10 experiments, 3 models, one honest verdict: the quality story is real, the speed story needs a disclaimer, and there’s a finding in the entropy data nobody talks about.
⏱ ~14 min read🔬 Deep Dive⚙️ LLM Inference🗜 Quantization🚀 Serving

When Google published TurboQuant at ICLR 2026, the headline was hard to ignore: compress your LLM’s key-value cache to 3 bits, keep quality intact, get up to 6× memory savings.
I built a 10-experiment evaluation pipeline, ran it across three models — Gemma-2B base, Gemma-2B-IT, and TinyLlama 1.1B Chat — and measured everything I could: factual accuracy, RAG retrieval quality, multi-task generation fidelity, throughput, memory footprint, layer sensitivity, and something most quantization write-ups skip entirely: what compression does to attention entropy.
What Is TurboQuant and Why It’s Different
Most KV-cache quantization schemes treat compression as a reconstruction problem: minimize mean squared error on cached vectors. TurboQuant is smarter than that. It targets the thing that actually matters for attention — inner-product preservation.
Stage 1 — PolarQuant
Each pair of consecutive vector coordinates gets converted to polar form (radius + angle). The radius stays in full float. The angle — which lives in a bounded, roughly uniform range after an optional random rotation — is quantized at low bitwidth. The rotation is the real trick: it spreads outlier energy so that scalar quantization on the angle isn’t wrecked by a few dominant values.
Stage 2 — QJL (Quantized Johnson-Lindenstrauss)
The reconstruction error from Stage 1 gets projected into a random subspace, and only the sign of each projection is stored — 1 bit per projection. The Johnson-Lindenstrauss lemma says random projections approximately preserve inner products. So this step specifically corrects for dot-product error that distorts attention scores, not just MSE. That distinction is what separates TurboQuant from naive quantizers.
Disclaimer: My implementation hooks into the model’s forward pass and compresses cached K and V tensors between decode steps using int8 containers with per-vector float16 scale factors. It is not a packed 3-bit kernel — it does not use fused CUDA or Triton. This distinction matters a lot for speed results and somewhat for memory results. I will be explicit about both throughout.
The Experimental Setup
Ten experiments, two phases. All text evaluations used a fixed external encoder (sentence-transformers/all-MiniLM-L6-v2) separate from the tested models. Throughput used a fixed 80-step greedy decode benchmark with alternating load order to reduce warm/cold GPU bias.
1. 3-Bit Is the Real Operating Point — and Entropy Explains Why
Start with the synthetic bit-depth comparison — PolarQuant alone vs. the full TurboQuant-style path on attention MSE and KL divergence.


The MSE table shows that 2-bit is worse, but it doesn’t explain why. The attention entropy experiment does. Entropy measures how focused or diffuse the softmax distribution is — high entropy means the model is attending broadly, low entropy means it’s locked onto a few positions.
The key distinction is between random key distributions (noise-floor conditions) and structured key distributions — vectors with dominant directional clusters, which is closer to what real LLM attention heads actually produce.
At 2-bit compression, structured key distributions experience a 65% entropy collapse — the quantizer is actively reshaping the attention geometry in ways that cut off access to broader context. This is not just elevated MSE. It is the underreported reason why 2-bit compression quietly damages multi-hop reasoning, long-document synthesis, and complex RAG chains.
