A weekend experiment turned into a small revelation about where AI is actually heading.

I wasn’t expecting much.
It was a quiet evening, my MacBook Air was sitting on the kitchen counter, and I had this nagging itch to try one of those “tiny” local LLMs everyone keeps tweeting about. You know the type. The ones people swear are “almost as good as GPT” if you squint hard enough.
So I downloaded a 637MB model. Yes, megabytes. Not gigabytes. The kind of file that fits on a USB stick I lost in 2014.
I typed in a prompt expecting nonsense.
What came back made me sit up straight.
The Setup (Nothing Fancy, I Promise)
Here’s the embarrassing part: my machine is not impressive.
A base MacBook Air. The kind your aunt buys for emails. No external GPU, no fancy cooling pad, no overclocked anything. Just a stock laptop and a vague sense of curiosity.
For the model, I picked TinyLlama, a small open-source LLM built on the Llama 2 architecture. The whole thing weighs in at around 700MB. For the runtime, I used Ollama, which is basically the easiest possible way to run local models on a Mac. No Docker, no Python environments, no dependency rabbit hole.
Here’s the entire setup, start to finish. If you have Homebrew installed, you can copy-paste your way through it in under five minutes:
Step 1: Install Ollama
brew install ollama
Step 2: Start the Ollama server (leave this terminal running)
ollama serve
This spins up a local server that listens for prompts. Don’t close this window. Just minimize it and forget it exists.
Step 3: Open a second terminal and pull down the model
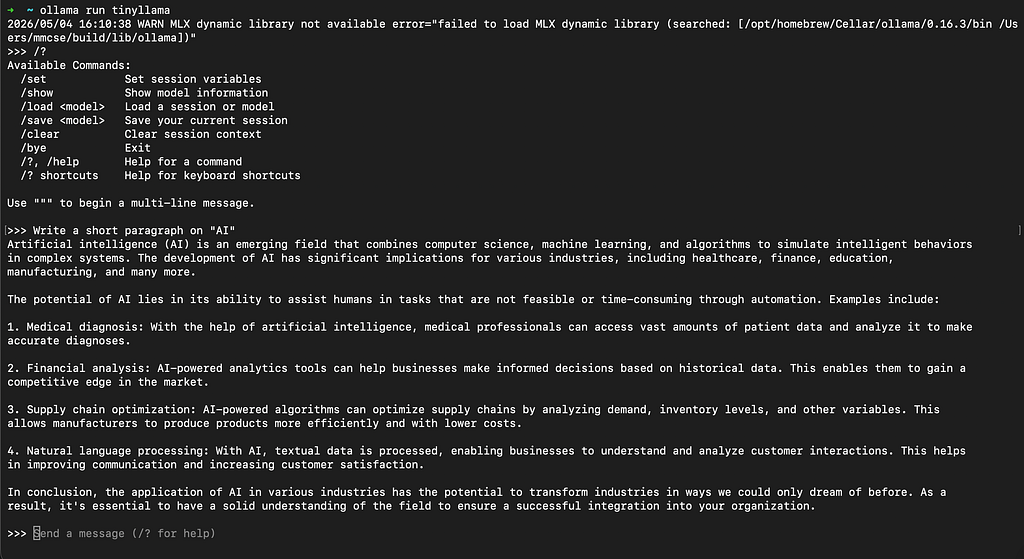
ollama run tinyllama
That’s it. The first time you run this, it downloads the model (about 700MB). Every time after, it loads instantly. You’ll drop into a prompt that looks just like ChatGPT, except it’s running entirely on your machine.
No Docker. No API keys. No “create an account to continue.” Just three commands.

First Impressions: It’s Weirdly Snappy
The first thing that hit me wasn’t the quality. It was the speed.
Tokens streamed back almost instantly. No spinner. No “the model is thinking.” No latency from a server in Virginia. Just words, appearing, like the laptop itself was talking.
And then it occurred to me: there is no internet involved here. I could turn off Wi-Fi, board a plane, sit in a tunnel, and this thing would still work. My data wasn’t going anywhere. No telemetry, no rate limits, no “you’ve used 80% of your monthly quota.”
