When a customer types “something professional I can wear to a client meeting in summer” into a search bar, most e-commerce engines return zero results. Not because the products don’t exist — they do. It’s because the engine is looking for those exact words in product titles, and none of them say “something professional.”
That gap between what users mean and what keyword systems can understand is not a minor inconvenience. It’s a fundamental architectural failure that costs real revenue every single day.
So I rebuilt the search layer from scratch using modern AI locally, on a consumer machine with 20GB of RAM, no GPU, no AWS bill.
This is the full technical story.
The Problem With Keyword Search
Standard e-commerce search relies on SQL LIKE operators, full-text search with inverted indexes, or at best BM25-ranked retrieval. These approaches share one hard limit: they only match when query tokens appear in the document tokens.
Here’s what that looks like in practice:
User QueryWhat They WantWhat Keyword Search ReturnsComfortable footwear for rainy daysWaterproof boots, rubber sandals0 resultsSomething to wear to a meetingFormal shirt, dress trousers0 resultsGift for mom who loves gardeningGardening gloves, pruning kit0 resultsBudget laptop bagSlim laptop sleeve0 results
Industry data consistently shows around 15% of all search queries return zero results on major platforms and users who hit zero-result searches are significantly less likely to convert or return.
The fix isn’t smarter synonyms or better autocomplete. It requires rethinking the search layer at the architectural level.
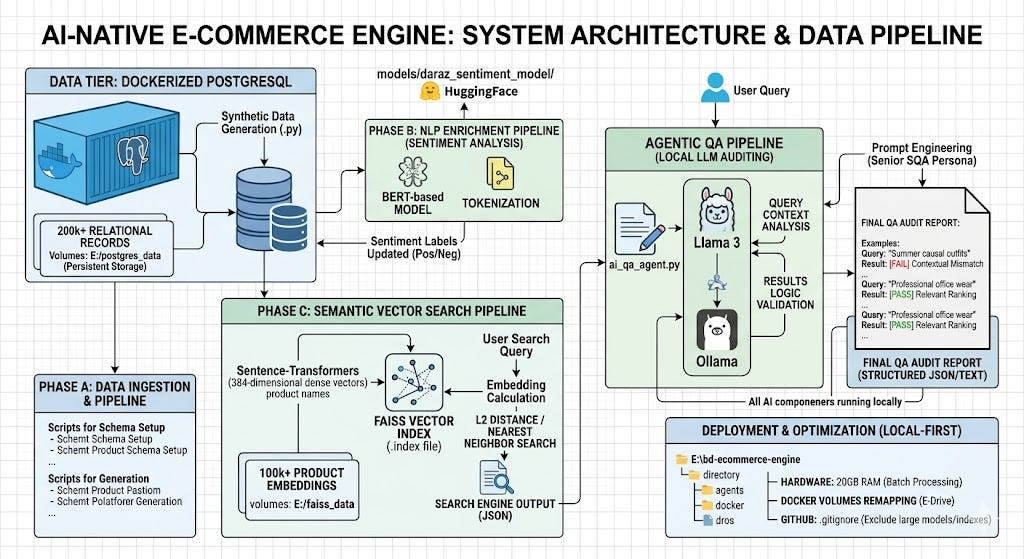
What I Built: A Four-Tier AI Stack
The AI-Native E-Commerce Engine integrates three distinct AI disciplines into a single, locally-operated pipeline:
- Phase A — Data Engineering: 200,000+ synthetic relational records in Dockerized PostgreSQL
- Phase B — NLP Sentiment Analysis: BERT-based sentiment classification of Bengali/English customer reviews
- Phase C — Semantic Vector Search: FAISS-powered similarity search using 384-dimensional sentence embeddings
- Agentic QA Framework: Llama 3 (8B) autonomously auditing every search result set, issuing structured PASS/FAIL verdicts with no human in the loop
The entire system runs on a single workstation: 20GB RAM, local E-drive storage, CPU-only inference throughout.
Phase A: Data Engineering at Scale
Real e-commerce datasets of sufficient scale are rarely available to independent researchers. Commercial datasets are proprietary; public datasets are often too small or too clean for a realistic AI pipeline.
