Google’s Gemma 4 Is the Most Architecturally Interesting Open Model Released This Year. Here’s the Full Breakdown.
20.8% to 89.2%. Same benchmark. One year apart. Same rough model size. I stopped what I was doing and read the entire model card.
That doesn’t happen often.

Google dropped Gemma 4 on April 2, 2026 quietly, by their standards. No developer conference, no keynote. Just a blog post, four model weights on Hugging Face, and a license change that, if you work in AI infrastructure, should immediately get your attention.
Here’s what they shipped: four open-weight models built on the same research and technology stack as Gemini 3. Not a scaled-down version. Not a research preview. The same underlying architecture, distilled and optimized across a range of sizes designed to run on everything from an Android phone to an H100.
The Gemma series has had 400 million downloads and spawned over 100,000 community variants since it launched in early 2024. Gemma 4 isn’t just the next version of that it’s a different kind of release.
Here’s what this article is going to prove with actual data:
1. The architecture is genuinely novel - Gemma 4 uses a hybrid attention mechanism and a parameter trick for edge models that most coverage has completely glossed over.
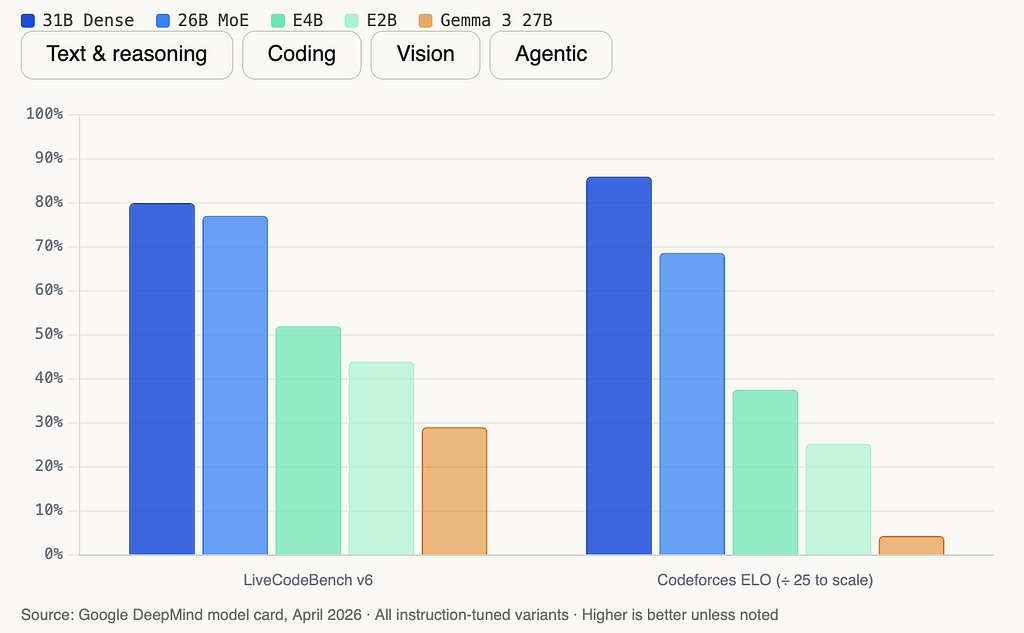
2. The benchmark jump from Gemma 3 is not incremental. On AIME 2026 math, Gemma 3 scored 20.8%. Gemma 4 31B scored 89.2%. That’s not a point release.
3. The edge story has become serious engineering, not a demo. The E2B model processes 4,000 tokens in under 3 seconds on a Raspberry Pi 5.
4. Apache 2.0 changes the enterprise calculus entirely and if you’ve been avoiding Gemma for legal reasons, that objection is now gone.
5. For specific workloads agentic tool use, offline code generation, local multimodal processing Gemma 4 is the right call today, not someday.
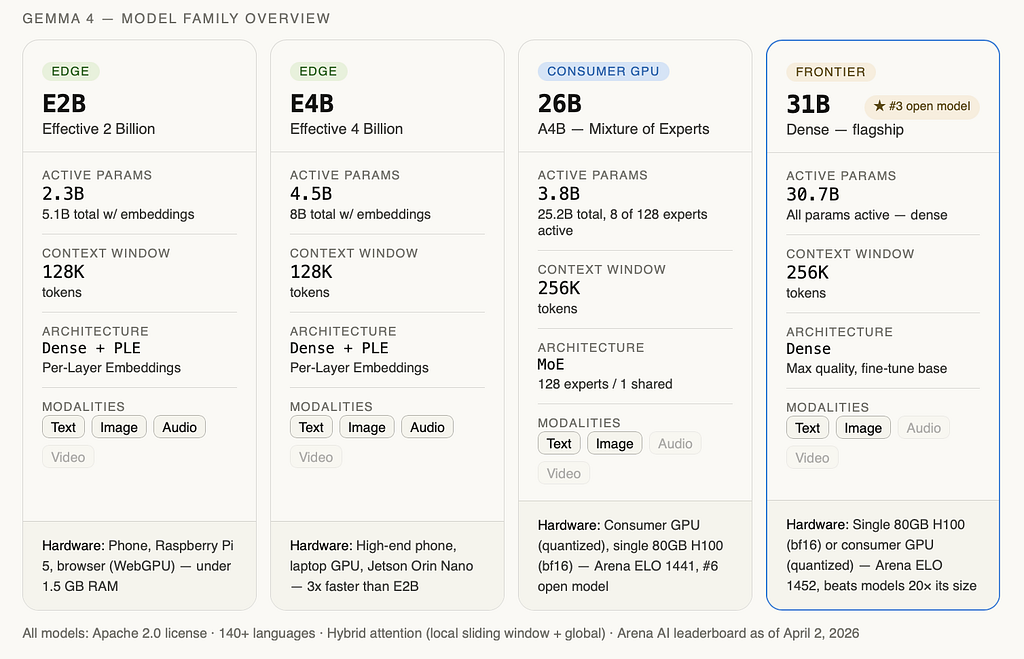
The architecture no one is explaining properly
Every article covering Gemma 4 this week has said the same three things: four sizes, Apache 2.0, runs on phones. Almost none of them have explained why it runs on phones, or what’s actually different under the hood. Let’s fix that.
Gemma 4 isn’t one architecture. It’s two distinct designs sharing a common research foundation and understanding that split is the key to understanding which model belongs in your stack.
The attention mechanism everyone skipped over
All four Gemma 4 models use what Google calls a hybrid attention mechanism. Every layer alternates between two types of attention: local sliding window attention and full global attention. The final layer is always global.
Here’s why that matters. Standard full attention is quadratic in sequence length as your context grows, compute cost explodes. Sliding window attention is linear, but it can only “see” a fixed window of tokens at a time, which limits long-range reasoning. Gemma 4’s hybrid design runs sliding window on most layers (cheap, fast, low memory) and reserves full global attention for a subset of layers where long-range dependencies actually need to be resolved. The final layer is always global so the model always has full context before generating its output.
The edge models use a 512-token sliding window. The larger models use 1024. The global layers also apply two additional optimizations: unified Keys and Values (reducing KV cache size significantly for long contexts) and Proportional RoPE - a positional encoding scheme designed to maintain coherence across very long sequences without degrading at the edges of a 256K context window.
This is not a new concept. But Gemma 4’s implementation is notable because it achieves 256K context on a 31B dense model running on a single 80GB H100, which would be impossible with naive full attention at that scale.
The edge trick: Per-Layer Embeddings
The E2B and E4B models have a parameter count that looks strange at first. E2B has 2.3 billion effective parameters but 5.1 billion total. E4B has 4.5 billion effective, 8 billion total. Where does the rest go?
Per-Layer Embeddings. Every decoder layer gets its own small embedding table for every token in the 262K vocabulary. These tables are large they’re what drives up the total parameter count but they’re used only for lookup operations. A lookup is memory-cheap and compute-cheap: you’re just reading a pre-computed value from a table, not running a matrix multiply.
The result: each layer has richer, more contextually differentiated token representations at essentially no additional inference cost. The model gets smarter without getting slower which is exactly the trade-off you need when you’re targeting a Raspberry Pi 5.
The MoE design: 128 experts, 8 active, 1 shared
The 26B model is architecturally different from the other three. It’s a Mixture-of-Experts model with 25.2 billion total parameters, but during any given inference pass, only 3.8 billion of those parameters are active.
