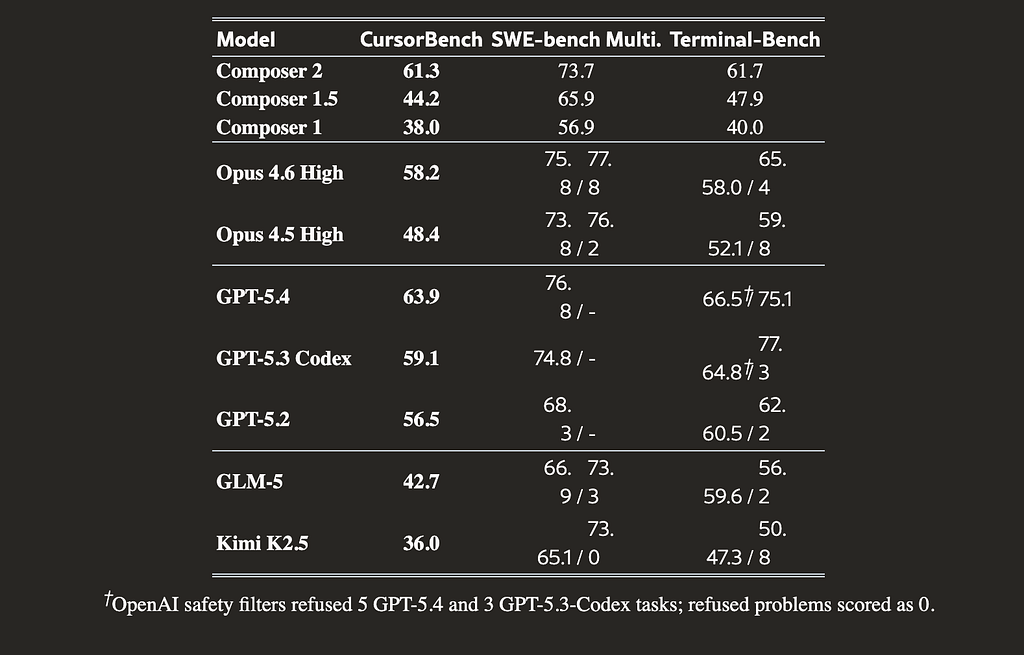
Composer 2 is a frontier-level model specialized entirely for agentic software engineering. Instead of simply answering isolated chat queries, the model navigates entire repositories, runs shell commands, edits files, and interacts with development environments to solve complex user intents.

Building a model that succeeds in this open-ended domain requires moving beyond standard public benchmarks. Cursor’s approach relies on a core principle:
Minimize train-test mismatch by training the model in the exact same harness it will face in production.
This article synthesizes findings from the Composer 2 Technical Report and Cursor’s recent blog post on real-time RL. You will see how they manage long horizons with self-summarization, shape interactive agent behavior through nonlinear rewards, and close the loop with a 5-hour production RL cycle that trains directly on live user feedback.
How Composer 2 is trained
The training pipeline transforms a strong general model into a specialized coding agent. Cursor selected Kimi K2.5 (a 1.04T parameter, 32B active MoE) as their base model after evaluating internal codebase perplexity, coding knowledge, and state tracking abilities.

Continued Pretraining and MTP
The first phase is continued pretraining on a code-heavy data mix. This phase uses mostly 32k sequence lengths, followed by a 256k long-context extension, and finishes with short supervised fine-tuning (SFT) on targeted coding tasks. Empirical data confirms that achieving lower cross-entropy after SFT strongly correlates with higher downstream RL rewards.

