The failure case you didn’t see coming
In late 2025, a major social platform quietly rolled back parts of its LLM-based moderation pipeline after internal audits revealed a systematic pattern: posts in African American Vernacular English (AAVE) were flagged at nearly three times the rate of semantically equivalent Standard American English content. The LLM reasoner, a fine-tuned GPT-4-class model had learned to treat certain phonetic spellings and grammatical constructions as proxies for “informal aggression.” A linguist reviewing the flagged corpus found no aggression whatsoever. The failure wasn’t adversarial. It was architectural: the model had no representation of dialect as a legitimate register.
Simultaneously, coordinated hate communities on adjacent platforms were having a productive year. A campaign using an evolving lexicon of food metaphors none appearing in any hate speech corpus moved freely through multiple automated systems for weeks. To any human reader with context, the semantic content was unmistakable. The classifiers scored it as cooking discussion.
These aren’t edge cases. They’re the operating conditions of modern content moderation.

The benchmark - deployment gap
The technical progression looks like a solved problem: keyword blocklists in the early 2010s gave way to SVM and logistic regression classifiers, then to LSTM and CNN architectures, then to the transformer era. BERT and RoBERTa introduced contextual embeddings capable of distinguishing “you’re killing it tonight” from “I want to kill you” a distinction no n-gram model could make. GPT-class models added reasoning about intent. Benchmark F1 scores on standard datasets climbed past 0.85.
The gap opened at deployment. Systems that perform well on HatEval, OffComBR, or OLID datasets with controlled distributions and careful human annotation routinely miss 30–40% of policy-violating content in live traffic while generating false positive rates that, at platform scale, mean millions of incorrectly suppressed posts per week.
The benchmark isn’t wrong. It’s measuring the wrong thing. A high F1 score on a static, annotated test set measures pattern-matching against a snapshot. Real hate speech is adversarial, dialectally heterogeneous, contextually embedded, and temporally evolving. The benchmark–deployment gap is not a model quality problem, it’s a problem definition problem. We’ve been solving the wrong version of the task.
Why the problem is fundamentally hard
Context and intent
Sentence-level classification assumes the relevant signal lives within the sentence. It doesn’t. “Keep your neighborhood clean” is innocuous real estate advice or a white nationalist dog whistle depending on speaker, recipient, conversational history, and posting community. Sarcasm inverts surface polarity entirely: “Oh sure, those people are just SO trustworthy” requires understanding that the stated claim is the inverse of the intended meaning a reasoning step, not a lexical lookup.
Implicit hate is harder still. It carries no surface-level toxicity markers. A post juxtaposing a fabricated crime statistic with a single demographic label inflicts serious harm through presupposition and stereotype activation, not through any word that would trip a classifier. Detecting it requires reading comprehension of the kind only becomes tractable with full conversational context and world knowledge about the speaker’s intent.
Cultural and linguistic complexity
Toxicity is socially constructed which means it is culturally relative and historically contingent. Reclaimed slurs function as in-group solidarity markers when used within a community and as weapons when directed at it from outside. A classifier trained on general annotations will conflate the two, systematically misclassifying in-group usage as hate speech and penalizing the community the system is meant to protect.
Code-mixing introduces a structural challenge: Hinglish sentences fragment across two morphological systems that most monolingual tokenizers handle poorly, if at all. AAVE’s well-documented syntactic features habitual aspect marking, copula deletion, negative concord-read as errors or aggression markers to models trained on Standard American English corpora. The model doesn’t know it doesn’t know the dialect, which is precisely what makes the failure so consistent.
Dataset and labeling limitations
Annotation subjectivity is a structural property of this task, not an artifact to be smoothed away. Inter-annotator agreement on subtle hate speech frequently falls below κ = 0.6, meaning human experts disagree on the ground truth at rates that would be disqualifying in any other ML domain. When the label itself is contested, what exactly is the model learning to replicate?
Static datasets compound this structurally. A corpus collected in 2021 encodes the hate speech lexicon of 2021. Communities adapt their language faster than annotation cycles can track. Timnit Gebru’s work on datasheets for datasets identified exactly this failure mode: deployed systems routinely inherit undocumented geographic, demographic, and temporal biases that become invisible once the dataset leaves the research pipeline. The bias doesn’t disappear it gets embedded in production weights.
Adversarial dynamics
Moderation systems aren’t static targets. Once filtering logic becomes observable through testing, leaks, or community analysis coordinated actors reverse-engineer its failure modes. The Scunthorpe problem (innocent strings containing banned substrings) was the naive first generation. Current-generation obfuscation involves semantic indirection: homoglyphs, character substitutions, plausible-deniability framing, and increasingly, migration into the visual channel where meme-based hate bypasses text analysis entirely.
Moderating hate speech is like chasing a moving target where the rules themselves keep changing and the target has read your rulebook.
What changed by 2026
Four shifts define the current deployment landscape.
