A production-ready enterprise RAG+MCP
Most RAG demos stop at the fun part: an embedding model wired to a vector store, tweak every knob possible (hybrid retrieval, contextual retrieval, graph-based pre-chunking document tuning, etc, etc), and once it performs well in RAGAS or Deep Eval, they declare success (with humility). This essay walks through an honest effort at production readiness, adding evaluation and observability layers, then compares it against the shape the same system takes at full enterprise scale. It concludes with ideas for further betterment and a note on Confluence, Jira, codebases, and governance.
I spend my days working on a retrieval system for internal users at Accenture. I built a small repo on a public corpus to demonstrate the parts that comprise an enterprise RAG MCP.
Code: [github.com/kimsb2429/internal-knowledge-base](https://github.com/kimsb2429/internal-knowledge-base).
Three layers:
1. **Retrieval machinery**: ingestion, chunking, embedding, reranking, and the MCP surface that serves the retrieved chunks.
2. **The discipline layer**: eval-in-CI with a merge gate, per-trace observability, and the habit of reporting honest numbers.
3. **Architectural shape at full scale**: a comparison with an example enterprise microservice, worker parallelization, and multi-tenant access control.
§A — Retrieval machinery
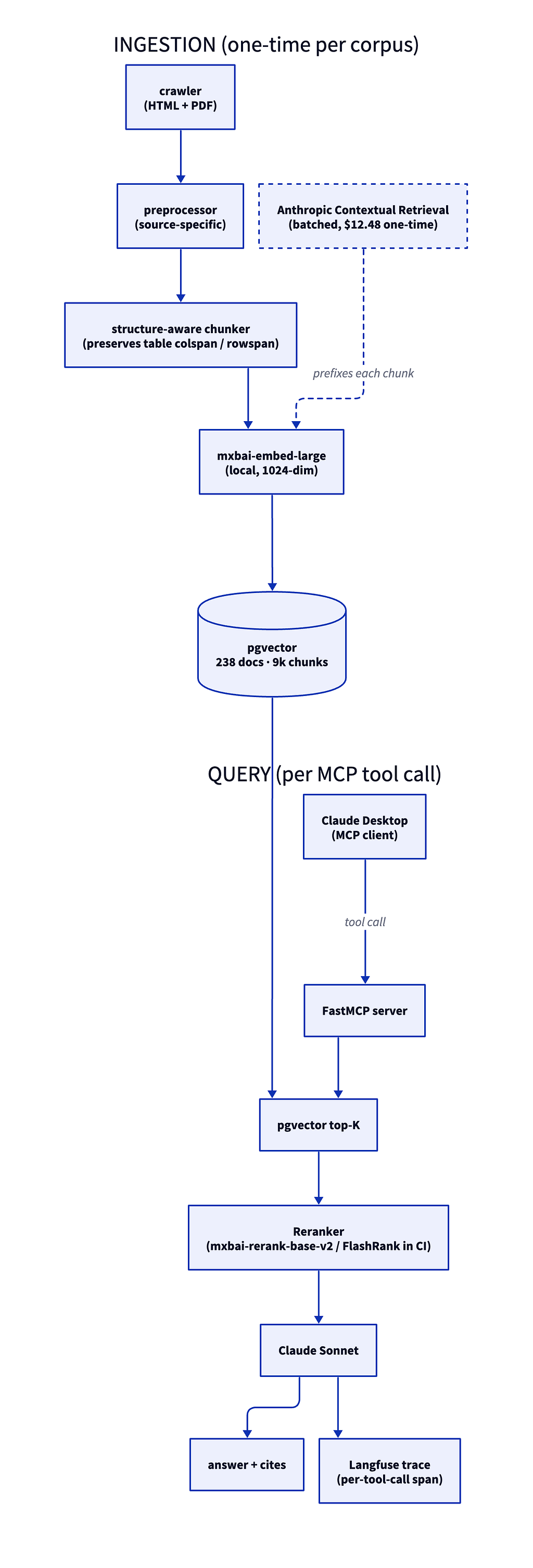
The pipeline follows a standard pattern for any RAG with a few things to note:
It uses structurally aware chunking, which is likely a good option for an internal knowledge base RAG of an enterprise. In this case the HTML tags provide the structural skeleton.
