A technical but approachable guide to how large language models handle memory — from the math behind statelessness to the engineering behind systems that make AI feel like it actually knows you.
An LLM is just a math function. A stateless one.
Let’s start with the uncomfortable truth. At its core, a large language model — at inference time — is nothing more than a parameterized mathematical function. It takes an input, runs it through billions of learned parameters, and produces an output.
Y = fθ(X)
Here, X is your input (the prompt), θ (theta) represents all the learned weights baked into the model during training, and Y is the output — the response the model generates.
Simple. But here’s the kicker: this function is stateless.
What does “stateless” actually mean?
Stateless means that when the function runs, it holds no memory of the past. Every single call to fθ(X) is completely isolated. The function doesn’t know if it’s the first time you’ve ever talked to it or the thousandth. It has no internal variable that says “last time this user said X.” It doesn’t accumulate experience. It doesn’t change based on history.
Think of it like a calculator. You press 5 + 3 and get 8. Then you press + 2 expecting 10 — but the calculator doesn’t remember the previous answer unless you explicitly carry it forward.
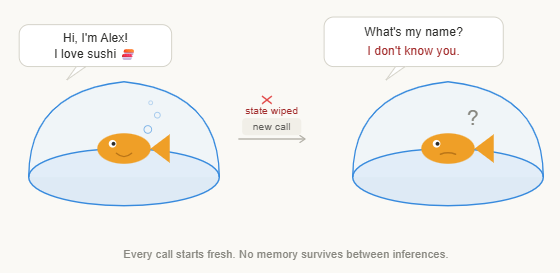
The fundamental fact LLMs have no intrinsic memory. There is no hidden state being updated between conversations. The model you’re talking to right now has zero awareness of any prior interaction — unless that information is explicitly provided to it.
The Context Window: The only memory an LLM truly has
So if LLMs are stateless, how do they seem to “remember” things you said three messages ago within a conversation? The answer is the context window.
The context window is essentially everything the model can “see” at once when generating a response. It’s a fixed-size buffer of tokens (words, subwords, characters) that gets fed into the model on every single inference call. When you’re in a conversation, the system works by concatenating the entire conversation history — your messages and the model’s replies — and passing it all in as one big input.
So every time the model responds, it isn’t “remembering” — it’s re-reading the whole conversation from scratch and generating the next token accordingly. This is what’s called in-context learning: the model uses the context window as a dynamic scratchpad, pattern-matching against everything provided to produce coherent responses.
Conversations are called “threads”
In most LLM systems, a single conversation is called a thread. Each thread has a unique identifier and stores all the messages exchanged within it. When you send a new message, the system fetches the thread’s message history, appends your new message, and sends the whole thing to the model.
How a thread works
thread_001 User: “What’s the capital of France?”
thread_001 Model: “Paris is the capital of France.”
thread_001 User: “What’s its population?” — The model sees the entire thread above, so it knows “its” = Paris.
This is Short-Term Memory (STM) — memory that exists only within the lifetime of a single thread. It works beautifully within a conversation, but it comes with serious structural limitations.
Why Short-Term Memory is not enough
STM via the context window is clever engineering, but as a memory system it is fundamentally fragile, finite, and isolated. Let’s break down each failure mode.
1. It is fragile
Context windows can be accidentally corrupted, overwritten, or lost. If a thread is reset, cleared, or not properly stored between requests, all memory is gone. A single session crash = total amnesia.
2. The token limit problem
Every model has a maximum context window size. As conversations grow longer, they eat up tokens. Eventually, you hit the wall — and the model either truncates old messages, loses coherence, or errors out entirely.
3. It is thread-scoped
Memory dies when the thread ends. Start a new conversation and the model has no idea who you are, what you prefer, or what you discussed yesterday.
Solution to fragility
Persist every message to a database keyed by thread ID. When a new message arrives, fetch the full message history from the database for that thread and reconstruct the context window dynamically. Thread ID 1 has its messages in the DB, Thread ID 2 has its own — nothing bleeds over, and nothing gets lost on crash.