How: the model has 128 expert sub-networks inside each MoE layer. For each token, a routing mechanism selects 8 of those 128 experts to process it plus one shared expert that always runs. The other 120 experts are idle for that token. This means the compute cost is closer to a 4B model than a 26B one, while the total parameter capacity (and therefore the model’s ability to specialize across different domains) is that of a 26B model.
The trade-off is real: lower quality ceiling than the 31B Dense on a per-token basis, because only a fraction of parameters participate in each prediction. But for workloads where speed matters more than raw quality real-time agents, streaming inference, interactive coding assistants, the 26B MoE is often the better call.
The vision and audio encoders
All four models have a vision encoder baked in, not bolted on. The edge models use a ~150M parameter vision encoder; the larger models use ~550M. Both support variable aspect ratios and resolutions via a configurable token budget (70 to 1,120 visual tokens), which lets you trade inference speed for visual detail depending on the task.
The edge models also include a ~300M parameter audio encoder, the larger models don’t. Audio supports up to 30 seconds of input, and the encoder handles both speech recognition and speech-to-translation across multiple languages natively.
Here’s how all of this fits together structurally:
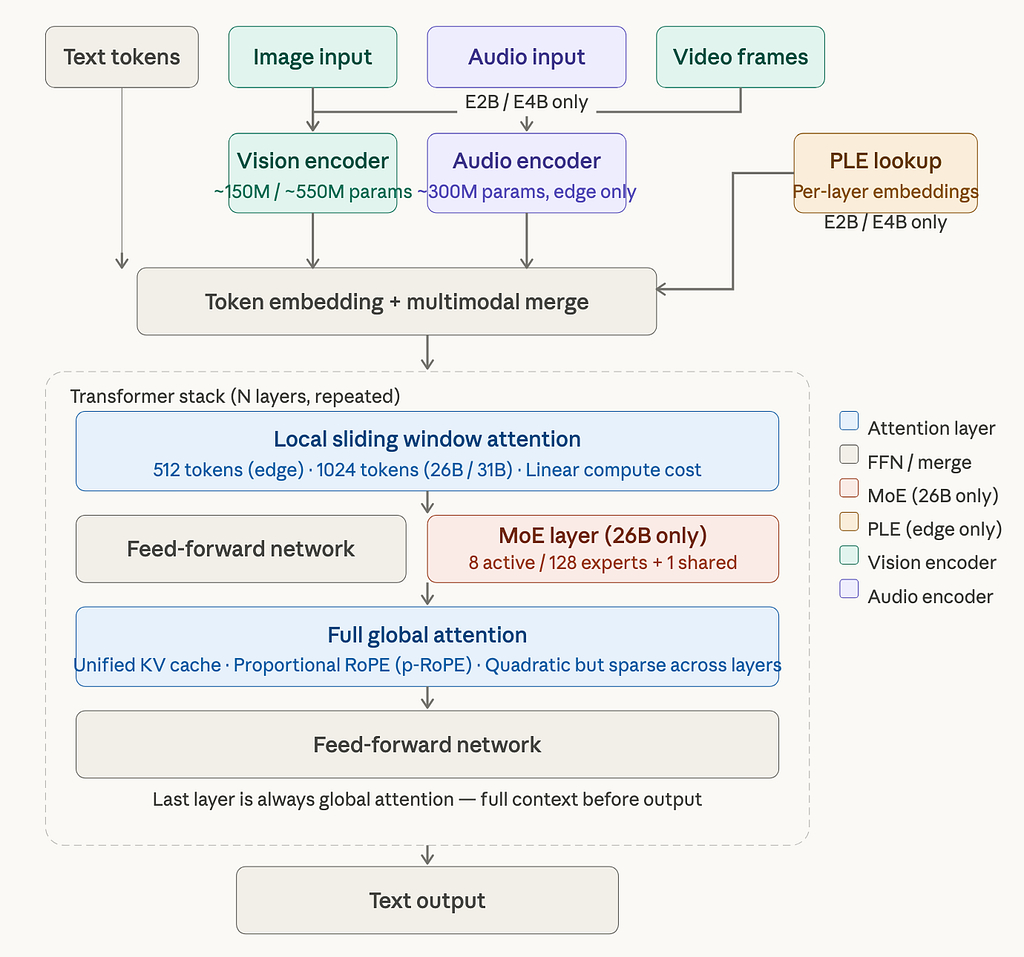
A few things worth calling out in that diagram before we move on. Notice that the MoE layer and the standard FFN layer sit at the same tier that’s intentional. In the 26B model, the MoE replaces the standard feed-forward network. The routing happens per-token, per-layer, and is invisible to the application calling the model. From your code’s perspective, it’s just a faster model.
Also notice where PLE lives: it’s not inside the transformer stack. It feeds into the token embedding merge before the stack. Each layer then reads from its own per-layer embedding table during the forward pass: hence “per-layer” but the lookup happens at the embedding stage, not mid-stack.
Now, the complete technical spec for all four models side by side:
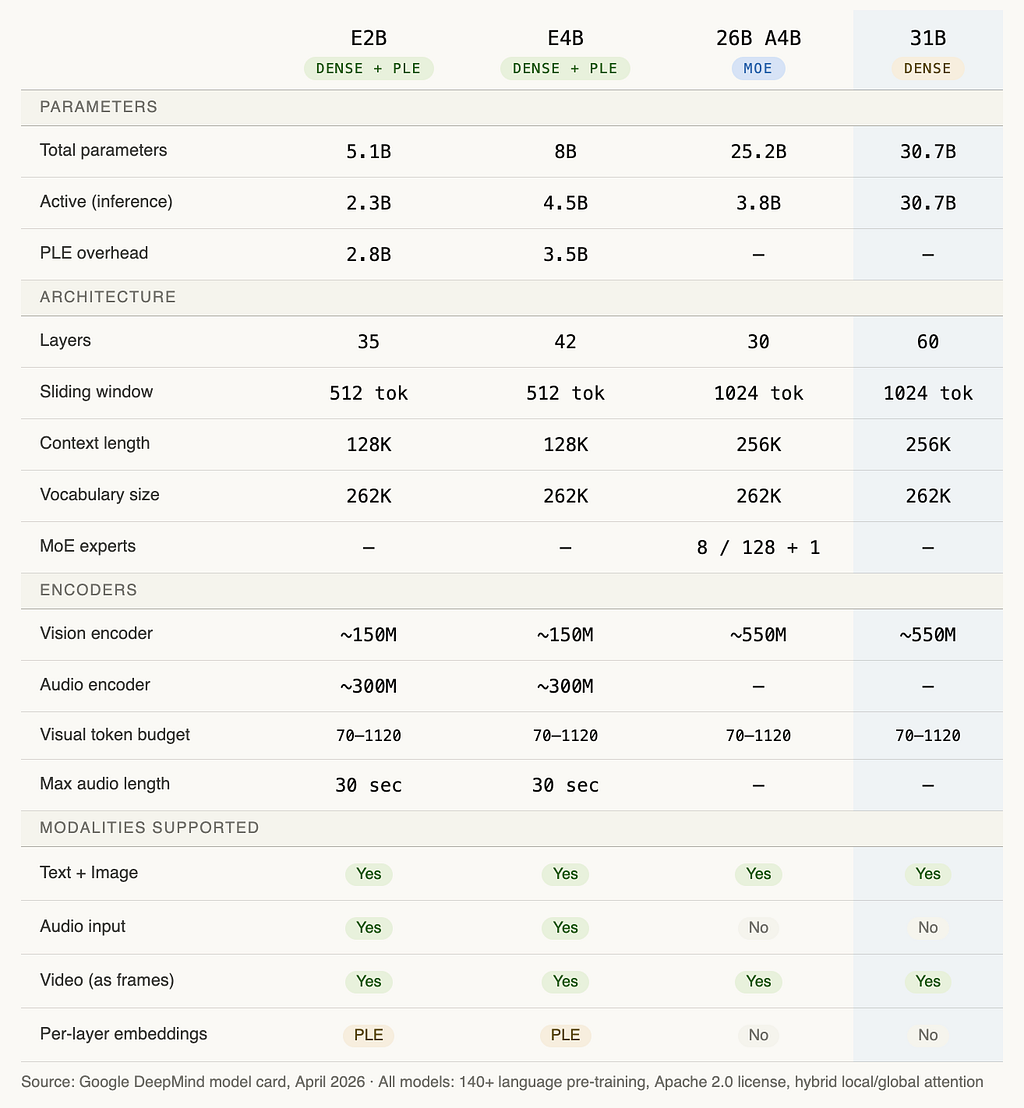
The number that surprises most people in that table: the 26B MoE has only 3.8B active parameters during inference fewer than the E4B. But it outperforms the E4B on every benchmark. That’s the MoE efficiency story in one data point.
