How the Dynamic OODA loop, release train engineering, and structured learning loops converge in a practical harness for AI agent fleets
The promise of agentic AI in software delivery is seductive: autonomous agents writing code, running tests, deploying to production. The reality, for anyone who has actually tried to orchestrate multiple agents on a non-trivial codebase, is considerably messier. Agents hallucinate. They drift from architectural intent. They make locally rational decisions that are globally incoherent. Without governance, a fleet of AI agents isn’t a team — it’s an ant farm with no colony structure.

This is the problem that led me to build Venutian Antfarm, an open-source framework for structured multi-agent software delivery with progressive autonomy, evidence-based governance, and measurable quality control. But before I walk through what the framework does and how it works, I want to share the thinking that produced it — because the architecture is inseparable from the governance philosophy underneath.
From OODA to DOODA: Sensemaking as the Governance Bottleneck
My thinking on agent governance traces back to research I co-authored at Gartner on digital business moments — published as “Get Out of Strategic Limbo: How to Discover and Exploit the Business Moments That Drive Digital Transformation.” ¹ That work used the Dynamic OODA (DOODA) loop — adapted from Brendt Brehmer’s amalgamation of Boyd’s OODA loop with cybernetic command-and-control theory² — as the core model for connecting business strategy to real-time detection and fulfillment of transient opportunities.

Boyd’s original OODA loop (Observe-Orient-Decide-Act) was a model of competitive decision-making where Orient is the schwerpunkt — the center of gravity.³ Brehmer’s contribution was to make the loop dynamic: rather than discrete cycles, the phases operate continuously and concurrently, with feedback from effects and friction informing the next sensemaking pass even while actions from the previous cycle are still in flight.
In our Gartner research, we mapped business moments along two axes — whether triggers are known or unknown, and whether paths to outcome are known or unknown — producing four dispositions drawn from the Cynefin framework:⁴ standard operating procedures (simple), opportunistic moments (complicated), improvisational moments (complex), and innovative moments (chaotic). Each disposition demands a different sensemaking tactic. Crucially, a moment’s disposition can shift mid-execution — what starts as opportunistic can become innovative when assumptions fail.
An agent fleet’s sensemaking function — its ability to orient on the current state of the codebase, the delivery process, and the business intent — is the critical bottleneck.
Individual agents can act with impressive speed, but without continuous reorientation at the fleet level, those actions drift from coherence. The DOODA loop taught me that governance isn’t a gate you pass through; it’s a persistent orientation function that runs concurrently with execution.
This concept connected directly to my experience implementing SAFe Agile Release Trains. In SAFe, the ART leadership triad — Product Management, Enterprise Architect, and Release Train Engineer — collectively maintains orientation across multiple scrum teams working in parallel on shared codebases.⁵ None of them writes code. Together, they are the sensemaking function — and they serve as a useful, if imperfect, analog for the multi-agent coordination problem we now face with AI.
What does the agile governance look like when the teams are AI agents?
The Triad: Servant Leadership as Governance Architecture
The answer begins with a structural observation. In well-functioning agile delivery, governance isn’t imposed through command-and-control hierarchies — it emerges from the interplay of three distinct perspectives: business value, technical soundness, and process health. In SAFe, these map to the Product Manager, Enterprise Architect, and RTE roles. In Scrum, it’s the Product Owner, the development team’s technical leadership, and the Scrum Master.⁵
Venutian Antfarm formalizes this as the Leadership Triad: a Product Owner agent, a Solution Architect agent, and a Scrum Master agent. These three operate as servant leaders — they don’t dictate what execution agents do, they enrich the context in which execution agents make decisions. The PO validates business value and acceptance criteria. The SA ensures technical coherence, manages non-functional requirements, and identifies cross-system dependencies. The SM owns process health, pace control, and conflict mediation.
