TL;DR
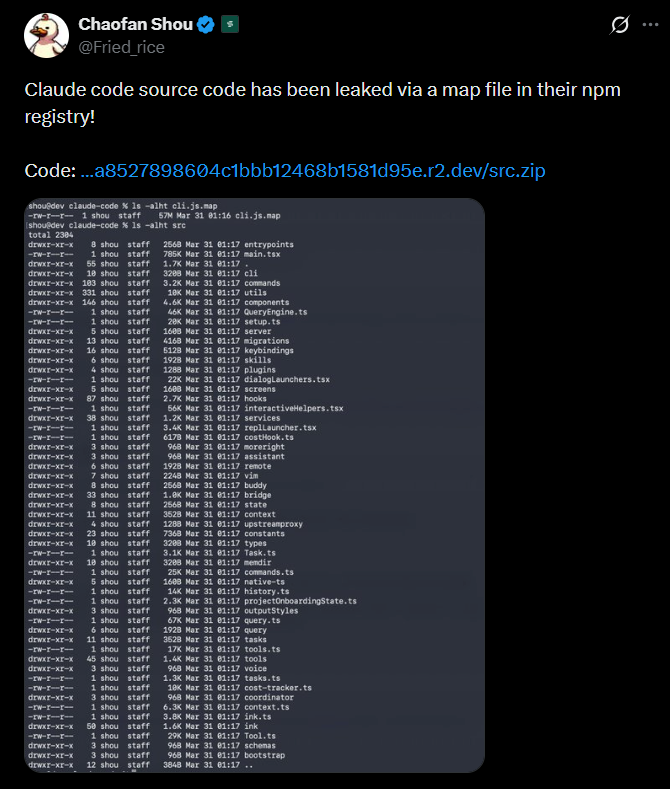
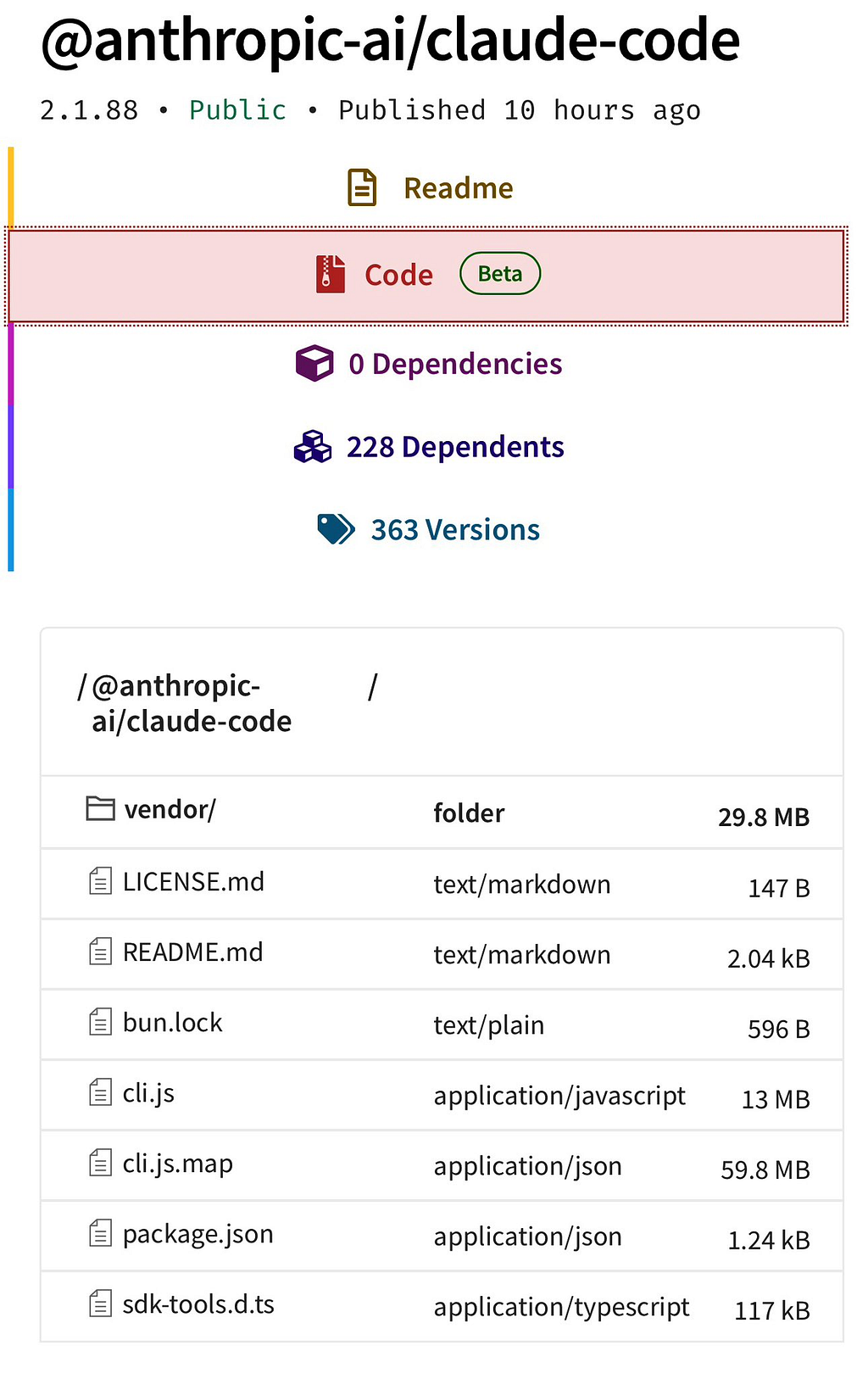
- On March 31, 2026, Anthropic accidentally published a 59.8 MB JavaScript source map file in version 2.1.88 of their @anthropic-ai/claude-code npm package, exposing the entire ~512,000-line TypeScript codebase.
- The root cause was a missing *.map exclusion in their publish configuration the bundler generates source maps by default, and no publish-time gate caught it before it went live.
- The leaked code reveals a product significantly more ambitious than its public surface: always-on background agents, 30-minute remote planning sessions, a Tamagotchi companion, and a multi-agent swarm orchestration system.
- The incident coincided with a supply-chain attack on the axios package during the same deployment window, compounding the blast radius for teams running npm install that morning.
- Reading the source reveals how Anthropic actually engineers AI agent systems at scale modular prompt caching, compile-time feature elimination, ML-based permission classification, and defensive prompt engineering around model failure modes patterns worth studying regardless of how the code got out.
Why This Matters
Anthropic is not a startup experimenting with AI wrappers. With a reported $19 billion annualized revenue run-rate as of March 2026 and Claude Code positioned as the flagship developer product, this incident is not a configuration footnote it is a case study in how sophisticated engineering organizations can be undone by a single missing line in a build configuration file.
