Moving from CNN’s Low-Level Visual Features to Deep Semantic Embeddings with SigLIP.

Convolutional Neural Networks (CNNs) have important semantic limitations: while they capture low and mid-level visual features (such as edges, textures, and colors), they often fail to encode the high-level global and semantic context that Vision-Language Models (VLMs) provide.
A previous story illustrated that recommendations relying solely on ResNet50 embeddings can include semantically irrelevant items. To mitigate this issue, I had to implement an additional filtering layer using Filtered k-NN in Elasticsearch.
The goal of this story is to illustrate how VLMs can improve embedding quality, resulting in better recommendations. Concretely, this story leverages the SigLIP (Sigmoid Loss for Language-Image Pre-training) model from Google DeepMind to extract image embeddings.
Before we start, you might be interested in the following other stories, closely related to this one:
- Building a Basic Image-Based Recommendation System,
- Building an Image-Based Recommendation System and Search Engine with Deep Learning and Elasticsearch,
- Building a Smarter Image Search with Gemini and Elasticsearch,
- From ANN Libraries to Vector Databases.
1. Using SigLIP as Image Embedding Extractor
Paper “Improving Visual Recommendation on E-commerce Platforms Using Vision-Language Models” [1] from Yuki Yada et al. at Mercari (a leading C2C e-commerce platform in Japan), demonstrates that moving from a CNN model to a fine-tune SigLIP (Sigmoid Loss for Language Image Pre-Training) model led to a 50% increase in Click-Through Rate, and a 14% boost in Conversion Rate 🚀.
Having read the paper, I decided to try using the SigLIP model [2] as an embedding extractor. As fine-tuning the SigLIP model is beyond the scope of this article, I am using the pre-trained weights from Google that are available on Hugging Face. I will publish a separate article focusing on the SigLIP model.
The code snippet below defines an ABC class called Image Embedding Extractor for embedding extractors, as well as a concrete implementation for the SigLIP model. I decided to proceed this way so that I can easily experiment with other embedding models, for which I will then create different concrete implementations of the ImageEmbeddingExtractor class.
from abc import ABC, abstractmethod
from typing import List
import numpy as np
from PIL import Image
import torch
from transformers import AutoProcessor, AutoModel
class ImageEmbeddingExtractor(ABC):
@abstractmethod
def extract_embeddings(self, image_paths: List[str]) -> np.ndarray:
"""Extract embeddings for a batch of image paths."""
pass
class SigLIPEmbeddingExtractor(ImageEmbeddingExtractor):
def __init__(self, model_name="google/siglip-base-patch16-224"):
self.processor = AutoProcessor.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
self.model.eval()
def extract_embeddings(self, image_paths: List[str]) -> np.ndarray:
images = [Image.open(path).convert("RGB") for path in image_paths]
inputs = self.processor(images=images, return_tensors="pt")
with torch.no_grad():
embeddings = self.model.get_image_features(**inputs)
embeddings = embeddings.pooler_output
return embeddings.detach().cpu().numpy()
Please find the complete source code in the related GitHub repository.
2. Refactor Embeddings and Search Methods
In a previous story, I have defined methods for embedding extraction, kNN search, and recommendation. For this story, I refactored these methods to support dynamic model selection by passing the model as an explicit input.
from elasticsearch import Elasticsearch
import os
MODEL_FIELD_MAPPING = {
"resnet": "image_features",
"siglip": "image_features_siglip",
"vertex_api": "image_features_vertex_api"
}
def extract_embeddings_and_update_es(
es: Elasticsearch,
embedding_extractor: ImageEmbeddingExtractor,
model: str = "resnet",
index_name: str = "items",
batch_size=128
):
# query ES to get all the image path
query = {
"size": batch_size,
"query": {
"bool": {
"must_not": {
"exists": {"field": MODEL_FIELD_MAPPING.get(model)}
}
}
}
}
response = es.search(index=index_name, body=query, scroll="5m")
scroll_id = response["_scroll_id"]
while True:
items = response["hits"]["hits"]
if not items:
break
# batch processing
paths = [
os.path.join(DATASET_DIR,
item["_source"]["imPath"]) for item in items
]
embeddings = embedding_extractor.extract_embeddings(paths)
bulk_update_embeddings(es, index_name, items, embeddings, model)
# continue scrolling
response = es.scroll(scroll_id=scroll_id, scroll="5m")
print("DONE: all embeddings updated.")
def knn_search(
es: Elasticsearch,
item_id: int,
index_name: str="items",
model: str="resnet",
k: int=10,
num_candidates: int=100,
apply_filter: bool=False
):
"""
Performs a KNN search using the specified model's embeddings.
"""
# Query Elasticsearch to get all the fields of the referenced item
res = es.get(index=index_name, id=item_id)
ref_item = res['_source']
# Determine which field to use based on the model
field_name = MODEL_FIELD_MAPPING.get(model, "resnet")
# Check if the reference item has the required embedding
if field_name not in ref_item:
raise ValueError(f"""The reference item does not have embeddings
for field '{field_name}'.""")
# build the knn query. Add a filter on the category if
# apply_filter is enabled
knn_query = {
"knn": {
"field": field_name,
"query_vector": ref_item[field_name],
"k": k+1, # +1 to account for the reference item
"num_candidates": num_candidates
}
}
if apply_filter:
knn_query["knn"]["filter"] = {
"term": {
"category": ref_item['category'][0]
}
}
# execute the knn query
res = es.search(index=index_name, query=knn_query)
knn_items = res['hits']['hits']
return ref_item, knn_items[1:]
Refer to this notebook for the complete code.
3. ResNet vs SigLIP Recommendation Results
The following are the recommendations resulting from the ResNet and the SigLIP embeddings, respectively.
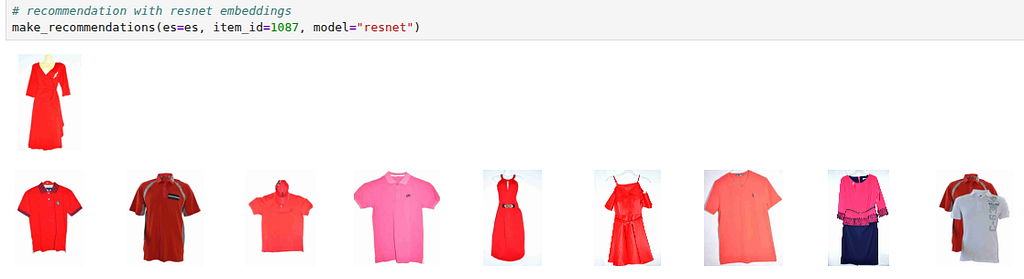
ResNet results
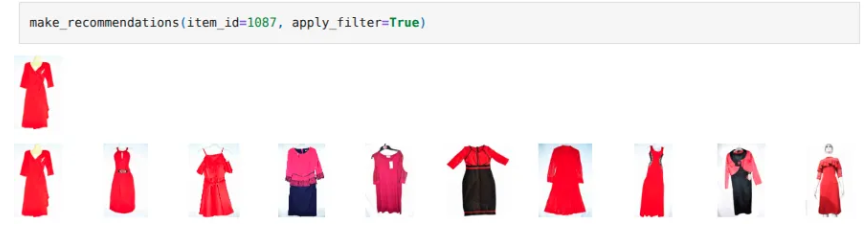
In order to improve the results of the recommendations, I applied Elasticsearch’s Filtered kNN. The resulting recommendation was as follows:
SigLIP results