Embedding is local: mxbai-embed-large, 1024 dimensions, via sentence-transformers. That is a cost-based decision: a local model means ingestion can be re-run against the full corpus during iteration without metering an API, which matters because ingestion gets re-run a lot while the chunker is still being tuned. At my workplace we make the same trade-off for the same reason, with the specific model constrained by client agreements.
On top of the embed-and-store loop, the demo runs Anthropic Contextual Retrieval as a batched preprocessing pass. Contextual Retrieval rewrites each chunk with a short situating prefix so it carries document context into the embedding.
Anthropic’s published claim is roughly a 35% reduction in retrieval failure rate. On this corpus at this scale, the measured improvement was more modest: +4.8 percentage points on answer relevance and +4.1 points on context precision versus a no-context baseline. Real gain, well short of the headline number.
The reranker does a lot of the heavy lifting (more than the contextual preprocessing). This demo uses `mxbai-rerank-base-v2`; CI swaps in FlashRank, a small MiniLM ONNX model that fits comfortably in a GitHub CPU runner. Same retrieval shape, different weight class. (This is a good pattern for running evaluation harnesses cheaply on every PR.)
Finally, the FastMCP surface. Because the end users for me are internal users in Claude CLI, generation happens on the client, a likely pattern for most other enterprises.
§B — The discipline layer
Three mechanisms turn a RAG pipeline into something safely iterable: a merge-gate eval in CI, per-trace observability, and a reporting discipline.
**Eval-in-CI with a merge gate.** Every PR and every push to main runs a fast 30-query eval with FlashRank swapped in for the heavier production reranker. Four metrics gate the merge, with tolerances checked in as code:
- `top1_source_match_rate`: regression if it drops more than 5 percentage points
- `topk_source_match_rate`: regression if it drops more than 5 percentage points
- `answer_keyword_recall_mean`: regression if it drops more than 5 percentage points
- `idk_rate`: regression if it rises more than 10 percentage points
A full 110-query DeepEval run with the production reranker reports the richer metric set: faithfulness 0.95, answer relevance 0.91, context precision 0.61, context recall 0.52, context relevance 0.56.
The gate is inspectable. [PR #5](https://github.com/kimsb2429/internal-knowledge-base/pull/5) is a merged pull request that deliberately tripped the regression check, showed the failing CI run, was corrected, then passed and merged.
**Per-trace observability.** Every MCP tool call emits a span to Langfuse. Take a look using this public trace: [us.cloud.langfuse.com/project/cmo0wah7a00pfad071nk6x84c/traces/a574193bbff7d5438f7fae9e27f4bb83](https://us.cloud.langfuse.com/project/cmo0wah7a00pfad071nk6x84c/traces/a574193bbff7d5438f7fae9e27f4bb83). Query, retrieved chunks, reranker scores, generation, per-stage latency, token counts, all logged and observable.
**The numbers.** The precision and recall numbers above are not flattering. Part of the reason is the multi-hop reasoning golden queries that require more tuning. Worth noting again: the contextual-retrieval gain falls short of Anthropic’s published improvement on this corpus.
§C — Architectural shape at full scale
The demo runs in one process, which is not the same as an enterprise deployment with multiple tenants, compliance constraints, and independent release cadences. At scale, the shape changes, and it changes toward *simpler*, not cleverer.