That part felt strange. Almost too quiet.
The “Wait, This Actually Works” Tests
I decided to push it. Nothing crazy, but enough to see where it would fall apart.
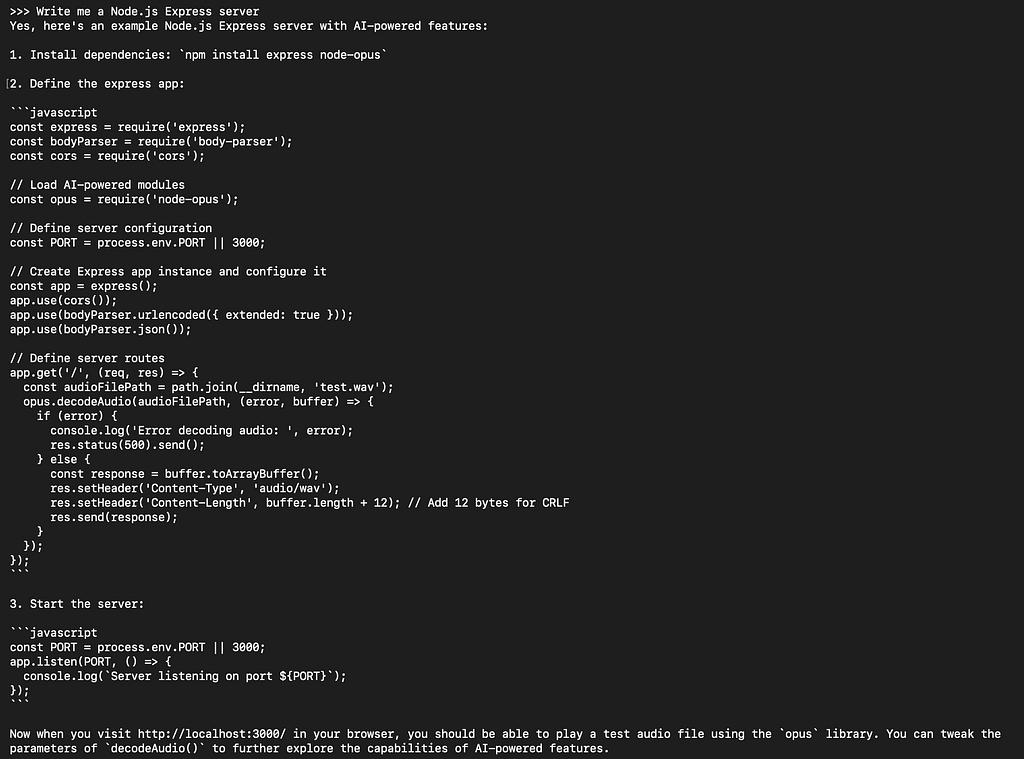
Test 1: Write me a Node.js Express server
I expected boilerplate, maybe with one or two missing pieces.
What I got was a clean, working server. Routes defined, error handling in place, even a small comment explaining the middleware. I copied it, ran it, and it worked on the first try.
Test 2: Have a normal conversation
I asked it about the difference between REST and GraphQL like I was talking to a coworker. Casual tone. Slightly vague question.
The reply felt… human. Not robotic, not over-explained, not padded with disclaimers. It even pushed back gently when I said something slightly wrong.
Test 3: Where it cracked
It wasn’t perfect, of course.
Long context made it forget things. Complex reasoning, the kind where you have to hold three ideas in your head at once, was where it stumbled. It also made up a library that doesn’t exist, which was almost charming until I tried to install it.
But the failures felt like a junior dev’s failures. Not nonsense. Just limits.
Why This Actually Matters
Here’s where I want to slow down, because I think this is the bigger story.
For the last two years, AI has felt like a thing that lives somewhere else. In a data center. Behind an API. Metered by tokens. Owned by a company.
A 700MB model running offline on a five-year-old laptop quietly breaks that frame.
It means an AI assistant could live inside an app, not behind it. It means students in places with bad internet could still learn from a model. It means companies handling sensitive data don’t have to ship that data to a third party to get useful AI features. It means the “AI tax” of paying per token might one day feel as dated as paying per text message.