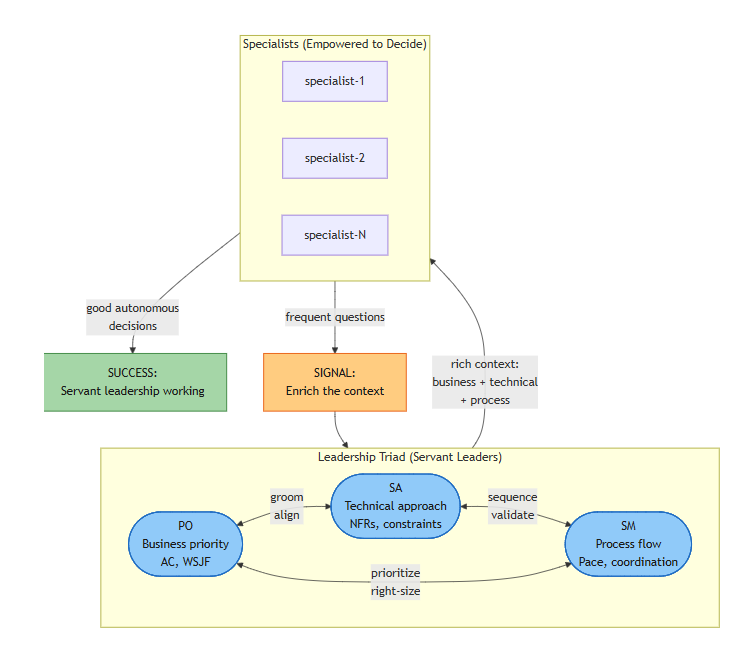
The triad doesn’t command — it enriches. When specialists ask frequent questions, that’s a signal to enrich the context, not tighten control.
The triad operates through consensus protocols. For conservative actions (maintaining or tightening governance), unified recommendation is sufficient. For accelerations (expanding autonomy, increasing pace), triad unanimity is required before seeking operator approval. When the triad disagrees, all perspectives surface for human decision-making. This isn’t bureaucracy — it’s checks and balances. The same structural principle that makes democratic governance resilient makes agent fleet governance resilient.
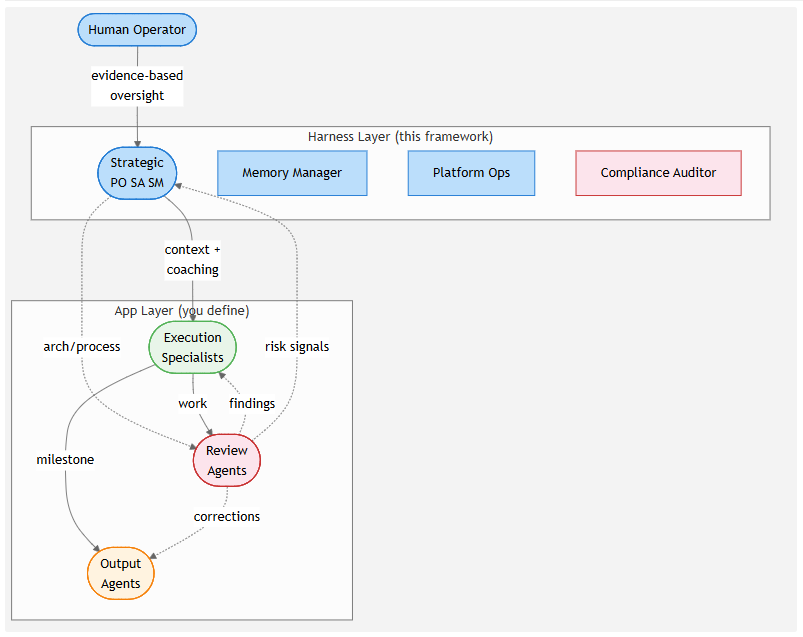
Below the triad sits the full fleet structure — harness agents providing governance, app-layer specialists doing the work, and a human operator providing evidence-based oversight:
Progressive Autonomy: Trust as a Measurable Gradient
Most agent frameworks offer a binary choice: approve every action, or let agents run free. This mirrors a false dichotomy that plagues human organizations too — micromanagement versus abdication. Neither works at scale.
Venutian Antfarm replaces this binary with a four-stage autonomy progression: Crawl–Walk–Run–Fly.

Crawl is the starting state. Agents propose nearly everything and explain their reasoning. The human reviews and approves. This is expensive, slow, and absolutely necessary — it’s how the system and the human build mutual calibration. Think of it as sprint zero for your agent fleet.
Walk introduces standard three-tier autonomy: some actions are autonomous (reading code, running tests), some require proposals (cross-domain changes, new dependencies), and some require escalation (compliance implications, destructive operations). The human engages at milestone reviews rather than every action.
Run expands autonomy further. Agents chain work across items, batch oversight replaces continuous review, and only strategic calls require proposals. This is where throughput starts to approach the theoretical promise of multi-agent delivery.