Solving the token limit problem
When conversations grow longer than the context window allows, systems use progressively smarter strategies:
- Trimming
Drop the oldest messages from the context window once it fills up. Simple, but lossy — early context is permanently gone.
2. Summarisation
Periodically compress older messages into a shorter summary. Preserve meaning, discard verbosity. More token-efficient but can lose nuance.
3. Hybrid
Keep recent messages verbatim (trimming), replace distant history with summaries. Best of both worlds — recency plus compressed history.
4. Modern LLMs
Models like Gemini 1.5 support 1M+ token windows, making trimming and summarisation far less urgent within a single session — but cross-session memory still requires external solutions.
Solving thread-scoped isolation — the hardest problem
This is the deepest structural flaw of STM, and it has three downstream consequences that compound painfully over time:
Loss of user continuity across conversations. Every new thread is a blank slate. The model has no idea you told it your preferences last week, that you’re working on a specific project, or that you hate long bullet-pointed answers.
Learning never compounds over time. Even if you correct the model, explain your workflow, or give detailed instructions in one thread — that knowledge evaporates. The model doesn’t get “smarter about you” over time.
Cross-thread reasoning is impossible. The model can’t connect something you mentioned in Thread 1 with a problem you’re describing in Thread 50. Insights from past sessions are permanently siloed.
The verdict on STMShort-term memory via context windows is adequate for single-session tasks but structurally incapable of supporting the kind of persistent, evolving understanding we expect from a truly intelligent assistant. We need something else entirely.
Long-Term Memory: The solution STM can’t provide
Long-Term Memory (LTM) in LLM systems is the architectural layer that allows a model to remember information across threads, sessions, and time. Unlike the context window — which is ephemeral, auto-cleared, and token-bound — LTM lives in persistent external storage that the system actively manages.
The key mental model: LTM is not inside the model. It is around it. It’s a set of external systems — databases, vector stores, retrieval pipelines — that intercept conversations, extract important information, and inject relevant memories back into future context windows when needed.
The three types of Long-Term Memory
- Episodic — “What happened?”
Episodic memory stores events and experiences — specific things that occurred in past interactions. “Last Tuesday, the user said their project deadline is end of April.” “In thread #23, the user mentioned they dislike formal tone.” It’s the equivalent of a diary: timestamped, contextual, experiential. It exists because raw factual memory alone can’t capture the when and why of information, which is critical for relevance.
Example: “User asked about React hooks on March 15 and said they were new to frontend development.”
2. Semantic — “ What is true? ”
Semantic memory stores general facts and beliefs about a user or the world — distilled truths extracted from many interactions. “The user is a Python developer.” “The user prefers concise answers.” “The user is based in Berlin.” Unlike episodic memory, semantic memory is de-contextualised — it doesn’t record how the fact was learned, only that it is (probably) true. It exists to give the model a stable model of who the user is without re-reading hundreds of past conversations each time.
Example: “User: Senior software engineer, prefers TypeScript, dislikes explanations with too many analogies.”
3. Procedural — “ How to do it? ”
Procedural memory stores instructions, workflows, and behavioral preferences — “how to interact” knowledge. “When summarizing code for this user, always include the file path.” “This assistant is connected to a GitHub repo and should check issue status before answering.” It’s less about facts and more about protocols. It exists because users and applications need AI assistants that follow consistent operating procedures, not just ones that know facts.
Example: “Always respond in the language the user writes in. Never mention competitors. Format code blocks with filenames.”
How Long-Term Memory actually works: the 4 steps

Step 01 — Creation / Update
The system monitors conversation in real-time. It looks at what the user said, what the model responded, what was implicit or explicit. An extraction layer — sometimes another LLM call — decides: “Is there anything worth remembering here?” New facts, corrections, preferences, and key events get written to the memory store.
Step 02 — Storage
Memories are stored externally — in vector databases (for semantic search), relational databases (for structured facts), or key-value stores (for quick lookups). Storage isn’t just “save the text.” It involves embedding the memory into a vector representation so it can be searched semantically later — finding relevant memories even when the exact words differ.