I generated a synthetic dataset of 200,000+ relational records spanning five entity types: Users, Products, Categories, Orders, and Reviews, using probabilistic modeling to mirror the statistical distributions observed on real South Asian platforms like Daraz.
The PostgreSQL schema was designed with both normalization and AI worker query patterns in mind:
sql
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
category_id INTEGER REFERENCES categories(id),
price NUMERIC(10,2),
sentiment_score FLOAT, -- Populated by Phase B
embedding_id INTEGER -- Maps to FAISS index row
);
CREATE TABLE reviews (
id SERIAL PRIMARY KEY,
product_id INTEGER REFERENCES products(id),
text TEXT NOT NULL,
sentiment INTEGER -- 0=Negative, 1=Positive (populated by BERT)
)
The Dockerization challenge: By default, Docker stores volume data on the C-drive. On my development machine, the C-drive was the system drive with limited capacity. The solution was Docker volume remapping — configuring the PostgreSQL data directory to persist to the E-drive:
yaml
services:
postgres:
image: postgres:15
volumes:
- E:/postgres_data:/var/lib/postgresql/data
deploy:
resources:
limits:
memory: 4G # Cap to leave headroom for AI models
This constraint-driven architecture, carefully accounting for every GB , became a recurring theme throughout the project.
Phase B: NLP Sentiment Analysis With Bengali Text
This is where it gets linguistically interesting.
Customer reviews on South Asian e-commerce platforms don’t follow clean English text patterns. They include:
- Pure Bengali in Bangla script: “পণ্যটি খুব ভালো”
- Banglish (transliterated Bengali): “product ta onek valo chilo”
- Code-switched Bengali-English: “delivery fast chilo but quality average”
- Emoji-laden informal text that shifts sentiment polarity
Standard English sentiment models fail catastrophically on this input. A model that hasn’t seen Bangla or Banglish tokens produces random or systematically biased outputs.
The solution was a BERT-based model fine-tuned specifically on Daraz product reviews. BERT’s bidirectional attention is critical here — for a review like “delivery fast chilo but quality ekdom kharap”, the model correctly infers negative overall sentiment by attending to the relationship between “but” and “kharap” (bad) across the full sequence. A unidirectional model would miss this.
python
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
MODEL_PATH = 'models/daraz_sentiment_model'
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_PATH)
sentiment_pipeline = pipeline(
'sentiment-analysis',
model=model,
tokenizer=tokenizer,
device=-1, # CPU inference — no GPU required
batch_size=32 # Balance throughput vs. memory
)
Performance achieved: 18.07 iterations per second on CPU-only inference with batch_size=32. The BERT model footprint: ~420MB RAM. The full 200,000-review dataset could be processed in an overnight batch run of approximately 3 hours.
After inference, sentiment labels propagate to product-level scores:
sql
UPDATE products p
SET sentiment_score = (
SELECT AVG(r.sentiment::FLOAT)
FROM reviews r
WHERE r.product_id = p.id
AND r.sentiment IS NOT NULL
);
This score becomes a re-ranking signal in search — semantically relevant products with consistently negative reviews get deprioritized automatically.
Phase C: Semantic Vector Search With FAISS
Here’s the core insight of semantic search: semantically related concepts occupy proximate regions in high-dimensional space.
The all-MiniLM-L6-v2 model from Sentence Transformers encodes each product name through a 6-layer transformer, then applies mean-pooling to produce a single 384-dimensional dense vector as a semantic fingerprint. Geometric proximity in this space corresponds to semantic relatedness.
“Waterproof boots” and “comfortable footwear for rainy days” end up close together in this space, even though they share no keywords.