Fly grants full autonomous operation. Agents execute, commit, and deploy with metrics-driven monitoring rather than action-level approval. But critically, even at Fly pace, the escalation tier never disappears. Compliance floor violations, strategic decisions, and destructive operations always surface to a human.
Transitions are evidence-driven and reversible. You don’t set pace based on vibes.
In our implementation, run pace requires a change failure rate below 5%, first-pass handoff acceptance above 95%, and declining findings frequency — thresholds that teams should calibrate to their own domain and risk tolerance. Pace ratchets back down when problems emerge. When significant problems surface at any pace, the triad consults: if high consensus and pace is current, proceed; if high consensus and pace should increase, a unified recommendation goes to the user; if low consensus, each perspective surfaces independently for the human operator to decide.

This is where the DOODA influence shows most clearly. Crawl corresponds to the chaotic/innovative Cynefin disposition where you must act-sense-respond because nothing is yet proven; Fly corresponds to the simple/standard-operating-procedure disposition where triggers and paths are well understood. Cynefin practitioners will recognize the critical danger here: the cliff between simple and chaotic.⁴ When a system operates in the simple domain too long, it risks complacency — oversimplifying situations, failing to account for exceptions, and suddenly tipping into chaos when an unrecognized edge case breaks assumptions. The escalation architecture is the structural mitigation.
The Findings Loop: Structured Learning With a Fitness Function
Rather than passive memory accumulation — the approach most agent frameworks take, where you dump everything into a growing context — Venutian Antfarm implements a structured continuous improvement loop with a measurable fitness function, borrowing the shape of reinforcement learning without the algorithms.⁶
The cycle works as follows:
- Signal generation. Agents record notable events during work — surprises, boundary tensions, pattern observations, replicable successes, outright failures — as findings with urgency classification (critical through low).
- Curation. The Scrum Master agent reviews findings, identifies patterns, and proposes refinements: prompt updates, memory enrichments, autonomy tier adjustments, or process changes.
- Application. The triad reviews and applies approved refinements across the fleet.
- Measurement. The same finding type should decrease in frequency over time. If it doesn’t, the refinement failed and needs revision.
The structural shape resembles reinforcement learning — findings act as the signal, curation evaluates policy, refinement updates it, measurement closes the loop — but this is deliberate analogy, not implementation. There are no gradient updates or reward models. What makes it effective is the human-in-the-loop component at steps 2 and 3, preventing the objective drift that purely automated learning systems can produce.
The findings loop also provides the evidential foundation for pace transitions. You can’t credibly argue for Run pace if the findings register shows recurring architectural drift or compliance near-misses. The data makes the case, not the aspiration.
The Compliance Floor: Governance That Doesn’t Negotiate
Progressive autonomy creates a risk: what happens when a high-pace fleet encounters a situation that should never be handled autonomously? The answer is the compliance floor — a small set (typically 3–5) of non-negotiable rules that override all autonomy tiers, pace settings, and priority decisions, enforced by a dedicated Compliance Auditor agent during review phases.
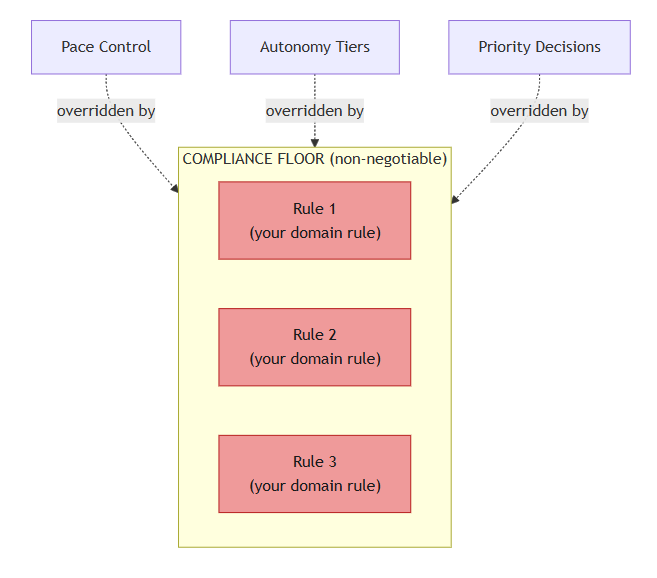
Pace Control, Autonomy Tiers, and Priority Decisions are all overridden by the Compliance Floor. The rules are yours to define; the override behavior is non-negotiable.