One more thing worth flagging before we move to benchmarks. The 31B Dense has 60 layers. The 26B MoE has 30. More layers means more depth for reasoning which is why the 31B leads on tasks like AIME 2026 math and GPQA Diamond despite having “only” 31B parameters against competitors with far more. Depth is often more important than raw parameter count for difficult reasoning tasks.
The benchmark data: what the numbers actually say
Let me be direct about something before showing you these charts. Benchmarks are gameable, and Google has every incentive to cherry-pick the ones where Gemma 4 looks good. So I’m going to show you the full picture including the numbers where the gap to proprietary frontier models is still significant and let you decide what it means for your work.
That said: some of these jumps from Gemma 3 are not normal. They’re the kind of numbers that make you go back and check you’re reading the right row.
The Arena AI leaderboard story
Arena AI’s chat arena is one of the harder benchmarks to game because it’s based on human preference voting in blind head-to-head comparisons not multiple-choice questions a model can pattern-match. As of April 2, the Gemma 4 31B sitting at ELO 1452 puts it third among all open models in the world. The 26B MoE is at 1441, sixth. Gemma 3 27B was at 1365.
A jump of 87 ELO points is enormous. For context, the gap between Gemma 4 31B and models like Qwen3–122B (1415) or DeepSeek v3.2-exp (1421) models with three to four times the parameter count is larger than most people expect. The efficiency-per-parameter claim isn’t marketing. It shows up in the leaderboard data.
Here’s the performance vs. size chart directly:

The blue cluster is Gemma 4. Everything in gray to the right of it is a larger model. The amber dot is Gemma 3. Hover any point for the exact numbers.
What that chart makes viscerally clear: the 26B MoE and 31B Dense are competing with models at 122B, 397B, and 685B parameters and beating most of them. The only models ahead of Gemma 4 31B are GLM-5 (685B) and Kimi-k2.5-thinking (~1 trillion parameters). That is an extraordinary result at 31 billion parameters.
Now the benchmark that actually changed my mind
The leaderboard ELO is persuasive. But the number that made me stop and re-read the model card was this one:

AIME 2026 is the American Invitational Mathematics Examination - a competition math test designed for the top few percent of high school students in the US. Gemma 3 27B solved roughly 1 in 5 problems. Gemma 4 31B solves nearly 9 in 10. That is not a product iteration. That is a different class of reasoning capability.
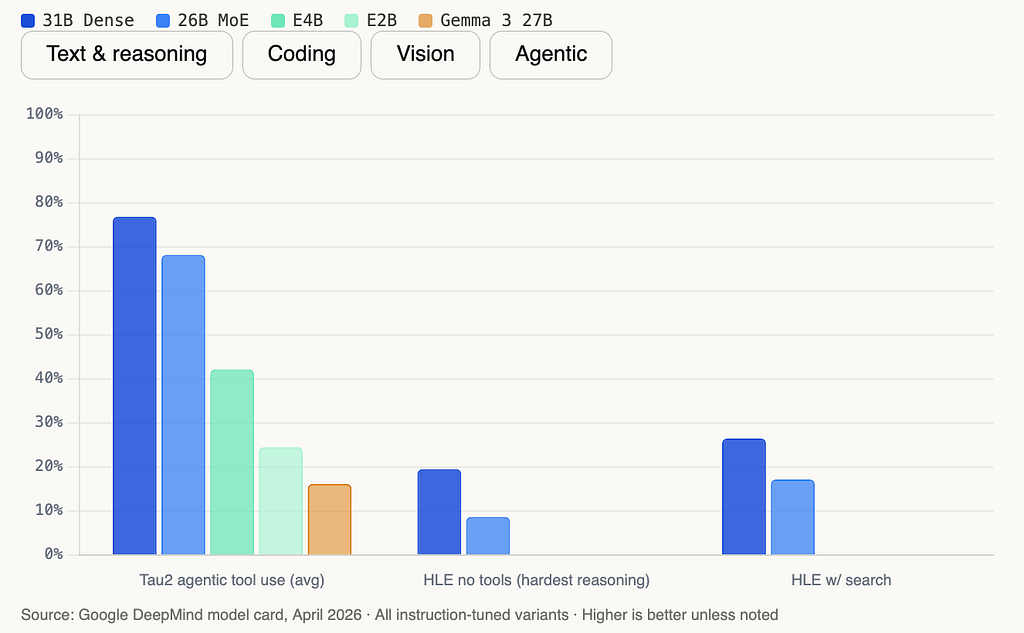
The Tau2 agentic tool use jump is the one I keep coming back to. Tau2 tests whether a model can reliably plan, call tools, interpret results, and complete multi-step workflows exactly what you need for production agents. Going from 16.2% to 76.9% is the difference between “interesting demo” and “deployable in production.”
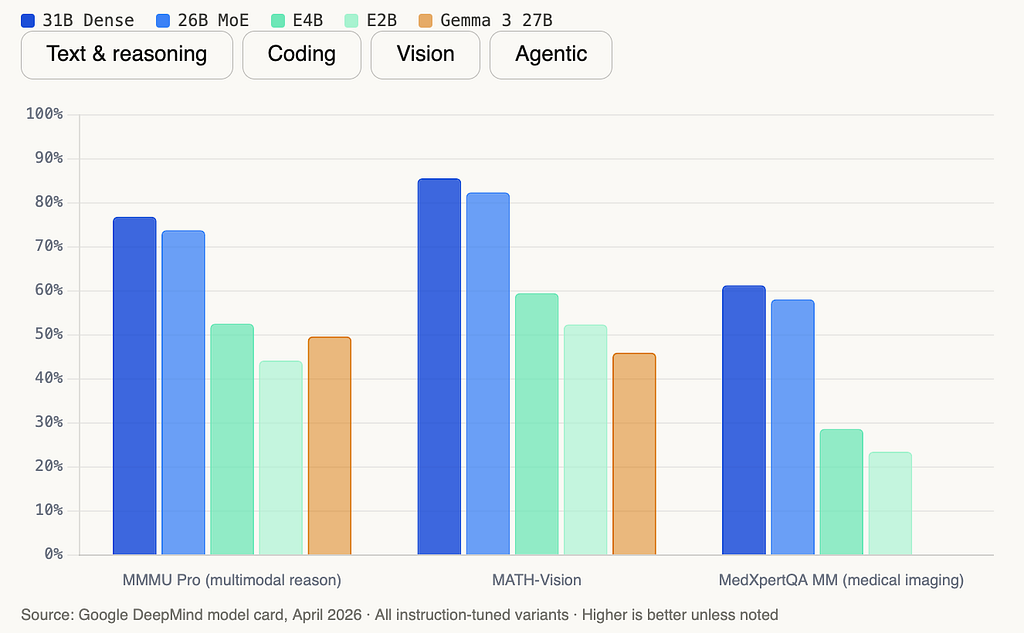
Here’s the full benchmark breakdown across all five models:
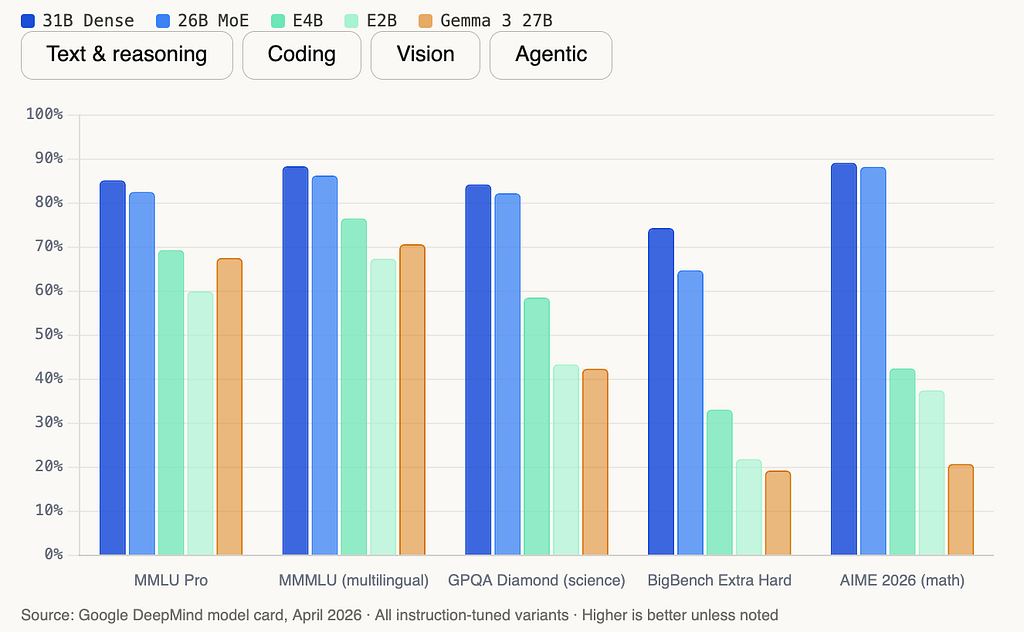
Where the gap still exists
HLE without tools at 19.5% for the 31B is the honest number. HLE (Humanity’s Last Exam) is designed to probe the absolute ceiling of AI reasoning across graduate-level academic domains. Gemma 4 31B solves about 1 in 5. With search enabled, it improves to 26.5% still below frontier proprietary models. If your workload lives at that extreme edge of difficulty, this is not your model yet.