What makes the leak particularly instructive is the contrast it exposes: Anthropic engineered a system called Undercover Mode specifically to prevent their AI from accidentally leaking internal information in open-source commits. They built a whole subsystem to stop Claude from mentioning internal codenames in pull request descriptions and then inadvertently shipped the entire codebase to the npm public registry via a .map file. That .map file was, in all likelihood, generated by Claude's own build toolchain.
The technical community response was immediate. Within hours, the codebase was archived across GitHub. One particularly notable response came from Kuber Mehta, who built claurst a clean-room Rust reimplementation of Claude Code’s behavior, reverse-engineered from behavioral specifications derived from the leak rather than carrying any original TypeScript forward. The project already has 4.9k stars and 5.9k forks, a signal of how much developer appetite there is to understand how this tool actually works. The version in question (2.1.88) has since been pulled from the npm registry, but the codebase is permanently mirrored across the internet. Anthropic cannot unpublish this.
How It Happened
Source maps exist so that when minified code crashes in production with a useless stack trace, a developer can trace it back to the original readable source. The .map file is a JSON structure and its sourcesContent field is not a pointer to the original code. It is the original code, embedded verbatim:
// A source map file (.map) — what it actually contains:
{
"version": 3,
"sources": ["src/main.tsx", "src/tools/BashTool.ts", ...],
// ⚠️ This field contains the FULL original source of every listed file
"sourcesContent": [
"// entire contents of main.tsx ...",
"// entire contents of BashTool.ts ..."