In the production system where this pattern originated — a PII-sensitive case management application — the compliance floor included rules like “no PII in the operational database,” “row-level access control on every query,” and “secrets managed through vault, never hardcoded.” An agent at Fly pace still escalates on compliance floor contact. The floor is the governance bedrock that makes progressive autonomy safe.
Measuring What Matters: DORA Meets Flow Quality
You can’t govern what you can’t measure. Venutian Antfarm implements a metrics pipeline built around two complementary frameworks.
DORA metrics capture delivery outcomes: deployment frequency, lead time from promotion to acceptance, change failure rate, and mean time to recovery. These metrics were empirically validated as the strongest predictors of organizational software delivery performance,⁷ and they translate directly to agent fleet measurement.
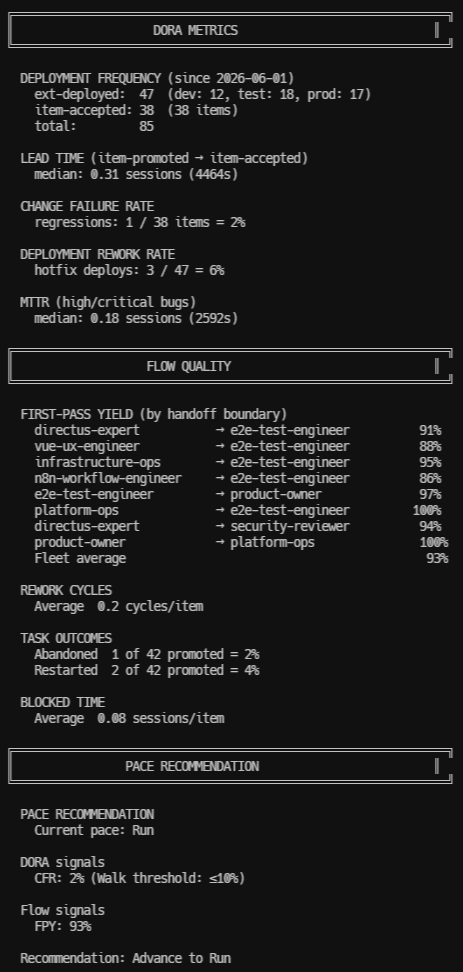
Flow quality metrics capture process health: first-pass yield (percentage of handoffs accepted without rejection), rework cycles, task abandonment rates, blocked time, and restart rates. First-pass yield by agent boundary pair is particularly actionable — it reveals exactly where inter-agent handoff quality breaks down.
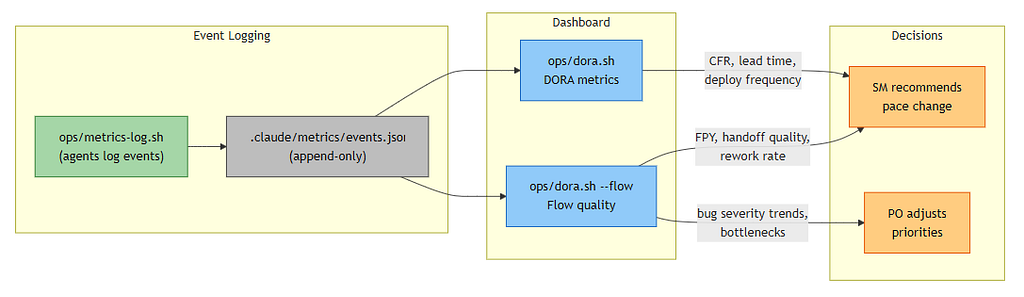
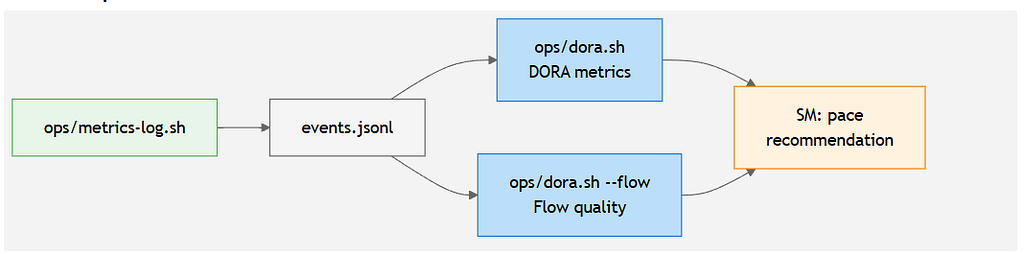
Together, these metrics feed back into both pace control decisions and findings curation, creating the continuous orientation loop that the DOODA model prescribes.