For everything else - the 90% of real production workloads that involve classification, summarization, code generation, document parsing, agentic pipelines, and multimodal understanding the benchmark data says Gemma 4 is ready to be taken seriously.
What it can actually do, capability by capability
Benchmark scores tell you how a model performs on standardized tests. They don’t tell you what it’s like to build with. This section is about the second question: what Gemma 4 can actually do in your code, and what the limits of each capability are.
Thinking mode
Every model in the Gemma 4 family ships with a configurable reasoning mode. When enabled, the model works through a problem step by step before producing its final answer. The thinking output is wrapped in a special channel token so you can parse it separately from the response.
You toggle it with a single parameter at inference time:
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # flip this off to skip the reasoning trace
)
One important constraint: in multi-turn conversations, you strip the thinking content from the history before passing it back. Only the final response goes into the next turn’s context. Leaving thinking traces in history degrades output quality.
For the E2B and E4B models, disabling thinking actually suppresses the output entirely. For the 26B and 31B, disabling it still produces the channel tags but with an empty thought block. The architecture always reserves the pathway; you’re just choosing whether to use it.
The AIME 2026 and GPQA Diamond numbers above are with thinking enabled. Those benchmarks require it. For latency-sensitive workloads where you need a fast answer rather than a careful one, turning it off is a legitimate trade-off.
Vision and multimodal input
All four models process images natively. The key design decision Google made here is variable resolution support via a token budget system. Rather than forcing every image through the same fixed-size patch grid, you choose how many visual tokens to allocate per image:
- 70 tokens: fast inference, low detail. Good for classification, rough captioning.
- 280 tokens: balanced. Good for most visual QA tasks.
- 1,120 tokens: maximum detail. Required for OCR, document parsing, reading small text in charts.
This matters in practice. If you’re building a pipeline that processes thousands of images for classification, you don’t need 1,120 tokens per image. Running at 70 tokens is roughly 16 times cheaper in compute than running at 1,120. The same model, the same weights, tuned by a single parameter.
Images should be placed before text in your prompt for best performance. For document parsing and OCR tasks, use the higher token budgets. For anything requiring fine-grained text extraction, the 26B and 31B use a larger vision encoder (~550M params vs ~150M on edge models) and will produce noticeably better results.
Video is supported on all four models by processing sequences of frames. Maximum 60 seconds at one frame per second. Use lower token budgets here because you’re multiplying cost by frame count.
Audio (edge models only)
The E2B and E4B models include a dedicated audio encoder that the larger models don’t have. It handles two tasks: automatic speech recognition (transcription within the same language) and automatic speech translation (transcribe in source language, translate to target).
Maximum input length is 30 seconds. The encoder was trained across multiple languages and handles multilingual ASR well. On CoVoST, E4B scores 35.54 and E2B scores 33.47 on translation quality.
The practical applications: voice-driven interfaces that run completely offline on Android, transcription pipelines on constrained hardware, multilingual support without routing audio to a cloud service.
Function calling and agentic workflows
This is the capability I’d highlight above all others for most developers reading this. Gemma 4 has native support for structured tool use, including function calling with typed parameters, structured JSON output, and system prompt handling.
The combination matters. Prior Gemma models supported basic instruction following but weren’t reliably usable for production agentic workflows because the tool-use adherence wasn’t strong enough. The Tau2 jump from 16.2% to 76.9% reflects a model that can now plan a multi-step task, call a tool, interpret the result, and decide what to do next without falling apart.
Google’s own Agent Development Kit integrates with Gemma 4 directly. If you’re building agents that interact with APIs and need to run them locally or within a private infrastructure boundary, this is now a real option.
Code generation
Codeforces ELO of 2,150 on the 31B is the headline number, but the more useful fact for most developers is that Gemma 4 supports offline code generation. The model generates code without a network connection. You can build a local coding assistant that never sends your codebase to an external server.
LiveCodeBench v6 at 80% on the 31B and 77.1% on the 26B MoE means competitive programming problems are largely within reach. For practical tasks like code review, completion, refactoring, and explanation, both the 31B and 26B are strong choices.
The 26B MoE is particularly interesting for coding workloads because its inference speed is close to a 4B model while its quality is close to the 31B on most coding tasks. If you’re running a coding assistant where latency matters, the 26B is often the better choice than the 31B.
Long context
Edge models support 128K tokens. The 26B and 31B support 256K. For reference: a 256K context window holds roughly 200,000 words, or about two full-length novels, or a mid-sized code repository.
The MRCR v2 8-needle 128K benchmark tests whether a model can find specific pieces of information buried in very long documents. The 31B scores 66.4%. The 26B scores 44.1%. Edge models score in the 19–25% range. The performance degradation at long context is real and worth accounting for when choosing which model to use for retrieval-heavy tasks.
Multilingual
The models were pre-trained on over 140 languages and have strong out-of-box performance in 35+. The MMMLU multilingual QA benchmark shows the 31B at 88.4% and the E2B still at a respectable 67.4%. For teams building for non-English audiences, this is baked in rather than retrofitted.