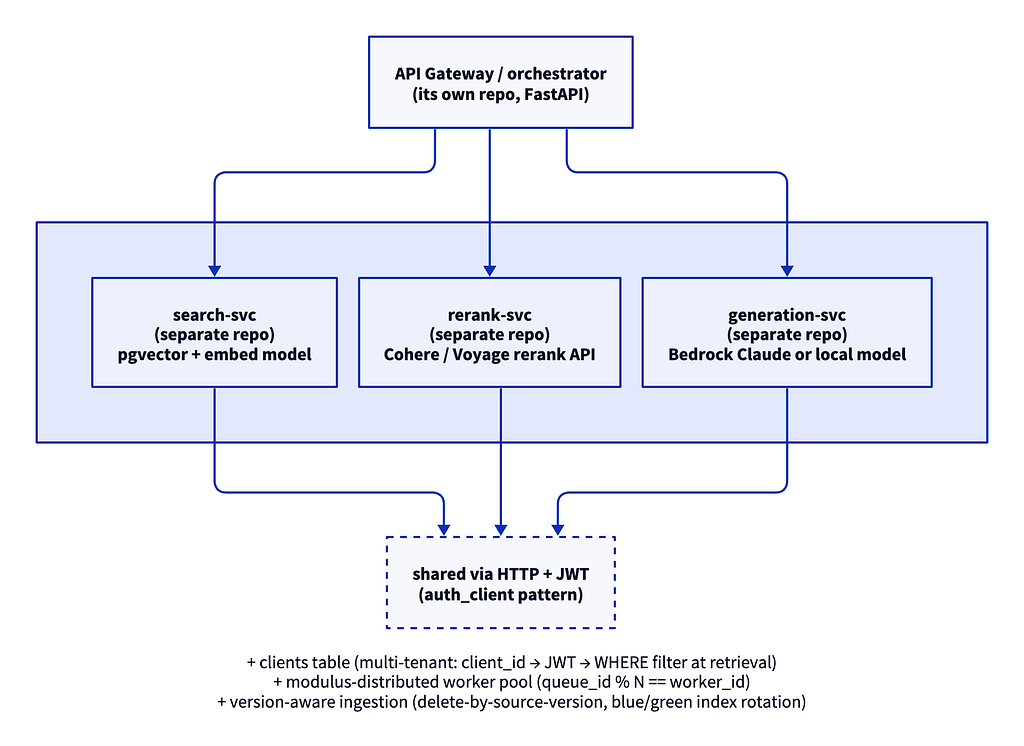
The microservice decomposition separates the `search` service, which owns the vector store and embedding model, from the `rerank` service, which handles post-processing and fallback mechanisms. A standalone reranker can be canaried at 5% of traffic, rolled back on a metric dip. The `generation` service is included for completeness, but the end users at my workplace use the MCP to access the RAG through their coding agents.
Distributed worker pool deterministically assigns a shard to each worker. Older than modern orchestration tooling, but effective in its simplicity.
Here is a side-by-side comparison of the demo pipeline and the microservices enterprise version (just the search service):

The search service has a default chunker built in, but it’s rarely used directly. Structure-aware preprocessing runs upstream in source-specific preprocessors (just like in the demo pipeline), and the search service receives already-chunked content.
It is also worth noting that ingestion clones a docs repo, adding another layer of modular simplicity critical for the design of a robust operation.
The discipline layer from Section B lifts into the platform at this shape. Eval and observability become cross-service concerns rather than in-process habits. The pattern is the same, applied to a larger surface.
Close
A successful production RAG needs all three layers: retrieval that preserves structure, discipline that makes iteration safe and observable, and architectural shape that keeps concerns decoupled.
Most enterprise internal-KB sources (Confluence pages, Jira tickets, source repositories, SharePoint exports) arrive as semi-structured documents whose layout carries meaning. Each source gets its own preprocessor to normalize into the structure-aware chunker. Atlassian MCP should serve you well, and codebases are better off with a sourcegraph cross-repo tree (rather than a RAG). I will elaborate on this in future articles. Useful research from industry frontrunners:
- Uber — Enhanced Agentic-RAG: What If Chatbots Could Deliver Near-Human Precision?
- Dropbox Dash — Building RAG with multi-step AI agents
- Dropbox Dash — How Dash uses context engineering for smarter AI
- Atlassian Rovo — Advancing semantic search for millions of Rovo users
- Atlassian Rovo — How Rovo solves search challenges through entity linking
- Sourcegraph — How Cody understands your codebase
- Sourcegraph — Lessons from building AI coding assistants: Context retrieval and evaluation
Enterprise RAG often also carries the load of governance as well: PII detection and redaction at ingestion, tenant-scoped access control at retrieval, audit trails tied to user identity, and data-residency constraints. In a regulated environment (FedRAMP High, HIPAA, etc.), every choice becomes constrained: observability backends must meet retention and audit requirements, the vector store must support encryption at rest. Microservice decomposition earns its keep here because governance controls apply at service boundaries, and tight boundaries are cheaper to audit than a monolith.
More discussions to come.
Internal Knowledge Base RAG MCP: POC-to-Production was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.