The Architecture: Six Agents You Don’t Write
The framework ships with six governance-layer agents: the Product Owner, Solution Architect, and Scrum Master (the triad), plus a Memory Manager (knowledge consistency and staleness detection), Platform Ops (DORA metrics, CI/CD visibility, deployment health), and Compliance Auditor (domain-specific rule enforcement).
Users extend these with custom specialist agents tailored to their technology stack and domain. The framework uses an inheritance model where app-layer agents override harness agents only in specified fields — unmodified governance properties are preserved. This means you get structured governance without duplicating governance logic into every specialist agent you write.

The framework uses a three-layer enforcement architecture, a design choice motivated by the observation that not every governance check needs an LLM invocation:
- Hooks are deterministic shell scripts triggered on tool events. They block dangerous operations, auto-format code, and detect drift at zero LLM cost.
- Memory provides persisted behavioral rules that carry across sessions at minimal token cost on recall.
- Skills and checklists are loaded prompts with mandatory steps for complex workflows — higher token cost but high reliability through forced sequencing.
Agent dispatching also includes an isolation model: agents can be dispatched against a temporary worktree (assessing committed state only) or the live working tree (current state), controlled by a frontmatter flag.

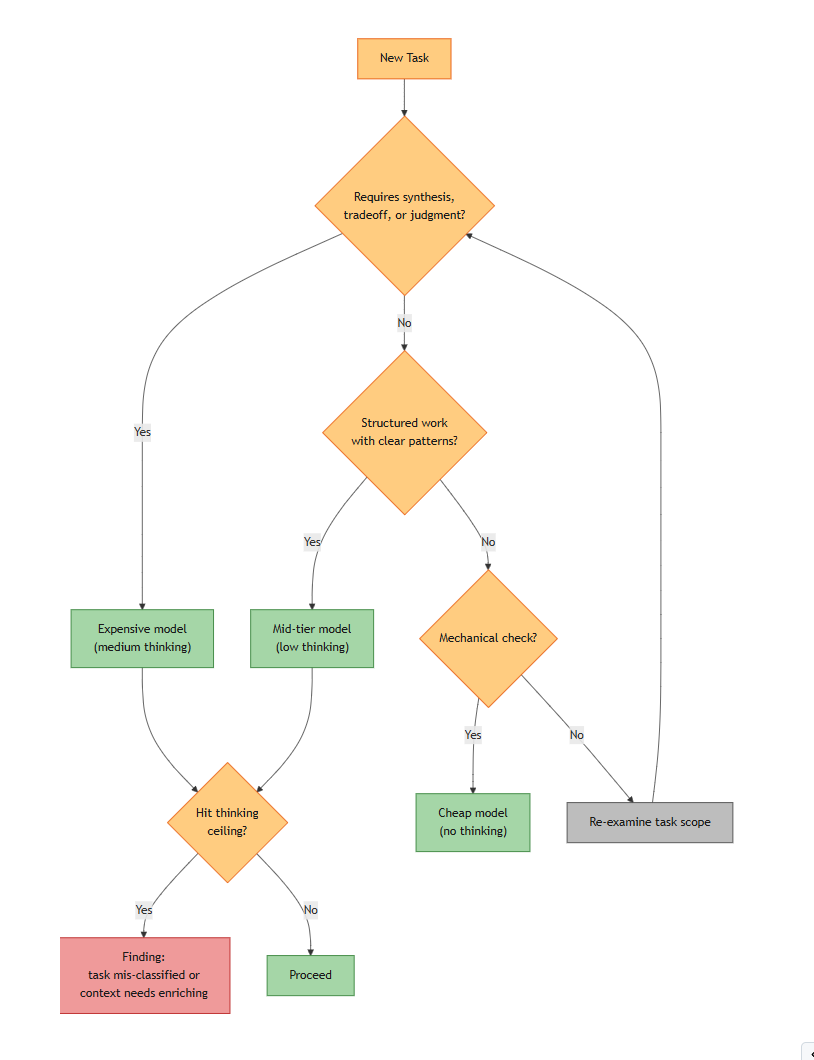
Within each task, agents select models appropriate to the work: synthesis and judgment tasks use expensive models with medium thinking budget; structured work with clear patterns uses mid-tier; mechanical checks use cheap models with no thinking overhead. When an agent hits its thinking ceiling, that’s a findings signal — the task was mis-classified or context needs enriching.
