btw, /fork, and /rewind: The Context Hygiene Toolkit By Rick Hightower
Context pollution degrades AI coding sessions by filling the context window with unrelated Q&A. This article covers three Claude Code commands that address this: /btw spawns a temporary agent to answer mid-task questions without affecting the main session context; /fork creates a parallel session that inherits the full conversation history for safe exploration; and /rewind rolls back bad code or conversation to a clean checkpoint. Together, they form a toolkit for maintaining a high signal-to-noise ratio across long sessions.
Our must-read articles
1. Google’s A2A Protocol using LangGraph: Build Agent Systems That Actually Communicate By Divy Yadav
Google’s Agent2Agent (A2A) protocol targets a persistent gap in enterprise AI: agents from different vendors cannot coordinate without custom glue code. The piece explains how A2A uses Agent Cards for discovery, structured task lifecycles, and HTTP-based messaging to enable cross-vendor agent collaboration across organizational boundaries. It contrasts A2A with MCP, clarifying that they solve distinct layers, and covers production failure modes, including timeout handling, context mismatch, and authentication drift.
2. What SFT, DPO, RLHF, and RAG Actually Do in an AI Agent By Shenggang Li
A working AI agent needs more than fluent replies. This article anchors each training technique to a customer support scenario. It shows exactly when each applies: SFT for correcting tone and task format through demonstrations, RAG for injecting business facts at inference time without touching model weights, DPO for selecting between two valid replies when one felt better, and RLHF for targeting the full decision path when the problem ran deeper than any single answer.
3. Your One-Stop Reference for PatchTST, Because It Is the Only Time Series Model Which Listens! By Dr. Swarnendu AI
The fundamental flaw in Transformer-based time series models is not the architecture but the token. Instead of encoding a single timestamp per token, the paper from Princeton and IBM Research sliced each series into overlapping patches, each representing a semantic time window. Paired with channel independence and Reversible Instance Normalization, the approach reduced MSE by 21% compared to prior Transformers on standard benchmarks. The article covers the full mathematics, a PyTorch implementation, and an honest map of when XGBoost still wins.
4. Agentic AI Project: Build a Customer Service Chatbot for a Clinic By Alpha Iterations
The article walks you through building a clinic appointment chatbot with end-to-end implementation using LangGraph, GPT-4o-mini, SQLite, and Streamlit. The system manages a multi-step conversational workflow across nodes, handling specialty selection, doctor display, time slot generation, and booking confirmation. A SQLite service layer abstracts database operations into reusable agent tools, while a MemorySaver checkpointer maintains session state across turns. The finished chatbot reduces administrative overhead and prevents scheduling conflicts through a clean, guided conversational interface that can be deployed as both a web app and a Jupyter notebook.
If you are interested in publishing with Towards AI, check our guidelines and sign up. We will publish your work to our network if it meets our editorial policies and standards.
LAI #121: The single-agent sweet spot nobody wants to admit was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.