Here is the full capability picture across all four models:
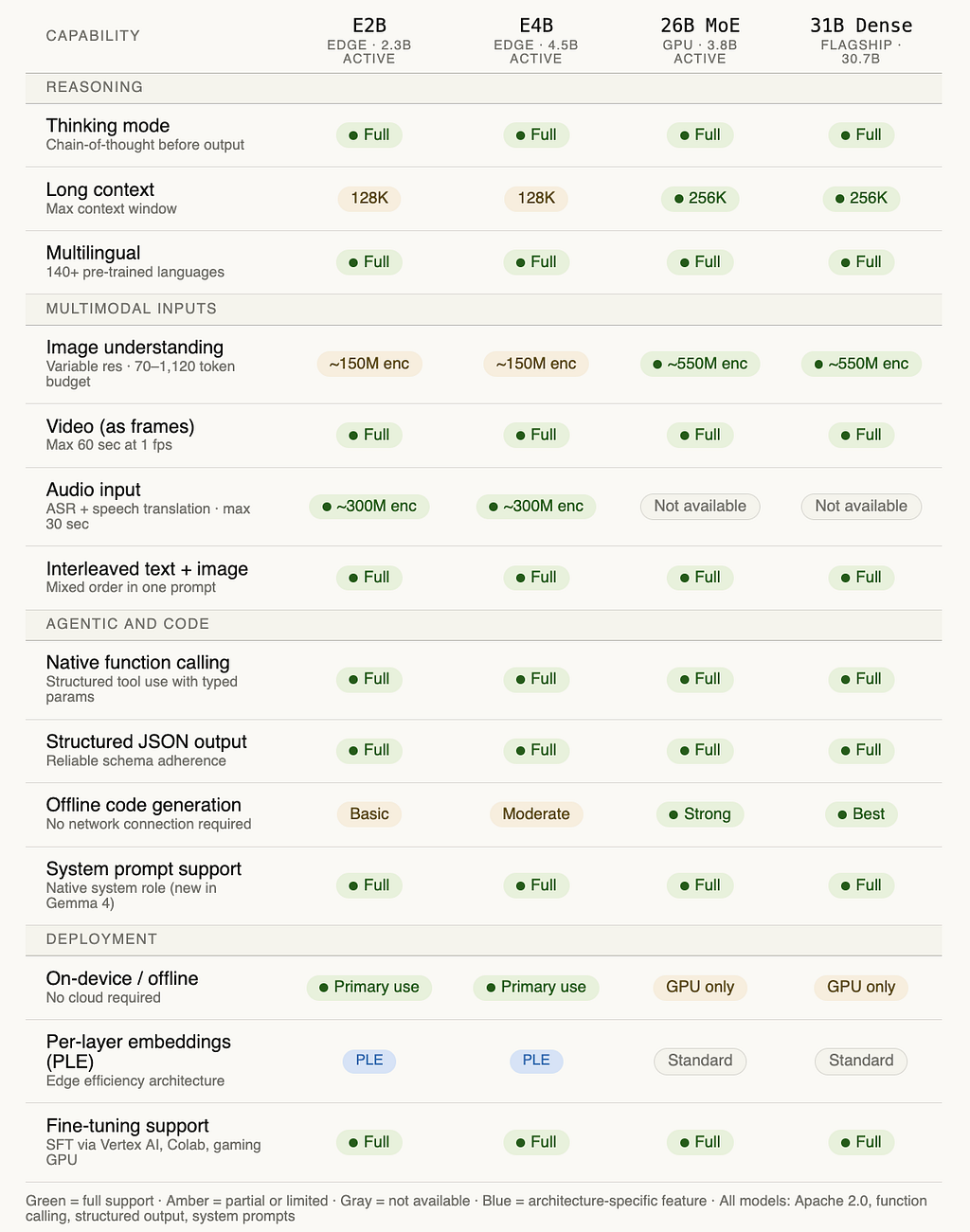
The one row worth lingering on: system prompt support. Gemma 3 didn’t have a native system role. Gemma 4 does. This sounds like a minor UX detail but it actually matters for production deployments. With a proper system role, you can inject persona, guardrails, and task context in a structured way that the model was explicitly trained to respect rather than treat as just another turn in the conversation.
The other thing the matrix makes clear: audio is a deliberate edge-only capability. Google made a choice to put the audio encoder exclusively in the two smallest models. The reasoning is sound. Audio input is most valuable in the exact scenarios where you want a model running offline on a device in your hand, not in a server rack.
The edge story: runs on your phone, Raspberry Pi, and Jetson Nano
The phrase “runs on-device” has been in AI marketing copy for three years. It usually means “runs on a high-end MacBook with an M3 Max if you quantize it heavily and don’t ask it anything too hard.”
Gemma 4’s edge story is different, and the difference is measurable.
On a Raspberry Pi 5, the E2B model processes 4,000 input tokens across two distinct tasks in under 3 seconds. Using Google’s LiteRT-LM runtime, it fits in under 1.5 gigabytes of RAM. It runs completely offline. It supports text, images, audio, and video frames. And it scores 67.4% on the multilingual MMMLU benchmark, which means it’s not just fast on constrained hardware, it’s genuinely useful.
For context: a Raspberry Pi 5 costs around $80.
What changed architecturally
Two things made this possible, and both were covered in the architecture section above but worth connecting to the deployment story here.
Per-Layer Embeddings (PLE) keep the effective parameter count at 2.3 billion during inference. The total parameter count is 5.1 billion, but the extra 2.8 billion are embedding lookup tables that require reads, not multiply-accumulate operations. On ARM processors without dedicated matrix multiply units, this distinction is the difference between usable latency and unusable latency.
The hybrid attention mechanism handles the 128K context window without the quadratic memory explosion that would otherwise make long-context inference impossible on a device with 4–8GB of shared memory. Sliding window attention on most layers, global attention reserved for a handful of layers, unified KV cache to keep memory footprint manageable.
Neither of these is a software optimization applied after the fact. They’re architectural decisions made during training. The model was designed to be fast on ARM before a single line of the LiteRT-LM runtime was written.
The Android deployment path
Google’s AICore Developer Preview is available today on supported devices. You can download the E2B and E4B models directly to your Android test device, run inference locally, and ship to production via two routes.
The first route is the ML Kit GenAI Prompt API, which is the production-ready path for Android apps today. The second is the AICore framework itself, which is getting tool calling, structured output, system prompts, and thinking mode support during the preview period.
The forward-compatibility angle is worth understanding clearly. Gemma 4 is the foundation for Gemini Nano 4, which will ship on next-generation Pixel hardware later this year. Code you write against Gemma 4 today runs on Gemini Nano 4 automatically. Google is giving you a head start on the production runtime before the hardware ships. That is not a common offer.
For developers outside the Android ecosystem: E2B and E4B run on iOS with CPU and GPU support, on Windows, Linux, and macOS, and in the browser via WebGPU. The cross-platform deployment story is genuinely broad.
The hardware partners
Google worked directly with Qualcomm Technologies and MediaTek on the E2B and E4B optimization. This means the models are tuned for the specific AI accelerators in current flagship Android chips, not just for generic ARM inference. On the server side, the 26B and 31B models are optimized for NVIDIA Blackwell GPUs (RTX Pro 6000 with 96GB vGPU memory is specifically supported on Cloud Run) and AMD GPUs via the ROCm stack.
On NVIDIA Jetson Orin Nano, the E2B and E4B run with near-zero latency. Jetson Orin Nano targets robotics and industrial IoT. If you’re building anything that moves and needs to reason about its environment locally, this is now a serious option.
The real use cases this unlocks
Four categories that weren’t viable before and are now:
Voice assistants that work in airplane mode. The E2B and E4B’s audio encoder handles speech recognition and translation offline. Combined with function calling, you can build a voice-driven agent that completes multi-step tasks without touching a network.
Local code review with zero data leakage. Your proprietary codebase never leaves the machine. The 26B MoE running on a consumer GPU provides near-31B quality code review at 4B inference speed.
On-device RAG pipelines. Embed, retrieve, and generate without a cloud provider in the loop. With 128K context, you can pass substantial document sets in a single prompt.
Robotics and industrial IoT. Jetson Orin Nano deployments for systems that need real-time multimodal reasoning about camera feeds, sensor data, and audio inputs in environments where network connectivity is unreliable or prohibited.