Building the index (offline, runs once):
python
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
MODEL_NAME = 'all-MiniLM-L6-v2'
INDEX_PATH = 'E:/faiss_data/products.index'
model = SentenceTransformer(MODEL_NAME)
# Batch encode 100,000+ product names
all_embeddings = []
for i in range(0, len(products), 512):
batch_names = [p[1] for p in products[i:i+512]]
embeddings = model.encode(batch_names, convert_to_numpy=True,
normalize_embeddings=True)
all_embeddings.append(embeddings)
# Build FAISS flat L2 index
all_embeddings = np.vstack(all_embeddings).astype('float32')
index = faiss.IndexFlatL2(384)
index.add(all_embeddings)
faiss.write_index(index, INDEX_PATH)
Query-time search (real-time, per request):
python
def semantic_search(query: str, top_k: int = 5) -> list[dict]:
index = faiss.read_index(INDEX_PATH)
query_vector = model.encode([query], convert_to_numpy=True,
normalize_embeddings=True).astype('float32')
distances, indices = index.search(query_vector, top_k)
return [
{
'name': get_product_by_embedding_id(idx)['name'],
'similarity_distance': float(dist),
'sentiment_score': get_product_by_embedding_id(idx)['sentiment_score']
}
for dist, idx in zip(distances[0], indices[0])
]
FAISS index specs:
PropertyValueIndex typeIndexFlatL2 (exact exhaustive search)Dimensionality384Vectors stored100,000+Index file size~150MB on diskSearch latency<5ms per query (CPU)RAM when loaded~150MB
The choice of exact search (IndexFlatL2) over approximate variants was deliberate at this stage, it provides a correct performance baseline. Approximation via HNSW or IVF is an MLOps tuning step, not a baseline.
The Agentic QA Framework: AI Auditing AI
This is the part I find most architecturally interesting.
Testing an AI search engine creates a challenge that traditional QA cannot address. In deterministic software, a test case has a definitive expected output. In semantic search, no single “correct” result exists — only a spectrum of relevance. Scaling human review to thousands of queries per day is infeasible.
The solution: deploy a second AI to audit the first.
Llama 3 8B, running locally via Ollama, is prompted to act as a Senior QA Engineer evaluating search result relevance. It applies the same common-sense reasoning a human would — but automatically, at scale, with structured JSON output.
python
SYSTEM_PROMPT = '''
You are a Senior Software Quality Assurance Engineer specializing in
e-commerce search relevance evaluation.
Evaluation Criteria:
- PASS: All or majority of results are logically relevant to the query intent
- FAIL: One or more results are clearly mismatched with the query intent
Respond ONLY with valid JSON in this exact format:
{
"verdict": "PASS" or "FAIL",
"confidence": 0.0-1.0,
"reasoning": "brief explanation",
"mismatched_items": ["item names that failed, if any"]
}
'''
def audit_search_result(query: str, results: list[dict]) -> dict:
result_list = '\n'.join([
f'{i+1}. {r["name"]} (Category: {r["category"]})'
for i, r in enumerate(results)
])
user_prompt = f'User Query: "{query}"\n\nSearch Results:\n{result_list}'
response = call_ollama(SYSTEM_PROMPT + '\n\n' + user_prompt)
try:
return json.loads(response)
except json.JSONDecodeError:
# Three-tier fallback for malformed JSON
verdict = 'PASS' if 'PASS' in response else 'FAIL'
return {'verdict': verdict, 'raw_response': response}
Deploying Llama 3 locally required one storage workaround: the default Ollama model directory on Windows points to the C-drive. With 4.7GB model weights, that’s a problem. Fix: redirect via environment variable before launching.
powershell
[System.Environment]::SetEnvironmentVariable(
'OLLAMA_MODELS', 'E:\ollama_models', 'User'
)
Audit Results: What the AI Caught
I ran the QA agent over a 12-query test set spanning formal/casual wear, seasonal clothing, accessories, and multi-attribute queries. Here are three representative cases:
Case A: “Professional office wear”
- Results: Smart Watch, Formal Trousers, Formal Shirt
- Verdict: PASS (0.94 confidence)
- Agent reasoning: All items associate logically with professional office context. Crucially — none of the product names contain the words “professional” or “office.” The match was achieved purely through semantic proximity in the 384-dimensional space.
Case B: “Summer casual outfits”
- Results: Casual Shirt, Formal Trousers, Formal Shirt
- Verdict: FAIL (0.91 confidence)
- Agent reasoning: The Casual Shirt passes. Formal Trousers and Formal Shirt fail the formality criterion. The embedding model conflated “outfit” (broad clothing category) with formal options insufficient metadata differentiation between casual and formal product clusters.