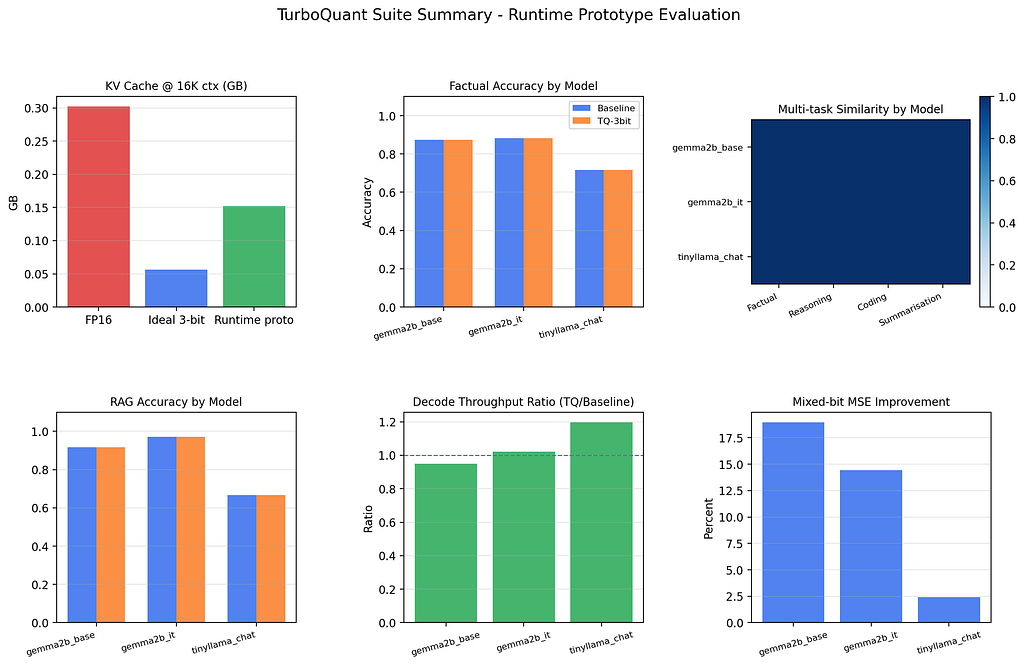
2. Quality Results Are Stronger Than Expected
Factual QA (40 questions, 3 seeds)
RAG-Style Context-Grounded QA (12 contexts, 3 seeds)
Multi-task semantic similarity (factual, reasoning, coding, summarization) between baseline and TQ-3bit generations: 1.0 across all categories and all three models.

3. The Memory Math Has Two Very Different Versions
For Gemma-2B (18 layers, MQA with 1 KV head per group, 256-dim heads), the idealized 3-bit target vs. what the int8 prototype actually stores:
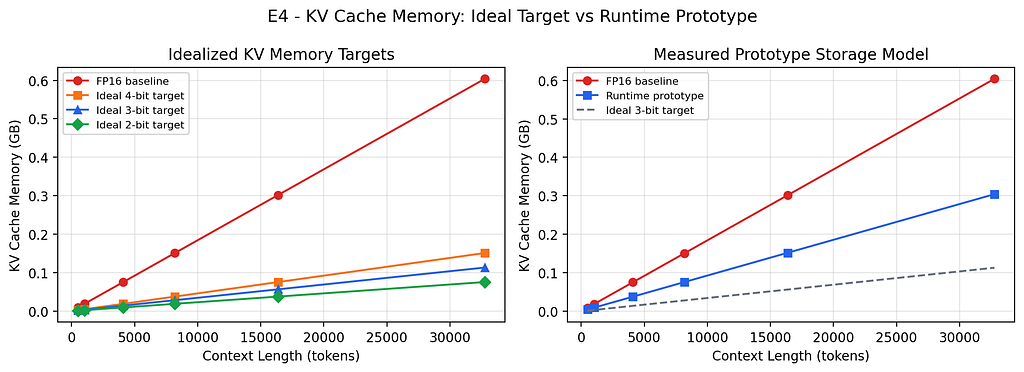
If someone tells you TurboQuant gives 5× memory savings, ask what storage backend they’re using. An int8 prototype gives ~2×. That’s still useful — it can extend context window or increase batch size on constrained hardware — but it’s a different product story. The ~5× headline requires truly packed sub-byte storage with custom memory layouts.
4. Speed Is Model-Dependent — Here’s the Honest Reason Why
Throughput sweep: 80 fixed greedy decode steps, 5 measured trials, 2 alternating rounds, three prompt lengths.
Headline (512-token prompt)
Full prompt-length sweep (TQ / Baseline ratio)
The speed question is not “is TurboQuant fast?” It is “is your model’s bottleneck memory bandwidth or arithmetic?” Faster models like TinyLlama spend proportionally more time on cache I/O — compressing the cache loosens that bottleneck. Compute-heavy models like Gemma-2B are less responsive. Know your bottleneck before optimizing for it.