],
// Maps minified output positions back to original line numbers
"mappings": "AAAA,SAAS,OAAO..."
}
The sourcesContent field is optional in the spec, but most bundlers include it by default because it makes offline debugging possible. That means if you publish a package without explicitly excluding .map files, you've shipped your entire source tree to anyone who installs the package.
The fix is trivially simple any one of these three options would have prevented this:
Option 1 — Exclude .map files from your publish manifest:
Add "*.map" to your .npmignore file
Option 2 - Turn off source map generation for production builds:
Set sourcemap = "none" in your bundler config
Option 3 - Verify what you're shipping before every release (takes 10 seconds):
Run: npm pack --dry-run
Then check the output for any .map files
If you see any → stop, fix, repeat
The irony is structural: Anthropic built Undercover Mode specifically to prevent their AI from leaking internal information in open-source commits and then shipped the full source to npm in a .map file, most likely generated by the same build toolchain that Claude Code uses to build itself.
What Was Actually Leaked
The numbers alone are striking: nearly 2,000 source files, over 512,000 lines of code, a 59.8 MB source map, all sitting in the npm registry for hours before anyone noticed.
But the raw scale undersells the substance. What the leak reveals is not an overengineered CLI it is a production AI agent platform with a feature set substantially ahead of what Anthropic has publicly announced.
The Multi-Agent Orchestration System
Claude Code’s coordinator mode transforms the tool from a single agent into a full orchestration layer. The coordinator system prompt explicitly teaches parallelism: workers run concurrently, communicate via structured messages, and share state via a gated scratchpad directory. The prompt architecture reflects a mature understanding of multi-agent failure modes there is an explicit prohibition on lazy delegation, instructing the coordinator to “read the actual findings and specify exactly what to do” rather than passing vague directives down to workers.
The system also implements an agent swarm capability supporting in-process and process-based teammates, team memory synchronization, and color assignments for visual distinction of agents in the terminal. These are production engineering concerns, not research prototypes.
The Dream System
Background memory consolidation in Claude Code runs under a system called autoDream. It operates as a forked subagent independent from the main agent's context and is triggered by a three-gate system: at least 24 hours since the last run, at least five sessions since the last run, and a successfully acquired consolidation lock. All three gates must pass.
When triggered, the dream runs four phases: orient (read existing memory state), gather (find new signal worth persisting), consolidate (write and update memory files with absolute timestamps rather than relative ones), and prune (keep the memory index under 200 lines and ~25KB). The subagent has read-only access it can observe but not modify. The goal is a clean, high-signal context for the next session, maintained without human intervention.
The engineering rationale for forking a subagent rather than running consolidation in-process: it prevents the main agent’s context from being contaminated by its own maintenance operations the same isolation principle behind database vacuuming and log compaction in distributed systems.
KAIROS: Proactive Agency Without the Annoyance
KAIROS is a persistent background mode where Claude Code does not wait for user input it watches, logs, and acts proactively. The system uses append-only daily logs, receives periodic tick prompts, and maintains a 15-second blocking budget for any action that would interrupt the user’s flow. Actions exceeding that budget are deferred.
The KAIROS-exclusive tool set includes push notifications to the user’s device, the ability to subscribe to pull request activity, and file delivery. The “Brief” output mode extremely concise responses designed for persistent background operation reflects a real UX consideration: a background agent that generates paragraph-length responses on every tick would not survive user tolerance.
ULTRAPLAN: Offloaded Long-Horizon Planning
ULTRAPLAN delegates computationally expensive planning to a remote cloud container running Opus 4.6, giving it up to 30 minutes to reason through a complex task. The local terminal polls every three seconds. A browser-based UI lets the user observe the planning process and approve or reject the result. The approved result is then returned to the local session via a sentinel marker.