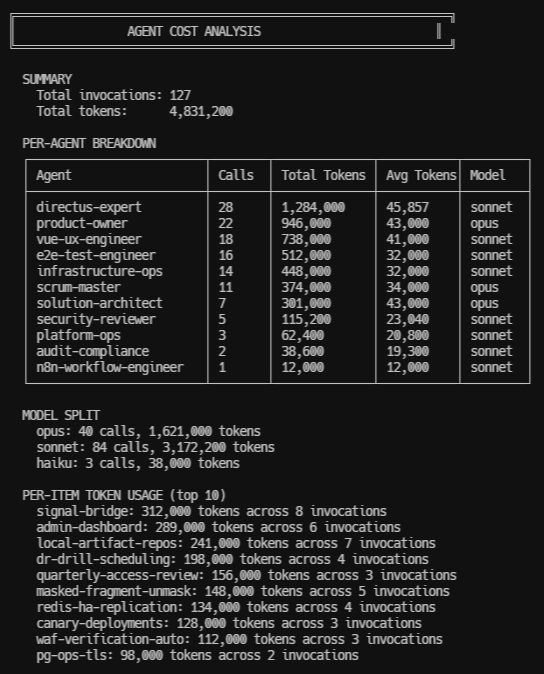
Agent Cost Analysis tracks token spend across every agent in the fleet — broken down by agent, model tier, and work item. It answers the question every team running agentic workflows eventually asks: where are my tokens going, and is the spend producing quality? The dashboard surfaces per-agent call counts, model distribution against budget ceilings, and per-item token cost so you can spot misclassified tasks, stale context driving re-exploration, and whether your cost-per-accepted-item trend is improving over time.
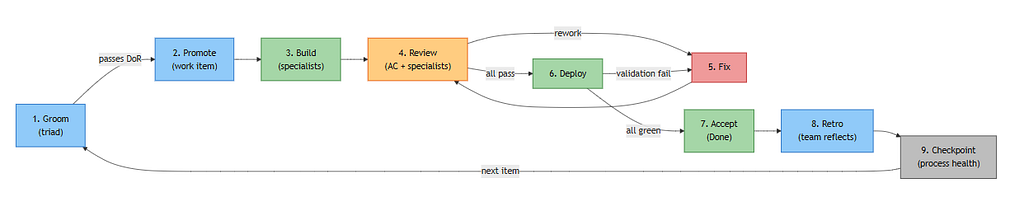
Work items flow through a nine-phase lifecycle — Groom, Promote, Build, Review, Fix, Deploy, Accept, Retro, Checkpoint — with shift-left validation at every stage. The executing agent owns the full validation cycle, not just their piece. This eliminates the “throw it over the wall” anti-pattern that plagues both human teams and naive agent architectures.

Related Work
The governance challenge for AI agent fleets is attracting attention from multiple directions, each addressing a different slice of the problem.
Dong et al.’s Governance-as-a-Service (GaaS) framework⁸ introduces runtime policy enforcement through trust scoring and graduated response modes — block, warn, or escalate — applied to individual agent outputs. Venutian Antfarm operates at a different level of abstraction: rather than filtering per-output, it governs the delivery process itself through fleet-wide pace control, role-based sensemaking, and lifecycle metrics. The two approaches are complementary — GaaS could enforce output-level policy within a fleet that Venutian Antfarm governs at the process level.
Snowden’s Cynefin framework⁴ has been applied to generative AI contexts with the argument that the domain is inherently complex and demands learning amplifiers rather than rigid policy factories. Our Crawl–Walk–Run–Fly progression and triad consultation model are an attempt to operationalize that insight — treating governance posture as a dynamic response to observed complexity rather than a fixed configuration.
The DORA research program⁷ provides the empirical foundation for our delivery outcome metrics. Wang et al.’s survey of LLM-based autonomous agents⁹ documents the structural evolution from individual ungoverned agents toward coordinated multi-agent assemblies — the trajectory that progressive autonomy with evidence-gated transitions is designed to support.