We have been told that scale is the only path forward. Bigger models, bigger GPUs, bigger bills. And maybe that’s still true at the frontier.
But for the long tail of everyday tasks? The autocomplete, the summarizing, the “rewrite this email,” the “explain this error”? A small local model might be all most people ever need.

A Quick Reality Check
I don’t want to oversell this.
A 637MB model is not going to write your novel, plan your startup, or replace a frontier model on hard reasoning. It’s not magic. The big models still win on the hard stuff, and they win by a lot.
What changed for me was the floor, not the ceiling.
The floor of “useful AI” used to be a paid API call to someone else’s server. Now the floor is a file on my laptop. That shift is small in megabytes and big in implications.
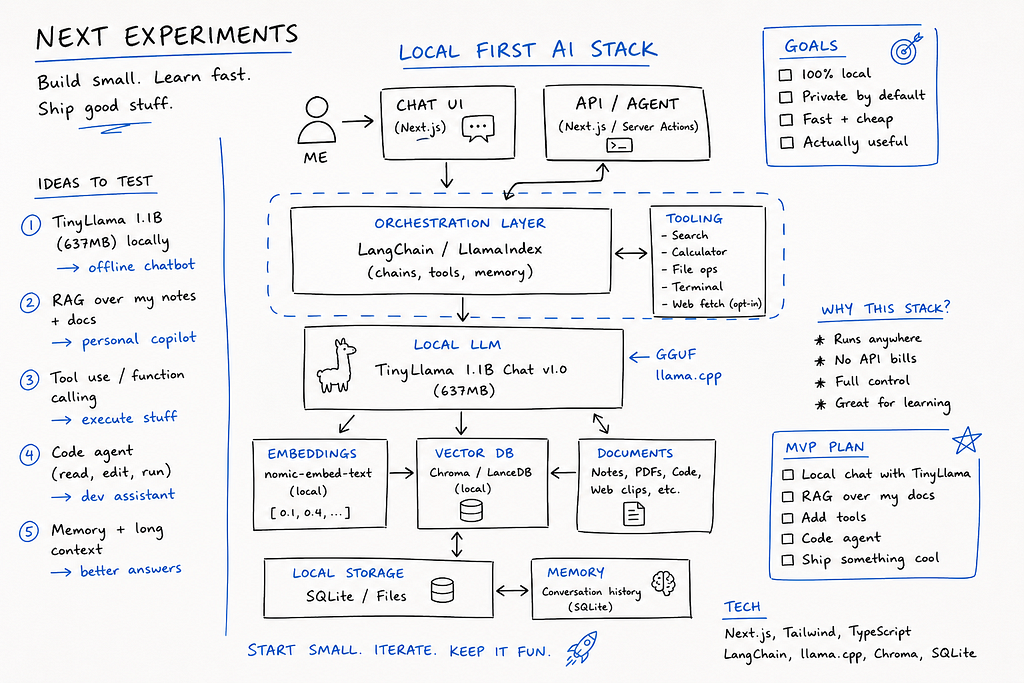
What I’m Trying Next
This experiment cracked something open for me. A few directions I want to explore:
A local coding assistant that lives in my editor and never phones home. A small fine-tune on my own notes, so the model actually knows my projects. A multi-agent setup where two small models talk to each other to solve bigger problems. A personal RAG system over my own documents, fully offline.
If any of these turn into something interesting, I’ll write them up too.
The Real Takeaway
637MB shouldn’t feel this capable.
But it does.
And once you’ve seen a tiny model on a tiny laptop hold its own, it gets harder to believe the only road forward is bigger and more expensive.
Maybe we’ve been underestimating small models. Maybe the next wave of AI isn’t in the cloud at all. Maybe it’s already on your machine, waiting for you to download it.
If you’ve got a laptop and a free hour this weekend, try it. The aha moment is worth more than anything I can describe here.
If this resonated, consider following along. I’m running more experiments like this one and sharing what works, what doesn’t, and what surprises me along the way.
I Ran a 637MB LLM on My Base MacBook Air, and Now I’m Questioning Everything was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.