This mirrors human-in-the-loop approval flows common in enterprise automation, but its integration into a developer CLI reflects a bet that some planning tasks are genuinely worth the latency and infrastructure cost.
Undercover Mode: The Irony Is Load-Bearing
Undercover Mode exists because Anthropic engineers use Claude Code to contribute to public open-source repositories. When active, the system prompt instructs the agent not to include internal model codenames, project names, unreleased version numbers, or any indication that the commit was authored by an AI. The injected instruction reads:
## UNDERCOVER MODE - CRITICAL
You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository.
Your commit messages, PR titles, and PR bodies MUST NOT contain
ANY Anthropic-internal information. Do not blow your cover.
NEVER include in commit messages or PR descriptions:
- Internal model codenames (animal names like Capybara, Tengu, etc.)
- Unreleased model version numbers (e.g., opus-4-7, sonnet-4-8)
- Internal repo or project names
- Internal tooling, Slack channels, or short links
- The phrase "Claude Code" or any mention that you are an AI
- Co-Authored-By lines or any other attribution
The activation logic is deliberately conservative: the mode
turns on automatically unless the repo remote matches an internal allowlist.
There is no force-off flag. The leak confirms several things the mode was
designed to conceal: internal model codenames follow an animal naming
convention (Tengu, Fennec, Capybara, Numbat), and the project codename
for Claude Code itself appears to be Tengu, visible as a prefix across
hundreds of feature flag and analytics event names.
The Companion Nobody Knew About
Buried in the codebase is a feature that no product announcement has mentioned: a full Tamagotchi-style companion pet system called Buddy, gated behind a compile-time flag and completely absent from the public release.
Species are assigned deterministically via a seeded random number generator the same user ID always produces the same species:
// Deterministic species assignment — reproducible per user, every time
function assignBuddySpecies(userId):
seed = hash(userId) + salt("friend-2026-401")
rng = SeededRandom(seed) // same input → same output, always
roll = rng.nextFloat() // number between 0.0 and 1.0
// Rarity tiers - cumulative probability:
if roll < 0.60 → Common (Pebblecrab, Dustbunny, Mossfrog ...)
if roll < 0.85 → Uncommon (Cloudferret, Gustowl ...)
if roll < 0.95 → Rare (Crystaldrake, Deepstag ...)
if roll < 0.99 → Epic (Stormwyrm, Voidcat ...)
else → Legendary (Cosmoshale, Nebulynx)
// Shiny is a separate independent 1% roll - unrelated to rarity
isShiny = rng.nextFloat() < 0.01
// A Shiny Legendary Nebulynx: 1% × 1% = 0.01% chance
Each buddy gets procedurally generated stats across five axes (DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK), ASCII art sprites with idle and reaction animations, and a personality description generated by Claude on first hatch. The companion can respond when addressed by name, using a system prompt that establishes it as a separate watcher not Claude itself.
Species names are obfuscated in the original source via character-code arrays, which tells you Anthropic specifically didn’t want them surfacing in a simple string search of the binary. The code references May 2026 as the planned public launch.
The Security Compounding Factor
The source map disclosure would have been significant on its own. What made March 31 materially worse was its overlap with an unrelated supply-chain attack.
Users who installed or updated Claude Code via npm between 00:21 and 03:29 UTC on March 31, 2026 may have pulled in a malicious version of the axios HTTP client containing a cross-platform remote access trojan. The dependency plain-crypto-js is the indicator of compromise. Any team whose lockfile contains axios versions 1.14.1 or 0.30.4 should treat the host as fully compromised, rotate all secrets, and perform a clean reinstallation.
Additionally, threat actors moved quickly to exploit awareness of Claude Code’s internal private package names revealed by the leak by publishing typosquat packages. These were empty stubs at time of writing, consistent with the name-squatting phase of a dependency confusion attack: squat the name, wait for installs, push a malicious update.
Anthropic has designated the native installer (curl -fsSL https://claude.ai/install.sh | bash) as the recommended installation method going forward, as it uses a standalone binary outside the npm dependency chain.