LLM-based moderation pipelines are now standard at large platforms. Rather than a single classifier, the typical architecture chains a fast base model for triage with a GPT-4-class reasoner for ambiguous cases. The LLM can write a rationale for its decision valuable for appeal workflows and regulatory compliance. It also introduces new failure modes: LLMs produce inconsistent judgments across paraphrases of identical content and are sensitive to prompt framing in ways that violate the consistency requirements of any fair moderation system.
Multimodal content has become the dominant moderation surface. Text-only pipelines are increasingly insufficient as hate speech migrates into image macros, short-form video, voice messages, and overlaid text on visual content. Vision-language models have extended the analysis surface, but multimodal hate where harm emerges from the combination of individually benign text and image remains poorly understood at the research level and largely unsolved in production.
Real-time scale has tightened latency constraints to the point where even a fast transformer is expensive for the long tail. Tiered architectures where the LLM sees only the fraction of content the base model marks ambiguous have become the practical solution, but they concentrate errors in exactly the high-ambiguity cases that most need careful handling.
Regulatory pressure from the EU Digital Services Act, the UK Online Safety Act, and emerging legislation across Southeast Asia now imposes transparency, explainability, and appeal requirements that are in structural tension with black-box inference pipelines. Building compliant systems means building systems that can justify their decisions a harder problem than classification alone, and one the research community has not yet solved cleanly.
Current system design
The modern content moderation stack is a layered ensemble. Each layer trades cost for precision, handling the volume its accuracy justifies.

The heuristic layer clears roughly 60% of volume at near-zero inference cost. The base classifier handles the remainder at single-digit millisecond latency. The LLM reasoner which may cost 50–100× more per call than the base classifier sees only the cases where the base model is uncertain. Human review handles the long tail and doubles as a quality signal for the automated layers.
The weakest link is the feedback loop. Most platforms lack tooling to systematically learn from wrongful removals, so false positives dissipate without improving the system. Correct appeals are processed; the signal they carry about model error is not.
Failure modes
Three failure modes account for the majority of production incidents. Understanding them precisely is more useful than abstract accuracy metrics.



Practical demonstration
The following uses HuggingFace’s pipeline API with unitary/toxic-bert to illustrate how off-the-shelf toxicity classifiers behave across four distinct input types. Run it; the gap between prediction and ground truth is the point.
from transformers import pipeline
classifier = pipeline(
"text-classification",
model="unitary/toxic-bert",
top_k=None
)
test_cases = [
{
"text": "[Group X] are subhuman vermin and should be eliminated.",
"type": "Explicit hate",
"ground_truth": "TOXIC"
},
{
"text": "You know how those people are. Always taking what isn't theirs.",
"type": "Implicit hate — coded stereotype",
"ground_truth": "TOXIC (requires speaker/context)"
},
{
"text": "bruh u deadass clownin rn no cap fr fr",
"type": "Benign AAVE / Gen-Z slang",
"ground_truth": "NOT TOXIC"
},
{
"text": "The data clearly shows replacement-level migration patterns.",
"type": "Neutral-framed extremist talking point",
"ground_truth": "TOXIC (context-dependent)"
}
]
for case in test_cases:
result = classifier(case["text"])
top = max(result[0], key=lambda x: x["score"])
print(f"\n[{case['type']}]")
print(f" Text : {case['text'][:62]}...")
print(f" Prediction : {top['label']} (conf{top['score']:.3f})")
print(f" Ground truth: {case['ground_truth']}")
Expected outputs and what they reveal
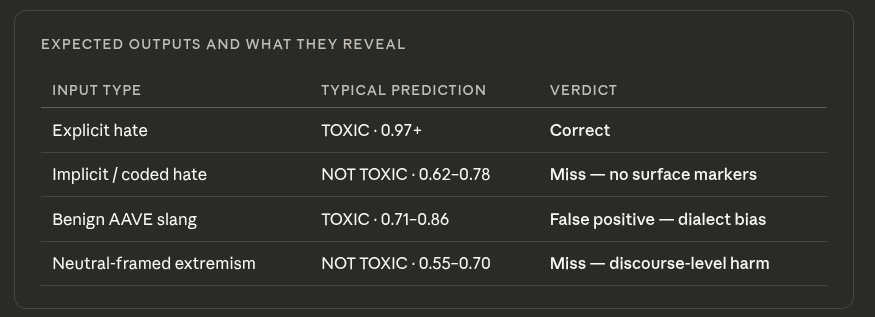
The model handles explicit hate reliably because training signal is concentrated there. The two failure modes missing coded hate and penalizing AAVE are where the real-world harm concentrates. Neither is fixable by adding more of the same kind of training data; both require dialectally balanced corpora and discourse-level supervision signals that most public datasets don’t provide.
Research insights: 2023–2026
The research literature has converged on several findings with direct implications for system design though the gap between published findings and production deployments remains wide.