Step 03 — Retrieval
Given the current input, the system queries the memory store: “What do I know that’s relevant right now?” This is selective, not exhaustive. You don’t dump all memories into the context — that would defeat the purpose. Instead, you retrieve the top-K most relevant memories using semantic similarity, recency, or importance scoring.
Step 04 — Injection
Retrieved memories are injected into the model’s context window — typically in a system prompt block before the conversation. The model never “knows” it’s consulting a memory system; it simply sees relevant context at the top of its input and uses it to ground its response. Memory influences behavior entirely through the context window.
Key insight on retrieval : Retrieval must be selective, not exhaustive. A system that stuffs all memories into every prompt is worse than no memory system at all — it pollutes the context with irrelevant information and wastes tokens. The art of LTM is knowing what not to inject.
The hard challenges in building memory systems
- Deciding what is worth remembering: Not every message deserves to be stored. If the user says “thanks!” — that’s not a memory. But if they say “I’m allergic to seafood” in the middle of a recipe conversation — that’s critical. Building reliable filters that distinguish noise from signal, across thousands of different conversation types, is a fundamentally hard classification problem.
- Retrieving the right memory at the right time: Storing memories is the easy part. Knowing when to surface them is the hard part. If the user mentions “my Python project,” should you retrieve a note from six months ago about their preferred code style? Maybe. But you shouldn’t retrieve every Python-related memory ever stored. Retrieval systems must balance recency, semantic relevance, and contextual appropriateness — simultaneously.
- Orchestrating the entire system: Memory is not one step — it’s a pipeline. Extraction, embedding, storage, retrieval, deduplication, ranking, injection — all of these need to work together, reliably, in real time, without blowing up latency or context budgets. Coordinating these steps across different datastores and model calls is a serious systems engineering challenge.
Libraries and tools solving this today
The good news: you don’t have to build a memory system from scratch. A growing ecosystem of libraries and services has emerged specifically to solve the LTM problem for LLM-powered applications.
LangMem
A memory management library from the LangChain ecosystem. Provides primitives for storing, organizing, and retrieving long-term memories in LangGraph and LangChain applications. Handles episodic, semantic, and procedural memory natively.
mem0
A production-ready memory layer for AI assistants and agents. Offers a simple API to add, search, and manage memories — with built-in vector storage, automatic memory extraction, and support for user-level, session-level, and agent-level scopes.
Supermemory
A developer-focused memory infrastructure tool built for building AI apps with persistent, searchable long-term memory. Designed to be model-agnostic and easily pluggable into existing LLM pipelines.
Building memory into the model itself
All the solutions we’ve discussed so far are external to the model — they work around the statelessness problem rather than solving it at the architecture level. But researchers are pushing further: what if the model itself could maintain long-term memory natively?
Google researchers explored exactly this in a paper called Titans: Learning to Memorize at Test Time. The core idea: instead of forcing everything through a fixed context window, give the model a learnable memory module that can be updated at inference time — not just at training time. This neural long-term memory learns which information is surprising, important, and worth retaining — mimicking how human memory works by prioritizing novel or emotionally salient information.
Why this matters : Models like Titans represent a paradigm shift from “LLM + external memory system” to “LLM with built-in memory.” If successful at scale, they could eliminate the orchestration complexity of today’s retrieval-augmented memory systems and enable genuinely persistent AI cognition — not engineered around statelessness, but designed beyond it.
Memory is the missing layer
LLMs are extraordinary pattern-matching engines — but by design, they are amnesiac. Every session is a blank slate. Every thread is an island. The work of making AI feel persistent, personalized, and genuinely intelligent over time is not happening inside the model. It’s happening in the systems we build around it — the memory pipelines, the vector stores, the retrieval logic, and now, the new architectures that challenge statelessness at its root. Memory isn’t just a nice-to-have feature. It’s the layer that turns a language model into something that actually knows you.
If LLMs Have No Memory, How Do They Remember Anything? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.