What the Leak Reveals About the Model Roadmap
Several unreleased model references appear throughout the codebase. Capybara is the internal codename for an upcoming Claude model family, with a fast variant and a 1M context window in preparation. Opus 4.7 and Sonnet 4.8 are explicitly referenced. Migration functions reveal the naming history: Fennec mapped to Opus 4.6, Sonnet with 1M context became Sonnet 4.5, then 4.6, with Numbat still in testing.
The production engineering around Capybara is illuminating. The code documents a real failure mode observed in production: Capybara would prematurely stop generating when the prompt structure resembled a turn boundary after a tool result. The mitigation was prompt-shape surgery injecting a safe boundary marker, relocating content blocks, and adding placeholder text for empty tool outputs. All of this is gated behind named feature flags for staged rollout and rapid revert. The presence of A/B test evidence in code comments suggests these changes were launch-critical.
How Anthropic Actually Writes AI Agent Code
This is where the leak earns its keep. Forget the model roadmap hints and the Tamagotchi the most durable value in 512,000 lines of leaked source is the engineering craft. Reading production code from a team that has been building AI agents longer and at higher stakes than almost anyone else is a rare education. Several patterns stand out.
System Prompts as Modular, Cached Architecture
Most teams treat a system prompt as a string. Anthropic treats it as a compiled artifact with explicit cache boundaries.
Claude Code’s prompt is built from modular sections composed at runtime, divided into two tiers content that’s the same for every user (safe to cache) and content that’s unique per session (must never be cached):
// How Claude Code assembles its system prompt at request time:
━━━ STATIC SECTION (cached - identical for every user) ━━━━━━━━━
· Core agent behavior and personality
· Tool descriptions and usage rules
· General safety instructions
↑ These never change per-request, so they're cached and reused.
Anthropic pays to process them once, not on every API call.
════ SYSTEM_PROMPT_DYNAMIC_BOUNDARY ════
━━━ DYNAMIC SECTION (never cached - unique per request) ━━━━━━━━
· Current user's preferences and name
· Active project context and file structure
· Session-specific state and conversation history
↑ These change every request. Caching them would serve stale data.
// Any section that intentionally breaks cache is named:
// DANGEROUS_uncachedSystemPromptSection(...)
//
// The DANGEROUS_ prefix is deliberate - it signals "this choice
// was made on purpose" so a future engineer won't silently
// "fix" it by adding caching and introduce a subtle bug.
The lesson transfers to any team using LLMs at scale: prompt caching isn’t just a cost optimization it’s a correctness concern. If you’re not explicitly partitioning what can and can’t be cached, you’re either overpaying or accidentally serving stale context. The naming convention is the real takeaway: making invisible trade-offs permanently visible in the code.
Feature Gates as First-Class Citizens
The entire Claude Code codebase is governed by two layers of feature gatingc ompile-time flags that physically remove code from external builds, and runtime flags with aggressively cached values:
// TWO-TIER FEATURE GATING SYSTEM
The _CACHED_MAY_BE_STALE naming is the real lesson. Not all feature decisions need real-time data. For flags controlling UI behavior or non-critical paths, a slightly stale value is almost always better than adding a network call to the hot execution path. The name makes that trade-off a permanent, visible decision rather than an accident waiting to be "fixed."
Defensive Prompt Engineering Around Model Failure Modes
The production engineering around the Capybara model reveals something most teams never document: what happens when the model itself misbehaves, and how you ship a fix without waiting for a new model release.
// REAL PRODUCTION FAILURE MODE — documented in source comments
── Tier 1: Compile-time gates ──────────────────────────────────────
Evaluated when the binary is BUILT, not when it runs.
A false flag doesn't hide code - it deletes it from the binary.
External users literally cannot access internal features because
those features don't exist in their version of the program.
Pseudocode:
BUILD_FLAG "KAIROS" = false (for public release)
IF KAIROS is enabled at build time:
→ compile in proactive agent code
ELSE:
→ remove it entirely (dead-code elimination)
→ zero trace in the external binary
── Tier 2: Runtime gates ───────────────────────────────────────────
Evaluated while the program is running.