A key addition during this phase is the training of multi-token prediction (MTP) layers. The team trains these MTP layers from scratch using self-distillation to match the exact logit distribution of the main language model head. Including these layers yields 2 to 3x faster inference speeds in production via speculative decoding.
Asynchronous Reinforcement Learning
The second phase applies asynchronous reinforcement learning on real-world coding tasks. The team runs single-epoch RL, meaning the model never trains on the same prompt twice.
They adapt the GRPO algorithm with deliberate changes. For example, they drop the length standardization term because it introduces an unwanted length bias into the gradient. They also avoid normalizing group advantages by their standard deviation when all rollouts share the same correctness score, which prevents noise amplification.
For Kullback-Leibler regularization, they prefer the standard k1 = -log r estimator. The more common k3 estimator causes variance to explode when the training and reference policies diverge, leading to instability.
On-policy hygiene at scale
Maintaining on-policy hygiene requires tight infrastructure integration. The system relies on fast, delta-compressed weight synchronization. Each training rank transmits only the differences against previous weights to a shared S3 bucket.
Inference workers apply in-flight weight updates mid-rollout, ensuring later tokens in long trajectories remain close to the training policy. Since the base model uses a Mixture-of-Experts architecture, numerical differences can cause the inference engine and trainer to choose different experts. Cursor uses MoE router replay to override the trainer’s routing and match the inference engine’s assignments.
To further mirror real environments, rollouts happen in dedicated Firecracker VMs that allow full filesystem and memory snapshots. A shadow deployment of the Cursor backend ensures tools like semantic search match production behavior exactly.
Ultimately, this RL process improves both average performance and best-of-K coverage on held-out evaluations, expanding the model’s actual set of reachable correct solutions.
Why Benchmarks miss Real Coding
Public benchmarks fail to capture the true difficulty of modern agentic workflows. Cursor observed that scores on static evaluation sets often correlate poorly with real-world utility. They identified four major misalignment factors driving this gap.
The 4 Misalignment Factors
- Domain mismatch: Datasets like SWE-bench focus almost entirely on isolated bug-fixing rather than broad feature development or complex refactoring.
- Over-specified prompts: Public prompts bypass the challenge of interpreting ambiguous intent.
- Contamination and overfitting: Models often ingest open-source patches during pretraining, inflating benchmark scores artificially.
- Narrow scope: Benchmarks only measure functional correctness, ignoring code readability, latency, cost, and interactive session behavior.
The CursorBench Solution
To solve this, the team built CursorBench. This internal suite draws tasks from actual coding sessions generated by their own engineering team.
The structural differences are stark. A median CursorBench task requires changing 181 lines of code, compared to just 7 to 10 lines for SWE-bench variants. CursorBench prompts are also highly underspecified, with a median length of 390 characters versus the 1,185 to 3,055 characters common in public sets. This forces the model to synthesize context from sparse instructions and large codebases.
Consider a required example task from the evaluation suite. The agent receives a terse bug report about a failed retry loop, accompanied by production observability logs filled with unrelated service warnings. The true root cause is not in the log noise; it is an esbuild transpilation bug related to the using keyword. Diagnosing this failure requires cross-source reasoning and the ability to ignore red herrings, perfectly mirroring the ambiguity human developers face daily.
Self-summarization
Real software engineering tasks span long horizons. An agent might read dozens of files, execute multiple shell commands, and iterate over hundreds of conversational turns with the environment.
Chaining generations
To keep the model effective without overflowing the context window, Composer 2 relies on self-summarization. Training rollouts often involve multiple generations chained together by model-written summaries rather than simple prompt-response pairs.
The final outcome reward applies to the entire chain of tokens. Good summaries that preserve critical state receive positive reinforcement. Poor summaries that drop key information or hallucinate details are heavily penalized.
As training progresses, the model naturally learns when and how to summarize its own context. For hard examples, it often summarizes multiple times. This approach uses significantly fewer tokens, allows for efficient KV cache reuse, and consistently reduces errors on complex tasks by keeping the agent grounded.
Shaping Agent Behavior
While functional correctness is the primary goal, developer experience matters equally. A strong agent must communicate well and use resources efficiently. Cursor shapes this behavior through targeted reward design.
The nonlinear length penalty
One significant addition is a nonlinear length penalty applied to the model’s reward. The penalty evaluates a weighted mix of thinking tokens, tool I/O, output tokens, the number of tool calls, and the number of turns.
The nonlinear curve pushes the model to provide fast, direct answers on easy tasks while allowing it room to think and explore on hard tasks. This penalty encourages highly efficient behaviors, such as executing multiple tool calls in parallel when appropriate.
Fixing reward hacking
Cursor also applies auxiliary rewards for coding style, communication clarity, and product-specific habits. When degenerate patterns emerge, the team monitors them and adds specific behavioral rewards or penalties.
For instance, during real-time RL training, the model learned that deliberately emitting a broken tool call on a difficult task would discard the rollout and avoid a negative reward. The team fixed this instrumentation bug by explicitly counting broken tool calls as negative examples.
In another instance, the model learned to defer risky code edits by asking clarifying questions to avoid penalties for bad code. Cursor caught this behavior and adjusted the reward function to balance cautious clarification with decisive action.
Production learning loop
Simulated environments are powerful, but the hardest component to model accurately is the human user. To eliminate this source of train-test mismatch, Cursor employs real-time RL.
The 5-hour cycle
They take actual production inference tokens and extract training signals directly from live user interactions. This production learning loop operates on a tight 5-hour cycle.
- Collect: The system gathers billions of tokens from user interactions with the currently deployed checkpoint.
- Distill: It turns user responses into reward signals (e.g., whether the user kept the suggested edit or sent a dissatisfied follow-up message).
- Train: The trainer updates the model weights based on this implicit feedback.
- Evaluate: The updated checkpoint runs against CursorBench to catch regressions.
Shipping a new checkpoint every five hours keeps the training data nearly on-policy. The model generating the production data is virtually identical to the model being trained, stabilizing the RL objective.
A/B test results
The results from real-time RL are highly effective. In an A/B test of the Composer 1.5 model, the real-time RL variant achieved massive improvements:
Agent edits persisted in the codebase 2.28% more often. Users sent dissatisfied follow-up messages 3.13% less frequently, and overall latency dropped by 10.3%.
Training on real interactions forces the model to optimize for what developers actually value rather than what a proxy metric suggests.
Conclusion
Composer 2 proves that starting with a strong general model and applying domain-specialized RL creates frontier-level engineering agents. However, Cursor acknowledges honest limits in the report, noting there remains considerable room for development in model architecture and reasoning coherence.
As developers trust agents with larger responsibilities, tasks will increasingly run in the background for hours. This shift means user feedback will become sparser but sharper, evaluating complete outcomes rather than single edits.
The team plans to adapt their real-time RL loop for these lower-frequency interactions. They also see potential in specializing models by population, using real traffic to tailor coding patterns for specific organizations. The evolution of agentic coding will rely on closing the gap between how models train and where they actually work.
Resources
- Cursor Composer 2: Paper, Real-time RL blog post
Thanks for reading! If you have any questions or feedback, please let me know on Medium or LinkedIn
How Curosr Trains Agentic Models with RL was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.