Here is a decision flowchart to help you land on the right model for your specific deployment context:
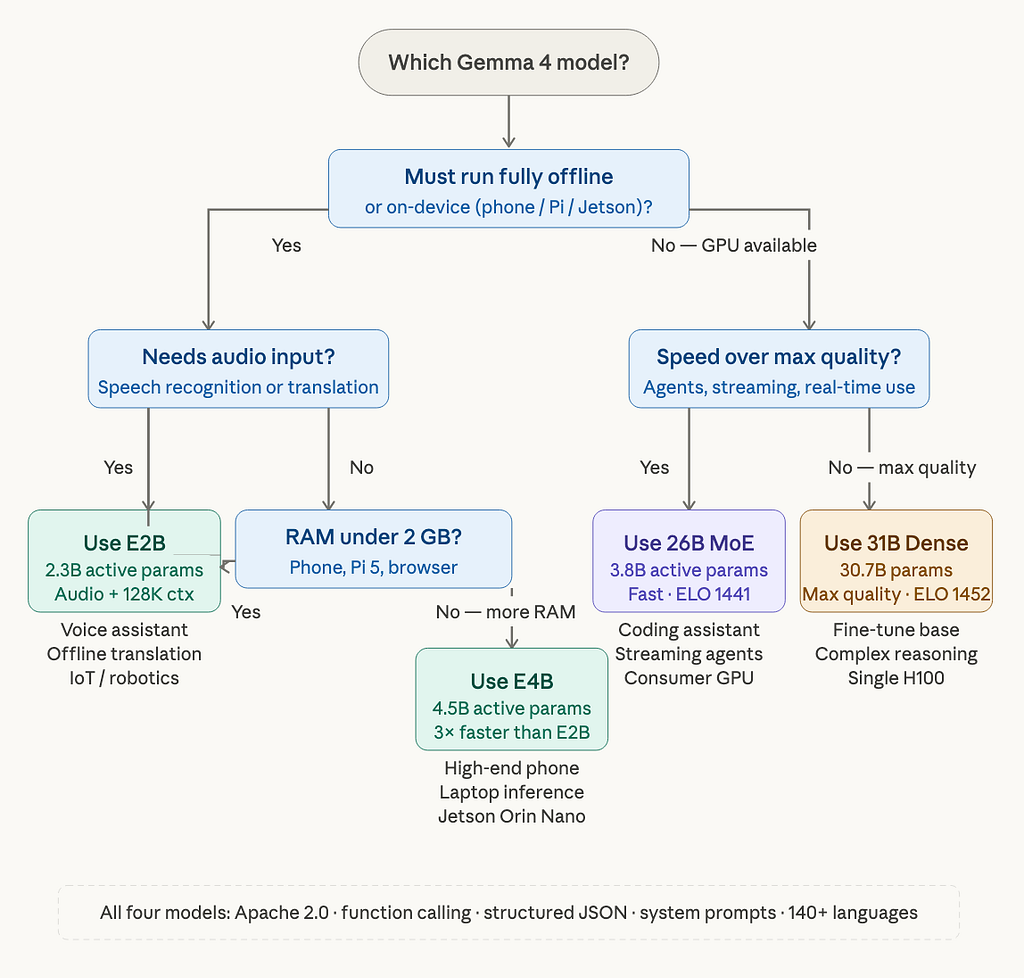
The flowchart collapses to two primary questions. First: does your deployment need to run without a network connection or on constrained hardware? If yes, you’re in the E2B/E4B column. If no, you have a GPU available and the second question becomes whether you need throughput or peak quality.
One nuance the flowchart doesn’t capture fully: the 26B MoE is often the right choice for cloud-hosted agents even when you could afford the 31B. The speed difference matters at scale. If you’re running thousands of agent steps per hour and each step involves a model call, the 26B MoE’s near-4B inference speed translates directly into cost and latency savings with only a modest quality trade-off. On Tau2 agentic tool use, the 26B MoE and the 31B Dense score identically at 76.9%. The speed advantage of the MoE is free. For agentic workflows specifically, the 26B MoE is the more compelling choice.
That number surprised me too when I went back to the model card. On agentic tool use, the gap between the 26B MoE and the 31B Dense is much smaller than the gap on pure reasoning benchmarks. Build your agents on the MoE first. Graduate to the Dense only if you hit a wall.
The Apache 2.0 move: why it changes the enterprise conversation
Licensing is the part of model releases that engineering blogs skip and legal teams actually read. With Gemma 4, the licensing change is the part of this release that matters most for a significant number of organizations and it deserves more than a paragraph.
Previous Gemma models shipped under Google’s custom Gemma Terms of Use. That document had specific clauses that created friction for commercial deployment: restrictions on using Gemma outputs to train competing models, requirements around attribution in certain contexts, and enough ambiguity in edge cases that enterprise legal teams would routinely flag it as needing review before sign-off. The Gemma license was not hostile, but it was non-standard. And in enterprise software procurement, non-standard equals slow.
Apache 2.0 is the most widely understood permissive open source license in existence. Every major enterprise legal team has a pre-approved stance on it. It grants you four things clearly and without qualification:
Use the model commercially without paying royalties. Modify the weights and architecture for any purpose. Redistribute the modified model, including as part of a closed-source product. Deploy it in any infrastructure without contractual obligations back to Google.
The “without contractual obligations back to Google” part is the sovereignty argument. An organization running Gemma 4 on their own hardware, fine-tuned on their own data, serving their own users has zero ongoing relationship with Google required. No API keys, no usage monitoring, no data flowing through Google’s infrastructure. That is a fundamentally different risk profile than any hosted model service.
Clément Delangue, co-founder and CEO of Hugging Face, called the switch to Apache 2.0 “a huge milestone” on launch day. He’s right, but not just for philosophical reasons. Hugging Face’s enterprise customers have been asking for Apache 2.0 licensed foundation models for years. The Gemma license was one reason Llama remained the default open model choice in enterprise environments despite Gemma’s technical merits.
How it compares to the competition
Meta’s Llama 4 is not Apache 2.0. It ships under Meta’s Llama Community License, which restricts use by services with more than 700 million monthly active users and prohibits using Llama outputs to train competing models. For most companies that is not a binding constraint, but it is a non-standard license that requires legal review and creates ongoing compliance obligations.
Mistral’s models have historically shipped under Apache 2.0, which is one reason Mistral built such strong enterprise adoption. Gemma 4 now matches that baseline while offering substantially stronger benchmark performance.
OpenAI and Anthropic’s models are not open weight at all. You access them through an API, subject to their terms of service, with pricing and rate limits set unilaterally. The comparison to Gemma 4 is not about which model is smarter. It is about the deployment model you are choosing.
Here is that comparison across the major models your team is likely already using or evaluating:
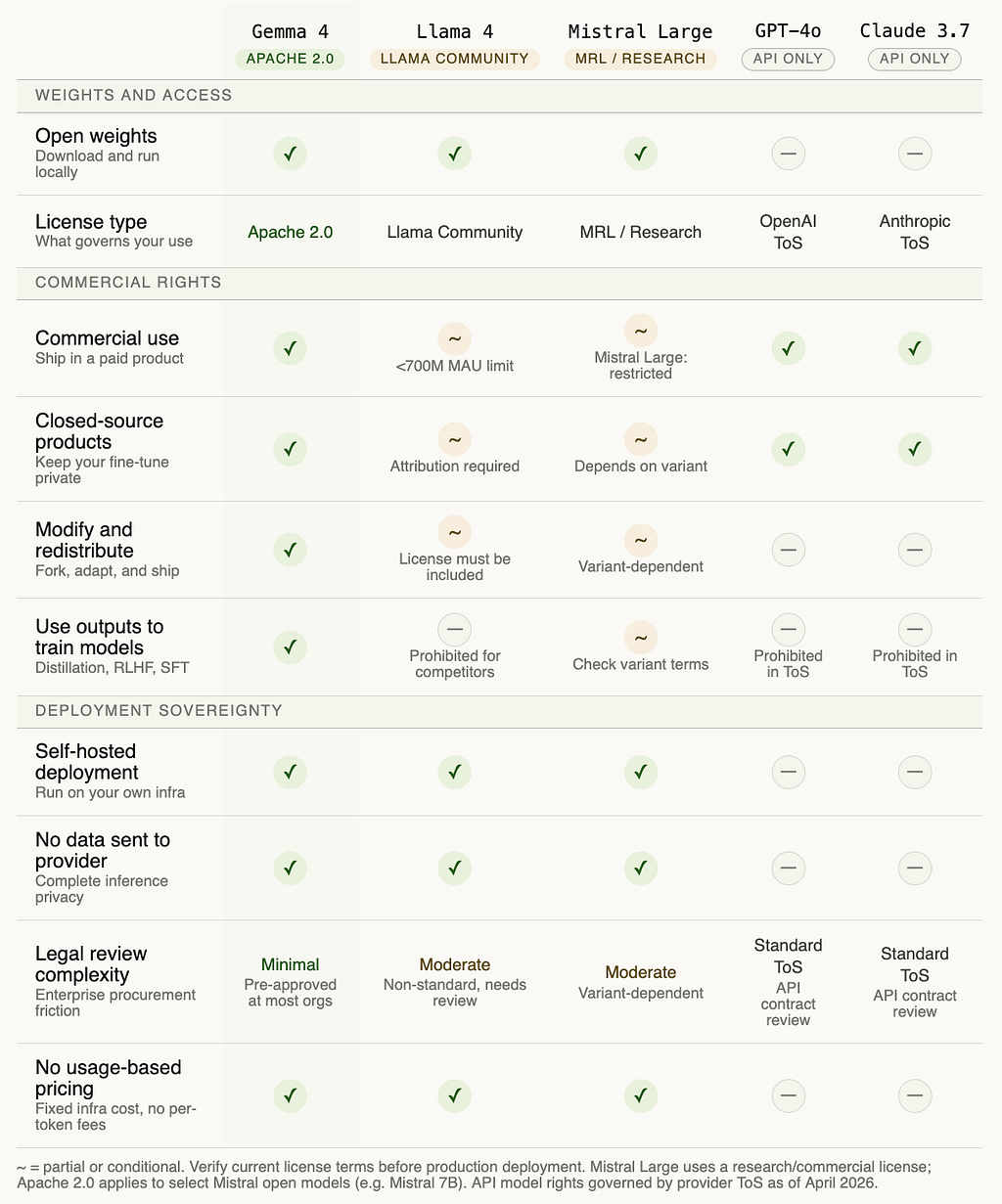
The comparison makes the strategic picture clear. GPT-4o and Claude 3.7 are excellent models. They are not open weight, they do not support self-hosting, and your inference data flows through a third-party API. For many workloads that is an acceptable trade-off. For regulated industries, sensitive data pipelines, or any context where per-token cost compounds at scale, the trade-off looks different.