Allow staged rollout and instant revert without redeploying.
Values are fetched from a feature flag service, heavily cached.
Key naming convention in the source:
getFeatureValue_CACHED_MAY_BE_STALE("feature-name")
^^^^^^^^^^^^^^^^^^^
This suffix signals: "we know this value might be slightly old,
and we've decided that's acceptable - don't 'fix' this cache."
── Why both layers? ────────────────────────────────────────────────
Compile-time → hard security boundary (internal = truly gone)
Runtime → operational flexibility (ship fast, roll back faster)
Problem:
Capybara (unreleased model) sometimes stops generating mid-response.
It gets confused when the prompt "looks like" a conversation boundary
right after a tool returns output - and thinks its turn is over.
Before fix (triggers premature stop):
─────────────────────────────────────
[Tool returned this output]
{ "status": "success", "data": "..." }
← Model sees this shape and sometimes halts here
After fix (prompt-shape surgery):
──────────────────────────────────
[Tool returned this output]
Tool loaded. ← Injected safe boundary marker
{ "status": "success", "data": "..." }
Continue with your response. ← Reminder folded into tool result
Empty outputs get a placeholder:
"" → "[no output]"
(prevents the model from seeing a blank and stopping)
Rollout discipline:
· Entire fix wrapped in a named feature flag → instant rollback if needed
· Code comment: "un-gate once validated on external via A/B"
· Internal users are the canary lane before public rollout
· A/B test evidence cited in comments - not hand-wavy, measurable
What’s notable is not the specific fix that’s model-specific and temporary. What’s notable is the discipline: the failure mode is documented, the fix is reversible, and the removal condition is written directly in the code. Most teams doing prompt engineering are still fixing these issues by editing a string and hoping for the best.
The Three-Gate Trigger Pattern
The autoDream system’s trigger logic is a clean example of a general pattern for scheduling background work that should happen regularly but not too often, and never concurrently:
// THREE-GATE TRIGGER — all three must pass or the job is skipped
function shouldRunMemoryConsolidation():
GATE 1 - Time:
Has it been at least 24 hours since the last run?
NO → skip. (Too soon. Nothing meaningful will have changed.)
YES → check gate 2.
GATE 2 - Volume:
Have at least 5 new sessions happened since the last run?
NO → skip. (Not enough new signal to justify the work.)
YES → check gate 3.
GATE 3 - Concurrency lock:
Can we acquire the consolidation lock right now?
NO → skip. (Another instance is already running. Avoid collision.)
YES → proceed. Run the consolidation job.
// Why three separate gates?
// Each one addresses a distinct failure mode:
// Gate 1 → prevents running too frequently (wasteful, noisy)
// Gate 2 → ensures there's meaningful new data to process
// Gate 3 → prevents two concurrent runs from corrupting shared state
//
// A single "run every 24 hours" cron would only catch gate 1.
// You need all three to get the behavior right.
This pattern is well-understood in database maintenance (vacuuming, log compaction) and distributed systems (leader election, garbage collection), but it rarely appears this cleanly in application-layer code. If you’re writing “run this background job occasionally,” this is the structure worth reaching for.