Case C: “Comfortable footwear for rainy days”
- Results: Rain Boots, Waterproof Sandals, Rubber Slippers
- Verdict: PASS (0.88 confidence)
- Agent reasoning: All results are contextually appropriate. “Rainy days” resolved correctly to waterproof/rubber material signals without any keyword overlap.
Overall: 9 PASS, 3 FAIL (75% pass rate) across 12 queries. The three failures share a consistent root cause: the embedding model was trained on product names alone, without category or attribute signals. “Formal Trousers” and “Casual Trousers” may sit close in embedding space because “Trousers” dominates the semantic signal. The fix — multi-field embeddings combining name + category + attributes — is the clear next step.
The Memory Budget: Running Everything on 20GB
The most underappreciated engineering challenge in this project was memory. The full stack, running simultaneously:
- ComponentRAM UsageManagement StrategyPostgreSQL
- (Docker)~2.0GBCapped via docker-composeBERT Sentiment
- Model~420MBLoaded once, kept during batchSentence
- Transformer~80MBLightweight, minimal impactFAISS Index (100k vectors)~150MBLazy-loaded on first queryLlama 3 8B
- (Ollama)~6.0GBLargest component; CPU-onlyPython workers~500MB Garbage collected between stagesOS overhead~3.0GB Windows baseline Available headroom~7.85GB Buffer for spikes
The critical discipline: BERT and Llama 3 are never co-loaded in the same process. Batch processing for embeddings prevents memory spikes from large tensor allocations. Lazy loading defers all heavy object initialization until first use:
python
_sentiment_model = None
def get_sentiment_model():
global _sentiment_model
if _sentiment_model is None:
_sentiment_model = pipeline('sentiment-analysis',
model=MODEL_PATH, device=-1)
return _sentiment_model
The Bigger Picture: What This Architecture Proves
A few things worth noting beyond the technical implementation:
1. Cloud is not a prerequisite for production AI. Every component in this stack, BERT inference, FAISS vector search, PostgreSQL at 200k+ records, an 8B-parameter LLM runs on hardware anyone can buy. The assumption that serious AI requires AWS is increasingly wrong.
2. The QA bottleneck in AI systems is real and underaddressed. As AI becomes embedded in commercial software, manually testing AI outputs at scale is not viable. The pattern demonstrated here, an AI auditing another AI with structured verdicts, is an early prototype of the evaluation infrastructure that production AI systems will increasingly require.
3. Failures are as valuable as successes. The FAIL verdicts from the QA agent are the most actionable output of the entire pipeline. They directly identify that category-level metadata is missing from the embedding input a concrete improvement roadmap is generated automatically.
What’s Next: The MLOps Roadmap
The architecture was designed with cloud scalability in mind. The migration path is straightforward:
- PostgreSQL on Docker → AWS RDS or Google Cloud SQL
- FAISS on E-drive → Pinecone or AWS OpenSearch with k-NN
- BERT inference → SageMaker endpoint or HuggingFace Inference API
- Ollama + Llama 3 → AWS Bedrock or self-hosted EC2 GPU instance
The agentic QA agent is also uniquely positioned as a CI/CD quality gate: every catalog update or model retrain triggers an automated audit, and deployment is blocked if the pass rate drops below threshold. That’s not future thinking, that’s a GitHub Actions workflow away.
The Core Takeaway
The AI-Native E-Commerce Engine is proof that with the right engineering discipline, careful memory management, lazy loading, batch processing, and thoughtful component sequencing, a complete, production-quality AI stack is achievable on consumer hardware.
But more than the technical achievement, it demonstrates something about how we should build AI systems: with autonomous evaluation loops baked in from the start, not bolted on after deployment. An AI that can’t audit itself can’t be trusted at scale.
The system thinks in concepts. The evaluation thinks in concepts. That’s the direction all of this is heading.
I Built a Production-Grade AI Search Engine on a 20GB Laptop (No Cloud Required) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.