Context-aware models consistently outperform isolated sentence classifiers on hard cases. Thread-level and conversation-level analysis where the model has access to preceding turns, topic metadata, and community context improves implicit hate detection by 15–25 percentage points in controlled evaluations. The HateXplain dataset, which pairs hate labels with annotated human rationales, has become the standard benchmark for testing whether models learn decision-relevant reasoning or surface proxies. Models that produce explanations aligned with human rationales generalize substantially better across domains and demographic groups.
Fairness evaluation has matured beyond demographic parity. Equalized odds, counterfactual fairness, and group-conditional calibration are now standard metrics in research papers — measuring not just whether the model is accurate, but whether its errors are symmetrically distributed across demographic groups. These metrics are not yet routinely enforced in production deployments, which is where the gap between research norms and platform practice is most visible.
LLMs improve reasoning quality but degrade consistency. A consistent finding across ACL and EMNLP 2024–2025 is that LLMs produce more human-aligned explanations for borderline cases than fine-tuned classifiers, but exhibit substantially higher decision variance: the same content framed slightly differently yields different verdicts 25–30% of the time. For a system applying policy consistently across millions of users, this variance is not a minor quirk — it’s a fairness violation at scale.
Continual learning systems that update on new adversarial patterns without catastrophic forgetting remains an active research frontier with no production-ready solution. Most deployed systems retrain on fixed schedules, structurally lagging adversarial evolution by weeks or months.
Future directions
The most promising directions converge on a shared principle: moving from isolated token-level classification toward contextually grounded, collaborative reasoning systems.
01 — Conversational models
Thread-level analysis treating moderation as discourse reasoning, not sentence scoring.
02 — Multimodal reasoning
Joint analysis of text-image-audio combinations, where harm emerges from content interaction.
03 — Human-AI collaboration
Interfaces surfacing model uncertainty and rationale to reviewers — not binary decisions.
04 — Fairness-first training
Dialect-balanced corpora and group-conditional calibration as primary training objectives.
05 — Continual learning
Adversarial pattern catalogues enabling rapid adaptation without full retraining cycles.
06 — Explainability pipelines
Policy-grounded rationales meeting DSA and OSA audit and transparency requirements.
The ethical layer
Every moderation system encodes a theory of harm and a theory of speech and neither is neutral. The choice of what to suppress is simultaneously a choice about whose speech gets suppressed, and at what rate. A system that over-flags marginalized dialects reproduces, at scale, the same exclusionary logic that hate speech itself employs. The tool becomes the harm.
Cultural relativity is a technical specification requirement, not a philosophical hedge. What constitutes a threatening reference varies across national, historical, and community contexts. US-centric training corpora produce classifiers that systematically miscategorize culturally specific expressions from South Asian, African, and Middle Eastern language communities a pattern documented repeatedly and corrected rarely. Treating “toxic” as a universal category imposes the norms of the annotation team on every community in the deployment zone.
Platform power is the least examined variable in the technical literature. Automated moderation systems make billions of consequential decisions daily with limited transparency, constrained appeal pathways, and no external audit. The same infrastructure that protects users from coordinated harassment can suppress political dissent, labor organizing, or competitive criticism with plausible deniability baked in by design. The research community has largely treated this as out of scope. It isn’t.
Conclusion
The title works in both directions. “Still cooks” means the problem is still live, still demanding, still technically unsolved in its hardest forms — and it still has enough heat to damage both users and systems that underestimate it.
The trajectory from keyword lists to transformer classifiers to LLM reasoning pipelines represents genuine, measurable progress. Systems are more accurate, more interpretable, and more linguistically aware than they were five years ago. But technical progress has consistently outpaced institutional progress. Better models are deployed in worse contexts with less human oversight, more regulatory pressure, higher content volumes, and more sophisticated adversaries than any of these systems were originally designed to handle.
Better models don’t fix broken feedback loops. Better models don’t fix annotation corpora that don’t represent the populations they govern. Better models don’t fix platforms that treat moderation as a cost center rather than an infrastructure problem.
Key insights
1. Hate speech detection is an adversarial reasoning problem embedded in social context not a static classification task. Benchmark performance measures the wrong thing.
2. Systematic false positives on AAVE and code-mixed languages are an equity failure, not an edge case. They are the expected output of models trained on non-representative corpora.
3. LLMs improve per-case reasoning quality but degrade decision consistency at scale a structural tension for systems that must apply policy uniformly.
4. Calibration is as consequential as accuracy. High-confidence wrong predictions on out-of-distribution inputs cause more downstream harm than correctly uncertain ones.
5. The technical problem and the institutional problem are inseparable. No model improvement closes the gap if the feedback infrastructure, annotation pipeline, and governance context remain static.
The benchmark tells you how well your model handles last year’s hate speech.
The adversary is writing next year’s.
Hate Speech Detection Still Cooks (Even in 2026) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.