The Permission System as a Separate Reasoning Layer
Claude Code’s permission system is not a simple allow/deny list it’s a layered architecture that wraps all tools uniformly, so security logic never lives inside individual tool implementations:
// LAYERED PERMISSION ARCHITECTURE
// (applies to every tool, without exception)
User requests an action: "delete all log files in /var/logs"
│
▼
┌───────────────────────────────────────────────────┐
│ TOOL LAYER │
│ The tool (e.g. BashTool) receives the request. │
│ It has NO permission logic of its own. │
└──────────────────────┬────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────┐
│ RISK CLASSIFICATION LAYER │
│ Every action is classified automatically: │
│ LOW — read-only, no lasting side effects │
│ MEDIUM — writes data, but recoverable │
│ HIGH — destructive or irreversible │
│ │
│ This action: HIGH (mass deletion, can't undo) │
└──────────────────────┬────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────┐
│ EXPLANATION LAYER │
│ A separate AI call generates a plain-English │
│ explanation of the specific risk: │
│ │
│ "This will permanently delete all .log files │
│ in /var/logs. This action cannot be undone." │
│ │
│ (Not a hardcoded string — generated per action, │
│ so it always reflects what's actually happening)│
└──────────────────────┬────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────┐
│ APPROVAL LAYER │
│ LOW → auto-approve (or ML classifier decides) │
│ MED → prompt the user │
│ HIGH → always require explicit user approval │
│ │
│ Some files are hardcoded as never auto-approved: │
│ .gitconfig, .bashrc, .zshrc, .mcp.json, etc. │
└───────────────────────────────────────────────────┘
The key insight is architectural: security decisions are not embedded in individual tool implementations they live in a separate layer that wraps everything uniformly. This means the security policy can evolve without touching any tool code. For teams building AI agents, the temptation is to add permission checks inside each tool. The Claude Code architecture shows why that doesn’t scale.
Ownership at the Code Level
One small detail that says a lot about engineering culture. The security-critical instruction block carries this comment at the top:
// ─────────────────────────────────────────────────────────────────
// ⚠️ IMPORTANT: DO NOT MODIFY THIS INSTRUCTION WITHOUT
// SAFEGUARDS TEAM REVIEW
//
// Owner: Safeguards team (David Forsythe, Kyla Guru)
//
// This section defines the security boundary for what Claude Code
// will and will not help with. Changes here are not a routine
// code review — they require explicit sign-off from the owners.
// ─────────────────────────────────────────────────────────────────
This is the kind of comment that either already exists in your codebase for your most sensitive invariants, or it doesn’t. Encoding ownership directly in code provides something access controls don’t: visible provenance for future engineers. It answers “who decided this and why” without requiring a git archaeology expedition. For security-critical paths in particular, this practice is worth adopting deliberately.
What Engineering Leaders Should Take Away
The build pipeline is a security surface. This leak was not caused by a sophisticated attacker. It was caused by a build tool generating a file that was not excluded from a publish manifest. Every team shipping proprietary code as packages should audit their ignore files and bundler configuration. The check is one command: npm pack --dry-run.
Feature flags are not a security boundary. The internal features in Claude Code - KAIROS, ULTRAPLAN, Coordinator Mode, Buddy are hidden from external builds via compile-time dead-code elimination. But source maps don’t care about dead code elimination. Everything that exists in the source is embedded in the .map file, including code the bundler removed from the output binary.
The gap between internal and external builds is widening. The Claude Code source reveals a product substantially more capable in its internal configuration than in its public release. The gap here proactive background agents, 30-minute offloaded planning, push notifications, swarm orchestration suggests the public Claude Code experience is a conservative subset of what Anthropic’s internal teams are actively using. For engineering organizations evaluating AI coding tools, this should inform expectations about the trajectory of public releases.
Incident response matters as much as prevention. Anthropic moved quickly to pull the affected package version, but the internet had already mirrored the codebase. The additional supply-chain attack on axios during the same window underscores that multiple failure modes can compound in a single incident window. Post-incident rotation of secrets and credential hygiene are not optional steps.
Further Reading
- claurst — Clean-room Rust reimplementation of Claude Code — Kuber Mehta’s behavioral reimplementation, the most technically substantive community response to the leak
- Source Map Specification (v3) — The formal spec, including the sourcesContent field behavior
- Abusing Exposed Sourcemaps — Sentry Blog — Real-world examples of source map exploitation, including account takeover via undocumented endpoint discovery
- OWASP npm Security Cheat Sheet — Canonical reference for npm publish security, including dependency confusion mitigations
- VentureBeat: Claude Code Source Code Leak Coverage — Timeline and security impact summary
- The Hacker News: Claude Code Leak and Axios Supply Chain Attack — Coverage of the concurrent axios RAT incident and mitigation steps
Thanks for reading! If you have any questions or feedback, please let me know on Medium or LinkedIn
Inside Claude Code’s Leaked Source: What 512,000 Lines Tell Us About Building AI Agents was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.