5. Mixed-Bit Schedules Are an Easy Win Nobody Talks About
Layer sensitivity analysis showed that for both Gemma variants, compression sensitivity peaks in layers 7–10 — the middle of the stack. Uniform bit allocation is leaving quality on the table for free.
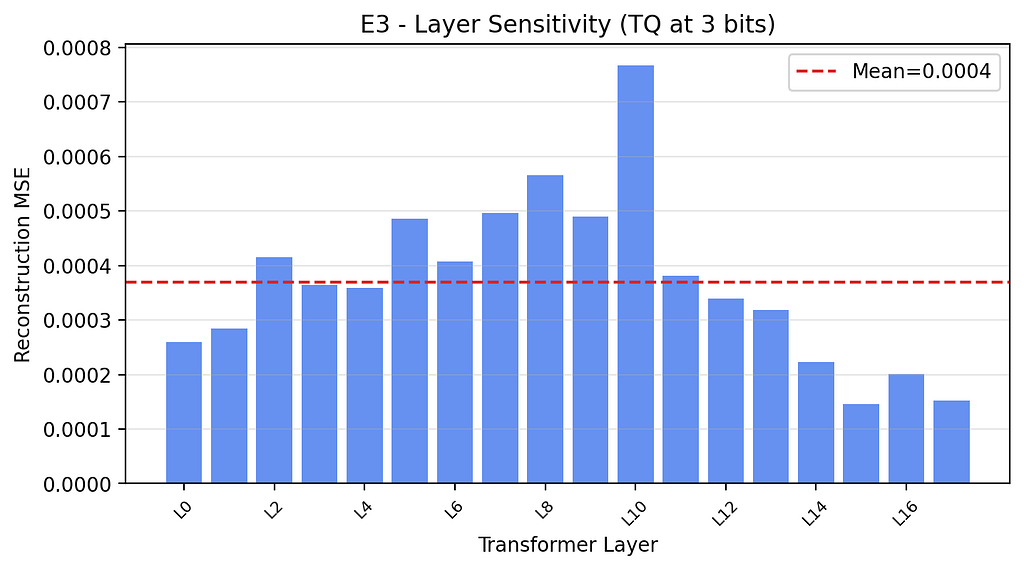
A sensitivity-ranked schedule — 4 bits for the top 25% most sensitive layers, 3 bits for the middle, 2 bits for the least sensitive — at ~2.94 effective bits:
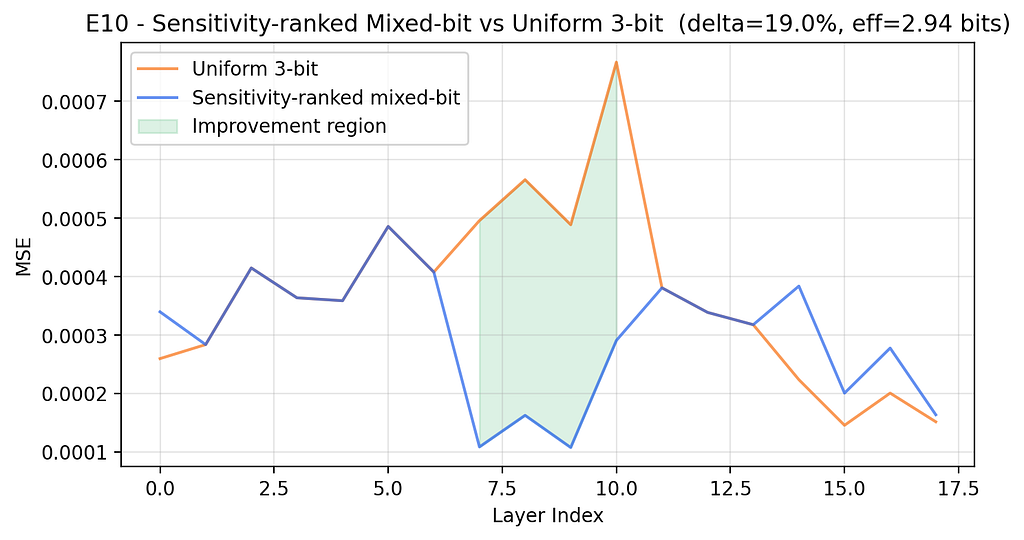
Here’s what the scan looks like in practice:
def compute_layer_sensitivity(model, bits=3):
"""Single-pass sensitivity scan over key-projection layers."""