The “use outputs to train models” row is the one worth flagging specifically for ML teams. Both OpenAI and Anthropic prohibit using outputs from their models to train competing AI systems. If you are building a training pipeline that involves model-generated data, GPT-4o and Claude outputs cannot legally be part of it. Gemma 4 outputs can be used to train anything, including a model that competes with Gemma.
That is the Apache 2.0 position stated plainly. Google is accepting that permissiveness fully, including the part where it could be used against them.
The sovereignty angle
Google’s cloud blog specifically mentions Sovereign Cloud solutions as a deployment path for Gemma 4. Sovereign Cloud refers to infrastructure configurations where data processing is guaranteed to remain within a specific geographic and legal jurisdiction. For European organizations operating under GDPR, for government entities, for healthcare organizations subject to HIPAA, and for financial institutions with strict data residency requirements, running an open-weight model on your own infrastructure is often not a preference but a compliance requirement.
Gemma 4 under Apache 2.0 fits that requirement cleanly. Fine-tune it on your data, deploy it in your jurisdiction, serve requests without the data leaving your infrastructure. No exceptions, no data processing agreements to negotiate, no dependency on a third-party uptime SLA.
The combination of frontier-adjacent benchmark performance and a license that fits enterprise legal requirements without friction is genuinely new territory for open models. Llama came close. Gemma 4 closes the gap.
How to start in under 5 minutes, with real code
Everything up to this point has been analysis. This section is about opening a terminal.
Gemma 4 is available right now on Hugging Face, Kaggle, Ollama, Google AI Studio, and AI Edge Gallery. The 31B and 26B MoE are accessible in Google AI Studio without any local setup. The edge models are in AI Edge Gallery. If you want to run weights locally, you have three main paths depending on how much configuration you want to do.
One note before the code: the recommended sampling configuration across all Gemma 4 models is temperature=1.0, top_p=0.95, top_k=64. These are not defaults in most frameworks. Set them explicitly, especially if you are comparing outputs across experiments and need consistency.
A second note on multi-turn conversations with thinking enabled: the model’s internal reasoning trace should never appear in the conversation history you pass back on the next turn. Only include the final response. Thinking content in history degrades output quality noticeably. The parse_response method on the processor handles this automatically if you use it.
Here is everything you need to go from zero to running inference, across three paths: Ollama(fastest start), Transformer + thinking Mode, Multimodal image input.
1. Ollama(fastest start)
# Install Ollama if you haven't already
curl -fsSL https://ollama.com/install.sh | sh
# Pull and run the 27B MoE (fast inference on consumer GPU)
ollama run gemma4:27b
# Or the flagship 31B Dense
ollama run gemma4:32b
# Edge models for CPU / low-RAM machines
ollama run gemma4:4b
ollama run gemma4:2b
Note: Hardware needed: The 27B MoE runs on a single consumer GPU with ~20GB VRAM (quantized). The 31B needs ~24GB VRAM quantized or a single 80GB H100 in bf16. Edge models run on CPU with under 4GB RAM.
2. Transformer + thinking Mode
Bash - install -> Load the model -> Run inference - thinking mode off (fast) or Run inference - thinking mode on (complex reasoning)
pip install -U transformers torch accelerate
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-27b-it" # or gemma-4-E2B-it, gemma-4-E4B-it, gemma-4-32b-it
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
dtype=torch.bfloat16,
device_map="auto"
)
# thinking mode off (fast)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain hybrid attention in one paragraph."},
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # fast path, no reasoning trace
)
inputs = processor(text=text, return_tensors="pt").to(model.device)
input_len = inputs["input_ids"].shape[-1]
outputs = model.generate(
**inputs,
max_new_tokens=1024,
temperature=1.0, # recommended sampling params
top_p=0.95,
top_k=64
)
response = processor.decode(outputs[0][input_len:], skip_special_tokens=True)
print(response)
# thinking mode on (complex reasoning)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Solve this step by step: if f(x) = x^3 - 2x + 1, find all real roots."},
]
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # model reasons before answering
)
inputs = processor(text=text, return_tensors="pt").to(model.device)
input_len = inputs["input_ids"].shape[-1]
outputs = model.generate(**inputs, max_new_tokens=4096, temperature=1.0, top_p=0.95, top_k=64)
raw = processor.decode(outputs[0][input_len:], skip_special_tokens=False)
# parse_response separates thinking trace from final answer
result = processor.parse_response(raw)
print("Thinking:", result.thinking)
print("Answer:", result.response)
# IMPORTANT: in multi-turn, only pass result.response back into history.
# Never include the thinking trace in the next turn's messages list.
Note: Thinking mode trade-off: Thinking enabled is slower but scores significantly higher on math, science, and complex reasoning. Thinking disabled is faster and works well for summarization, classification, chat, and code completion where step-by-step reasoning is not needed.
3. Multimodal image input
A. Python: Image input
from PIL import Image
import requests, torch
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-27b-it"
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, dtype=torch.bfloat16, device_map="auto")
# Load an image (local path or URL)
image = Image.open("diagram.png") # or requests.get(url).content
# Always place image BEFORE text for best results
messages = [
{
"role": "user",
"content": [
{"type": "image"}, # image first
{"type": "text", "text": "Extract all text from this diagram and summarise the architecture."}
]
}
]
# Visual token budget: 70=fast/low-detail, 1120=OCR/document parsing
# For chart reading or small text: use 560 or 1120
# For classification or captioning: use 70 or 140
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=text, images=[image], return_tensors="pt").to(model.device)
input_len = inputs["input_ids"].shape[-1]
outputs = model.generate(**inputs, max_new_tokens=1024, temperature=1.0, top_p=0.95, top_k=64)
response = processor.decode(outputs[0][input_len:], skip_special_tokens=True)
print(response)
B. Python: speech recognition prompt (For Audio input use E2B and E4B only).
# Use E2B or E4B model only - larger models have no audio encoder
MODEL_ID = "google/gemma-4-E4B-it"
# ASR system prompt structure (required for reliable transcription)
ASR_PROMPT = """Transcribe the following speech segment in English into English text.
Follow these instructions:
* Only output the transcription, with no newlines.
* When transcribing numbers, write the digits (write 3 not three)."""
messages = [
{"role": "system", "content": ASR_PROMPT},
{
"role": "user",
"content": [
{"type": "audio"}, # audio input, max 30 seconds
{"type": "text", "text": "Transcribe."}
]
}
]
# Pass audio array (numpy float32, 16kHz) via processor(audio=audio_array, ...)
Note: Visual token budget guide: Use 70–140 tokens for image classification, bulk processing, or video frames. Use 280–560 for general visual QA. Use 1,120 for OCR, document parsing, reading charts with fine text, or any task requiring high spatial accuracy.
Three things in that code worth calling out because most tutorials skip them.
The parse_response call on the thinking output is not optional if you want clean separation of the reasoning trace from the final answer. The raw output without it includes the channel tokens and the full thought block mixed into the string. If you're logging, storing, or displaying responses to users, you want to run parse_response every time thinking is enabled.
The visual token budget is a parameter most developers will ignore until they hit a case where OCR is coming back wrong or image text is being misread. The default in most framework implementations leans toward speed. If you are parsing documents, switch explicitly to 1,120 before you spend an hour debugging what looks like a model failure but is actually a resolution issue.
The audio prompt structure is strict. The transcription quality on the E2B and E4B models is noticeably better when you use the exact prompt format from the model card rather than a loose instruction. The model was trained to follow that structure and the results reflect it.