Why “Venutian Antfarm”
The name is deliberately playful. An ant farm is a system where individually simple agents produce complex collective behavior — but only when the colony has structure. The “Venutian” qualifier (yes, it’s a deliberate misspelling) nods to the alien, sometimes surreal experience of watching an AI agent fleet coordinate on real software — and to Alien Ant Farm, the band whose most famous track was a cover of someone else’s work, reinterpreted with enough energy to make it their own. That’s not a bad metaphor for what a governed agent fleet does: takes established patterns and executes them with a different kind of intensity.
The name is a reminder not to take ourselves too seriously while doing serious work. Annie are you OK?
Getting Started
Venutian Antfarm is open source: github.com/rdunie/venutian-antfarm
Clone the repo, define your compliance floor, add specialist agents for your stack, configure your deployment targets, and open in Claude Code. The six governance agents activate immediately alongside your specialists. The framework is dual-licensed under AGPL 3.0 (with an app-layer exemption) and a commercial license — your agents, compliance rules, and configurations remain your intellectual property.
Rob Dunie is a product and technology innovation leader with experience spanning enterprise architecture, agile delivery, and agentic software development. His previous research at Gartner on digital business moments and adaptive strategy informs his current work on AI governance frameworks.
If you’re experimenting with multi-agent delivery systems, I’d love to hear what governance challenges you’re encountering. The problems are real, the solutions are evolving, and the conversation is just getting started.
Appendix A: Framework Comparison

Appendix B: Research Gaps & Future Work
Progressive autonomy thresholds. Our evidence gates use domain-inspired thresholds (CFR < 5%, FPY > 95%). How do optimal values vary by codebase complexity, domain risk, or LLM backend? Controlled benchmarks against ungoverned baselines could quantify the throughput-safety tradeoff empirically.
Triad effectiveness. Does triad consensus reduce hallucination and architectural drift more than solo governance agents, or does the coordination overhead negate the benefit? A/B tests on SWE-bench variants measuring handoff yield and escalation frequency would clarify this. ⁶
Findings loop impact. Does declining findings frequency correlate with sustained Fly-pace stability, or does it produce the Cynefin “cliff” — a fleet so operationally confident it becomes brittle to novel edge cases? ⁴ Longitudinal studies across multiple fleets are needed.
Metrics generalization. DORA and flow quality metrics were developed for human teams. ⁷ Do agent-specific failure modes — deadlock, prompt drift, context diffusion — require new instruments not captured by existing frameworks?
Scaling limits. At what fleet size does triad coordination overhead outweigh benefit? Governance decay in large swarms — where triad agents can no longer maintain coherent orientation across the full portfolio — remains an open question. ⁹
I welcome empirical contributions via the repo — your production data could shape v2.
Notes
- Scheibenreif, D. and Dunie, R. “Get Out of Strategic Limbo: How to Discover and Exploit the Business Moments That Drive Digital Transformation.” Gartner Research, November 2017. ID G00341410.
(Gartner paywalled; institutional gateway) - Brehmer, B. “The Dynamic OODA Loop: Amalgamating Boyd’s OODA Loop and the Cybernetic Approach to Command and Control.” Proceedings of the 10th International Command and Control Research and Technology Symposium, 2005.
Alternate mirror - Boyd, J. “The Essence of Winning and Losing.” Unpublished briefing slides, 1996.
(Closely related compiled material: A Discourse on Winning and Losing) - Snowden, D. and Boone, M. “A Leader’s Framework for Decision Making.” Harvard Business Review, November 2007.
- Scaled Agile, Inc. SAFe 6.0 Framework: Agile Release Train. scaledagileframework.com, 2023.
RTE role - Ouyang, L. et al. “Training language models to follow instructions with human feedback.” NeurIPS, 2022.
- Forsgren, N., Humble, J., and Kim, G. Accelerate: The Science of Lean Software and DevOps. IT Revolution Press, 2018.
DORA research - Dong, Y. et al. “Governance as a Service: Runtime Policy Enforcement for LLM Agents.” arXiv:2504.01234, 2025.
- Wang, L. et al. “A Survey on Large Language Model based Autonomous Agents.” Frontiers of Computer Science, 2024.
Governing the Ant Farm: A Governance-First Framework for Multi-Agent Software Delivery was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.