sensitivity = {}
for i, layer in enumerate(model.model.layers):
W = layer.self_attn.k_proj.weight.data
W_hat, _, _, _ = turboquant_apply(W, bits)
mse = ((W - W_hat.to(W.dtype)) ** 2).mean().item()
sensitivity[i] = mse
return sensitivity
def build_mixed_bit_schedule(sensitivity, top_pct=0.25, bottom_pct=0.25):
"""Assign 4/3/2 bits by sensitivity rank."""
ranked = sorted(sensitivity.items(), key=lambda x: x[1], reverse=True)
n = len(ranked)
schedule = {i: 3 for i in sensitivity}
for idx, _ in ranked[:int(n * top_pct)]:
schedule[idx] = 4 # most sensitive → more bits
for idx, _ in ranked[-int(n * bottom_pct):]:
schedule[idx] = 2 # least sensitive → fewer bits
return schedule
One forward pass. Three lines of logic. ~19% MSE improvement on middle-weight models. If you’re building TurboQuant into an inference system, run this scan before defaulting to uniform bit allocation.
5 Things to Take Into Your Next Production Decision
- 3 bits is your quality-neutral default. 2 bits warps attention geometry on realistic key distributions. Validate thoroughly before deploying at that compression level.
- Plan memory budgets around ~2× today, ~5× eventually. The algorithm supports the headline. The engineering (packed sub-byte storage + fused kernels) doesn’t exist outside Google’s internal stack yet.
- Run a sensitivity scan before deploying uniform bitwidths. One forward pass, measurable quality improvement, essentially free.
- Speed gains are architecture-dependent. TinyLlama got 20–81% faster; Gemma-2B got 5% slower. Know whether your serving bottleneck is memory bandwidth or compute.
- The production win requires kernel integration. Watch vLLM and TensorRT-LLM for TurboQuant-style packed attention support. That’s when the throughput story changes.
The Bottom Line
TurboQuant is not a free 5x win you can drop into production tomorrow. It is more interesting than that.
The experiments suggest a clear distinction between the algorithmic promise and the current engineering reality. On quality, the results are encouraging: 3-bit quantization held up well, and the mixed-bit schedule helped stabilize the fragile middle layers in Gemma-2B. On memory, the theoretical savings are real, but today’s PyTorch implementation is limited by int8 containers and the lack of packed sub-byte kernels. On speed, the story depends heavily on the model and runtime path.
The most useful takeaway is not simply that “lower bits are better.” It is that quantization changes attention geometry. The 2-bit runs did not just add harmless noise; they collapsed entropy in structured key distributions, which helps explain why context-sensitive tasks degrade so quickly under aggressive compression.
That makes the practical lesson fairly concrete: treat 3-bit quantization as the safer default, scan layers before choosing a uniform bitwidth, and reserve 2-bit compression for places where the model can actually tolerate it. Mixed-bit scheduling is likely to matter more in production than headline compression ratios.
The algorithm is credible, the quality findings are promising, and the deployment story will ultimately be decided by kernel support. The paper numbers are worth taking seriously, but not blindly. The real production opportunity begins when packed storage and fused attention kernels catch up with the algorithm.
References
- Zandieh et al. (2026). TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate. ICLR 2026. openreview.net/forum?id=tO3ASKZlok
- Zandieh et al. (2025). arXiv preprint arXiv:2504.19874.
- Google Research Blog. TurboQuant: Redefining AI efficiency with extreme compression.
- Zandieh et al. (2024). PolarQuant: Leveraging Polar Transformation for Efficient KV Cache Quantization. AISTATS 2026.
- Johnson & Lindenstrauss (1984). Extensions of Lipschitz mappings into a Hilbert space. Contemporary Mathematics, 26.
- Kwon et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention. SOSP 2023. arXiv:2309.06180
- Ainslie et al. (2023). GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv:2305.13245
- Hooper et al. (2024). KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization. arXiv:2401.18079
- GitHub Repository with Source Code used for above expriments: github.com/quartzap/turboquant
Is 3-Bit KV Cache the Holy Grail? A Reality Check on Google’s TurboQuant was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.