Where to access each model right now
- Google AI Studio: 31B and 26B MoE, no local setup required
- AI Edge Gallery: E2B and E4B, Android device required
- Hugging Face: all four models, weights available for download
- Kaggle: all four models, includes free GPU notebooks to run the 27B and 31B
- Ollama: all four models, simplest path for local inference
- Android AICore Developer Preview: E2B and E4B, production path via ML Kit GenAI Prompt API
Competitive context: where Gemma 4 sits vs Llama 4, Mistral, Qwen3, and the frontier APIs
The open model landscape in April 2026 is crowded in a way it wasn’t twelve months ago. Chinese labs have been shipping aggressive open-weight models at a pace that has compressed the quality gap with proprietary frontier models significantly. Meta has distribution advantages that no other open-model provider can match. Mistral has deep enterprise relationships in Europe. Against that backdrop, Gemma 4 needs to earn its place in your stack rather than assume it.
Here is an honest positioning of where Gemma 4 sits relative to each major alternative.
Llama 4
Meta’s Llama series is the default open-model choice for most developers today. The distribution advantage is real: Llama is integrated into more inference frameworks, has more community fine-tunes, has more tutorials, and has broader organizational familiarity than any other open model family. If your team already has Llama 4 running in production, switching to Gemma 4 is a meaningful migration cost that the benchmark differences need to justify.
Where Gemma 4 has a clear edge: the Apache 2.0 license versus the Llama Community License, the native audio encoder on edge models, and the Tau2 agentic tool use score. Llama 4’s agentic performance is competitive but Gemma 4 31B’s 76.9% on Tau2 puts it ahead on the workloads that matter most for production agent builders.
Where Llama 4 retains an advantage: ecosystem depth. The volume of community fine-tunes, quantizations, and deployment recipes for Llama models is substantially larger than what exists for Gemma today. If you need a specific domain adaptation that someone else has already trained, Llama is more likely to have it on Hugging Face right now.
Qwen3 series
The Qwen3 models from Alibaba represent the strongest challenge to Gemma 4 at comparable parameter counts. Qwen3–27B sits at roughly ELO 1404 on Arena AI versus Gemma 4 31B’s 1452. Qwen3–122B-a10B sits at 1415, still below the Gemma 4 31B despite having four times the total parameters.
The honest comparison is that Qwen3 and Gemma 4 are competing for the same position: the best open model you can run on accessible hardware. Qwen3 has a broader parameter range including very large MoE variants. Gemma 4 wins on intelligence per parameter at the sizes that fit on consumer and single-accelerator hardware.
The export control question is relevant for enterprise teams. Qwen models are developed by Alibaba, a Chinese company. Some regulated industries and government-adjacent organizations have policies that restrict or complicate the use of models from Chinese developers regardless of license terms. Gemma 4, developed by Google DeepMind, does not carry that compliance complexity for those organizations.
Mistral
Mistral Large is not the right comparison for Gemma 4. Mistral Large is a hosted API product under a research and commercial license. The right Mistral comparison is the open-weight Mistral models, several of which ship under Apache 2.0.
On benchmark performance, Mistral Large 3 sits at approximately ELO 1415 on Arena AI, meaningfully below Gemma 4 31B’s 1452. For the open-weight Mistral models, Gemma 4 outperforms the comparable size tier on most benchmarks while matching Mistral’s licensing posture. Mistral’s European roots give it a compliance advantage for organizations with strict EU data sovereignty requirements, but Gemma 4’s Sovereign Cloud deployment path on Google Cloud addresses the same need.
Mistral’s strongest card remains its compact models. The Mistral 7B and its derivatives remain extremely efficient for their size. Gemma 4 E2B and E4B are competitive but the Mistral small-model ecosystem has more community momentum.
GPT-4o and Claude 3.7
This comparison operates on a different axis. GPT-4o and Claude 3.7 are not open-weight models. You cannot download them, self-host them, fine-tune them on your own data, or run inference without paying per token and routing your data through a third-party API.
On raw benchmark performance, frontier proprietary models still lead at the hardest tasks. HLE without tools at 19.5% for Gemma 4 31B compares unfavorably to frontier proprietary model performance on the same benchmark. GPQA Diamond at 84.3% is strong but frontier models score higher. The gap exists and is real.
For the workloads where that gap matters cutting-edge research, the absolute hardest reasoning tasks, complex multi-step workflows with no latency tolerance and no cost sensitivity GPT-4o and Claude 3.7 remain the stronger choice.
For everything else, the calculation has shifted. Classification, summarization, document parsing, code review, agentic pipelines for well-defined domains, multilingual processing, local inference, regulated data environments: Gemma 4 now competes on quality while offering deployment flexibility and cost structure that hosted APIs cannot match.
The honest framing is not “Gemma 4 vs Claude 3.7.” It is “which workloads need frontier API quality, and which workloads can use Gemma 4 to reduce cost, eliminate data exposure, and gain deployment control.” For most organizations running AI at scale, the answer is that both have a place in the stack. The mistake is using a hosted API for everything because it is the path of least resistance, not because it is the right tool for every job.
The competitive summary
Gemma 4 wins clearly on: intelligence per parameter at the 26–31B tier, Apache 2.0 licensing with no restrictions, native multimodal including audio on edge models, agentic tool use performance, and edge deployment story.
Gemma 4 trails on: ecosystem depth versus Llama, absolute frontier performance versus GPT-4o and Claude 3.7, and small-model community fine-tune availability versus Mistral.
The window where “just use the API” was the obvious default for every workload is closing. Gemma 4 is one of the models closing it.
Verdict: what to actually do with this
Here is the decision, stated plainly without hedging.
If you are building voice interfaces, IoT systems, robotics, or any application that needs to run without a network connection, the E2B and E4B models are the most capable open models ever shipped for that deployment context. There is no serious competition at this size tier for on-device multimodal inference. Start there today.
If you are building agentic workflows and you are currently paying per-token to a hosted API, benchmark the 26B MoE against your existing setup before you commit to another month of that spend. The Tau2 score of 76.9% is not a research result. It is a production-relevant number on a benchmark designed to test exactly what production agents do: plan, call tools, interpret results, and complete multi-step tasks reliably. The 26B MoE runs at 4B inference speed. The economics shift substantially.
If you are building a local code assistant, the 31B Dense with thinking enabled and Codeforces ELO 2,150 is the strongest open model for that use case available today. Run it on a quantized consumer GPU or on Kaggle’s free GPU notebooks to evaluate it against your actual codebase before making any infrastructure decisions.
If your team has been avoiding Gemma for legal reasons, those reasons are gone. Apache 2.0 means your legal team already has a pre-approved stance on it. The license review conversation takes five minutes instead of three weeks.
If your workload lives at the frontier of reasoning difficulty graduate-level research, the hardest symbolic reasoning tasks, complex multi-agent orchestration at the edge of what any model can do stay on GPT-4o or Claude 3.7 for those specific tasks. Gemma 4 31B’s HLE score of 19.5% is honest about where the ceiling is.
The one thing most coverage has missed
Every article this week has led with the Apache 2.0 license or the Arena AI leaderboard position. Both are important. But the number I keep coming back to is Tau2: the agentic tool use benchmark that jumped from 16.2% on Gemma 3 to 76.9% on the Gemma 4 31B.
Agentic AI is where the production value is being created right now. Not in chat interfaces. Not in summarization pipelines. In systems that plan, act, observe results, and decide what to do next across multiple steps and tool calls. The model that can do that reliably, offline, at low inference cost, under an Apache 2.0 license is a qualitatively different thing from what existed before April 2, 2026.
That is the real story of this release. Everything else is context.
Gemma 4 is not the most powerful model you can access right now. It is the most capable model you can actually own. That distinction is going to matter more over the next twelve months than most people currently expect.
The per-token API era is not ending. But the window where it was the obvious default for every workload, at every scale, in every data environment, is closing fast. Gemma 4 is one of the things closing it.
If you are building with open models, or trying to figure out when to stop paying per token, that is exactly what this publication covers every week. Hit follow and you will get the next piece the moment it lands, no newsletter, no algorithm lottery, straight to your feed.
And if this breakdown saved you three hours of reading model cards and benchmark tables, the clap button is right there. It takes one second and it helps other developers find the article.
Google’s Gemma 4 Is the Most Architecturally Interesting Open Model Released This Year. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.