Observations
When the ResNet model processes the red dress (the query image), it focuses on small, basic details such as the red color and a V-neck.
- What it does well: It is very good at finding other items that have the same shade of red or have the same sleeve style.
- Where it fails: It doesn’t really understand that the item is a “dress”. This is why the results showed red shirts. To ResNet, a red shirt is “close enough” because the color and top-half shape match, even though it’s a completely different type of clothing.
The SigLIP model is much smarter because it processes the entire image at once. It understands the concept of what it is seeing.
- What it does well: It correctly identifies the item as a dress (without any additional filtering using Filtered kNN). Because of that, it suggests other dresses. It understands that a black or blue dress is a much better recommendation for a red dress than a red shirt would be.
4. Visual Search Engine Results
In the bonus part of this story, we explored how to use Elasticsearch to perform visual search. The search engine consisted of three steps:
- Get the Query Vector: extract embeddings of the query image with the ResNet model,
- Perform a kNN search with Elasticsearch using the extracted Query Vector,
- Display the recommended product.
The search results using ResNet were as follows. It includes items that are not semantically related to the query image. To address the semantic gap, I needed to use an image classifier model (few-shot image classification with Gemini) to identify the category of the query, then perform a filtered kNN search based on the predicted category. More details are available in the “Building a Smarter Image Search with Gemini and Elasticsearch” story.

Search Results with SigLIP-based Embeddings
The following are the search results when using SigLIP. It provides significantly higher-quality results. Unlike ResNet, it successfully filters out irrelevant categories such as men’s footwear and children’s items.

A key differentiator is SigLIP’s ability to retrieve items outside the immediate “shoes” category, such as dresses and blazers. This suggests two sophisticated search behaviors:
- Style Matching: The model identifies these items as belonging to a similar aesthetic or “women’s fashion” cluster.
- Predictive Styling: The results can be interpreted as a “Complete the Look” feature, identifying dresses that would naturally pair with the specified shoes.
Summary
This story illustrates how VLMs (SigLIP in this case) capture more semantic information than CNNs (ResNet50 in this case). As a result, VLMs can produce higher-quality embeddings. Higher-quality embeddings produce better recommendations and search results.
Thanks for reading. 🙏
If you found this story useful, encourage me to produce such content by:
👉 Following me on Medium,
👉 Connecting with me on LinkedIn and GitHub,
References
[1] Yuki Yada et al. (2025) — Improving Visual Recommendation on E-commerce Platforms Using Vision-Language Models — Mercari.
[2] Xiaohua Zhai et al. (2023) — Sigmoid Loss for Language Image Pre-Training — Google DeepMind.
Improving Visual Recommendations with Vision-Language Model Embeddings was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.